基于分段距離和子序列匹配的飛機故障檢測
2017-07-12 02:38:09馬發(fā)民王錦彪張林
計算技術(shù)與自動化 2017年2期
馬發(fā)民+王錦彪+張林
摘要:針對飛機故障檢測數(shù)據(jù)中重復(fù)率高數(shù)據(jù)量大,監(jiān)測算法效率和準確率低的問題,本文在PAA壓縮數(shù)據(jù)的基礎(chǔ)上使用分段概率提取細分QAR數(shù)據(jù),調(diào)整FP-Growth算法創(chuàng)建獨具特色FP-Tree降低數(shù)據(jù)的重復(fù)度,提高數(shù)據(jù)的查詢速度,提出了基于分段距離和子序列匹配算法,本文采用真實的飛機飛行QAR數(shù)據(jù)驗證該算法的有效性和準確度。
關(guān)鍵詞:飛機故障檢測; 分段概率提取;QAR數(shù)據(jù);FP-Tree;子序列匹配
中圖分類號:TP301 文獻標識碼:A
Abstract: As about high repetition and large volume of data in airplane fault detection data as well as low efficiency and accuracy of monitoring algorithm, this paper, based on PAA packed data, utilizes Segmental Probability to extract, adjust FP-Growth and establish FP-Tree, thereby reducing repetition degree of data and improving its searching speed. In addition, algorithm on the basis of segmental distance and subsequence match is proposed. In this paper, the real QAR data of flight will be adopted to verify reliability and accurateness of the algorithm.
Key words: airplane fault detection;segmental probability extract;QAR data;FP-Tree;subsequence matc
1對QAR數(shù)據(jù)建立分段后的樹形結(jié)構(gòu)
飛機飛行狀態(tài)通常是穩(wěn)定的,即QAR數(shù)據(jù)的屬性值大量重復(fù)出現(xiàn)[1-2],如此使得分段后的數(shù)據(jù)規(guī)律跟關(guān)聯(lián)規(guī)則挖掘中大量項目同時出現(xiàn)的情況很類似[3],因而可以把每個數(shù)據(jù)段當作一個項集,采用類似頻繁項集挖掘的方法對其進一步信息整合,將類似的數(shù)據(jù)段集中到相近的位置,相同數(shù)據(jù)段只計算一次,提高數(shù)據(jù)搜索匹配的效率。
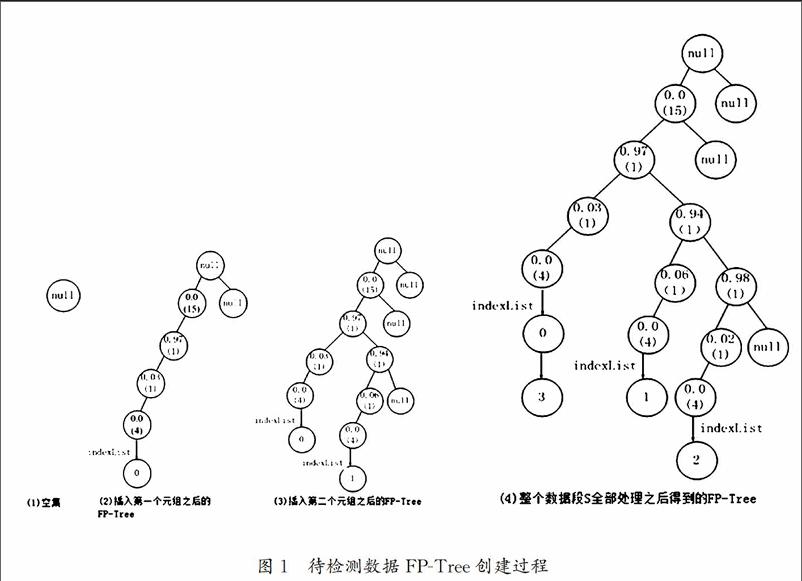
分段概率提取后的21元組的元素順序既定[4],在使用FP-Growth算法進行建樹操作之前,不需第一步掃描數(shù)據(jù)庫并按各項支持數(shù)進行排序,只需直接進行類似FP-Growth模式增長的建樹操作。需要增加的是在該FP樹的每個葉子節(jié)點上要添加一個indexList鏈表,用以記錄所有重復(fù)了從根節(jié)點到葉子節(jié)點的所有數(shù)據(jù)域的數(shù)據(jù)段,即每條從根節(jié)點到葉子節(jié)點的路徑都代表一個數(shù)據(jù)段,而indexList則記錄了跟本路徑相同的所有數(shù)據(jù)段標記。建樹過程可通過以下示例對分段后所形成數(shù)據(jù)段S={ 0:[0,..., 0, 0.97, 0.03, 0, 0 ]T, 1: [ 0,..., 0, 0.94, 0.06 , 0, 0]T, 2: [0,..., 0, 0.98, 0.02 , 0, 0]T, 3:[ 0,..., 0, 0.97, 0.03, 0, 0]T}的處理具體描述如下:
①創(chuàng)建T的根節(jié)點,標號為“null”(如圖1中的(1)),T節(jié)點含有如下成員:節(jié)點數(shù)據(jù)(data),指向其子節(jié)點的指針和指向其右節(jié)點的指針;
②讀取下一段數(shù)據(jù)(現(xiàn)在是第一個元組)0:[0,..., 0, 0.97, 0.03, 0, 0 ]T,在T中從根節(jié)點開始搜索。首先搜索0, T中如果有此節(jié)點,接著搜索下一個元素0.97;T中沒有此節(jié)點,于是不用再繼續(xù)搜索,直接建立整個0:[0,..., 0, 0.97, 0.03, 0, 0 ]T序列的子樹(如圖1中(2)所示,其中多個連續(xù)重復(fù)出現(xiàn)的符號在圖中只出現(xiàn)一次,并在其節(jié)點數(shù)據(jù)后的括號中標注其連續(xù)出現(xiàn)的次數(shù),如圖5-1中的(2)中根節(jié)點的左子節(jié)點0.0(15)表示0.0共連續(xù)出現(xiàn)了15次),建立到葉子節(jié)點后,看該葉子節(jié)點是否存在名為indexList的一個索引鏈表,若存在,則直接將正在處理的數(shù)據(jù)段的段號添加到indexList中若不存在則為該葉子節(jié)點創(chuàng)建indexList鏈表,并添加當前段號到indexList中;
③重復(fù)過程②,直到S中的最后一個數(shù)據(jù)段處理完畢,對S的第二段數(shù)據(jù)處理后fp樹如圖1中的(3)所示。S全部數(shù)據(jù)段處理完畢后fp樹如圖1中的(4)所示。
2子序列匹配定位故障數(shù)據(jù)段
樹型數(shù)據(jù)結(jié)構(gòu)由于其前綴共享的特點,能夠避免數(shù)據(jù)操作過程中大量的重復(fù)操作,大幅提高數(shù)據(jù)處理效率。數(shù)據(jù)大爆炸環(huán)境下,為高效處理數(shù)據(jù),無不考慮引入樹型結(jié)構(gòu)改進算法,例如文獻[5]中將DFST-Tree結(jié)構(gòu)引入數(shù)據(jù)流挖掘算法研究,而在人工智能與數(shù)據(jù)挖掘方向的prifix前綴樹與FP-Growth等算法更是久負盛名。目前樹型結(jié)構(gòu)用于匹配查詢方向的算法如k-d樹查詢[6]及子樹匹配,前者是從k-d樹中查詢給定序列,給定序列并非樹型結(jié)構(gòu);后者則用于查詢兩棵樹的結(jié)構(gòu)是否類似,但是并不關(guān)心樹的節(jié)點數(shù)據(jù)。本文基于FP-Growth算法對分段后的源數(shù)據(jù)序列建立樹形結(jié)構(gòu),然后根據(jù)故障模型進行序列匹配,定位到可能出現(xiàn)故障的數(shù)據(jù)段。序列匹配定位算法的具體描述如下:
先序遍歷fp樹,從根節(jié)點到每個葉節(jié)點的路徑都是一個數(shù)據(jù)段的代表,從根節(jié)點搜索到葉節(jié)點的匹配過程如下:
①計算加入當前節(jié)點后該條路徑上所有點與故障模型的距離,若距離小于給定閾值,檢查當前節(jié)點是否為葉子節(jié)點,若是轉(zhuǎn)③,若不是葉子節(jié)點轉(zhuǎn)②;若距離大于給定閾值則剪去該節(jié)點及其所有左子節(jié)點并轉(zhuǎn)②。
②轉(zhuǎn)入當前節(jié)點的左子樹并重復(fù)步驟①。
③當前節(jié)點已經(jīng)是葉子節(jié)點,且從根節(jié)點到葉子節(jié)點整條路徑上所有點與故障模型的距離不超過給定閾值,則該條路徑所代表的數(shù)據(jù)段即為與故障模型匹配成功,得到葉子節(jié)點的indexList鏈表,即為故障數(shù)據(jù)段位置鏈表,本條路徑匹配完畢。
3實驗結(jié)果及分析
取航空公司CAB737-800型飛機的2008年8月份的25個航班記錄,每個航班記錄序列的長度為6089~11949不等,數(shù)據(jù)分段段長取100,數(shù)據(jù)符號化范圍為0到20。飛機故障通常情況下不是由單一因素引起,面與飛機故障有關(guān)的不同屬性在飛機發(fā)生故障過程中的重要程序也各不相同,根據(jù)專家經(jīng)驗給出的空中顛簸故障屬性重要度調(diào)查表[7-8],垂直加速度屬性是對空中顛簸故障發(fā)生的最重要影響屬性,因此主要針對該故障數(shù)據(jù)的垂直加速度屬性數(shù)據(jù)實驗。
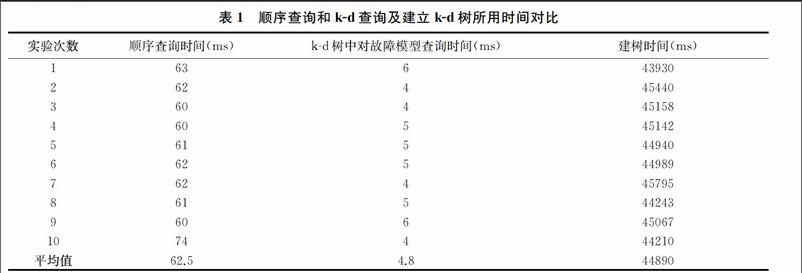
文獻[9-10]通過研究并驗證k-d樹的特點和優(yōu)勢,對QAR數(shù)據(jù)進行符號化并建立了多維時序飛行數(shù)據(jù)的子序列,并驗證了k-d樹查找的速度相比于順序掃描的明顯優(yōu)勢,適用于大規(guī)模時序飛行序列中子序列的相似性搜索。其實驗結(jié)果如表1所示。
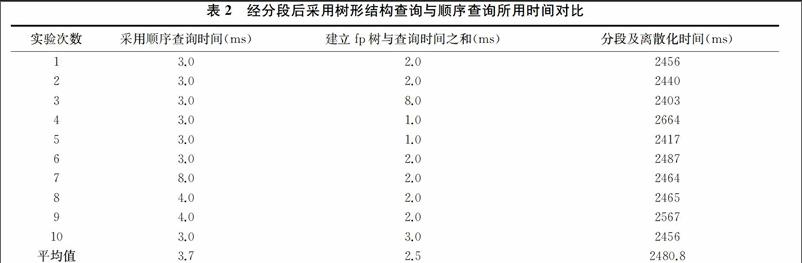
表1清晰表明了k-d樹查找的速度遠快于順序掃描的速度,適合大規(guī)模時序飛行序列中子序列的相似性搜索。但是在k-d查詢之前所需的建樹時間依然不容忽視,本文通過分段符號化并概率提取然后再建樹查詢,分段及離散化共用時間平均為310.1ms,建樹和查詢所用時間之和平均僅為2.5ms。綜合表1和表2,顯然分段后的查詢時間僅為不分段就順序查詢的一半,而采用樹形結(jié)構(gòu)查詢之后搜索時間再一次得到提升,從建樹到查詢結(jié)束的總時間低于k-d樹的僅查詢時間。
另外子序列查找過程中以查找到的類似故障數(shù)據(jù)段為目標輸出,并將類似故障數(shù)據(jù)段輸出到到文件,當檢測數(shù)據(jù)為模擬的非故障數(shù)據(jù)時,輸出文件無內(nèi)容,而當檢測數(shù)據(jù)為模擬的故障數(shù)據(jù)時,輸出文件中會得到如圖2的結(jié)果,其中“文件0”是一個待檢測的故障數(shù)據(jù)文件,“異常數(shù)據(jù)段0”則是故障模型中的一個故障點代表,與其相似的數(shù)據(jù)段表示采集到該待檢測數(shù)據(jù)的航班有可能會發(fā)生與故障模型相同的故障。實驗得到故障相似數(shù)據(jù)段之后可以根據(jù)其數(shù)據(jù)段號(比如圖2中“數(shù)據(jù)段42”的“42”)來定位故障發(fā)生的具體位置。由此可見本程序可以正確識別出并定位本類型的故障數(shù)據(jù)段,具有相當?shù)膮⒖純r值。
綜上可知本文所用方法對于大規(guī)模數(shù)據(jù)處理具有足夠的正確率和高效性。
4小結(jié)
本文主要介紹了針對突發(fā)故障點數(shù)據(jù)段的檢測和定位方法,在PAA表示方法的基礎(chǔ)上進一步對QAR數(shù)據(jù)進行分段細化,將故障點鎖定在更小的數(shù)據(jù)段內(nèi),對于時序數(shù)據(jù)來說,能夠定位到更貼近故障突發(fā)的時間段;通過基于樹的子序列查詢算法提高了搜索查詢的效率的同時保證了查詢的正確性,實驗證明本文采用算法是有效可行的。
參考文獻
[1] 王天明.基于QAR數(shù)據(jù)的飛行安全模型研究[D]:[碩士學(xué)位論文].天津:中國民航大學(xué).航空自動化系,2008.
[2] 閆偉. QAR飛行時序數(shù)據(jù)相似性搜索算法研究[D]. 天津: 中國民航大學(xué), 2010: 21-25.
[3] 趙恒. 數(shù)據(jù)挖掘中聚類若干問題研究[D]. 西安: 西安電子科技大學(xué), 2005 : 10-11.
[4] Jong P.Yoon,Jieun Lee,Sung Kim.Trend Similarity and Prediction in Time-Series Database.Proceeding of SPIE,2000,4057:13-20.
[5] Tomas Flouri, Jan Janousˇek, and Borˇivoj Melichar. Subtree Matching by Pushdown Automata. ComSIS, Special Issue, April 2010, 7(2) :331-357.
[6] 張國振. 多元時序飛行數(shù)據(jù)子序列的相似性搜索算法研究[D]:[碩士學(xué)位論文]. 天津:中國民航大學(xué). 計算機科學(xué)與技術(shù)學(xué)院, 2011.
[7] Chakrabarti,K. et al., Locally adaptive dimensionality reduction for indexing large time series databases. ACM Trans on Database Systems, 27, 2002: 188-228.
[8] Kamran Rokhsaz, Linda K. Kliment, and Alhambra L. Yee, etc. Comparison of Two Business Jets – Usage and Flight Loads. 2013 Aviation Technology, Integration, and Operations Conference August 12-14, 2013, Los Angeles, CA.
[9] 肖輝.時間序列的相似性查詢與異常檢測[D]:[博士學(xué)位論文].上海:復(fù)旦大學(xué).計算機與信息技術(shù)系,2005.
[10] 郝飛. 基于粗糙集的時序數(shù)據(jù)挖掘及其應(yīng)用[D]. 成都: 西華大學(xué), 2008: 9-10.
