基于數據挖掘的網絡用戶興趣分類研究
2017-07-24 15:45:26張志強
電子設計工程 2017年10期
張志強
(西安外事學院 陜西 西安 710077)
基于數據挖掘的網絡用戶興趣分類研究
張志強
(西安外事學院 陜西 西安 710077)
在移動互聯網發展快速的今天,數據是最寶貴的資源之一,如何利用海量數據完成特定應用。本文基于數據挖掘技術實現網絡用戶興趣分類為用戶提供特定服務,設定合理的用戶興趣模型確保個性化服務優劣的核心。提出一種基于HITS算法通過用戶訪問量實現興趣分類的策略,通過網絡數據采集、模型分析完成對興趣數據的處理,得出了HITS在用戶興趣分類方面有較大的優勢。
移動互聯網;海量數據;數據挖掘;興趣分類
數據挖掘的基礎技術研究已經進展了將近十年,各類基于數據挖掘的應用服務已經得到了廣泛的推廣。對于互聯網的使用,如何實現面向用戶群的特定服務推廣是學者專家以及各類互聯網公司研究的熱點問題,本文提出了一種面向用戶興趣分類的移動互聯網數據分類算法。
1 概 述
數據挖掘技術的發展推進了移動互聯網應用的廣泛推廣,根據 CNNIC (China Internet Network Information Center)公布的統計結果表明,截止到2015年12月,中國網民規模達到6.88億,手機用戶也達到了1.27億,如何提升用戶上網感知度是當前互聯網研究的熱點問題。
網絡用戶興趣分類是指根據互聯網用戶的訪問點擊量來實現自動分類推薦功能,常見有通過統計關鍵詞、點擊鏈接等方式來統計用戶的興趣熱點,比如用戶輸入關鍵詞“蘋果”,有些用戶關注水果“蘋果”方面的知識,有些用戶關注“IPhone”等系列電子產品的知識,通過這種方式形成個性化服務。利用數據挖掘技術完成個性化服務的研究[5]。
當前對于興趣分類研究,國內外學者已經做了大量的研究工作,Cantador I[1]等人提出了一種從個人配置的語義信息文件中獲取用戶興趣的方法。主要策略是對用戶共享的這些語義信息文件進行聚類,得到若干類簇,并根據聚類結果,建立多層結果的興趣模型。Kramar T[2]等人提出了一種基于元數據的用戶興趣模型,其中元數據是由從用戶訪問的每個頁面提取的關鍵字,術語和標記等詞組與擴展的詞組合而成的序列。當用戶使用短語進行搜索時,可以根據這種擴展的詞組能準確的獲取用戶所需要的信息。Liu Z,Chen X[3]等人針對微博用戶發表的信息的嘈雜性和詞語的多樣性,提出一種將基于轉化的方法和基于頻次的方法相結合的關鍵詞提取方法來挖掘用戶的興趣。
文中提出一種利用數據挖掘技術實現網絡用戶興趣分類的應用模型,首先介紹了經典的HITS模型理論,從數據采集、理論分析等方面介紹模型的具體實現過程,并通過實驗分析了模型的性能特性。
2 HITS模型介紹
在互聯網搜索領域中,HITS(Hypertext Induced Topic Search)算法是一種重要的基于權重排序的互聯網數據搜索算法,HITS算法的核心是利用網頁設計中兩個通用的值:hub值與authority值,所謂hub值是由頁面所指向的所有網頁的authority值構成;而authority值由指向該頁面的所有網頁hub值構成。在互聯網應用中,通常采用較高權值的網頁更加傾向與其它相關網頁進行連接,換句話說,多個權值高的網頁若指向同一個未知網頁,那么該網頁具備更高權值的可能性會很大[5-7]。
HITS的邏輯實現過程如下公式如下所示,描述過程如下:假設在實際網絡中節點i在時刻t時的authority值由所有指向i節點在t-1時刻的hub值累加構成,如公式(1)所示,而公式(2)中表示節點i在時刻t的hub值由節點i所指向的所有節點的t-1時刻的authority值累加構成,而公式(3)和公式(4)是權值計算的迭代過程,經過 n次迭代后實現authority值和hub值的歸一化,直到排序結果趨于穩定后停止迭代。
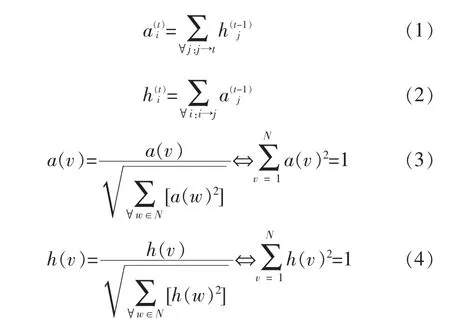
文中針對HITS模型在實際互聯網應用中存在的問題進行改進,傳統的HITS模型通常在網頁訪問中將hub中每一個指向的鏈接都將指定一個權重高的值,假若頁面中僅有1條鏈接,那么hub值會被傳遞給連接頁面的authority值,但如果一個頁面存在大量的連接時,將會有大量的hub值被傳遞給頁面的authority值,這顯然是不符合實際應用情況的。為此本文對公式(2)提出進行了修改,如公式(5)所示,在模型中增加了網絡流的方向性,Oi,out表示用戶i的出度。
2.1 數據采集
數據采集主要完成模型數據的采集工作,通過對互聯網上所關注用戶-數據的抓取,利用文獻[4]中所提的HTML頁面數據收集算法,通過wireshark網絡工具采集具體的數據信息。采集結果如表1所示。

表1 數據采集結果
通過將用戶瀏覽的html頁面內容表示成文本的特征向量形式,作為數據預處理的過程,便于后續模型的使用。
2.2 模型實現
文中通過Hadoop框架進行模型的實現設計,通過IE瀏覽器實現搜索引擎的連接,在Hadoop的編程框架中利用MapReduce函數匹配搜索引擎并進行分析處理[6]。在Map階段對數據進行預處理,去除字段不完整的記錄,按照設定的規則拆分相應字段,用于匹配各個搜索引擎的Host字段,然后根據各個搜索引擎的特點,進行相應的解碼[10]。采取這種處理模式,實現了對多個搜索引擎(也可認為是多業務輸出的目的)的處理,偽代碼如下:
2.3 實驗驗證


在本節中,我們評估使用相應的測試集本文提出的分類器的性能。該實驗基于SVM根據該信息在個人網站發布的用戶的消費意愿進行分類。本章中所使用的所有數據均來自Amazon.com。
在亞馬遜的網站有10個大類和60多萬的采購數據,這些數據從數字設備選定表1所示。從所有的采購數據,2 000條記錄,隨機拿起本實驗中使用amazon.com的數據類別。我們刪除了這些短信息,最后剩下的是第1 898個標記后,我們獲得了990個消費意圖的信息和908個沒有信息消費的意圖[11-15]。
通過獲人工標注的方法得測試數據,我們從個人網站隨機抽取的發布信息的記錄。然后手動注明這些記錄是否與消費興趣相關,依照本文提出的分類算法得出如表3所示的分類結果。
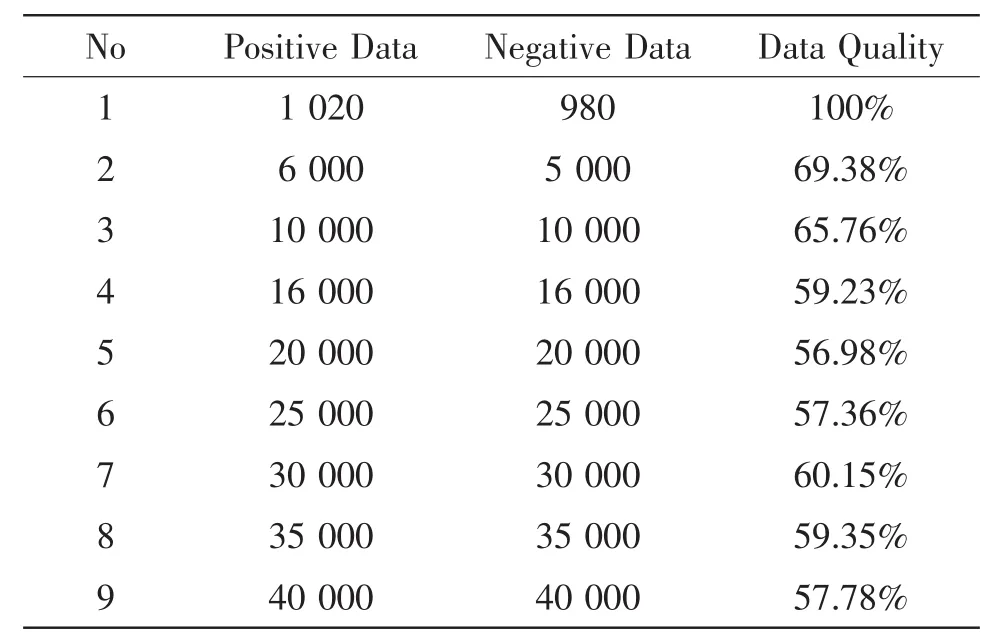
表2 測試數據
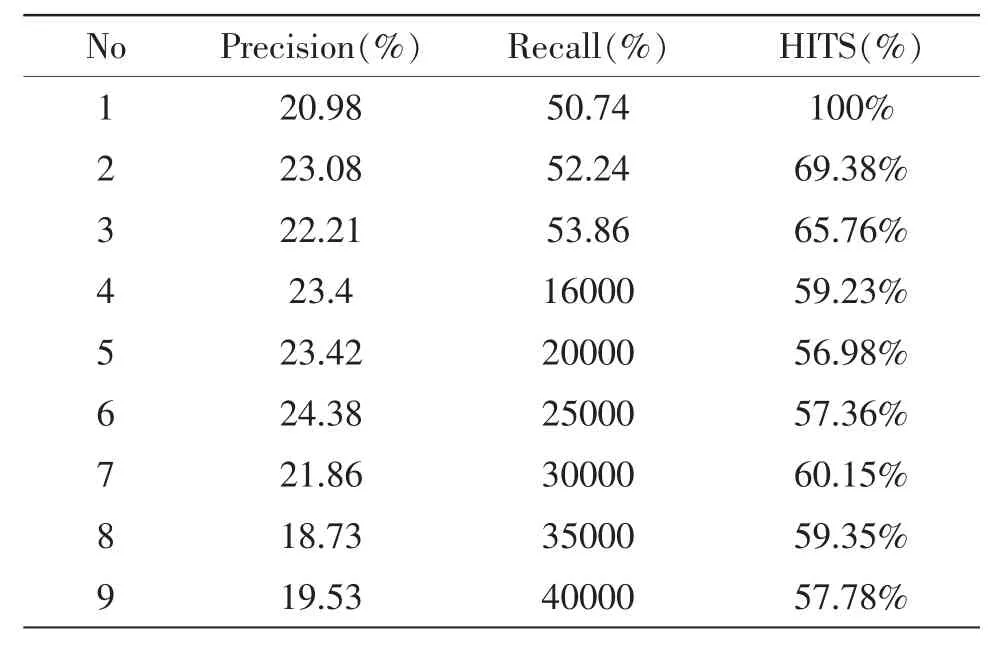
表3 改進的HITS分類性能
通過該測試結果顯示在本文提出HITS算法在網絡用戶興趣分類上有明顯的應用效果。
3 結 論
文中利用數據挖掘的思想設計實現了用于解決互聯網用戶興趣分類的研究,利用經典的HITS算法的迭代思想,對算法進行部分改進實現,并且按照數據采集、模型實現,采用Hadoop的挖掘框架完成整個模型的設計,實驗證明模型的性能的優勢。
[1]Cantador I,Castells R.Extracting multilayered communities of Interest from semantic user profiles:Application to group modeling and hybrid recommendations[J].Computers in Human Behavior,201l,27(4):1321-1336.
[2]Kramar T,Barla M,Bielikovi M.Personalizing search using socially enhanced interest model builtfrom the stream of User’S activity[J].J.Web Eng.,2013,12(1&2):65-92.
[3]Liu Z,Chen X,Sun M.Mining the interests of Chinese microbloggers via keyword extraction[J],Frontiers of Computer Science,2012,6(1):76-87.
[4]梅佩.基于瀏覽內容的用戶興趣研究[M].北京:北京交通大學,2015.
[5]陳如明.大數據時代的挑戰,價值與應對策略[J].移動通信,2012(17):14-15.
[6]陳吉榮,樂嘉錦.基于Hadoop生態系統的大數據解決方案綜述 [J].計算機工程與科學,2013,35(10):25-35.
[7]Liu C, Zhou W X.Heterogeneity in initial resource configurationsimproves a networkbasedhybrid recommendation algorithm[J].Physica A:Statistical Mechanics and itsApplications,2012,391(22):5704-5711.
[8]Nacher J C,Akutsu T.On the degree distribution of projected networks mapped frombipartite networks[J].Physica A:Statistical Mechanics and its Applications,2011,390(23):4636-4651.
[9]Pieter N,Michiel H.Mining twitter in the Cloud: A Case Study [C]//CLOUD 2010,Miami,FL,United states, IEEE Computer Society, 2010: 107-114.
[10]Abraham R,Martinez T.Twitter:Network properties analysis[C]//CONIELECOMP 2010,Cholula Puebla,Mexico,IEEE Computer Society,2010:180-184.
[11]余肖生,孫珊.基于網絡用戶信息行為的個性化推薦模型 [J].重慶理工大學學報自然科學版,2013,27(1):47-50.
[12]Garcia L M.Programming with Libpcap Sniffing the Network From OurOwn Application[J]. Hakin9-ComputerSecurityMagazine,2008:2-2008.
[13]XurenW,Famei H,An implement of broadband network monitoring system based on libnidsand winpcap [C]//New Trendsin Information and Service Science,2009-NISS!09.International Conference on.IEEE,2009:812-814.
Research on data mining classification based on user interest
ZHANG Zhi-qiang
(Xi'an International University,Xi'an 710077,China)
In today's rapid development of mobile Internet,data is the most precious resources,how to use the vast amounts of data to complete a specific application.Thispaperproposedthatthedata mining technology network user interest classification is to provide users with a particular service,andset a reasonable user interest model is to ensure that the core of personalized service merits.Also presenting a user views HITS algorithm to achieve the classification of interest policy,through the network data collection,analysis model to complete the processing of the data of interest,and by examples demonstrate obtain the advantages of the policy.
mobile Internet;vast amounts of data;data mining;classification of Interest
TN929.5
A
1674-6236(2017)10-0034-04
2016-07-18稿件編號:201607130
教育部信息管理中心項目(EIJYB2015053);西安市專項基金項目(16IN08)
張志強(1978—),男,河南許昌人,碩士,講師。研究方向:數據挖掘、云計算、計算機網絡。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
電子設計工程(2014年18期)2014-02-27 12:00:13
