
基于神經(jīng)網(wǎng)絡(luò)的車牌字符識別系統(tǒng)研究
2017-09-13 08:37:33劉濱
求知導(dǎo)刊 2017年19期
劉濱


車輛牌照識別(Vehicle License Plate Recognition,VLPR)技術(shù)作為交通信息服務(wù)系統(tǒng)的重要手段,主要任務(wù)是分析處理汽車圖像,自動識別汽車牌照。一個(gè)好的VLPR系統(tǒng),能夠從一幅圖像中自動提取車牌圖像,自動分割字符圖像,進(jìn)而對字符進(jìn)行正確識別。隨著計(jì)算機(jī)視頻技術(shù)和模式識別技術(shù)的發(fā)展,車牌自動識別系統(tǒng)已成為智能交通系統(tǒng)的重要組成部分。
一、字符網(wǎng)格特征的提取
構(gòu)造一個(gè)高性能的識別系統(tǒng),最主要的是如何選擇有效的特征。任何一個(gè)特征都是從某個(gè)角度刻畫圖像的,不可能十全十美,因此,必須用多種特征互相補(bǔ)償,才能達(dá)到良好的效果。選取字符特征應(yīng)滿足如下條件:①所選特征必須足以區(qū)分各字符,特征應(yīng)該穩(wěn)定,受字形影響越小越好。②所選特征應(yīng)便于提取,便于用計(jì)算機(jī)實(shí)現(xiàn),特征維數(shù)應(yīng)盡可能少。③所選特征之間應(yīng)具有補(bǔ)償性,即各種特征能從不同角度描述一幅圖像,以達(dá)到全面反映圖像信息的目的。
依據(jù)以上原則,本文選取改進(jìn)的字符粗網(wǎng)格特征作為所識別字符的特征。
設(shè)f(i,j)是漢字規(guī)一化后N×N大小的二值化點(diǎn)陣圖像:
黑像素1表示該點(diǎn)有筆畫,白像素0表示該點(diǎn)沒有筆畫。
粗網(wǎng)格特征提取方法是指先把待識別字符進(jìn)行大小和位置規(guī)一化,再等分為N×N個(gè)網(wǎng)格,然后依次統(tǒng)計(jì)各網(wǎng)格內(nèi)的黑像素(或白像素)的數(shù)量,取得一個(gè)以數(shù)值表示的N×N維的網(wǎng)格特征。粗網(wǎng)格特征屬于統(tǒng)計(jì)特征中的局部特征,又稱局部灰度特征,反映了字符的整體形狀分布,但抗位置變化能力較差,即字符的傾斜、偏移等導(dǎo)致對應(yīng)網(wǎng)格之間的錯位,會大大降低字符識別的正確率。考慮到車牌字符識別屬于小分類問題,為了同時(shí)保留字符的整體結(jié)構(gòu)特征和細(xì)節(jié)特征,本文充分利用神經(jīng)網(wǎng)絡(luò)所具有的并行處理能力及其隱藏層所具有的提取特征的能力,將歸一化后字符點(diǎn)整的每個(gè)像素點(diǎn)作為一個(gè)網(wǎng)格,即提取字符的原始特征,將其直接輸入神經(jīng)網(wǎng)絡(luò)分類器,再對該字符進(jìn)行分類的粗網(wǎng)格特征提取方法。
待識別的數(shù)字字符“0”如圖1所示,按32×16的比例尺寸歸一化后字符“0”點(diǎn)陣如圖2所示,字符“D”點(diǎn)陣如圖3所示。
在車牌字符識別時(shí),這種字符圖像不可避免會存在噪聲環(huán)境,對于形如0和D這種形狀極其相似的字符,有時(shí)仍會發(fā)生混淆。根據(jù)車牌字符規(guī)范,設(shè)計(jì)字母數(shù)字神經(jīng)網(wǎng)絡(luò)分類器,對9個(gè)數(shù)字和除I以外的25個(gè)英文大寫字母進(jìn)行分類識別。經(jīng)過初步測試,字母數(shù)字神經(jīng)網(wǎng)絡(luò)分類器對字母O、B、C、D、U識別時(shí)經(jīng)常混淆。因此,可將字母數(shù)字神經(jīng)網(wǎng)絡(luò)分類器設(shè)計(jì)為2級神經(jīng)網(wǎng)絡(luò)分類器,即在原字母數(shù)字神經(jīng)網(wǎng)絡(luò)分類器的下一級增加一個(gè)細(xì)分類器,完成字母O、B、C、D、U的分類。最后對被識別為O和D的識別樣本,提取左上角和左下角的粗網(wǎng)格特征加以區(qū)別。通過對粗網(wǎng)格特征提取方法加以改進(jìn),數(shù)字字母神經(jīng)網(wǎng)絡(luò)分類器的正確識別率非常高。
二、BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計(jì)
BP神經(jīng)網(wǎng)絡(luò)是采用誤差反向傳播算法對網(wǎng)絡(luò)權(quán)值進(jìn)行訓(xùn)練的多層前向網(wǎng)絡(luò)(如圖4所示)。BP神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)的最大特點(diǎn)是網(wǎng)絡(luò)的權(quán)值是通過使網(wǎng)絡(luò)輸出與樣本輸出之間的誤差平方和達(dá)到期望值而不斷調(diào)整網(wǎng)絡(luò)的權(quán)值訓(xùn)練出來的。進(jìn)行神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)的首要任務(wù)是網(wǎng)絡(luò)結(jié)構(gòu)的確定,包括輸入/輸出神經(jīng)元個(gè)數(shù)、隱含層個(gè)數(shù)、隱含層中神經(jīng)元數(shù)目以及每層傳遞函數(shù)的確定。一般情況下,神經(jīng)網(wǎng)絡(luò)的輸入層與輸出層的神經(jīng)元數(shù)目由問題本身的性質(zhì)決定,隱含層的層數(shù)及各隱藏層的神經(jīng)元數(shù)目需要由設(shè)計(jì)者根據(jù)問題的性質(zhì)和對神經(jīng)網(wǎng)絡(luò)的性能要求決定。
一般的車牌共有7個(gè)字符,其中第一個(gè)字符是省份(自治區(qū)、直轄市)的漢字簡稱,第二個(gè)字符是字母,第三至第七位字符是字母或漢字。實(shí)驗(yàn)表明,BP神經(jīng)網(wǎng)絡(luò)對小類別字符集有較高的識別率,因此在車牌字符識別系統(tǒng)中分別設(shè)計(jì)漢字網(wǎng)絡(luò)、字母網(wǎng)絡(luò)和數(shù)字字母網(wǎng)絡(luò),可實(shí)現(xiàn)對字符的分類。
輸入層神經(jīng)元個(gè)數(shù)由待識別字符所取得的網(wǎng)格像素特征的維數(shù)大小確定。在本系統(tǒng)中,對歸一化為32×16點(diǎn)陣大小的字符,以每一個(gè)像素點(diǎn)為一個(gè)網(wǎng)格,故輸入層神經(jīng)元個(gè)數(shù)取512。
神經(jīng)網(wǎng)絡(luò)輸出層神經(jīng)元個(gè)數(shù)由設(shè)計(jì)網(wǎng)格時(shí)所采用的輸出表示和決策規(guī)則所確定。以模式樣本和它的類別標(biāo)記做訓(xùn)練,采用“M中取1”的方式表示目標(biāo)向量。因此,網(wǎng)絡(luò)輸出層神經(jīng)元的數(shù)目即為待識別的類別數(shù)M,輸出層的每一個(gè)神經(jīng)元代表一個(gè)目標(biāo)種類。神經(jīng)網(wǎng)絡(luò)均使用Logistic函數(shù)作為激活函數(shù),各網(wǎng)絡(luò)輸出層神經(jīng)元個(gè)數(shù)如表1所示。
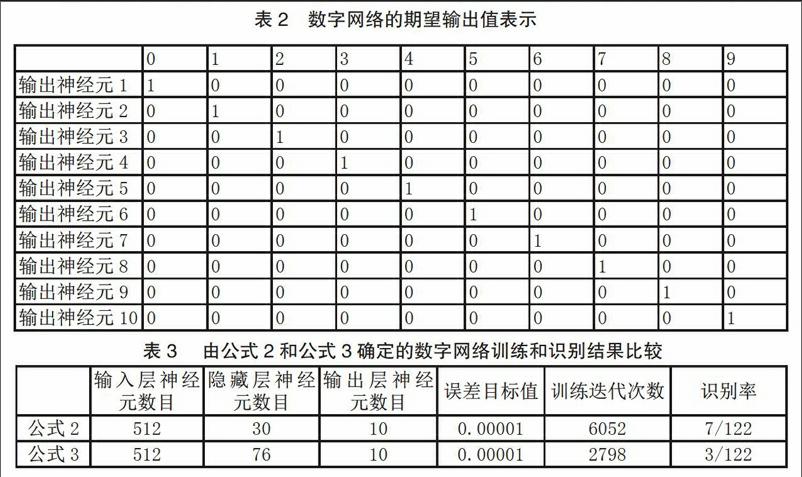
以數(shù)字網(wǎng)絡(luò)為例,其期望輸出值表示如表2所示。
本系統(tǒng)的神經(jīng)網(wǎng)絡(luò)所處理的都是小類別的分類問題,采用具有一個(gè)隱藏層的三層BP神經(jīng)網(wǎng)絡(luò)。
隱藏層神經(jīng)元數(shù)目太多,計(jì)算復(fù)雜度增加,網(wǎng)絡(luò)訓(xùn)練收斂速度降低,網(wǎng)絡(luò)訓(xùn)練時(shí)間過長。隱藏層神經(jīng)元數(shù)目太少,訓(xùn)練網(wǎng)絡(luò)時(shí)可能陷入局部極小點(diǎn)。在本系統(tǒng)的研制過程中,先后采用下面三個(gè)公式確定隱藏層神經(jīng)元個(gè)數(shù):
式中,h_num表示隱藏層神經(jīng)元個(gè)數(shù),i_num表示輸入層神經(jīng)元個(gè)數(shù),o_num表示輸出層神經(jīng)元個(gè)數(shù)。
采用公式(1)確定數(shù)字網(wǎng)絡(luò)的隱藏層神經(jīng)元個(gè)數(shù)為h_num=2525,個(gè)數(shù)太大;網(wǎng)絡(luò)在訓(xùn)練過程中經(jīng)過數(shù)次運(yùn)算,就使輸出神經(jīng)元處于飽和狀態(tài),網(wǎng)絡(luò)各次輸出誤差的差別太小,導(dǎo)致網(wǎng)絡(luò)不能訓(xùn)練。
分別采用公式(2)和公式(3)確定的數(shù)字網(wǎng)絡(luò)訓(xùn)練和識別,結(jié)果比較如表3所示。
由表3可見,隱藏層神經(jīng)元個(gè)數(shù)較少,網(wǎng)絡(luò)訓(xùn)練困難,且識別率有所下降。故本論文各神經(jīng)網(wǎng)絡(luò)均采用公示3確定網(wǎng)絡(luò)隱藏層神經(jīng)元數(shù)目(如表4所示)。
車牌字符識別系統(tǒng)中各神經(jīng)網(wǎng)絡(luò)分類器所處理的都是小類別分類,最多的漢字網(wǎng)絡(luò)為51個(gè)漢字字符,為簡單起見,采用Logistic函數(shù)作為激活函數(shù)。以數(shù)字網(wǎng)絡(luò)為例,激活函數(shù)為:
輸出誤差目標(biāo)取值0.02,對數(shù)字網(wǎng)絡(luò)進(jìn)行訓(xùn)練,經(jīng)過115次迭代,輸出誤差達(dá)到目標(biāo)值,訓(xùn)練完成。endprint
網(wǎng)絡(luò)突觸權(quán)值和閾值初值的一個(gè)較好的選擇對一個(gè)成功的網(wǎng)絡(luò)設(shè)計(jì)會有較大的幫助。過大或過小的初始化突觸權(quán)值都應(yīng)該避免,恰當(dāng)?shù)某跏蓟x擇應(yīng)位于這兩種極端之間。設(shè)置突觸權(quán)值和閾值初始值是為了使網(wǎng)絡(luò)能夠快速和均衡地學(xué)習(xí)。對于一個(gè)有d個(gè)輸入神經(jīng)元的網(wǎng)絡(luò),輸入層到隱藏層的突觸權(quán)值選取在 之間。對隱藏層到輸出層的突觸權(quán)值,若隱藏層神經(jīng)元個(gè)數(shù)為nH,隱藏層到輸出層的權(quán)值初始值應(yīng)該在
之間。
三、BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練
對設(shè)計(jì)好的BP網(wǎng)絡(luò)的訓(xùn)練直接關(guān)系到最后的識別正確率。對于一個(gè)給定的訓(xùn)練集,反向傳播學(xué)習(xí)可以采用串行方式和集中方式進(jìn)行。以在線運(yùn)行的觀點(diǎn),由于是以隨機(jī)方式給定網(wǎng)絡(luò)的訓(xùn)練模式,利用一個(gè)模式接一個(gè)模式的方法更新權(quán)值,使得在權(quán)值空間的搜索自然具有隨機(jī)性,降低了陷入局部最小的可能性。
訓(xùn)練樣本的選取對網(wǎng)絡(luò)的分類和泛化能力也有很大影響。在車牌字符識別系統(tǒng)中,為每一類字符所選取的訓(xùn)練樣本必須能真實(shí)反映該類字符的共同特征。對于本文所研究的車牌字符的識別,由于受攝像機(jī)的性能、車牌的整潔度、光照條件、拍攝時(shí)的傾斜角度以及車輛運(yùn)動等因素的影響,牌照中的字符幾乎不可避免會因?yàn)槌霈F(xiàn)比較嚴(yán)重的模糊、歪斜、缺損或污跡現(xiàn)象而受到干擾。這就使得經(jīng)過車牌定位、字符分割等處理后得到的字符點(diǎn)陣經(jīng)常存在一些噪聲以及不同程度的傾斜現(xiàn)象。對于一些結(jié)構(gòu)較復(fù)雜、筆畫較多的字符,還會出現(xiàn)一些筆畫粘連的情況。本位采取為筆畫較多、結(jié)構(gòu)較復(fù)雜的字符如鄂、贛、湘等同時(shí)建立2個(gè)或3個(gè)訓(xùn)練樣本:標(biāo)準(zhǔn)樣本、典型粘連樣本和典型偏移樣本,同時(shí)訓(xùn)練,可極大提高字符識別正確率。
四、車牌字符識別系統(tǒng)
本文針對車牌字符的特點(diǎn),采用基于字符網(wǎng)格特征的BP神經(jīng)網(wǎng)絡(luò)分類器對車輛字符進(jìn)行分類,使用Visual C++編程,可完善車牌字符識別系統(tǒng)。
首先將整個(gè)BP網(wǎng)絡(luò)車牌字符識別系統(tǒng)設(shè)計(jì)為一個(gè)類CBP,包括BP車牌識別系統(tǒng)的所有函數(shù)(功能)。由于三層BP前饋網(wǎng)絡(luò)結(jié)構(gòu)較復(fù)雜,定義一個(gè)類CBPNet封裝BP網(wǎng)絡(luò)結(jié)構(gòu)。BP網(wǎng)絡(luò)的運(yùn)行主要有訓(xùn)練過程和識別過程。訓(xùn)練過程由函數(shù)Train()實(shí)現(xiàn),識別過程由函數(shù)Recognise(char *filename)實(shí)現(xiàn)。
訓(xùn)練的基本過程可采取以下步驟:
(1)定義一個(gè)BP網(wǎng)絡(luò)結(jié)構(gòu): CBPNet *bpnet,確定輸入層、隱藏層和輸出層神經(jīng)元個(gè)數(shù)。
(2)初始化一個(gè)隨機(jī)數(shù)種子:調(diào)用initialize(int seed)函數(shù)初始化隨機(jī)數(shù)種子。
(3)創(chuàng)建BP網(wǎng)絡(luò):調(diào)用creat(int n_in,int n_hidden,int n_out)函數(shù)創(chuàng)建一個(gè)BP網(wǎng)絡(luò),其中n_in,n_hidden,n_out分別為BP網(wǎng)絡(luò)輸入層、隱藏層和輸出層的神經(jīng)元個(gè)數(shù)。
(4)將輸入模式傳遞給創(chuàng)建的BP網(wǎng)絡(luò):事先將標(biāo)準(zhǔn)訓(xùn)練樣本保存在文件train.txt中,每個(gè)標(biāo)準(zhǔn)訓(xùn)練樣本以NN_RESX行NN_RESY列的矩陣形式存儲。定義目標(biāo)向量,調(diào)用Train()函數(shù)訓(xùn)練創(chuàng)建的BP網(wǎng)絡(luò)。最后釋放內(nèi)存。
識別過程步驟如下:
第一至第三步同訓(xùn)練基本過程。
第四步,將待識別字符的輸入模式傳遞給創(chuàng)建的BP網(wǎng)絡(luò)。
第五步,將訓(xùn)練完成后保存的權(quán)值矩陣讀入相應(yīng)的BP網(wǎng)絡(luò)結(jié)構(gòu)的權(quán)值矩陣中。
第六步,調(diào)用feedforward(CBPNet *net)函數(shù)進(jìn)行前向計(jì)算。
第七步,判斷輸入的待識別樣本的類別,并輸出結(jié)果。
(5)實(shí)驗(yàn)結(jié)構(gòu)與分析。對實(shí)驗(yàn)采集到的64個(gè)不同的車牌系統(tǒng)進(jìn)行字符識別實(shí)驗(yàn)。每個(gè)車牌包含7個(gè)字符,總計(jì)448個(gè)字符識別樣本。當(dāng)用訓(xùn)練集中的訓(xùn)練樣本作為待識別樣本時(shí),識別率可達(dá)到100%。
當(dāng)用所有訓(xùn)練樣本和識別樣本作為測試集時(shí),識別率有所下降。但針對識別錯誤的字符,從結(jié)構(gòu)上提取其特征并采取相應(yīng)的措施,能有效提高系統(tǒng)的識別率,且可達(dá)到100%。
實(shí)驗(yàn)結(jié)果表明,基于BP神經(jīng)網(wǎng)絡(luò)的神經(jīng)網(wǎng)絡(luò)分類器具有較強(qiáng)的容錯能力、分類能力、學(xué)習(xí)能力,既可以設(shè)計(jì)成粗分類器,又可以設(shè)計(jì)成細(xì)分類器。而神經(jīng)網(wǎng)絡(luò)粗分類器和細(xì)分類器的結(jié)合,可以有效地提高系統(tǒng)的抗干擾性和識別率。
參考文獻(xiàn):
[1]廖翔云,許錦標(biāo),龔仕偉.車牌識別技術(shù)研究[J].微機(jī)發(fā)展,2003,13(S2):31-32.
[2]莊鎮(zhèn)泉,王熙法,王東生.神經(jīng)網(wǎng)絡(luò)與神經(jīng)計(jì)算機(jī)[J].電子技術(shù)應(yīng)用,1990(4).
[3]鄧萬宇,鄭慶華,陳 琳,等.神經(jīng)網(wǎng)絡(luò)極速學(xué)習(xí)方法研究[J].計(jì)算機(jī)學(xué)報(bào),2010,32(2):279-287.
[4]王 敏,黃心漢,魏 武,等.一種模板匹配和神經(jīng)網(wǎng)絡(luò)的車牌字符識別方法[J].華中科技大學(xué)學(xué)報(bào)(自然科學(xué)版),2001,29(3):48-50.
[5]葉晨洲,楊 杰,宣國榮.車輛牌照字符識別[J].上海交通大學(xué)學(xué)報(bào),2000,34(5):672-675.endprint
