基于漢字固有屬性的中文字向量方法研究
2017-07-18 10:53:17陳凱琪
中文信息學報 2017年3期
胡 浩,李 平,陳凱琪
(西南石油大學 計算機科學學院 智能與網絡化系統研究中心,四川 成都 610500)
基于漢字固有屬性的中文字向量方法研究
胡 浩,李 平,陳凱琪
(西南石油大學 計算機科學學院 智能與網絡化系統研究中心,四川 成都 610500)
中文短文本在如今高速發展的互聯網應用中變得日趨重要,如何從海量短文本消息中挖掘出有價值的信息,已成為當前中文自然語言處理中非常重要且具有挑戰性的課題。然而,采用傳統的長文本處理方法進行分析往往得不到很好的效果,其根本原因在于中文短文本消息的語法及其語義的稀疏性。基于此,該文提出一種基于漢字筆畫屬性的中文字向量表示方法,并結合深度學習對短文本消息進行相似性計算。該方法結合中文漢字的構詞和拼音屬性,將中文漢字映射為一個僅32維的空間向量,最后使用卷積神經網絡進行語義提取并進行相似性計算。實驗結果表明,與現有的短文本相似性計算方法相比,該方法在算法性能及準確率上均有較大的提高。
短文本;中文字向量;深度學習
1 引言
隨著互聯網,尤其是移動互聯網的快速發展,社交媒體已經變成人們交流和傳遞思想的主要平臺。每天從社交平臺上產生的信息交互量難以估計。面對如此海量的消息,如何進行科學的有效管理,已成為當前的研究熱點。根據中國互聯網發展統計報告,文本信息已占網絡資源的70%以上,是互聯網中信息傳播的主要載體,每天從網絡中產生的文本信息量在TB級別以上。在文本處理領域,一般將文本信息分為長文本和短文本。 互聯網產生的數據大多數以短文本為主,如騰訊空間說說、新浪微博、百度知識問答和淘寶商品的評價等。 相對于傳統大篇幅的長文本,人們更容易接受以短文本的形式進行交流。如新浪微博限制其消息字數為140,知識問答都是以簡略語句的形式來概括。短文本能更好的表達出人們的情緒,人們更喜歡以幾個字甚至一個表情來表達自己的情感傾向。如何使用機器學習的相關方法對這些數據進行分析,挖掘出有用的信息,從而更好的利用互聯網改善人民的生活已經變得日趨重要,如幫助商家提供決策,以使其利益最大化,幫助用戶更有效的提高產品體驗,是當前文本挖掘的重要課題。
中文文本挖掘中一個關鍵問題是對文本語義相似度[1]進行計算,這也一直是自然語言處理(natural language processing,NLP)[2]的研究熱點之一,其應用場景非常廣泛。在推薦系統[3]中,可以找到與其商品屬性描述類似的其他商品進行推薦;在文本聚類[4]中,可以找到一些主干相似的句子;在信息檢索中,可以找到與用戶檢索信息匹配的信息;在搜索引擎中,可以根據相似度排序提供查詢結果。另外,文本相似度分析還可應用于論文文獻查重。然而,對短文本的研究發現,短文本消息不像傳統的長文本消息具有豐富的結構信息,并且詞與詞之間的相關性較弱,語義及語法的稀疏性使它很難利用傳統研究長文本的方法來分析。近年來,隨著在圖像及語音領域獲得的各種突破,深度學習也越來越受到自然語言領域研究者的重視。然而,自然語言處理任務由于其自身特點,與圖像、語音處理在應用深度學習技術上存在著一些區別。其中一個最根本的區別在于,圖像、語音信號可以直接在向量空間進行表示,而傳統的自然語言處理是在詞匯一級表示,不能直接作為深度神經網絡的輸入變量。因此,采用深度學習方法處理文本的首要任務是對語言的向量化。在傳統自然語言處理過程中,通常用向量空間模型(vector space model,VSM)[5]對文本進行向量化。在向量空間模型中,單個詞被表示成One-hot的形式,即在基于詞表的向量中該詞出現的位置為1,其余置為0。由于詞表通常很大,表征詞匯的向量維度很高,容易造成數據稀疏。
另一方面,One-hot的表征方式無法反映語義信息。典型的做法是用奇異值分解(singular value decomposition,SVD)[6]來獲得關于詞的語義信息。然而,這種方式得到的關于詞的表征受詞匯量的影響較大,計算復雜度也比較高。目前,一種基于深度神經網絡[7]自動學習的向量表示受到極大關注。深度學習是機器學習中一個相對比較新興的領域,主要通過構建多層神經網絡,通過組合低層特征形成更加抽象的高層表達,根據其結構不同,目前主要有前饋神經網絡(feed-forward neural network)[8]、卷積神經網絡(convolution neural network, CNN)[9]、遞歸神經網絡(recursive neural network)[10]、反饋神經網絡(recurrent neural network)[11]等。各種不同架構的神經網絡用于不同的任務,如遞歸神經網絡可以用于情感分析;長短時記憶模型(long-short term memory, LSTM)用于處理帶序列的數據,屬于反饋神經網絡的一種;卷積神經網絡(CNN)被廣泛應用于圖像處理領域。在確立神經網絡模型之后,其主要難點是如何把要處理的對象表示成可計算的數值或向量輸入到網絡中,從而得到想要的輸出結果。
借助于神經網絡模型,詞義信息可以用它的上下文來表達,這種表征不僅在維度上較One-hot的表示低了很多,而且能夠很大程度上反映詞與詞之間語義的相關關系。然而,需要指出的是,深度神經網絡模型中的輸入層通常還是采用One-hot表示。由于這種表示非常浪費空間資源,微軟亞洲研究Huang等人[12]提出了一種基于字母組合的輸入表示法,并在深度語義網絡模型的訓練下取得了較好的效果。盡管在英文及其他西文文本的詞向量表示方法上,自然語言處理領域已經取得了顯著進展,但一些有效的方法并不能直接用于表征中文文本的語義。清華大學Chen[13]等人提出一種詞向量表示方法CWE(character-enhanced word embedding), 它是在CBOW(continue BOW)[14]的基礎上,通過融合漢字的特性(如漢字在詞語中出現的位置和所屬類別等)提出的一種詞向量方法,該方法取得了較好的效果。受Huang等人的工作啟發,本文提出一種基于漢字筆畫的字向量表示法,并用于深度神經網絡學習,從而獲取短文本的語義信息。實驗證明,在短文本相似度計算上,該字向量表示方法具有較好的效果。特別地,該字向量表示的向量維度低,空間開銷小。
針對短文本消息的特征,本文提出使用卷積神經網絡的方法來實現中文短文本語義相似度的計算,針對網絡的輸入問題,同時也提出一種根據中文漢字的結構屬性來獲取它在高維空間中的表達,即用一個32維的向量來表示每一個漢字,并將其作為網絡的輸入。實驗中,使用相關短文本數據,結合提出的字向量表達方法,并對實驗結果進行分析,驗證了本文所提方法的有效性。
2 相關工作
文本相似性計算是指給出兩個文本消息,通過分別對它們進行數據預處理,分析并使用恰當的算法提取其相應的特征,再通過一定的方法來度量它們之間的相似性。當前計算短文本消息相似性的方法有如下幾種。
(1) 傳統經典模型TF-IDF以及一些基于它改進的方法: 主要思想是通過提取文本消息中詞語的權重來標識句子,使文本消息構成向量表達。權重主要由兩部分組成,即該詞語在文本中的頻率(term frequency, TF)與反文檔頻率(inverse document frequency, IDF)。然而這種方法太過于依賴詞語的共現,加上本身短文本消息就由很少的字組成,往往實際應用中得不到很好的效果。因為兩個文本消息可能沒有共同的詞語但也可以語義相關,相反如果兩個文本消息有一些共同的詞語也不一定語義相關。如”富士蘋果很好吃,趕緊買”,“蘋果六代真好用,趕緊買”和”喬布斯逝世了”。
(2) 基于知網的方法: 知網是一個以包括漢語和英語所代表的概念為描述對象,以揭示它們之間所具有的屬性關系為基本內容的常識知識庫[15],義原作為其最小的不可分割的語義單位被廣泛應用。通過對文本消息分詞處理加上使用義原樹可以計算詞語之間的相似度,最終通過一定的方法來得出文本之間的相似性,其中吳健[16]、江敏[17]、劉群[18]、Resnik[19]、李峰[20]、李培[21]、Dekang Lin[22]等在義原間相似度計算方面做了大量的研究工作。
(3) 通過對短文本消息進行特征擴展: 擴充它的語義信息來彌補其稀疏性[23-28]。文獻[28]通過適當聚合某一個Tweet用戶發布的一些短文本消息,使之構成相對較豐富的文本信息。但這種方式的局限性在于不一定都能找到適合與原文本消息擴展的其他消息,比如某些用戶可能只有很少的Tweet消息。
(4) 基于主題模型的方法:LDA(latent dirichlet allocation)是主題模型的典型代表,由于理論的完備性與可解釋性被廣泛應用于文本主題挖掘任務中,主要用來發現在文本集中潛在的主題分布。在實驗研究中發現,短文本消息主題模型同樣存在上述所說的稀疏性問題。為了解決這一問題,文獻[29]提出BTM(biterm topic model)主題建模,它充分利用基于全局文檔的詞語共現模式,能一定程度克服短文本消息的語義特征稀疏性,能夠取得比LDA更好的效果,表1展示了BTM的部分效果,但是BTM的算法復雜度較高。
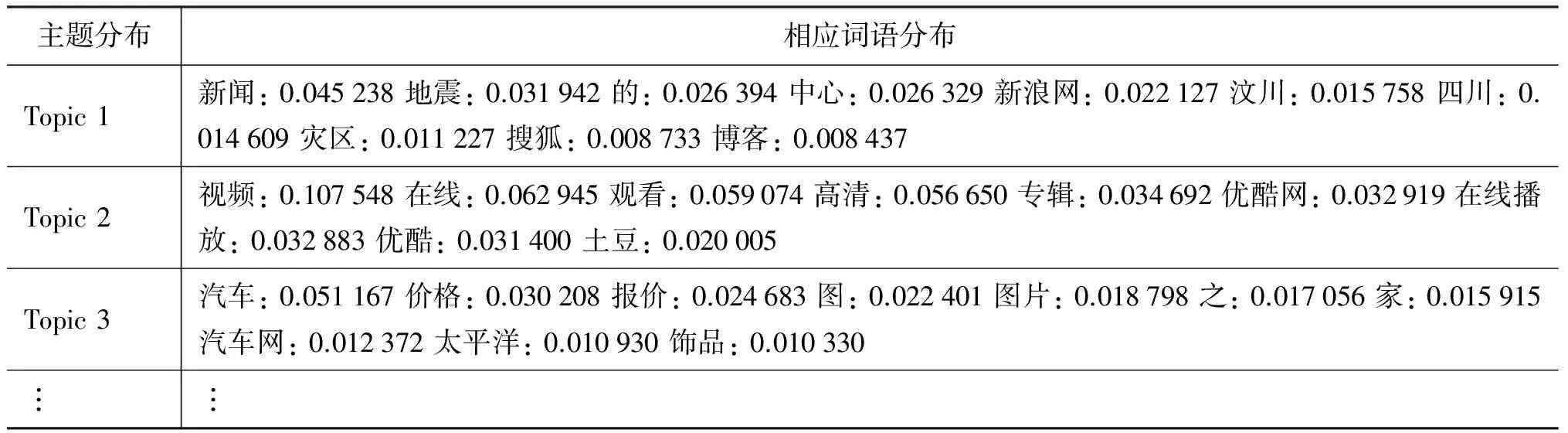
表1 BTM 主題模型樣例
由于短文本消息語義稀疏并且沒有豐富的結構信息,其包含的可利用的信息量非常有限,以上傳統的文本間相似度計算方法普適性普遍較差。本文主要使用卷積神經網絡對短文本消息進行語義特征提取,并在此基礎上提出根據漢字字型結構及其拼音形式構造字向量作為網絡的輸入,然后利用隱藏層不斷學習其抽象特征,最后得出其文本消息更高層次的向量表達,即可視為該文本消息的語義特征。
3 基于筆畫的字向量模型與卷積神經網絡
3.1 基于筆畫的字向量模型
漢字造字法,即古人所說的“六書”: 象形字、會意字、指事字、形聲字、轉注、假借,可分為“四體二用”,其中四體的含義如下。
(1) 象形字是描摹事物的記錄方式,是世界上最早的文字,也是最形象、演變至今保存最完好的一種漢字字形。它純粹利用圖形來刻畫文字的使用,而這些文字與所代表的含義在形狀上很相像。如“休”字,像是一個人依偎著一棵樹。“山”就像一座大山的樣子,在一群山的中間有一座高高的山峰。
(2) 會意字是指兩個或兩個以上的獨體字根據其意思合成的一個字。
(3) 指事字是一種抽象的造字方法,當沒有或不方便用具體形象刻畫的時候就用一種抽象的符號來表示。
(4) 形聲字是在象形字、會意字、指事字三種形式的基礎上形成的。它是兩個文或字復合成體,其中一個文或字表示事物的類別,而另一個表示事物的讀音,也就是人們通常說的“讀音認字認半邊”。
另外,漢字還可以拆分為偏旁和部首,很多漢字如果具有同一個偏旁,可能表示同一個意思,甚至讀音也一樣。例如,很多帶“扌”的漢字表示為一個動作, 即提、扛、搶、挑等。不僅如此,根據漢字的結構,研究發現任何一個漢字都可以分別由橫、豎、撇、捺、折的個數線性組合。例如,
良=2·橫 +0·豎 +1·撇 +2·捺 +2·折
綜合以上信息,本文根據漢字的組成結構和其拼音結構,提出一種新的字向量模型,把漢字完全映射到歐氏空間。其中,每個漢字由一個長度僅為32位的向量組成。相比于One-hot的向量表示方法,基于筆畫的字向量具有非常低的維度,詳見表2。

表2 字向量模型的32位構成
在實驗中,通過公開的漢字筆畫庫和拼音庫[30],對20 902個漢字使用上述方法分別構造出它們的字向量(表3),發現僅有297對字向量沖突,即不同的漢字具有相同的字向量表達,如表4列舉了部分沖突的漢字對。 然而,從表4中可以看到,很多沖突的漢字對都是通假字或是生僻字或是一些已經從字典中丟棄的字,并且在沖突的漢字對中,幾乎沒有在常用的2 500個漢字和次常用的1 000個漢字的范圍內。這說明基于筆畫的字向量模型是可行的。

表3 字向量舉例
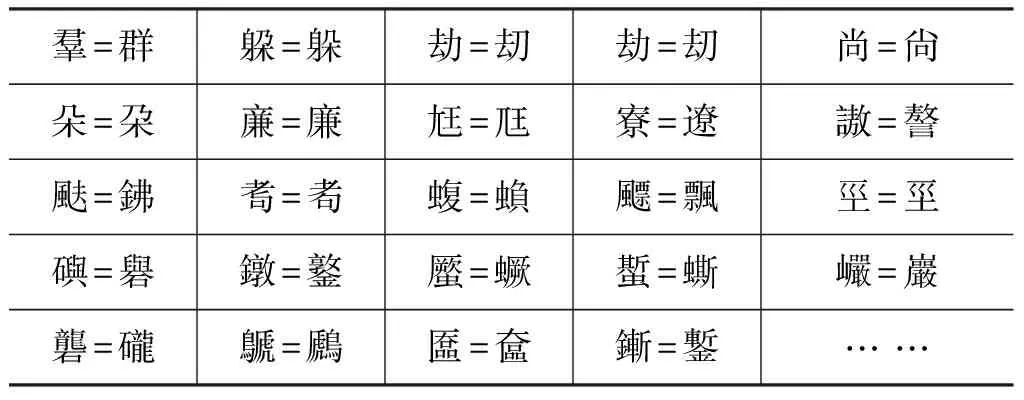
表4 字向量模型中的部分沖突
3.2 卷積神經網絡(CNN)
卷積神經網絡(CNN)屬于人工神經網絡,廣泛應用于語音處理和圖像識別領域。與其他神經網絡模型相比,它的主要優勢在于權值共享,減少了網絡結構中權值的數量,從而降低了后期訓練網絡模型的復雜度。此外,在圖像處理領域使用卷積神經網絡可以把圖像直接作為網絡的輸入,避免了像傳統圖像識別算法中復雜的數據重建和特征提取過程。卷積神經網絡是一個特殊的多層感知器,使之更類似于生物神經網絡。
在自然語言處理領域同樣可以使用卷積神經網絡,其關鍵點就在于如何把漢字表示成數字或向量輸入到網絡模型中。只要獲取到漢字的表達之后,就可以完全使用卷積神經網絡,最后提取出相應的語義特征。類似于圖像處理,使用卷積神經網絡的優點在于,當獲取到相應漢字表達之后,可以直接將其輸入網絡,不像傳統基于詞語類的特征提取方法。傳統方法中,要首先進行分詞,然后再根據詞語來提取該文本的特征,并且不同的分詞模型還可能會影響到最后的結果。對此,本文提出了一種基于漢字屬性結構的哈希映射方法。
4 基于卷積神經網絡的中文短文本相似度計算
4.1 方法概述
利用基于筆畫的字向量模型將漢字映射成向量,就可將短文本消息直接輸入網絡中計算。卷積神經網絡的架構包括: 輸入層、卷積層、采樣層、特征表達層,詳見圖1(注: 以下將用到的字母表示完全依照圖1)。
我們把使用卷積神經網絡加上基于筆畫的的字向量模型稱為CNN_CC(CNN for Chinese Character),下面對CNN_CC是如何進行短文本特征提取的做出詳細解釋。
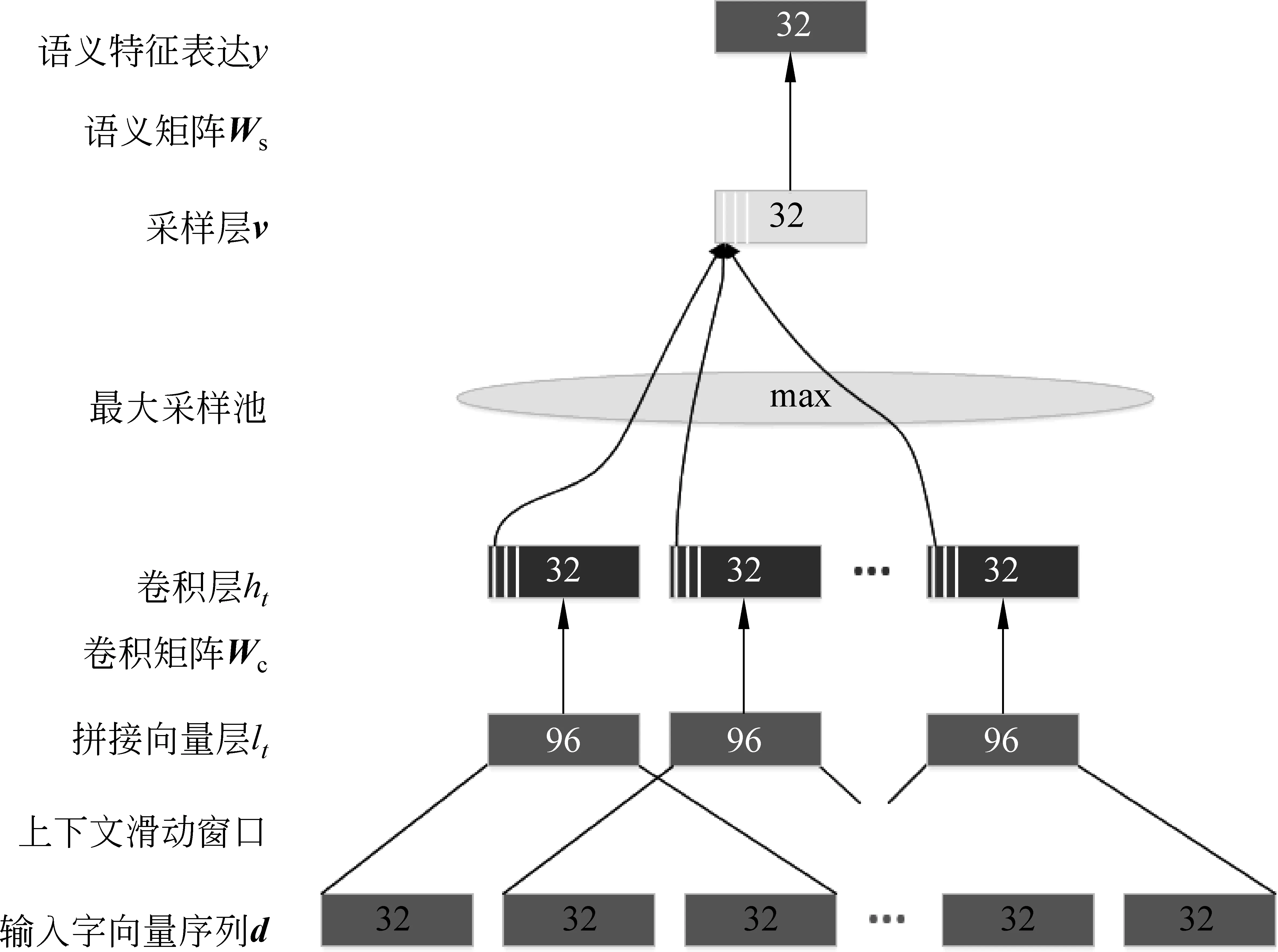
圖1 CNN_CC 模型
輸入層: 首先運用字向量模型,把待操作的短文本消息中的每一個字表示成一個字向量,并把它們拼接起來。拼接之后的向量就表示該短文本消息。如圖1表示,并非將每一個字向量單獨的輸入網絡中運算,而是采用上下文滑動窗口機制,即設某短文本消息有T個漢字組成,窗口大小為d,lt表示該消息中第t個字向量,則:
卷積層: 卷積層上的卷積操作可以視為基于滑動窗口的特征提取,首先根據滑動窗口產生一個上下文拼接向量,然后使用一個線性映射矩陣和tanh激活函數來產生局部特征向量,即
其中,
以這樣的方式操作每一組字向量。這種操作簡化了模型參數個數,因為對于每一個拼湊之后的矩陣lt都使用Wc來進行卷積操作。基于上下文的滑動窗方式,類似于自然語言處理中語言模型的思想,如n-gram模型。這樣做是因為很多字或詞在不同的語境下所表示的意思不盡相同,其周圍的鄰居詞語在一定程度上可以反映出它的含義,這種思想在很多自然語言處理任務中被廣泛使用。
采樣層: 在卷積層中提取出一系列局部上下文特征之后,這些詞語級別的特征需要被整合成句子級別的特征,它是一個固定長度且獨立于輸入字序列的一個特征向量。從直觀上理解,在提取短文本語義特征時,句子中那些并沒有顯著含義的字或詞應該過濾掉。相反,那些意思顯著的主干字應盡量保存下來。即在采樣層要盡量保留顯著的局部特征而抑制那些不重要的局部特征。出于這樣的目的,在此使用了max函數求每一維度的最大值,即
其中,v(i)表示采樣層v的第i個元素,ht(i)表示卷積層第t個局部特征的第i個元素。K是采樣層采樣的維度,和卷積層的維度相等。
特征表達層: 當采樣層提取出句子級別的特征之后,使用一個非線性的傳輸層來提取更高層次的語義表達,對應圖1中的語義表達層如式(5)所示。
其中,Ws表示語義映射矩陣,v是通過采樣層得到的特征向量,y表示潛在的語義空間表達,即所要求的目標量。
4.2 訓練模型參數
為最優化圖1的參數,即θ={Wc,Ws},使用基于文檔對之間的語義誤差作為訓練的目標(Yih et al.[31])。考慮一個短文本信息s,有兩個候選短文本消息t1和t2,其中t1和s的語義更相關,即使得:
其中σ(s,t)表示短文本消息s和t之間的語義相似度,其計算方法如式(7)所示。
其中ys和yt表示由卷積神經網絡產生的短文本消息s和t的語義特征向量,參數用θ表示。直觀上,我們需要最大化Δ,即最大化語義相似度高的文本集與語義相似度低的文本集之間的差距。因此,選取邏輯回歸的誤差損失函數表示,即
由于使用了余弦相似性,Δ的范圍為[-2,2],為了使它有一個更大的取值范圍,我們引入了比例因子γ。在實驗中取γ=10。由于式(8)可微,可以使用隨機梯度下降法來最優化。在其訓練過程中,我們采用自適應方法來調整學習率η: 即開始設置η=1.0,在每一次全部文本消息迭代完成之后,設置η=η·0.5,直到損失函數不再明顯減少或η小于預先設置的閾值(如0.000 01),才停止迭代。
5 實驗結果及分析
5.1 實驗數據集
為了驗證本文所提方法的有效性,我們使用了搜狗開放實驗室(Sogou Labs)[32]提供的兩份數據: 用戶點擊數據集和語義相關度標注數據集。不同數據集有其相應的特性。 點擊數據集里面的數據分散,對于每一條短文本,除了與其對應的標題語義相關之外,其他消息與之幾乎不相關。而標注數據集則相反,里面存在很多(大于20)彼此相關的短文本消息,只是相關程度不一,但都確保有其語義最相關的消息。部分數據展示如表5、表6所示。除此之外,還在網頁中爬取了相關URL的網頁標題, 這樣可以視為用戶搜索詞與點擊URL的標題這兩個短文本消息正相關,即視為他們表示相同的語義信息。這些數據與其他不相關的語義的短文本消息一起,就構成了模型的訓練數據集。

表5 用戶點擊數據集
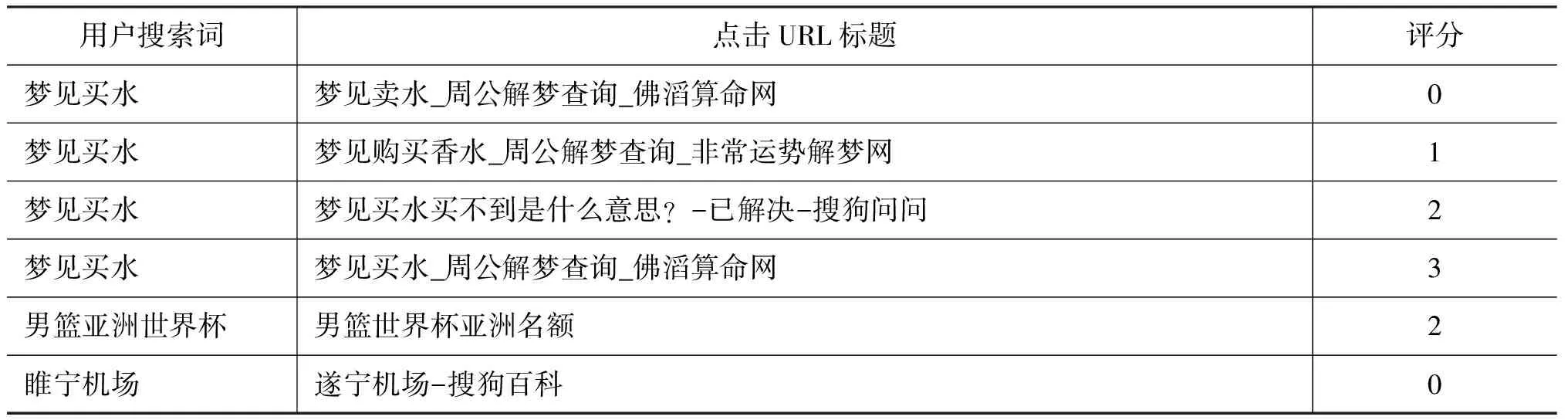
表6 語義相關度標注數據集
5.2 實驗效果對比
實驗中加入三個模型作為實驗結果的對比: VSM、BTM和CWE。其中,BTM被認為是目前短文本計算效果相對較好的主題模型,而CWE則是一種采用深度學習技術的詞向量表示方法。
在實驗過程中,當訓練好模型之后,分別提取每一個短文本消息的語義特征,即一個32維的向量,再通過余弦相似度計算短文本集中每一對短文本消息的語義相似性,最后反向對比每一個短文本消息是否匹配到最相關的語義消息,記準確率P為評論指標。考慮到空間向量模型(VSM)的特性,實驗分兩組進行:
第一組為CNN_CW、BTM和CWE的對比,應用在用戶點擊數據集中;
第二組為CNN_CW、VSM和CWE的對比,應用在語義相關度標注數據集中。
根據圖2可以得出: 在兩個數據集中的兩次實驗結果中,CNN_CC均比BTM和VSM的效果好,特別是在標注數據集中,甚至比VSM的命中率多了十倍。這是因為在標注數據集中每一個文本都至少有20條與其語義相關的消息,換言之,僅從組成漢字而言,有很多與目標消息在表面上字或詞重疊,這就使得VSM效果極差。
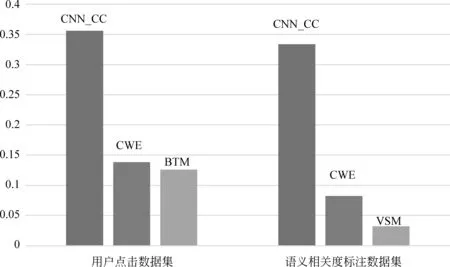
圖 2 實驗結果
為了進一步說明CNN_CC的優越性,圖3列出了更詳細的實驗結果,其中橫坐標表示通過模型計算出的與目標短文本最相似的前N個短文本,如果包含其最相似的短文本消息,即視為命中。
從圖3中可以看出: 由于點擊數據集由非常短的短文本消息(最短的兩個字)組成,使得基于傳統CBOW方法的學習效果非常差,從而導致CWE的效果不太理想。然而,在圖4中,由于語義相關度標注數據集文本的長度相對要長很多,而且固定模式的詞組會反復出現,所以CWE取得的效果比前一個數據集的效果好。綜上所述,CNN_CC在兩個數據集上的效果均優于其他兩種方法,并且在兩個數據集中的穩定性也相對更好。
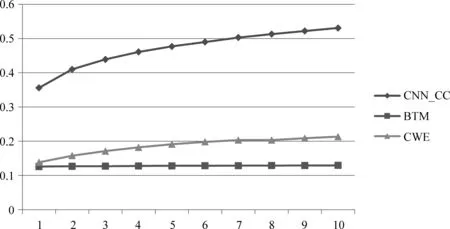
圖 3 對比三個模型在點擊數據集上的準確率
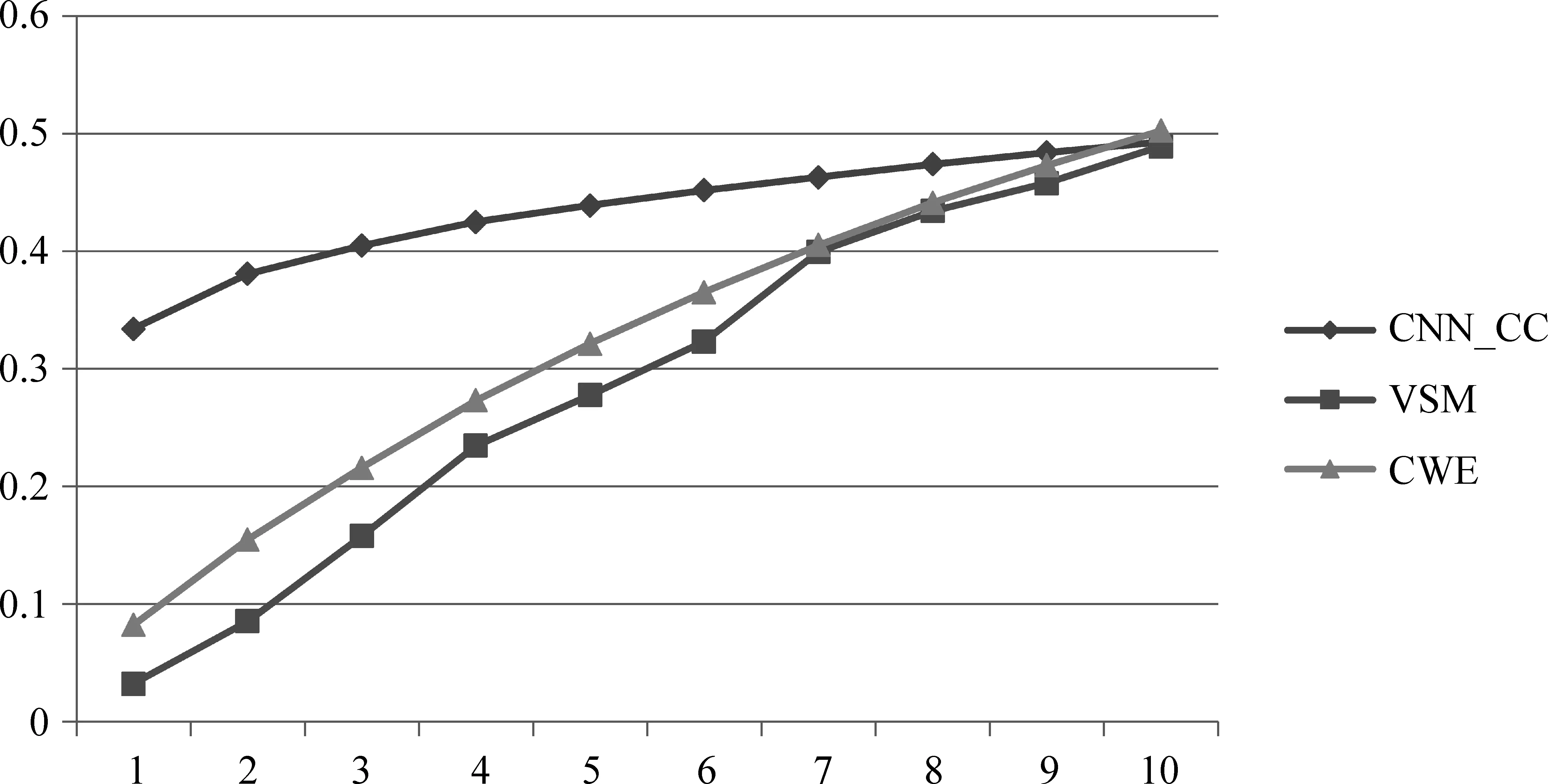
圖 4 對比三個模型在語義相關度標注數據集中的準確率
6 總結及未來的工作
隨著移動互聯網的快速發展以及移動智能設備的日益普及,短文本消息數量將成為信息傳播的主流載體。本文以短文本消息為研究對象,結合卷積神經網絡提出一種基于漢字的字向量模型(CNN_CC)。通過把漢字表示成一個32維的向量,再經過神經網絡每一層的復雜特征提取過程,最后得到短文本消息的語義特征表達。因此,只要獲取了其相應的語義特征向量,就可以計算出兩個短文本消息之間的語義相似度。利用筆畫信息進行漢字的向量化,不僅降低了文本向量化的維度,大幅降低了計算的復雜度,在真實數據集上的實驗結果也證明了該方法優于其他兩種常用的短文本處理方法。
在下一步的工作中,我們會考慮在32維的基礎上融入漢字的其他結構信息(如漢字有上下結構、左右結構、上中下結構等)和多音字信息,以及標點符號信息,因為中文的標點也帶有一定的感情色彩。此外,由于在當前的研究模型中我們只使用了一層全連接網絡,未來可以嘗試增加多層全連接網絡,使得網絡可以獲取更加豐富的文本信息。
[1] 代六玲, 黃河燕, 陳肇雄. 中文文本分類中特征抽取方法的比較研究[J]. 中文信息學報, 2004, 18(1): 26-32.
[2] 陳肇雄, 高慶獅. 自然語言處理[J]. 計算機研究與發展, 1989,(11): 1-16.
[3] Bedi P, Kaur H, Marwaha S. Trust based recommender system for the semantic web[C]//Proceedings of the 20th international joint conference on artifical intelligence. Morgan Kaufmann Publishers Inc.. 2007: 2677-2682.
[4] 劉遠超, 王曉龍, 徐志明,等. 文檔聚類綜述[J]. 中文信息學報, 2006,20(3): 55-62.
[5] Lee D L, Chuang H, Seamons K. Document Ranking and the Vector-Space Model[J]. Software IEEE, 1997, 14(2): 67-75.
[6] Yoshikawa T. Singular-value decomposition[M]. Foundations of Robotics: Analysis and Control. MIT Press, 2003: 268-271.
[7] Dong Y, Li D. Feature representation learning in deep neural networks[M]. Automatic Speech Recognition. Springer London, 2015: 157-175.
[8] Zhang J R, Zhang J, Lok T M, et al. A hybrid particle swarm optimization-back-propagation algorithm for feedforward neural network training[J]. Applied Mathematics & Computation, 2007, 185(2): 1026-1037.
[9] Huang W, Qiao Y, Tang X. Robust scene text detection with convolution neural network induced MSER trees[M]. Computer Vision-ECCV 2014 Springer International Publishing, 2014: 497-511.
[10] Dong L, Wei F, Tan C, et al. Adaptive recursive neural network for target-dependent twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2014: 49-54.
[11] Williams R J, Zipser D. A learning algorithm for continually running fully recurrent neural networks[J]. Neural computation, 1989, 1(2): 270-280.
[12] Huang P S,He X,Gao J,et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on conference on information & knowledge management ACM, 2013: 2333-2338.
[13] Chen X, Xu L, Liu Z, et al. Joint learning of character and word embeddings[C]//Proceedings of International Conference on Artificial Intelligence. AAAI Press, 2015.
[14] Goldberg Y, Levy O. word2vec Explained: deriving Mikolov et al.’s negative-sampling word-embedding method[J]. Eprint Arxiv, 2014.
[15] 董振東,董強.知網[DB/OL].[2011-06-23]. http://www.keenage.com/.
[16] 吳健,吳朝暉,李瑩,等.基于本體論和詞匯語義相似度的web服務發現[J]. 計算機學報,2005,28(4):595-602.
[17] 江敏,肖詩斌,王弘蔚,等.一種改進的基于《知網》的詞語語義相似度計算[J].中文信息學報,2008,22(5): 84-89.
[18] 劉群, 李素建. 基于《 知網》 的詞匯語義相似度計算[J]. 中文計算語言學, 2002, 7(2): 59-76.
[19] Resnik P. Using Information Content to Evaluate Semantic Similarity in a Taxonomy[C]//Proceedings of the 14th International Joint Conference on Artificial Intelligence. 1995: 448-453.
[20] 李峰,李芳. 中文詞語語義相似度計算——基于《知網》2000[J].中文信息學報,2007,21(3): 99-105.
[21] 李培.基于《知網》的文本相似度研究[D].河北工業大學碩士學位論文,2012.
[22] LIN Dekang.An information—theoretic definition of similarity semantic distance in WordNet[C]//Proceedings of the 15th International Conference on Machine Learning, San Francisco,CA: [s.n.], 1998.
[23] 寧亞輝,樊興華,吳渝. 基于領域詞語本體的短文本分類[J].計算機科學, 2009,03: 142-145.
[24] 王盛,樊興華,陳現麟. 利用上下位關系的中文短文本分類[J].計算機應用,2010,3(3): 603-606.
[25] 白秋產,金春霞.概念屬性擴展的短文本聚類算法[J].長春師范大學學報,2011,(10): 29-33.
[26] 史偉,王洪偉, 何紹義. 基于微博平臺的公眾情感分析[J].情報學報, 2012,31(11) : 1171-1178.
[27] Hong L and Davison B. Empirical study of topic modeling in twitter[C]//Proceedings of the First Workshop on Social Media Analytics, 2010:80-88.
[28] Weng J, Lim E, Jiang J, et al. Twitterrank: finding topic-sensitive influential twitterers[C]//Proceedings of the 3rd ACM international conference on Web search and data mining, 2010:261-270.
[29] Cheng Xueqi, et al. BTM: topic modeling over short texts[J]. IEEE Transactions on Knowledge and Data Engineering, 2014,26(12): 2928-2941.
[30] 漢字筆畫庫與拼音庫[EB/OL]. http://download.csdn.net/download/cshaoty/4295604.
[31] Yih W T, Toutanova K N, Meek C A, et al. Learning discriminative projections for text similarity measures[C]//Proceedings of the 15th conference on Computitional Natural Language Learning, portland, Oregon, USA, 2011:247-256.
[32] 搜狗開放實驗室(Sogou Labs)[EB/OL]. http://www.sogou.com/labs/.
ResearchonChineseCharacterEmbeddingBasedonItsInherentAttributes
HU Hao, LI Ping,CHEN Kaiqi
(Center of Intelligence and Networked System, School of Computer Science, Southwest Petroleum University, Chengdu, Sichuan 610500, China)
With the rapid development of Internet, Chinese short text has become increasingly im- portant. How to mining valuable information from massive short text has become a very important and challenging task in Chinese natural language processing. However, using the traditional methods which analyze long text often get bad results due to the sparsity of syntax and semantic. This paper proposed a Chinese word embedding method based on stroke, combined with deep learning of short text similarity calculation. This method combined Chinese word-building and its Pin-Yin attributes. The Chinese characters were mapped to a 32-dimensional vector. Then we used convolution neural network to extract the semantic of each short text and calculate similarity. Experimental results show that compared with the existing short text similarity calculation method, the method has greatly improved on performance and accuracy.
short text; Chinese word embedding; deep learning

胡浩(1990—),碩士研究生,主要研究領域為自然語言處理、深度學習。

李平(1977—),博士,副研究員,主要研究領域為網絡科學、統計機器學習、自然語言處理。

陳凱琪(1992—),碩士研究生,主要研究領域為自然語言處理、機器學習。
1003-0077(2017)03-0032-09
2016-04-26定稿日期: 2016-06-02
TP391
: A
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
