藏語拉薩語LPC語音參數提取研究
2017-09-25 15:05:38卓嘎董志誠
現代電子技術 2017年18期
卓嘎++董志誠
摘 要: 藏語語音參數提取是藏語語音識別的關鍵技術之一,參數提取的精確度直接影響語音識別的效果。線性預測系數(LPC)是語音信號的重要頻域參數,是目前語音信號處理過程中比較重要的處理技術,廣泛應用于語音壓縮、語音聲學建模、語音合成、語音識別等過程中。首先介紹了線性預測算法原理,然后提出了藏語語音LPC參數提取的方案,最后在Matlab平臺上實現了藏語語音LPC參數的提取和仿真分析,研究結果對完善藏語語音合成技術和提高藏語語音識別效率有一定的研究參考價值。
關鍵詞: 藏語語音; LPC; 參數提取; 語音信號
中圖分類號: TN912.3?34 文獻標識碼: A 文章編號: 1004?373X(2017)18?0020?03
Research on speech parameter extraction of LPC in Tibetan Lhasa language
ZHUO Ga, DONG Zhicheng
(School of Engineering, Tibet University, Lhasa 850000, China)
Abstract: Tibetan speech parameter extraction is the one of the key technologies of Tibetan speech recognition. The accuracy of parameter extraction directly affects the effect of speech recognition. Linear prediction coefficient (LPC), as an important frequency domain parameter of speech signals, is currently an important processing technology in speech signal processing and widely used in the process of speech compression, speech acoustic modeling, speech synthesis, speech recognition and so on. In this paper, the principle of linear prediction algorithm is introduced. A scheme of LPC parameter extraction from Tibetan speech signals is proposed. LPC parameter extraction from Tibetan speech signals and simulation analysis are conducted on the Matlab platform. The results of the research provide some references for improving the Tibetan speech synthesis technology and the efficiency of speech recognition.
Keywords: Tibetan speech; LPC; parameter extraction; speech signal
語音識別技術是集信號處理技術、語言學、聲學等知識的一門綜合的、跨學科的技術。目前,由于大數據、深度學習、語音智能化研究的興起[1],語音識別技術在國內外得到很多專家學者的高度關注[2?4]。線性預測算法[5](Linear Prediction)是語音識別的關鍵技術之一,這一術語是維納1947年首次提出的,此后,線性預測應用于許多領域中。1967年,板倉等人最先將線性預測技術直接應用到語音分析和合成中。隨著這一算法的深入研究和不斷完善,在語音的合成、分析、編碼和識別等方面得到了廣泛的應用。
本文首先介紹了LPC線性預測算法原理,然后提出了藏語語音LPC參數提取的方案,最后在Matlab平臺上實現了藏語語音LPC參數的提取和仿真分析。
1 LPC線性預測算法原理
LPC線性預測原理:對于輸入的一段語音信號,首先用信號樣點間的相關性,獲得線性預測的參數值,然后將預測樣點的值與原始語音信號樣點的值相減,得到的誤差值用某種計算準則降到最低,從而逼近原始語音波形。已知原始語音信號樣點值為[s(n)],預測語音信號樣點值[s(n)]的關系如下,[p]為原始樣點的個數,[ak]為加權系數即預測系數,那么預測樣值[s(n)]為[p]個原始樣點的加權之和:
[s(n)=k=1pak(n-k)]
從而可以得到預測誤差為:
[e(n)=s(n)-s(n)=s(n)-k=1pak(n-k)]
然后計算短時平均最小誤差:
[ε=E[e2(n)]=min]
為了使預測效果最佳,利用均方誤差最小算法,得到:
[?[e2(n)]?ak=0, 1≤k≤p]
令:
[?(i,k)=E[s(n-i),s(n-k)]]
得到最小的[ε]為:
[εmin=?(0,0)-k=1pak?(0,k)]
從而可以看出,誤差越接近于零,那么計算出的線性預測系數越逼近原始語音信號的樣點。
在實際應用中,可以用線性預測算法建立線性時不變因果穩定的全極點聲道模型[6],并進行語音合成,其數學公式如下,將時域誤差[e(n)]進行[z]變化,得到[p]階的誤差濾波器的系統函數:endprint
[H(z)=1+i=1paiz-i]
如果將輸入語音的濁音或清音作為系統的激勵信號[7],經過該系統函數,再進行逆濾波可以得到原始的語音信號[s(n)]。[ai=(i=1,2,…,p)]是[p]階線性預測系數,即該模型的參數模型的系統函數為:
[H(z)=1A(z)+11+i=1paiz-i]
常用的平均最小方差算法有自相關法和協方差法。用自相關法計算線性預測系數時,需要在數據段兩端補充零,從而造成一定的失真。協方差算法中,數據段兩端不需要添加零取樣值,因此其優點是在取合適的采樣點數和階數時獲取的參數比自相關法精確。但是,在語音處理過程中,只要取足夠的樣點數值,也能得到比較精確的參數值。因此,高效的自相關算法在語音信號處理過程中應用比較廣泛。自相關解法主要有杜賓算法、格型算法和舒爾算法等幾種高效遞推算法。
2 藏語拉薩語LPC參數提取方法
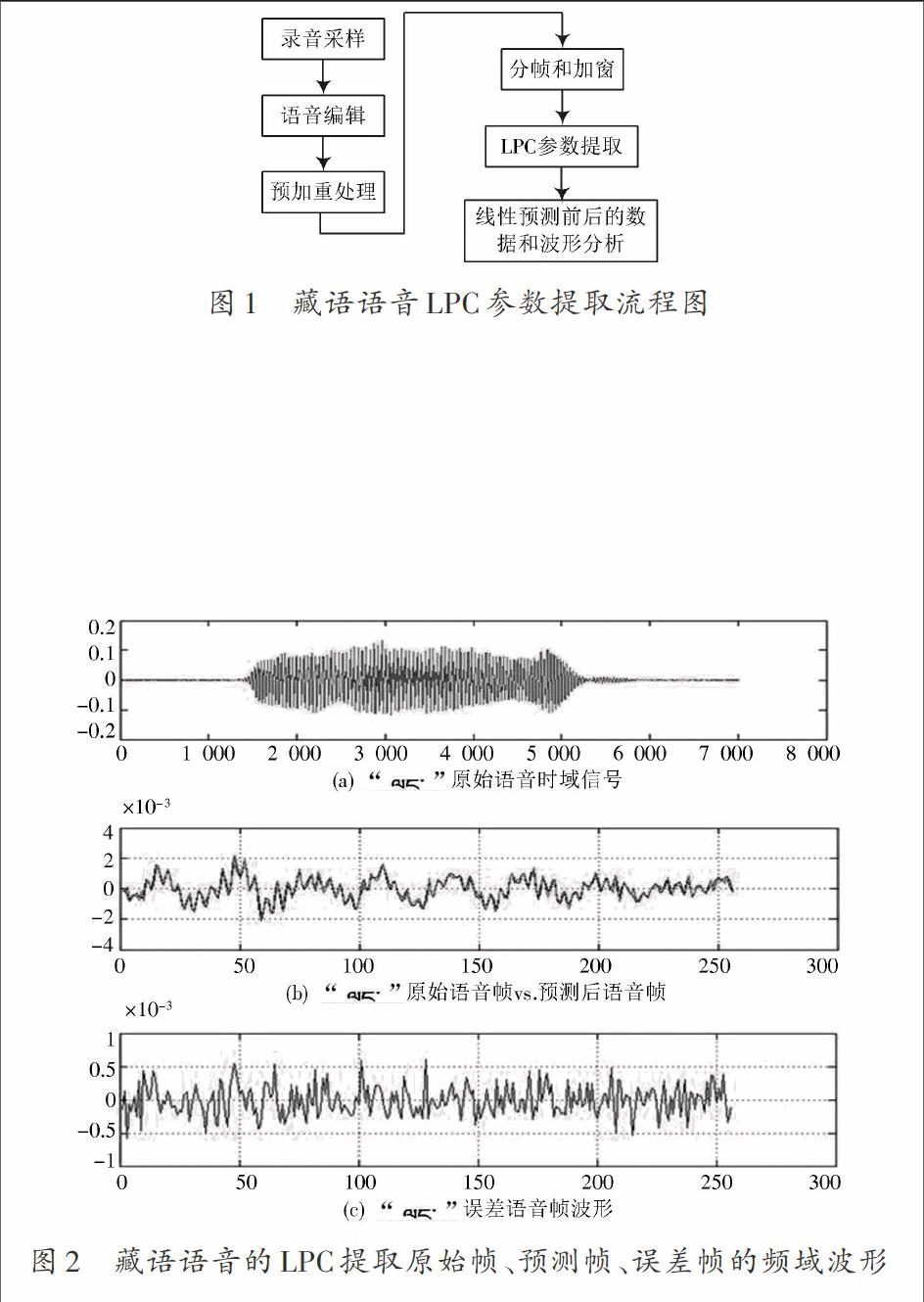
藏語拉薩語LPC參數提取流程圖如圖1所示,具體提取步驟如下:
(1) 語音的錄制和采集。Matlab自帶的函數wavread可以讀取語音信號并進行采樣,同時可以獲取采樣頻率。或者利用wavrecord自己錄制一段語音,再進行讀取。
(2) 語音編輯處理。對采集的語音數據進行前期的編輯、去噪、分割處理。
(3) 預加重處理。通過一個一階有限激勵響應高通濾波器[8],使信號的頻譜變得平坦,降低有限字長效應的干擾。
(4) 分幀和加窗。語音信號被看作是一種典型的非平穩信號,但由于語音的形成過程是與發音器官的運動密切相關的,這種物理運動比起聲音振動速度緩慢得多。因此可以假定語音信號為短時平穩的,即在10~20 ms這樣的時間段內,其頻譜特征和某些物理特征參量可近似地看作是不變的。這樣,就可以采用平穩過程的分析處理方法來處理。將每個短時的語音稱為一個分析幀,一般幀長取10~30 ms。在此采用一個長度有限的窗函數來截取語音信號形成分析幀。通常會采用矩形窗和漢明窗[9]。
(5) LPC參數提取和數據分析。通過Matlab編程仿真提取已采集的語音數據的頻譜、線性預測系數和共振峰參數[10]。分析藏語語音的原始幀、預測幀和誤差幀的頻譜圖、譜包絡結構和共振峰。
3 Matlab藏語語音LPC參數提取仿真和分析
在Matlab環境下,完成測試語音藏語
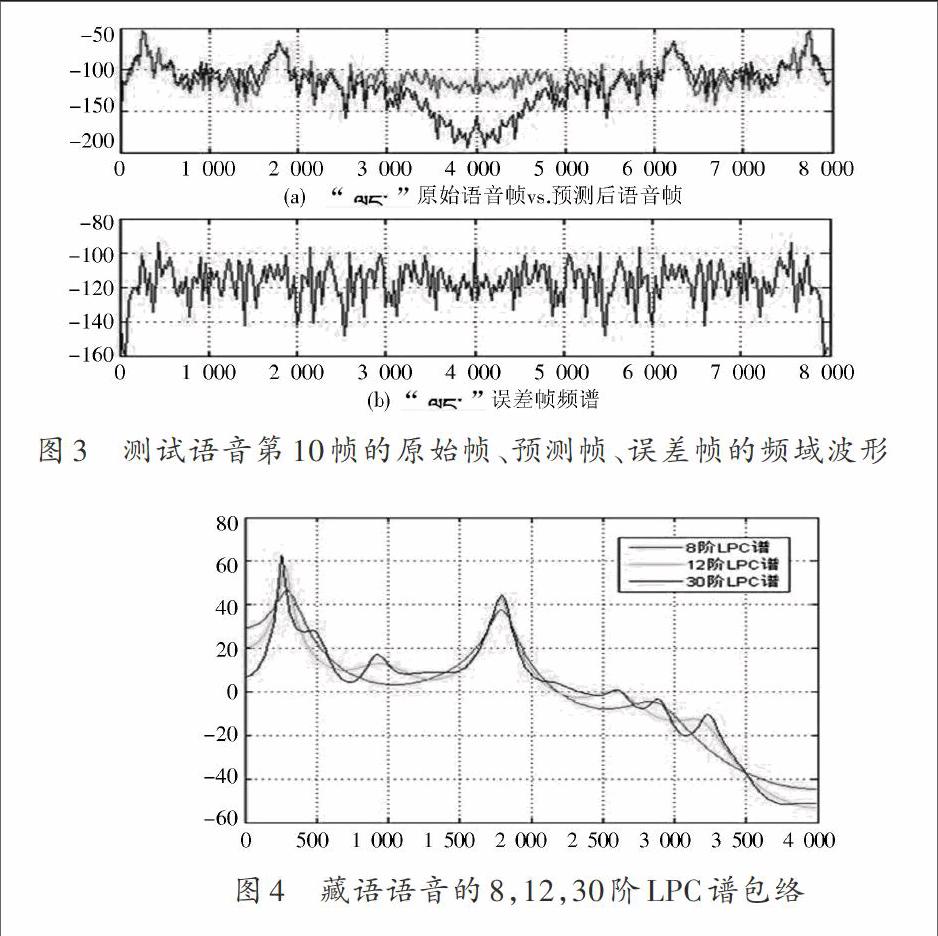
實驗中,原始藏語語音為圖2所示的第一個波形,采樣頻率為8 000 Hz,取第10幀,進行LPC參數提取,分別觀察了提取幀的時域、頻域的LPC原始幀、提取幀、誤差幀的波形和12階LPC包絡圖。圖2(a)是原始時域波形圖,在進行LPC參數提取之前,為了保證數據的有效性,先用手工方法將原始語音信號進行處理,只提取有效語音段[1 500 5 000],然后再進行參數提取。圖2(b)是對該語音的第10幀原始幀和預測幀的對比波形圖,從波形上可以看出基本重合,說明LPC算法能夠很好地預測原始語音信息。圖2(c)是該語音第10幀原始幀和預測幀誤差波形圖,為了得到最佳的預測效果,采用均方誤差最小的算法[11?12]使原始幀和預測幀的誤差接近于零。圖3是測試語音第10幀原始幀、預測幀、誤差幀的頻域波形。在頻域上也具有很好的吻合性。
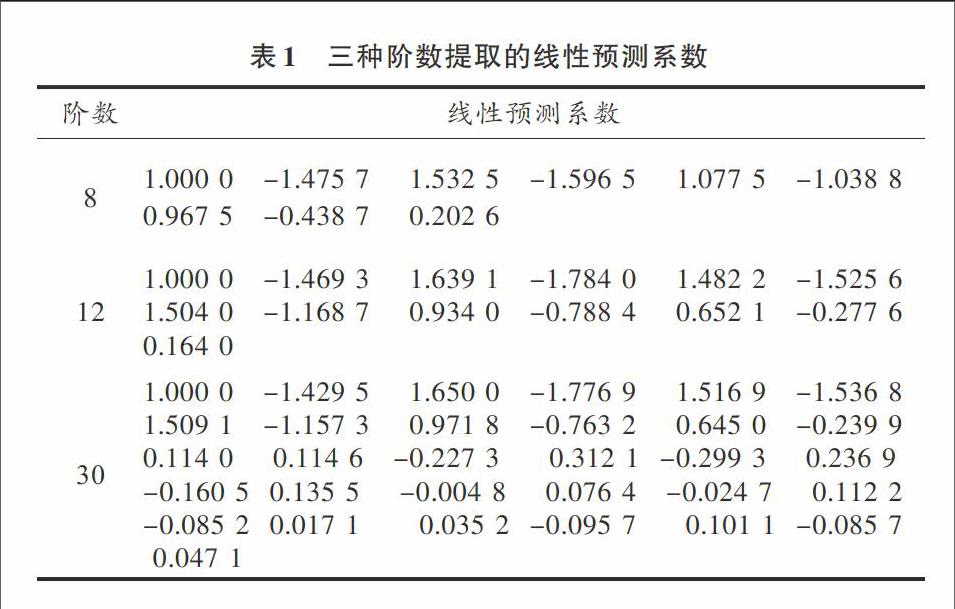
圖4 是測試語音的不同階數LPC譜包絡,從圖4可以看出明顯的共振峰,階數取8時的參數提取效果最佳,前三個為其共振峰。雖然階數越高提取的線性預測系數越多,但并不意味著提取的效果越好。在語音信號處理過程中,階數一般取8~14之間。表1是三種階數提取的線性預測系數。
4 結 語
LPC算法是目前語音識別過程中重要的語音參數提取技術之一,通過提取輸入語音的線性預測系數可以獲得共振峰的參數信息,從而進行得藏語語音的聲學分析,并在此基礎上可以提取其他相關的重要參數,如:LPC倒譜系數、共振峰、基音等特征參數。
表1 三種階數提取的線性預測系數
LPC算法存在靈敏度和人耳不匹配的問題,但是,在無噪聲環境下,線性預測系數算法是建立良好聲道模型的有效方法之一。LPC算法可以用于區分藏語語音的清音和濁音,提取共振峰、基音等頻率參數。因此,在藏語語音合成、識別過程中具有重要作用。
注:本文通訊作者為董志誠。
參考文獻
[1] 詹新明,黃南山,楊燦.語音識別技術研究進展[J].現代計算機,2008(9):43?45.
[2] 陳碩.深度學習神經網絡在語音識別中的應用研究[D].廣州:華南理工大學,2013.
[3] AREL I, ROSE D C, KARNOWSKI T P. Deep machine learning : A new frontier in artificial intelligence research[J]. IEEE computational intelligence magazine, 2010, 5(4): 13?18.
[4] 禹琳琳.語音識別技術及應用綜述[J].現代電子技術,2013,36(13):43?45.
[5] 張雪英.數字語音處理及Matlab仿真[M].2版.北京:電子工業出版社,2016.
[6] 李冠宇,孟猛.藏語拉薩話大詞表連續語音識別聲學模型研究[J].計算機工程,2012(5):189?191.
[7] 王文娟.基于壓縮感知理論的語音特性分析和研究[D].南京:南京郵電大學,2013.
[8] 周玲.基于Matlab的語音信號數字濾波處理[J].安慶師范學院學報(自然科學版),2011(3):46?49.
[9] 卓嘎,邊巴旺堆.基于Matlab的藏語語音基音檢測算法研究[J].現代電子技術,2015,38(10):20?22.
[10] 陳小瑩,艾金勇.藏語拉薩話元音共振峰聲學分析[J].西藏民族大學學報(哲學社會科學版),2016(3):110?115.
[11] 張明,劉祥樓,姜崢嶸.基于LPC的語音信號預測仿真分析[J].光學儀器,2015(1):71?74.
[12] YANG J. Combining speech enhancement and cepstral mean normalization for LPC cepstral coefficients [J]. Key engineering materials, 2011 (474/476): 349?354.
