語音驅動的口型同步算法
2017-11-01 08:58:00范鑫鑫楊旭波
東華大學學報(自然科學版) 2017年4期
范鑫鑫, 楊旭波
(上海交通大學 軟件學院, 上海 200240)
語音驅動的口型同步算法
范鑫鑫, 楊旭波
(上海交通大學 軟件學院, 上海 200240)
本文提出一種口型動畫同步算法, 可以根據輸入的語音信號, 生成與該信號同步的口型動畫.該算法分為預處理與運行時兩個階段.在預處理階段, 預定義一個基本口型動作集合, 然后令設計師通過定義該集合中元素的權重變化曲線, 來設計不同音素對應的口型動畫.在運行時階段, 首先獲取輸入語音信號對應的音素序列, 然后將該序列映射到一系列口型動畫片段上, 最后將這些片段互相拼接, 即可得到最終輸出的結果.試驗表明, 該算法具有較高的準確率, 在運行時耗時較少, 并且對于不同的人臉模型具有較高的可重用性.
語音驅動; 口型同步; 音素
口型動畫的制作在電影、游戲以及虛擬現實等新型人機交互方式中均占據重要地位.在觀看模型動畫時, 觀眾往往對模型口型動作的一些細微變化較為敏感.因此如何生成真實自然的口型動畫是當今計算機圖形學領域中的一個富有挑戰性的課題.
在生成口型動畫的方法中, 有一系列采用語音驅動的方法.這類方法一般以一段語音信號作為輸入, 生成一段與該信號同步的口型動畫.在這類方法中, 輸入的語音信號首先被轉化為由一串發音單元構成的序列, 這些發音單元被稱為音素.然后序列中的每個音素都會被映射到一個口型動作單元上, 這些口型動作單元被稱為視素, 視素是音素可視化的形態.最后, 將所得到的視素序列進行拼接與插值, 即得到最終的口型動畫[1].
在實際應用中, 除當前正在發音的音素外, 該音素之前或之后的一些音素也會對當前口型動作產生影響,這種現象叫做協同發音.協同發音現象是設計口型同步算法時必須考慮并且解決的問題.
為了解決口型同步與協同發音問題, 研究者們提出了不同的方法, 大致分為下述4種類別:
(1) 程序式的方法.這類方法定義了一系列針對音素的規則[2], 并且依照這些規則解決協同發音問題.其中Kalberer等[1]提出的方法最具代表性, 該方法為不同音素定義了不同的優先級, 在協同發音現象發生的時候, 優先級越高的音素對口型動作的決定作用也越大.
(2) 基于物理的方法.這類方法利用力學定律, 模擬臉部不同肌肉之間的相互作用, 進而生成對應的口型動畫[3].這類方法生成的口型動畫具有很高的真實度, 但是由于需要經過復雜的力學計算, 計算量較大且效率較低.
(3) 數據驅動的方法.這類方法需要預先采集大量的口型動作數據, 然后對于一段輸入的語音信號, 根據該信號對應的音素序列, 在所采集的數據中搜索最匹配的口型動作[4-5].為了滿足精確度的要求, 這類方法需要大量數據作為支撐.
(4) 基于機器學習的方法. 比較典型的有利用隱式馬爾科夫模型或者高斯混合模型等方法[6-7].這類方法通過訓練機器學習模型, 對輸入語音信號對應的口型動作做出基于概率的估計.與數據驅動的方法相比, 這類方法需要的數據量較少, 但是對于協同發音現象進行建模的結果具有較低的精確度.
本文提出的方法不同于上述4類方法.本文預定義一個基本口型動作集合, 所有口型動作均由該集合中的元素按照不同權重線性混合而成[8].由一位動畫設計師預先為每個音素設計對應的口型動畫, 這些口型動畫由一系列曲線構成, 分別代表每個基本口型動作的權重隨時間的變化.設計師在設計每個音素對應的口型動畫時, 需要考慮其后繼音素的所有可能情況, 并且針對不同情況設計不同的曲線作為音素之間的過渡動畫.在運行時, 分析輸入語音信號對應的音素序列, 然后將序列中的音素對應的口型動畫相互拼接, 最終得到完整的口型動畫.
本文方法的優點如下: (1)相比基于物理的方法需要在運行時進行運動模擬, 相比數據驅動的方法需要在運行時進行最優匹配的查找, 本文方法在運行時計算量很小, 這是因為所有音素對應的口型動畫均已在預處理階段被定義;(2)不同口型動畫之間相互獨立, 對其中一段口型動畫的調整不會影響系統的其余部分;(3)本文方法可以生成多數臉部模型對應的口型動畫, 在對模型進行變更時, 設計師只需要重新設計基本口型動作集合中的模型動作, 其余的模型動作均可由基本口型動作進行線性混合得到.
1 算法描述
本文方法包含兩個階段, 分別是預處理階段以及運行時階段.在預處理階段中, 設計師可以通過繪制曲線的方式定義音素對應的口型動畫; 在運行時階段中, 根據輸入語音信號對應的音素序列, 將序列中的音素對應的口型動畫互相拼接, 最終得到完整的口型動畫.
1.1預處理階段
1.1.1 音素的分類
本文所使用的Timit語音集合定義了46種不同的音素[9].語音學的研究表明, 有些不同的音素會表現為相似的口型動作, 比如/t/和/d/的發音, 只區別于聲帶是否振動, 其對應的口型動作是相近的.這種不同音素映射到相似口型動作上的現象是普遍存在的.基于上述結論, 本文將Timit語音集合中的46種不同音素映射到16個不同的類別上.映射的結果如表1所示[7].

表1 音素的分類Table 1 Classification of phonemes
設計師在設計每個音素對應的口型動畫時, 需要考慮其后繼音素的每種可能情況.因此, 對于原本的46種音素, 設計師需要設計共計2 116段不同的口型動畫, 這顯然是不現實的.通過音素的分類, 本文將需要設計的口型動畫數量減少到256種, 減少了約88%, 提高了預處理階段的效率.
為了使表達簡化, 下文中的術語“音素”均代指分類后的16類音素之一.
1.1.2 定義音素對應的口型動畫
為了減少設計師需要設計的模型動作數量, 進一步提高預處理階段的效率, 本文預定義了一個基本口型動作集合.通過定義基本口型動作的權重變化曲線, 設計師可以高效地設計不同音素對應的口型動畫.基本口型動作集合還使得本文方法支持對模型的變更, 設計師只需要重新設計基本口型.
動作集合中的模型動作, 除此之外不需要對系統的其余部分進行任何更改, 就可以得到新模型對應的口型動畫.
FaceGen建模軟件[10]提供了一系列預設的口型動作, 本文選取其中的6種口型動作組成基本口型動作集合.該集合中, 第一個元素是中性口型動作, 記作f1; 其余的元素分別對應表1中的類別2、6、13、15以及16, 記作f2至f6.圖1依次展示了上述6種基本口型動作.本文選取的基本口型動作參考了Xu等[11]的方法, 但本文認為, 基本口型動作集合的選取方式并非只有一種, 其他選取方式同樣能夠得出良好的效果.

圖1 6種基本口型動作Fig.1 Six kinds of basic lip poses
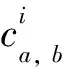
(1)
然后, 系統根據式(2)自動生成f1, 即中立口型動作的權重變化曲線.

(2)
語音學的研究表明, 人類在發聲的時候, 其唇部會迅速做出相應的動作, 然后在這個動作上穩定下來, 并且開始發聲.基于上述結論, 本文提出了權重變化曲線中的兩個階段: 穩定階段與變化階段.在穩定階段, 模型的唇部擁有與當前正在發音的音素相對應的穩定的動作; 在變化階段, 其唇部的動作則迅速向下一個音素對應的動作轉化.
在本文建立的口型動畫模型中, 每段口型動畫的穩定階段所持續的時間受說話的快慢、單詞中音素的緊密程度等多種因素所影響, 而變化階段所持續的時間則是基本恒定的.本文將變化階段所持續的時間記作T.若T值過小, 會使得最終生成的口型動畫動作過快, 表現得很不自然; 若T值過大, 則動畫中的口型與當前正在發音的音素吻合程度并不明顯, 表現得很不真實.試驗表明,T取30~50 ms之間的數值可以得出良好的效果.
每段口型動畫A(pa,pb)必須包含恰好一個穩定階段以及一個變化階段, 且穩定階段位于變化階段之前.其中, 穩定階段表示當前音素pa所對應的口型動作, 變化階段則表示當前音素pa向其后繼音素pb進行過渡的口型動作.
1.2運行時階段
運行時階段的工作流程如圖2所示.首先, 采用現有的音素分析工具, 根據輸入的語音信號, 得到對應的音素序列, 并且對于序列中的每個音素, 確定其在原語音信號中的起止時間.滿足條件的音素分析工具有很多, 如Festival系統[12]以及Julius系統[13]等, 本文采用了Festival系統進行分析.然后, 將音素序列映射到一系列預先定義好的口型動畫片段上.最后, 將這些動畫片段進行拼接, 根據拼接之后各基本口型動作的權重變化曲線, 混合成完整的口型動畫.
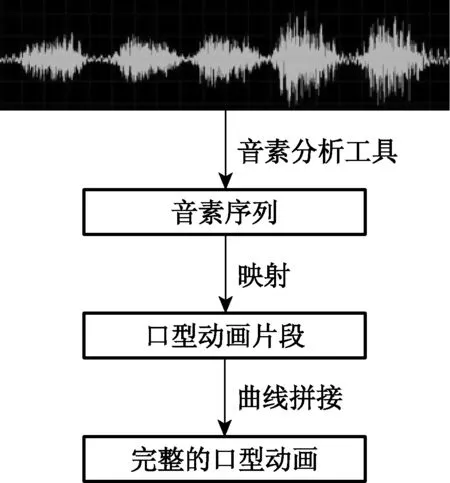
圖2 運行時階段的工作流程Fig.2 Flowchart of runtime phase
1.2.1 音素序列的映射
音素序列到口型動畫片段的映射過程如圖3所示.假設音素序列中存在一個音素pb, 并且其后繼音素為pc, 本文方法需要將事先定義好的動畫片段A(pb,pc)與音素pb相關聯.假設pb的持續時間為t1到t2, 本文分為t2-t1≥T以及t2-t1 t2-t1≥T的情況如圖3(a)所示.根據上文建立的口型動畫模型, 在映射結束后, 動畫片段A(pb,pc)中變化階段所持續的時間應該保持恒定不變, 而穩定階段所持續的時間則是可變的.所以, 本文令音素pb持續時間結尾處長度為T的部分, 即t2-T至t2, 作為新的變化階段; 剩余的部分即t1至t2-T, 則作為新的穩定階段.為了用動畫片段A(pb,pc)填充這段時間, 需要將該動畫片段中的穩定階段按照時間尺度縮放, 以適應新的長度, 而該動畫片段中的變化階段則無需進行任何更改, 直接填充至目標位置即可. (a)t2-t1≥T (b)t2-t1 英文單詞的音節緊湊, 為了保持語速, 在發音時經常不需要將當前音節完全發音, 而是只發音到一半便開始向著下一個音節過渡, 所以t2-t1 1.2.2 曲線的拼接 經過音素序列的映射步驟, 本文得到了一系列在時間軸上排列好的口型動畫片段, 并且有些片段是互相重疊的.每段口型動畫片段由6條權重變化曲線構成, 分別對應6個基本口型動作.所以, 將口型動畫片段進行拼接, 其實等同于對每個基本口型動作的權重變化曲線分別進行拼接. 本文提出的曲線拼接算法可以通過對曲線序列的一次遍歷完成.算法的輸入為由n個音素p1~pn構成的序列, 以及這些音素映射到的n條曲線c1(t)~cn(t); 輸出則為拼接完成的曲線c(t).在初始狀態下,c(t)是一條空曲線, 即c(t)的持續時間為0 ms.然后算法對音素構成的序列進行遍歷, 在遍歷到音素pi時, 將c(t)與ci(t)進行拼接, 并且將拼接完成的曲線作為c(t)的新值.在拼接時, 算法根據pi的持續時間與T的大小關系, 分兩種情況進行討論. c′(t)=(1-r(t))c(t)+r(t)ci(t) (3) 其中:r(t)為線性插值的比例函數, 其對應的表達式如式(4)所示. (4) 圖4是該算法作用在兩條曲線上的一個示例.在拼接之前, 兩條用虛線表示的待拼接曲線c(t)與ci(t)互相重疊.本文將上述兩條曲線在重疊區域內進行線性插值, 重疊區域外則保持各自的值不變.最終拼接完成的曲線在圖4中用實線表示. 圖4 曲線拼接示例Fig.4 Example of curve stitching 經過曲線的拼接步驟, 本文得到了6條完整的權重變化曲線, 每段曲線的持續時間均等于語音信號的總時間.設基本口型動作fi對應的完整權重變化曲線為ci(t), 最終生成的口型動畫F(t)可以通過基本口型動作按照式(5)的方式線性混合而成. (5) 設計師定義的每段曲線均滿足G1階連續, 并且可以從數學上證明c′(t)的連續性及其導函數的連續性, 所以最終得到的完整權重變化曲線滿足G1階連續, 由此生成的口型動畫滿足連續平滑的要求. 2.1時間分析 2.1.1 預處理階段 預處理階段消耗的時間主要用于對口型動畫進行設計.本文方法需要設計師設計256段不同的口型動畫, 為了提高設計的效率, 設計師可以將其中大部分權重變化曲線都定義為樣條曲線, 通過定義控制點的位置, 即可簡易地控制曲線的形狀.假設設計師定義并調整每段口型動畫平均需要15~20 min, 設計完成所有口型動畫的時間則需要5~6 d. 2.1.2 運行時階段 由于音素對應的動畫片段已經在預處理階段被設計師定義好, 本文方法在運行時階段只需要完成音素的映射與曲線的拼接, 其中只涉及一些簡單的線性插值計算.表2展示了本文方法分別處理Timit數據庫中8段音頻的耗時.觀察表2可以得出, 本文的方法擁有運行時計算量小、時間消耗少的優點. 表2 本文方法運行時的耗時與準確率分析Table 2 Runtime time consumption and accuracyanalysis of our method 2.2口型動畫效果分析 本文從根據Timit數據庫中的8段音頻生成的口型動畫中, 分別以固定間隔選取了50幀與真實情況進行了比較, 表2的最后一列展示了比較的結果.本文選擇了25名參與者, 請他們對本文的結果以及Xu等的結果進行評分, 評分的結果顯示, 25名參與者中認為本文的結果更加真實的有13名, 認為Xu等的結果更加真實的僅有 8 名.由此可以得出, 本文的方法具有更加真實的結果. 以Timit數據庫中的一段測試音頻為輸入, 最終生成的口型動畫中一些關鍵幀的截圖如圖5所示.在圖5中, 當前正在發音的單詞從左到右、從上到下依次為“she”“had”“your”“dark”“suit”“greasy”.觀察圖5可以得出, 以本文的方法生成的口型動畫基本上可以保持與語音信號的同步, 具有較高的精確度. 圖5 本文生成的口型動畫中關鍵幀的截圖Fig.5 Snapshots of our result lip animation 本文的方法允許設計師在不重新定義權重變化曲線的情況下, 生成其他模型對應的口型動畫.本文的方法作用在FaceGen建模軟件預設的兩個男性人臉模型上的效果如圖6所示.觀察圖6可以得出, 定義好的權重變化曲線可以適應不同的人臉模型, 說明本文的方法具有較高的可重用性. 圖6 本文方法作用在兩個男性人臉模型上的效果Fig.6 Result of our method when acting on two male face models 本文提出了一種語音驅動的口型同步算法,該算法預定義了一個基本口型動作集合, 設計師可以通過定義該集合中元素的權重變化曲線, 設計不同音素對應的口型動畫.本文提出了穩定階段與變化階段的概念, 并在此基礎上對設計師提出了在設計口型動畫時所需要遵循的3條約定.在運行時, 首先獲取輸入語音信號對應的音素序列, 然后將該序列映射到一系列口型動畫片段上, 最后將這些片段互相拼接, 即可得到最終輸出的結果.試驗表明, 本文方法在運行時耗時較少,生成的口型動畫基本上可以保持與語音信號的同步, 并且對于不同的人臉模型具有較高的可重用性. [1] KALBERER G A, MULLER P, GOOL L J V. Speech animation using viseme space [C] // Vision, Modeling, and Visualization Conference. Berlin, Germany: Akademische Verlagsgesellschaft Aka GmbH, 2002: 463-470. [2] CASSELL J, PELACHAUD C, BADLER N, et al. Animated conversation: rule-based generation of facial expression, gesture and spoken intonation for multiple conversational agents [C] // Proceedings of ACM SIGGRAPH 1994. New York, NY, USA: ACM, 1994: 413-420. [3] ALBRECHT I, HABER J, SEIDEL H P, et al. Speech synchronization for physics-based facial animation [C] // Proceedings of the International Conference on Computer Graphics, Visualization, and Computer Vision (WSCG’02). 2002: 9-16. [4] BREGLER C, COVELL M, SLANEY M.Video rewrite: driving visual speech with audio [C] //Conference on Computer Graphics and Interactive Techniques. 1997: 353-360. [5] CAO Y, TIEN W C, FALOUTSOS P, et al. Expressive speech-driven facial anima-tion [J]. ACM Transactions on Graphics, 2005, 24(4): 1283-1302. [6] BRAND M.Voice puppetry [C] // Proceedings of the 26th annual conference on Computer graphics and interactive techniques - SIGGRAPH '99. New York, NY, USA: ACM, 1999: 21-28. [7] BOZKURT E, ERDEM C E, ERZIN E, et al.Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation [C] // 3DTV Conference. 2007: 1-4. [8] DENG Z G, LEWIS J P, NEUMANN U. Synthesizing speech animation by learning compact speech co-articulation models [C] // Proceedings of Computer Graphics International (CGI2005). Washington, DC, USA: IEEE Computer Society Press, 2005: 19-25. [9] SENEFF S, ZUE V W. Transcription and alignment of the TIMIT database [M]. Recent Research Towards Advanced Man-Machine Interface Through Spoken Language, H. Fujisaki (ed.), Amsterdam: Elsevier, 1996: 515-525. [10] Singular Inversions. FaceGen [CP/OL]. http: //facegen.com/. [11] XU Y, FENG A W, MASELLA S, et al. A practical and configurable lip sync method for games [C] // Proc. Motion in Games, 2013: 109-118. [12] The center for speech technology research, The University of Edinburgh. The festival speech synthesis system [CP/OL]. http: //www.cstr. ed.ac.uk/projects/festival/. [13] Kawahara Lab, Kyoto University. Julius: open-source large vocabulary continuous speech recognition engine [CP/OL]. https: //github.com/julius- speech/julius. [14] WEI L, DENG Z G. A practical model for live speech-driven lip-sync [J]. IEEE Computer Graphics & Applications, 2015, 35(2): 70-78. (責任編輯:杜佳) ASpeech-DrivenLipSynchronizationMethod FANXinxin,YANGXubo (School of Software, Shanghai Jiao Tong University, Shanghai 200240, China) A speech-driven lip synchronization method is proposed to generate lip animation according to the input speech signal. The method contains two phases: preprocessing phase and runtime phase. In preprocessing phase, a basic lip pose set is predefined. Through adjusting the weight curves of the predefined lip pose set, animators can design lip animation segments corresponding to different phonemes. In runtime phase, the phoneme sequence of the input speech signal is acquired and mapped to a series of lip animation segments. These segments are then stitched together to generate the final result. Experimental results show that this method has high accuracy and low time consumption, and is reusable between different face models. speech-driven; lip synchronization; phoneme TP 301.6 A 1671-0444 (2017)04-0466-06 2016-12-19 國家自然科學基金資助項目(61173105,61373085);國家高技術研究發展計劃(863)資助項目(2015AA016404) 范鑫鑫(1994—),男,河北邢臺人,碩士研究生,研究方向為軟件工程數字藝術.E-mail: smwlover3601102@sina.com 楊旭波(聯系人),男,教授,E-mail: yangxubo@sjtu.edu.cn



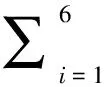
2 試驗結果



3 結 語
猜你喜歡
小哥白尼(趣味科學)(2021年12期)2021-03-16 05:40:38小學科學(學生版)(2020年10期)2020-10-28 07:52:18文苑(2019年22期)2019-12-07 05:28:56小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28作文評點報·低幼版(2017年7期)2017-03-11 20:49:41學生天地(2016年9期)2016-05-17 05:45:06Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
