基于大數據的數據挖掘引擎研究
2017-09-03 10:13:56王小燕張麗敏
電子設計工程 2017年15期
王小燕,張麗敏
(1.陜西廣播電視大學 陜西 西安 710119;2.西安外事學院 信息與網絡學院,陜西 西安 710077)
基于大數據的數據挖掘引擎研究
王小燕1,張麗敏2
(1.陜西廣播電視大學 陜西 西安 710119;2.西安外事學院 信息與網絡學院,陜西 西安 710077)
為了解決數據挖掘在大數據中存在的問題,文中對大數據下的數據挖掘引擎進行了研究,以Spark作為核心引擎,并在Spark的內存計算算子的基礎上,實現了多個傳統數據挖掘算法的并行計算,使得傳統的數據挖掘算法能在集群環境中并行運行,從而在大數據中得到較好的應用。然后通過系統分層方法,將數據挖掘系統進行分層設計,實現了一個完整的大數據挖掘平臺。實驗表明,基于Spark實現的Apriori算法跟PageRank算法的并行計算能有效減少執行時間,在大數據挖掘上具有較好的應用。
大數據;數據挖掘;Spark;引擎
由于計算機的普及以及網絡的發展,互聯網在人們的日常生活與工作中應用越來越廣泛,每天均有大量的人在使用互聯網,同時也產生了大量的數據。隨著時間的推移,人們積累的數據量越來越多,規模高達TB級甚至PB級。為了取得這些數據中的有用信息,人們利用各種數據挖掘算法來挖掘其中的潛在價值。雖然數據挖掘在小數據集上的應用具有較好的效果,但對于大數據集而言,數據挖掘算法在執行效率,算法并行化及平臺易用性等存在問題[1-5]。
為了解決上述問題,文中對大數據下的數據挖掘引擎進行了研究,以Spark作為核心引擎,并在Spark的內存計算算子的基礎上,實現了多個傳統數據挖掘算法的并行計算,使得傳統的數據挖掘算法能在集群環境中并行運行,從而在大數據中得到較好的應用。然后通過系統分層方法,將數據挖掘系統進行分層設計,實現了一個完整的大數據挖掘平臺。
1 基于Spark的并行數據挖掘算法
Spark是一種開源集群計算環境,與Mahout相比,其擁有更快的計算速度,更適用于大數據的數據挖掘中,因此將其選為數據挖掘的核心引擎。由于Spark所提供的數據挖掘算法覆蓋量較少,例如缺少Apriori算法和PageRank算法。為了使Spark能成為核心引擎,本文在Spark的基礎上實現了Apriori算法和PageRank算法的并行執行。
1.1 Spark編程模型
Spark[6-7]主要有兩個特點,首先是彈性分布式數據集(RDD),其將集群中的節點內存全部組織起來,從而使所有節點內存能并行使用。RDD的建立一方面可通過加載HDFS文件來實現,也可由轉換現有的RDD來得到。用戶可將指定的RDD緩存在內存中,從而在再次使用時可免去創建過程,提升速度。
另一個特點是變量共享功能。Spark能在不同節點執行的任務中對共享向量進行拷貝,其能夠在并行計算中使用。Spark的共享變量主要有廣播變量及累加器變量,廣播變量用于將一個值緩存到所有節點內存中,累加器變量執行累加功能。
1.2 Apriori算法
Apriori算法[8-9]是一種關聯規則算法,其功能為挖掘大數據中事件的關聯性,篩選出關聯性大于預設閾值的事件,主要用于分析用戶的消費行以及為商業政策的制定提供可行性分析等。設定事件A與B同時發生的概率為支持度,事件項集支持度大于預設值稱為頻繁項集,Apriori算法的工作步驟為:
1)掃描數據庫,計算每個事件集的支持度,并將支持度小于預設值的事件集篩選掉,得到頻繁項集L1。
2)將頻繁項集的元素兩兩結合為一個事件項,形成新的事件項集。
3)將支持度小于預設值的事件集篩選掉,得到頻繁項集Lk。
4)重復執行步驟 2)、3),直到不能形成新的事件項集。
1.3 PageRank算法
PageRank算法[10-11]是一種對網頁搜索結果進行排序的算法,其工作原理為,以所有鏈接到某一網頁的鏈接數作為該網頁的支持度,對于一次搜索行為后,計算每一個搜索結果網頁的支持度,并按照支持度從大到小的順序對搜索結果進行排序。
2 系統設計
2.1 系統架構設計
本文的數據挖掘系統架構[12-15]如圖1所示,從底往上分別分為引擎層、中間層以及用戶層。引擎層為系統的最低層,其作為系統的數據處理引擎,以Spark集群為主體,并通過Zookeeper實現集群配置管理,以及使用Mesos對資源進行調度,封裝常見的數據接入接口。中間層包括對(RPC)接口的遠程調用以及多用戶并發的控制請求。用戶層主要包含開發套件和可視化控件等。
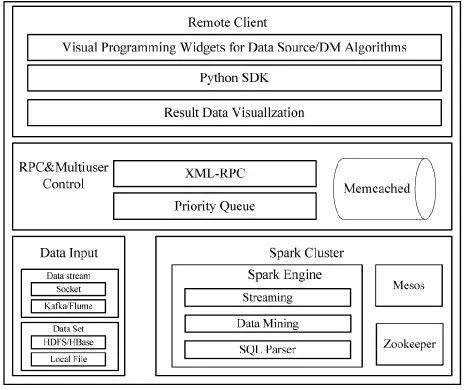
圖1 系統整體架構圖
2.2 引擎層
引擎層是整個數據挖掘系統的核心部分,其擔負著系統的數據處理引擎。引擎層運行在Linux集群環境下,文中使用的是Ubuntu 16.04 64位系統。引擎層以spark集群為核心,通過Zookeeper實現集群配置管理,并使用Mesos對資源進行調度,封裝常見的數據接入接口,包括Kafka,Flume等。此外,引擎層還具有3個組件,包括Spark SQL、數據挖掘算法包及Spark Streaming。Spark SQL用于處理結構化大數據;數據挖掘算法包用于提供數據挖掘算法,包括前文介紹的Apriori算法和PageRank算法;Spark Streaming用于處理流式數據。
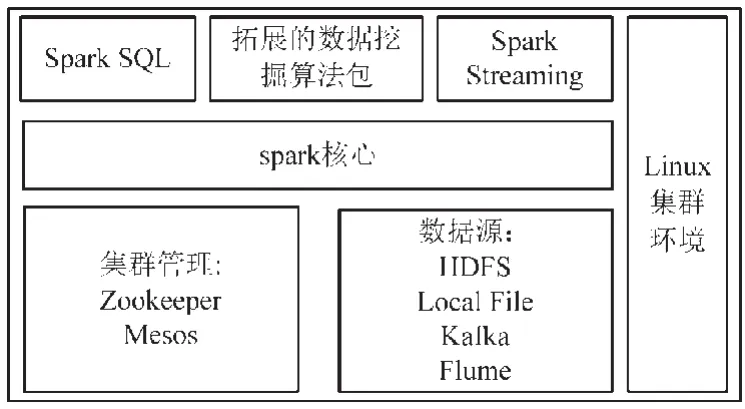
圖2 引擎層設計圖
2.3 中間層
中間層負責對(RPC)接口的遠程調用以及多用戶并發的控制請求。RPC(Remote Procedure CallProtocol),即遠程過程調用協議,其是一種通過網絡從遠程計算機程序上請求服務,而無需要了解底層網絡技術的協議。RPC能夠使用戶免去登錄到集群環境中進行操作的環節而直接在本地進行調用,減去了提交大數據計算任務的環節。由于RPC由Python語言編寫,因而選用Python的xml-rpc,其工作過程如圖3所示。
首先是用戶發起調用請求后,數據將被封裝為xml的格式,然后通過HTTP的post方法,將xml格式的數據傳播給rpc服務端,服務端解析xml數據,執行相關指令后,將結果以xml格式返回給調用端。
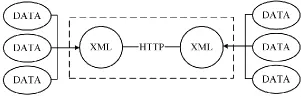
圖3 xml-rpc處理過程
為了滿足同一時間不同用戶的需求,引入隊列作為請求的存儲結構,對任務進行優先級排序。用戶請求調度過程如圖4所示,中間層在接收到一個RPC調用時,先判斷是否為getModel調用,若是將調用從Memcached取出執行,并將結果返回給用戶層。若不是getModel調用,判斷是否為Schedule調用,若為Schedule調用,則將調用標記為KEY鎖定并放入到候選隊列中等候執行;若不是Schedule調用,則不執行調用。
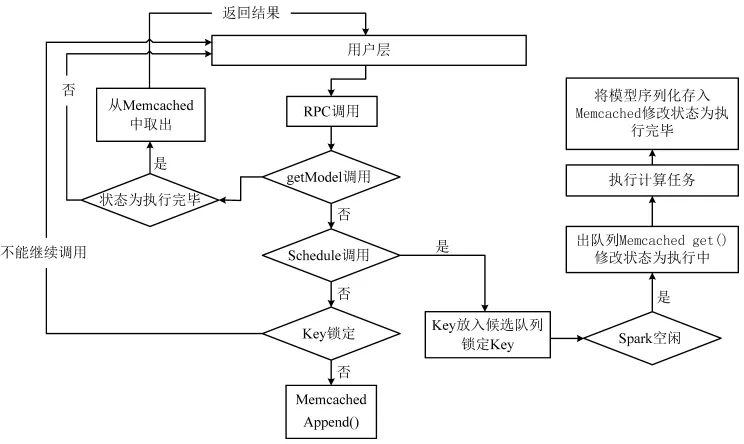
圖4 中間層流程圖
3 實驗測試
文中在惠普Precision T5810工作站上搭建實驗平臺,處理器為Intel E5-1620處理器,主頻3.5GHz,內存16G,硬盤1TB。在工作站上建立虛擬機,系統環境為Ubuntu 16.04 64位系統,完成Spark分布式環境的搭建。本文通過實驗來比較以MapReduce及以Spark為基礎的Apriori算法和PageRank的并行化執行效率,其中數據集采用大小分別為20MB,30MB,70MB,100MB 的 Note Dame,Stanford,Google以及Berkeley-Stanford數據集,對于頻繁項分析,本文采用T10I4D100K.數據集,實驗結果如圖5~8所示。
由圖5,圖7可看出,不管是Apriori算法還是PageRank算法,本文提出的基于Spark的內存計算算子實現的數據挖掘算法的并行計算,其平均執行時間遠小于MapReduce的平均執行時間。隨著數據量的增加,基于MapReduce的數據挖據算法執行時間成線性增長,且斜率較大。而基于Spark的數據挖掘算法執行時間增長緩慢,并未發生較大變化。這是由于Spark基于內存進行計算的,其將每次迭代結果均緩存在內存中,因而能直接讀取,減少了從硬盤讀取數據的時間。
其次,隨著Slave節點的增加,基于Spark的數據挖掘算法Apriori和PageRank算法的執行時間呈線性下降,說明這兩種算法均能較好地進行算法的并行計算。
4 結束語
基于大數據的數據挖掘算法其在執行效率,算法并行化以及平臺易用性等存在問題。為了解決這些問題,本文對大數據下的數據挖掘引擎進行了研究,以Spark作為核心引擎,并在Spark的內存計算算子的基礎上,實現了多個傳統數據挖掘算法的并行計算,使得傳統的數據挖掘算法能在集群環境中并行運行,從而在大數據中得到較好的應用。然后通過系統分層方法,將數據挖掘系統進行分層設計,實現了一個完整的大數據挖掘平臺。實驗表明,基于Spark實現的Apriori算法跟PageRank算法的并行計算能有效減少執行時間,在大數據挖掘上具有較好的應用。
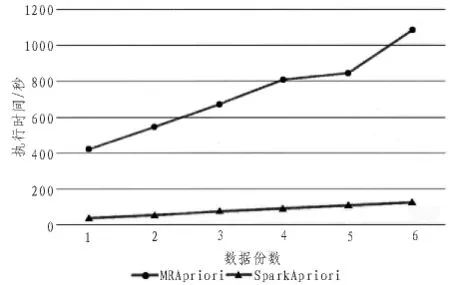
圖5 并行化Apriori算法的數據規模實驗結果
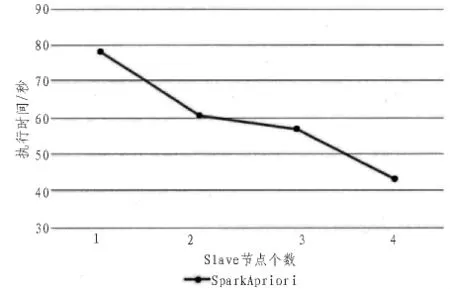
圖6 并行化Apriori算法的集群規模實驗結果
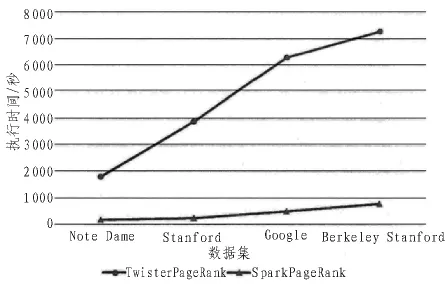
圖7 并行化PageRank算法的數據規模實驗結果
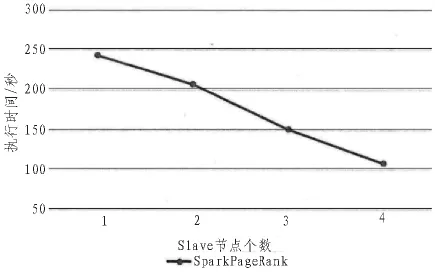
圖8 并行化PageRank算法的集群規模實驗結果
[1]Gheraawat S,Gobioff H,Leung ST.The Google file system [C].ACM SIGOPS Operating Systems Review.ACM, 2003,37(5):29-43.
[2]Dean J,Ghemawat S.MapReduce:simplified data processing on large chisters[J].Communications of the ACM,2008,51(1):107-113.
[3]Chang F,Dean J,Ghemawat S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems(TOCS),2008,26(2):4.
[4]Taylor R C.An overview of the Hadoop/Map Reduce/HBase framework and its current applications in bioinformatics[J].BMC bbinformatics,2010,ll(Suppl 12):S1.
[5]McKenna A, Hanna M, Banks E,et al.The Genome Analysis Toolkit:aMapReduce framework for analyzing next-generation DNA sequencing data[J].Genome research^2010,20(9):1297-1303.
[6]胡俊,胡賢德,程家興.基于Spark的大數據混合計算模型[J].計算機系統應用,2015(4):214-218.HU Jun,HU Xiande,CHENG Jiaxing.Spark Big Data hybrid computing model[J].Computer Systems&Applications,2015(4):214-218.
[7]王虹旭,吳斌,劉旸.基于Spark的并行圖數據分析系統[J].計算機科學與探索,2015,9(9):1066-1074.
[8]崔貫勛,李梁,王柯柯,等.關聯規則挖掘中Apriori算法的研究與改進[J].計算機應用,2010,30(11):2952-2955.
[9]栗青霞,王換換,傅喆.改進的Apriori算法在試題關聯分析中的應用[J].電子科技,2014,27(2):35-38.
[10]李稚楹,楊武,謝治軍.PageRank算法研究綜述[J].計算機科學,2011(s1):185-188.
[11]錢功偉,倪林,MIAO,等.基于網頁鏈接和內容分析的改進PageRank算法[J].計算機工程與應用,2007,43(21):160-164.
[12]余永紅,向曉軍,高陽,等.面向服務的云數據挖掘引擎的研究[J].計算機科學與探索,2012,6(1):46-57.
[13]張英朝,鄧蘇,張維明,等.智能數據挖掘引擎的設計與實現[J].計算機科學,2002,29(10):11-13.
[14]姚全珠,張杰.基于數據挖掘的搜索引擎技術[J].計算機應用研究,2006,23(11):29-30.
[15]陳勇,張佳驥,吳立德,等.基于數據挖掘的面向話題搜索引擎研究[J].無線電通信技術,2011,37(5):38-40.
Research on data mining engine based on big data
WANG Xiao-yan1,ZHANG Li-min2
(1.Shaanxi Radio and TV University, Xi'an 710119,China; 2.Xi'an Institute of Foreign Affairs and Network Information Institute, Xi'an 710077, China)
In order to solve the problem of data mining in large data,the data of the large-scale data mining engine is studied, using Spark as the core engine, and in the memory of Spark operator on the basis of the implementation of a number of traditional data mining algorithms of parallel computing,the traditional data mining algorithm can run in parallel in a cluster environment,so as to obtain the very good application in big data.Then through the system layering method,the data mining system is designed,and a complete big data mining platform is realized.Experimental results show that the Apriori algorithm based on Spark algorithm and PageRank algorithm can effectively reduce the execution time,and it has a good application in large data mining.
big data; data mining; Spark;engine
TN99
:A
:1674-6236(2017)15-0031-04
2016-09-17稿件編號:201609153
陜西省教育廳科研項目(16JK2176);陜西工商職業學院2015年度教學改革研究項目(GJ1510)
王小燕(1982—),女,陜西西安人,碩士,工程師。研究方向:軟件工程。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
大眾投資指南(2021年35期)2021-02-16 01:06:26
北京測繪(2020年12期)2020-12-29 01:33:58
商周刊(2017年22期)2017-11-09 05:08:31
家庭影院技術(2017年9期)2017-09-26 03:41:45
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
