面向大規模計算集群的多軌分割網絡
2017-12-08 05:30:24元國軍郇志軒孫凝暉
計算機研究與發展 2017年11期
關鍵詞:策略
邵 恩 元國軍 郇志軒 曹 政 孫凝暉
1(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190) 2(中國科學院大學 北京 100049)
(shaoen@ncic.ac.cn)
面向大規模計算集群的多軌分割網絡
邵 恩1,2元國軍1,2郇志軒1,2曹 政1孫凝暉1
1(計算機體系結構國家重點實驗室(中國科學院計算技術研究所) 北京 100190)2(中國科學院大學 北京 100049)
(shaoen@ncic.ac.cn)
在千萬億次規模的系統中,互連網絡設計面臨新的挑戰.高性能節點和大規模是構建千萬億次系統的主要技術趨勢,不斷提高的節點計算能力要求互連網絡提供更高的性能,而不斷增大的規模又對互連網絡擴展性提出了更高的要求.此外,隨著系統規模的增大,集合通信的執行時間也在不斷增長,制約了應用的擴展性,集合通信的性能需要得到進一步優化.除性能之外,可靠性問題也隨著系統規模的擴大而日益嚴重.而隨著計算節點性能的不斷提高,互連網絡逐漸成為限制大規模計算機系統性能的瓶頸.互連網絡核心部件交換芯片可提供的聚合網絡帶寬受到工藝和封裝技術的限制.從網絡結構與交換機結構的協同設計思想出發,提出了一種在交換機聚合帶寬限定的條件下多軌分割網絡結構和設計方法.通過數學建模和網絡模擬仿真,分析了該多軌分割網絡的性能邊界.評測結果表明:該網絡可將短消息(長度小于128 B)的平均延遲性能提高10倍以上,為以短消息占多數的數據中心網絡的性能優化提供了新思路.
大規模計算集群;多軌網絡;帶寬分割;數據中心網絡;大規模網絡模擬
隨著集群計算機計算節點性能的不斷提高,互連網絡性能逐漸成為大規模計算集群整體性能提升的瓶頸,然而網絡核心部件——“交換芯片”——的性能提升受到工藝和封裝的限制[1-2]: 1)高速串行收發器(serdes)的帶寬提升緩慢,端口帶寬提升依賴于多路高速串行鏈路的并行,例如100 Gbps端口采用4路25 Gbps鏈路;2)封裝技術限制交換芯片的引腳數目,進而限制交換芯片能夠集成的serdes數目.因此,工藝和封裝技術限定交換芯片能夠提供聚合網絡帶寬.在聚合帶寬限定的條件下,傳統追求高階高帶寬的best-effort設計方法將不再有效,交換芯片設計必須考慮最優的帶寬分配,如圖1所示:1)多端口策略.端口帶寬低,端口數目多.2)高帶寬策略.端口帶寬高,端口數目少.
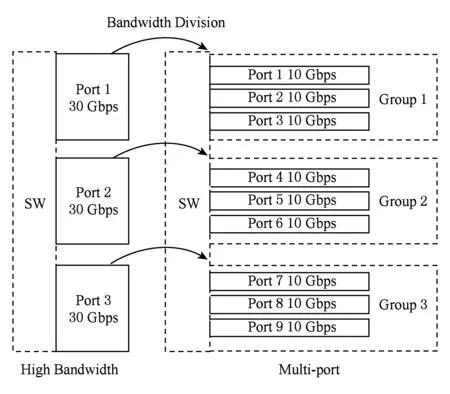
Fig. 1 Strategy between high bandwidth and multi-port圖1 高帶寬與多端口策略示意圖
直觀地,多端口策略是高帶寬策略的細化分割,更有利于提高組網的靈活性,降低網絡流的調度粒度,而高帶寬策略則有利于快速緩解網絡的擁塞.為評估2種策略的優劣,本文分別使用滿足不同策略的交換芯片模型,構建相同拓撲的網絡,通過理論分析和網絡模擬進行全系統網絡性能的評估.
為構建相同的拓撲,本文借鑒多軌網絡(multi-rail network)的思想,提出了多軌分割網絡結構:將多端口交換芯片抽象為高帶寬交換芯片的細分,將其構建的網絡(為方便描述,仍稱為多軌網絡)抽象為基于高帶寬交換芯片網絡的多軌化實現.但有別于傳統多軌網絡,本文的多軌網絡由多層低帶寬網絡構成,且層與層之間并不獨立,消息可以在不同層之間切換傳輸.本文多軌網絡的構建方法、流量分配、消息分片和路由策略,是本文重點討論的內容,是對基于高階交換芯片的組網方法的有益探索.
本文的網絡模擬均基于胖樹拓撲展開,模擬結果表明多端口策略相比高帶寬策略有3個優點:1)使網絡具有可擴展性的網絡流量調度與帶寬分配策略;2)在降低基礎網絡硬件成本的同時,將短消息(長度小于128 B)的延遲性能提高近10倍以上;3)隨網絡流量注入率的增加,長消息傳輸(長度大于2 048 B)出現擁塞的情況會提前10%以上.因此,多軌分割網絡能夠給目前短消息占據多數的數據中心網絡帶來明顯的性能提升.
1 相關研究
本文所提出的帶寬分割化網絡借鑒多軌網絡的設計思想.多軌網絡是指網絡拓撲互聯節點間用大于一層以上的彼此獨立且具有相同結構和功能的網絡相互連接,這種網絡通過設置多層并行子網的設計思路,將大規模計算集群從單純高聚合帶寬交換模式中解放,成為另一種網絡設計選擇.網絡分割度指網絡內具有彼此獨立且具有相同結構和功能的子網絡的個數;而單軌網絡作為多軌網絡的特例,其分割度為1.同時,多軌網絡因其擁有靈活配置網絡帶寬資源的設計可能,通過優化設計可以達到比高聚合帶寬設計性能更好的可能.但是本文提出的帶寬分割網絡結構,在包括帶寬鏈路分配、消息分片、路由和虛通道切換等策略方面,與傳統多軌網絡有很大區別.
對于傳統的多軌網絡結構,已經有較為充分的研究.文獻[3]結合多核網絡系統對多軌網絡的需求,針對在系統軟件層對多軌網絡子網利用率低的問題,提出獨立的一套軟件層通信庫,結合該通信庫對小包通信場景的優化,降低CPU通信開銷并提高通信并行性能.此論文所提出的通信協議優化策略,并未全面分析多軌網絡的網絡結構.文獻[4]基于InfiniBand與RDMA的特征,通過增高帶寬數據傳輸緩沖方式提高多軌HCA網絡的通信性能,并針對MPI多軌中數據亂序處理進行優化.文獻[5]希望通過在多軌網絡中設置靜態和動態的路徑分配算法來提升網絡的整體通信性能,雖然對路徑分配算法描述得非常清楚且給出數學模型,但是從模擬的結果上看整體通信性能并沒有提高,反而有惡化的現象.文獻[6]結合MPI在多軌網絡中上對失效備援和系統災備恢復方面的需求,設計并評測一套建立在多軌網絡上的系統切換與恢復算法.
文獻[7]面向Quadrics QsNetII集群系統,基于多核多軌網絡設計思想,通過增加源節點到目的節點的連接通道,即增加通信聚合帶寬,提高網絡的通信性能.該文與本文雖然都對多軌網絡的結構和通信行為進行分析,但是本文旨在不改變通信總帶寬的基礎上進行優化策略,與文獻[7]側重點不同.
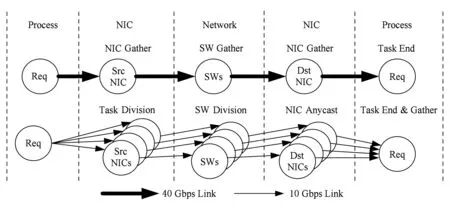
Fig. 2 The algorithm comparison between of multi-rail and single-rail圖2 多軌與單軌鏈路算法對比
目前已實現[8-9]針對多軌QsNetII網絡中基于多端口RDMA軟件通信層數據分片和歸集算法,并對小數據包進行性能評測.2篇論文對多軌網絡研究集中在彌補現有軟件通信庫功能的不足,與本文側重點不同.文獻[10]著眼于uDAPL獨立通信庫在對多軌網絡中通信功能支持方面進行的補充,通過實現2種多軌網絡的配置方法,實現在InfiniBand集群上的多軌通信性能優化,也與本文側重點不同.
文獻[11-12]中分別對微軟與Facebook數據中心網絡的負載特性進行了分析,通過真實的網絡平臺實驗測試,分析并總結主流數據中心網絡負載的數據包長度上具有固定性分布,超過50%以上的負載數據包長保持在100~400 B之間,表明低負載數據包在數據中心網絡中占有重要比重.
2 多軌網絡模型分析
本節將基于網絡多軌化構建思想對網絡多軌分割方法進行闡述,結合傳輸延遲性能理論推導,對其性能預期進行量化分析.
2.1多軌分割方法論
建立多軌網絡存在的2種策略:1)少量的高帶寬端口,即高帶寬策略;2)較多的低帶寬端口,即多端口策略.本節的目的就在于分析2種策略的性能差別,使用如下場景:單軌網絡使用一個高帶寬端口,多軌網絡使用多個低帶寬端口,但二者的聚合帶寬相同.下面將根據網絡結構搭建方法和多軌分割在網絡通信行為上的變化進行說明.
這2種構建多軌網絡的策略在拓撲搭建上,多端口策略是由高帶寬策略進行多軌帶寬分割變形而來,如圖2網絡分割方法所示,該方法不受網絡拓撲結構所限制.圖2中40 Gbps link的網絡鏈路為具有少量端口數且單條端口和鏈路帶寬都較高的高帶寬策略;10 Gbps link的網絡鏈路為具有較多端口數且單條端口和鏈路帶寬都較低的多端口策略.圖2羅列出從系統進程層面之間的數據傳輸通路,具體的分割算法可以視為將40 Gbps link的每一條鏈路都拆分為4條10 Gbps link,由此保證單條鏈路的聚合帶寬不變,同時單一鏈路的目的也要相應地多出端口來承載分割多出的鏈路.
網絡通信行為方面,40 Gbps link網絡鏈路由于網卡端口的唯一性,會在進程分發task和目的NIC接收數據的2處鏈路造成網卡數據聚集(NIC gather)現象;又由于網絡流量指向非定向行,在網絡鏈路傳輸過程中也會在交換機上產生交換數據聚集(switch gather)現象. 而這些收集現象在數據載荷較輕的流量傳輸過程中,往往會造成網絡的局部擁塞.

Fig. 3 Network delay model of single-rail圖3 單軌網絡延遲模型
在進行網絡分割后,在圖2所示的10 Gbps link網絡中,進程在進行task分發以及網絡轉發時,由于網卡和交換設備端口的分割,數據包產生開始以及網絡轉發階段都進行task pipeline.而在交換機將數據傳輸到目的網卡時,由于網卡端口的分割帶來的可選傳輸端口增多,因而任播通信方式也可以得以實現.雖然從以上分析來看,分割后網絡在通信行為上能夠更好地進行流水線傳輸;但是由于單端口帶寬降低,網絡中對單一數據包轉發時延也會增大.而多軌網絡中網絡分割策略究竟對網絡性能有怎樣的影響,還需要進行定量分析.
2.2多軌網絡性能理論分析
本節理論分析做如下設定:虛切入網絡中的最大包長(MTU)為L,共有n個長度為L的網絡數據包連續傳輸,網絡接口控制器的輸入帶寬為BW_i,單軌模式下的網絡鏈路帶寬為BW_sl,多軌模式下單層網絡鏈路帶寬為BW_ml,交換機單級交換延遲為Tswitch,單級傳輸延遲為Tline,網絡跳步數為Hop_cnt,并行網絡層數為m,數據傳輸延遲為LBW_sl與交換延遲Tswitch.令單軌網絡的帶寬BW_sl=m×BW_ml,網絡控制器輸入帶寬BW_i=k×BW_ml.
單軌網絡的信息注入模型如圖3所示.
在單軌網絡中,消息的傳輸延遲Ts為
Ts= t0+(n-1)×max(LBW_sl,Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_sl.
(1)
根據多軌網絡中的2種策略相應地存在對應的信息注入模型,如圖4所示.多軌網絡中,消息的傳輸延遲Tm為
Tm=t0+(m-1) ×LBW_i+(nm-1) ×
max(LBW_ml,m×LBW_i,Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml.
(2)
設如下場景:單軌網絡使用一個高帶寬端口,多軌網絡使用多個低帶寬端口,但二者的聚合帶寬相同.令單軌網絡的帶寬BW_sl=m×BW_ml,網絡控制器輸入帶寬BW_i=k×BW_ml.可得多端口策略比高帶寬策略的性能提升倍數為
G=((n-1)×max(L(m×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+L(m×BW_ml))
max(LBW_ml,m×L(k×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml).
可得多端口策略比高帶寬策略的性能提升倍數為
G=((n-1)×max(L(m×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+L(m×BW_ml))
max(LBW_ml,m×L(k×BW_ml),Tswitch)+
Hop_cnt×(Tswitch+Tline)+LBW_ml).
(3)
(Tswitch+Tline))((1+kn-1n)×LBW_ml+
當持續傳輸消息時,n趨于無窮,則提升倍數的極限為
(4)
(Tswitch+Tline)+k×L(m×n×BW_ml))
Hop_cnt×(Tswitch+Tline)).
當持續傳輸消息時,n趨于無窮,則提升倍數的極限為
(5)
(Tswitch+Tline))((k+m2n-mn-
Hop_cnt×(Tswitch+Tline)).
當持續傳輸消息時,n 趨于無窮,則提升倍數的極限為
(6)
(Tswitch+Tline)+L(n×BW_ml))
((1+(m2-m)(k×n)-mn)×LBW_ml+
當持續傳輸消息時,n 趨于無窮,則提升倍數的極限為
(7)
5) 當Tswitch≥max(LBW_ml,m×L(k×BW_ml))時,則提升倍數為
(Tswitch+Tline)+L(m×n×BW_ml))
(Tswitch+Tline)+L(n×BW_ml)).
當持續傳輸消息時,n趨于無窮,則提升倍數的極限為
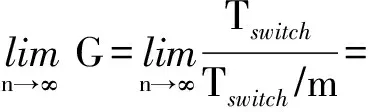
(8)
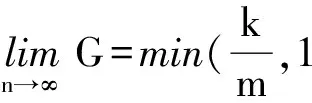
(9)
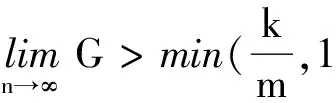
(10)
當Tswitch≥LBW_ml時(數據包較短),多端口策略相比高帶寬策略可以獲得m 倍的性能提升;當Tswitchlt;LBW_ml時(數據包較長),多端口策略的性能提升卻與m成反比.
因此若采用多端口策略,端口的數目不能無限制增加,其取值受限于k,即網絡接口控制器輸入帶寬與單層網絡帶寬的比值.當m=k 時,才能保證包長較大的情況下,多端口策略仍具有與高帶寬策略相當的性能.
通過3級胖樹為例,對以上分析進行計算,設Tswitch=130ns,Tline=100ns,BW_ml=10Gbps,k=6,Hop_cnt=5,n=10 000.可得不同分割度情況下,多軌策略性能提升倍數性能曲線,如圖5所示.數據負載重量都集中在小于數據包長度為128B的區間,多軌網絡中實行多端口策略較高帶寬網絡有性能提升優勢.實際網絡情況具體如何還需要進行模擬仿真進行驗證.
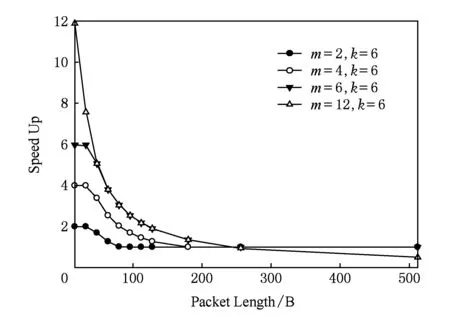
Fig. 5 Performance improvement in multi-rail with multi-port圖5 多軌網絡多端口策略性能提升倍數
3 多軌胖樹網絡實例分析

Fig. 6 The topological difference between high bandwidth and multi-rail in Fat-tree network圖6 高帶寬網絡與多軌胖樹網絡的拓撲區別
標準胖樹(Fat-tree)拓撲結構如圖6(a)結構所示,具有等分帶寬、低網絡直徑以及易于擴展的特點.圖6(a)所示胖樹拓撲中,方框圖形為網絡交換節點,圓形圖形為產生數據和接收數據的網卡.圖6中網絡交換節點各有4個端口,即A~D.在能夠滿足高帶寬、低延遲和可擴展的需求之外,由于標準胖樹拓撲結構包含眾多冗余鏈路的結構特性,有效避免網絡中死鎖問題的出現.
結合本文中所提出的數據分片算法,如2.1節中多軌分割方法所述,標準胖樹網絡進行帶寬分割后,形成的多軌分割胖樹網絡的拓撲結構如圖6(b)所示.圖6(b)是基于圖6(a)標準胖樹網絡進行分割度為4的帶寬分割變換后形成的網絡結構.標準胖樹單條帶寬為40 Gbps,而多軌胖樹由于將單條40 Gbps鏈路分割成4條10 Gbps鏈路,對網絡交換節點的端口需求也正比增加.在圖6(b)中,每個交換節點的都有A~P共16個端口.多軌胖樹在拓撲結構中的單層網絡擁塞可能性提高,因此需要設計專有負載均衡、數據處理以及通道處理算法.
本節將針對多軌胖樹網絡的特殊結構,設計流量均衡算法、數據分片算法以及路由和虛通道切換策略.為簡單描述,本文中所有的交換機都簡寫為SW,在集群中作為數據源的網卡簡寫為NIC.
3.1網絡流量均衡算法設計
網絡的多軌化為原有網絡提供更加豐富的路徑選擇,但是如果網絡中流量出現不均衡,網絡性能不但不會提高反倒會因為單一子網擁塞而導致更多不可預期的局部熱點,網絡也會更容易出現網絡擁塞.因此,配套的網絡流量均衡策略對多軌網絡優勢體現尤為重要.本節通過對多軌網絡中原址路由算法進行優化,提出一種基于單步均衡思想的流量均衡算法.下面以分割度為4的多軌胖樹網絡舉例來闡述該算法實現過程,設胖樹網絡中共有編號為0~3的4套胖樹子網.
保證在已有的多軌網絡源址路由算法中,網絡數據包由系統進程產生后,統一集中在4路子網的“0”號子網,即默認第1路子網.首先保證圖2中Task Division階段NIC網卡產生原始數據輸出的4路帶寬均衡,即進程產生數據包根據網絡分割度將task進行分段,形成適合多軌網絡均衡的數據包個數,由此保證NIC輸出的每一路都是10 Gbps帶寬.設連接相同源節點與目的節點的4條子網鏈路為同一組端口,即端口組.在多軌網絡的傳輸過程期間,在交換機的數據發送的中間處理過程中(即在原址路由表修改的步驟中)根據發往的目的節點端口ID,設置交換機的網絡局部變量,在每個交換設備中記錄下每個端口組上具有相同目的端口組和源發送節點的數據包所占用的端口號為歷史端口占用號.根據歷史端口占用號,設置當前數據包轉發端口,并修正歷史端口信息.在設置當前轉發端口時,可以通過依次遞增同一端口組中的端口號方式進行歷史端口占用號更新,保證每次發往統一交換設備的數據包能夠平均分配在4個子網上.
以上是多軌網絡中的端口流量均衡算法,在實現上是通過每次數據包在多軌網絡中轉發時進行單步修正的.結合3.3節中VOQ模式的使用策略,也可以采用相同機理的網絡虛通道流量均衡算法來進行實現,實現機理與端口均衡相同,這里不再贅述.這種算法在實現上的優勢:1)該流量均衡算法避免使用全局網絡狀態信息,僅使用網絡局部狀態信息就可以保證多軌分割網絡中同端口組子網間的流量均衡;2)算法可以在源址路由算法執行網絡包頭修改的過程中進行,沒有額外的算法執行時間損耗;3)根據分割度和交換設備的實際端口個數決定算法局部變量的存儲損耗,不會額外占用交換設備的過多存儲空間.
3.2數據分片算法
如圖7所示,進行重載數據(長消息)傳輸時,根據網絡分割度,對重載數據進行數據分割.根據圖5中不同分割度多軌網絡對網絡負載的傳輸性能的提升倍數,考慮到數據分片帶來的信息包頭的冗余信息,合理安排重載數據的分片方式,由此一個長消息被分拆為若干數據塊,分發到多個鏈路中同時傳遞.
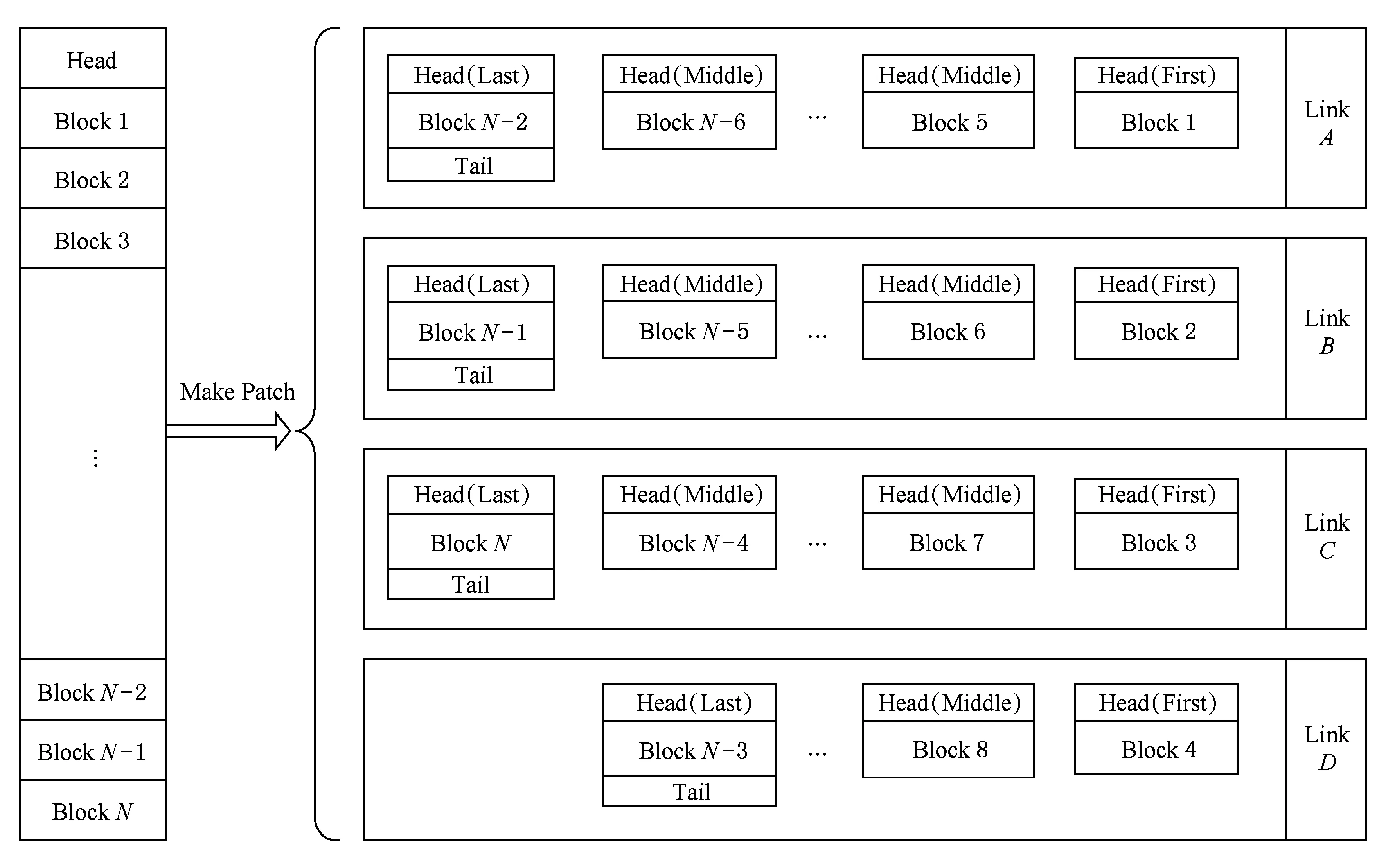
Fig. 7 Patch transmission of weight load圖7 重載數據包信息分片傳輸
在圖7某重載數據在分隔度為4的多軌網絡中,對重載數據分片后形成N個輕載數據包分別攜帶N個數據塊.這些輕載數據包依次被分配到鏈路A~D之中,在每個鏈路中,標記此消息在該鏈路中的首包和尾包,而此時所有鏈路中傳輸的數據包均為分片后的輕載荷數據包.由于單層網絡中該消息數據包的傳輸保序,因此目標節點通過對首包和尾包的記錄,即可獲得消息在單層網絡中的接收狀態.本研究后續在對多軌網絡實際性能進行評測時所使用的流量,都將使用本節中網絡接口設計中數據包分片后形成的流量進行評測.
這樣的網絡接口和重載數據包處理方法,雖然增加對單個重載包的處理成本,但是通過對多鏈路并行使用,并根據數據長度決定鏈路的使用個數,實現多鏈路的負載均衡和高效利用,因此在網絡整體性能角度上看,是極具性價比的網絡實現模式.
3.3路由和虛通道切換策略
虛擬輸出隊列(virtual output queuing, VOQ)結構可以很好地解決隊頭阻塞(HOL blocking)問題,在VOQ結構下,每個輸出端口設置多個虛通道緩沖隊列.如圖8(a)(b)所示,不同的數據包由于傳輸路徑不同,因而在節點A和節點B上流經不同的虛通道,緩解數據端口緩沖排隊的擁塞情況,因此在單、多軌網絡中利用VOQ和數據包分片策略,都能發揮數據包傳輸并行化的優勢.結合圖5中關于分隔度不同,多軌網絡對不同數據包長傳輸性能的差異,網絡結構設計者除了需要確定重負載數據包數據分片的策略和多軌分割度之外,還需要考慮虛通道的設置個數.不同分割度情況下,虛通道策略實現的數據并行效果如圖8(c)所示.在圖8(c)中表現單軌網絡(即分割度為1)和分割度為2的多軌網絡,在端口緩沖空間總量相同的前提下,對同樣重量的數據載荷進行數據分片后的并行傳輸效果.相同分割度情況下,受到端口轉發速率的影響,數據分片大小沒有本質影響數據轉發效率.
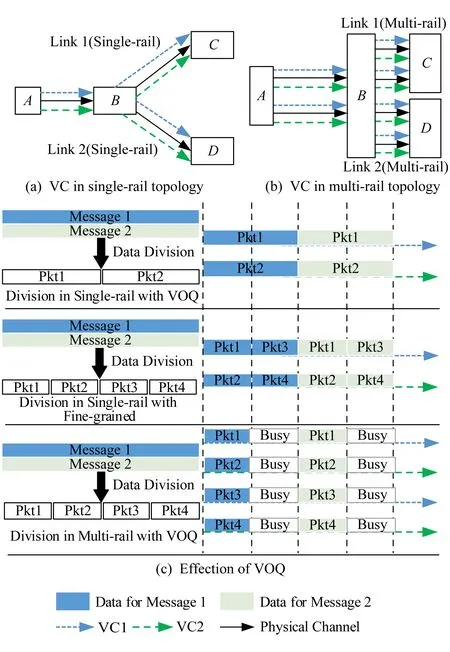
Fig. 8 The design of virtual channel圖8 虛通道設計與效果示意圖
由于端口緩沖空間總量相同,分割度為2的多軌網絡的單獨虛通道緩沖隊列是單軌隊列的一半,因此數據轉發效率雖然在并行處理上提高1倍效率,但是獨立隊列有效使用率出現50%的性能折損.如果圖8(c)中多軌虛通道緩沖區的深度與對應單軌虛通道保持一致,即在現有基礎上緩沖區的深度翻倍,圖8中的“Busy”就也能進行數據包轉發,而整體數據轉發性能也將翻一倍.因此,要想進一步發揮多軌網絡在VOQ模式下的性能,應該根據網絡熱點嚴重程度的不同,合理分配端口轉發緩沖區的深度.
4 網絡分割性能模擬與分析
本節中所進行的性能仿真都是基于(m-port,n-tree)胖樹網絡所進行的.其中,m為網絡中交換設備的端口總數,n為樹的最大層級數,記(m-port,n-tree)胖樹網絡為FT(m,n),樹的高度為n+1,包含2×(m/2)n個計算節點和(2n-1)×(m/2)n-1個交換機.本節仿真使用m=4,n=3標準胖樹網絡以及其多軌分割后形成的多軌胖樹網絡為仿真對象.在仿真所采用的網絡拓撲中,網絡交換節點從結構上共分為3級,最接近節點網絡一級的網絡交換節點為邊界交換節點asymmetricSW,作為第3級switch.除此之外,另外還有2級交換節點,其中距離網卡最遠的switch層級為第1級,另外一層為第2級.流量產生方式上,仿真流量采用uniform隨機流量模型.NIC端帶寬分割和網絡數據流量分配后,switch,asymmetricSW交換機的工作時鐘周期f(單位為ns)與數據位寬b(單位為B)的設置對網絡性能的影響;分割度d作為區別多軌分割網絡結構的特征參數.網絡交換節點的聚合帶寬B計算為
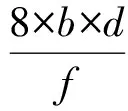
(11)
因此在各個參數共同影響下的B,可以表示當前網絡聚合帶寬,其中d還單獨表示當前因為帶寬分割度不同所表現的多軌網絡拓撲結構的差異.結合NIC端帶寬分割和網絡數據流量分配的情況下,本節仿真分為2部分:1)多軌極限性能仿真,用以模擬網絡多軌分割后網絡可達到的極限性能;2)數據均衡分片對比仿真,用以驗證多軌網絡的性能提升倍數理論.
本文網絡模擬基于cHPPNetSim(configurable HPP network simulator)多功能可配置并行網絡模擬器進行仿真.該模擬平臺主要功能是對大規模并行網絡進行細粒度的模擬,模擬結果可以得到網絡整體性能、局部性能,獲取每個網絡部件運行狀態.
4.1多軌極限性能仿真
本次仿真中的多軌網絡除對40 Gbps網絡進行帶寬4等分之外,子網間流量可以交叉,與此對比的對象是未分割獨立帶寬10 Gbps網絡.獨立10 Gbps網絡可以表示4路獨立10 Gbps網絡在網絡設備獨立、子網路徑獨立不共用情況下40 Gbps網絡的網絡性能.由于子網間沒有相互串擾,較少因跨網串擾導致的局部子網擁塞,所以10 Gbps網絡模擬組的網絡性能在理論上是40 Gbps網絡進行帶寬4等分網絡的極限性能.
如圖9所示的是2個網絡的最大延遲性能差對比圖.受工作頻率影響,以高頻工作的40 Gbps的分割網絡在接收帶寬小于32 Gbps的情況下,分割后性能優于10 Gbps獨立網絡50%左右;但從高強度注入率的情況看出,分割40 Gbps網絡性能在處理擁塞情況時仍然處于劣勢,性能較10 Gbps獨立網絡要差很多.
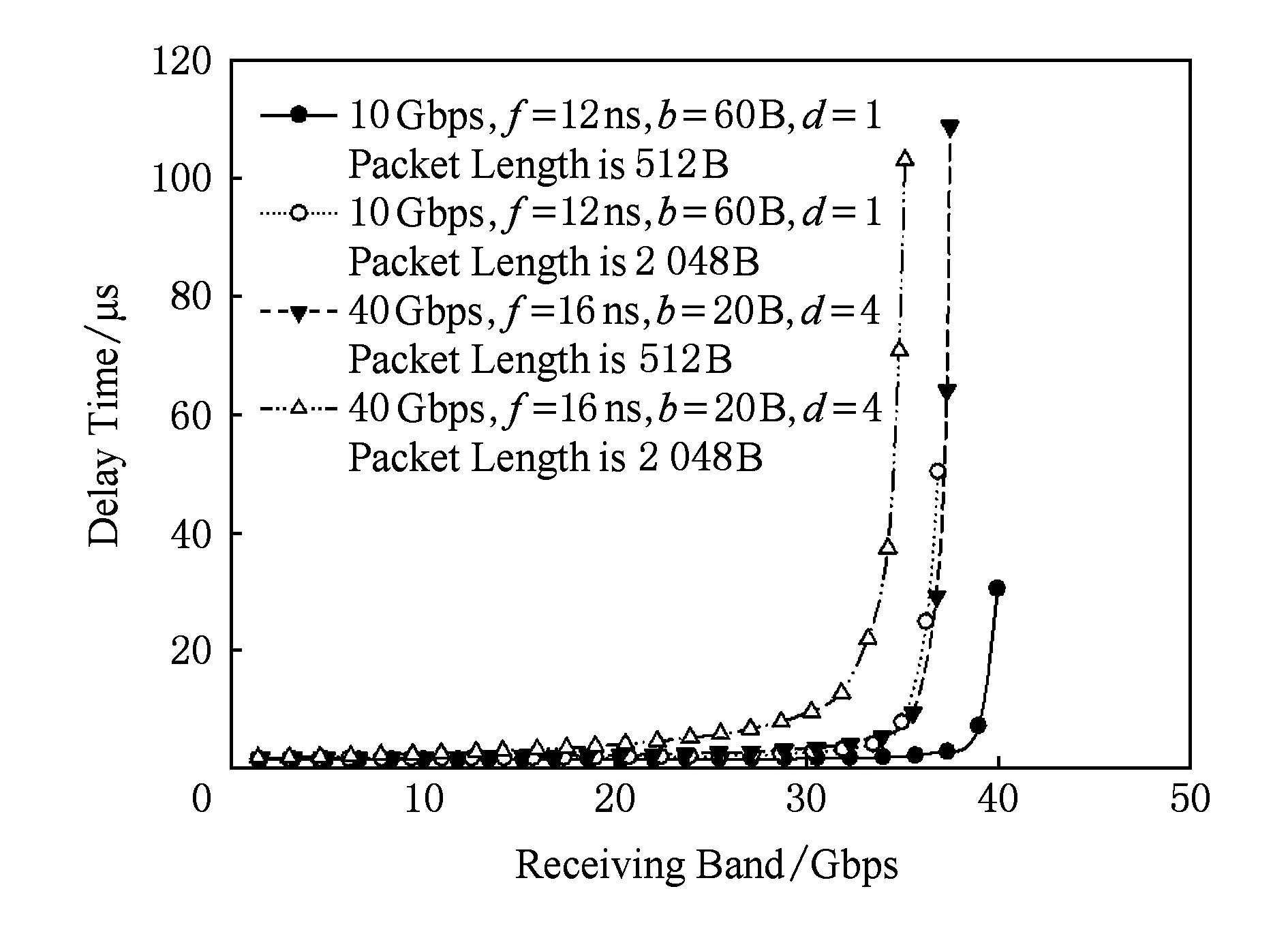
Fig. 9 The simulation of flow partitioning strategy of multi-rail圖9 流量均分策略多軌分割性能仿真
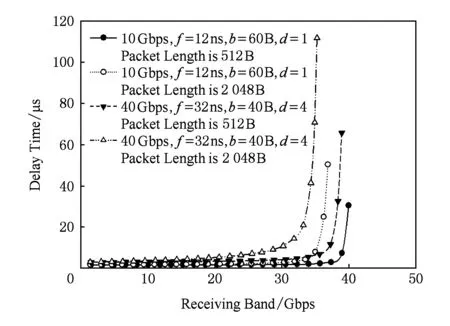
Fig. 10 Supplement simulation of flow partitioning圖10 流量均分策略性能補充仿真
為減少因為工作頻率較高帶來的網絡延遲性能提高,本節仿真特意增加40 Gbps,f=32 ns,b=40 B,d=4仿真組,代表40 Gbps分割網絡在低工作頻率情況下網絡特性的情況.如圖10所示2個網絡的最大延遲性能差對比圖.可以看出整體趨勢受到降低工作頻率的影響,在低注入率時性能提升幅度減小到10%左右.
4.2數據均衡分片對比仿真
在2.2節中對多軌網絡性能的理論分析,沒有考慮到網絡擁塞情況;但是在實際網絡中,擁塞情況往往會讓網絡性能急劇惡化.結合之前對多軌網絡的研究,多軌網絡雖然擁有結構靈活,且解放高帶寬網絡設備依賴等問題;但是由于網絡路徑數量隨分割度正比增加,分割多軌網絡的通信性能會因任何一條擁塞的鏈路導致整個網絡的通信傳輸性能下滑.
本次仿真中對20 Gbps,40 Gbps,80 Gbps高帶寬網絡中傳輸的數據包進行數據均勻分片,比如4 096 B數據包在4×10 Gbps網絡中,通過(4 096-16)/4+16=1 036 B在4段均分數據分片網絡中4路子網并行傳輸1 036 B數據包.結合之前所實現的子網間流量均衡,4 096 B數據包在40 Gbps高帶寬網絡傳輸的網絡性能對比對象即為:1 036 B數據包在4×10 Gbps多軌分割網絡傳輸的網絡性能,以此類推.所得到的網絡特性結果如圖11~16所示:
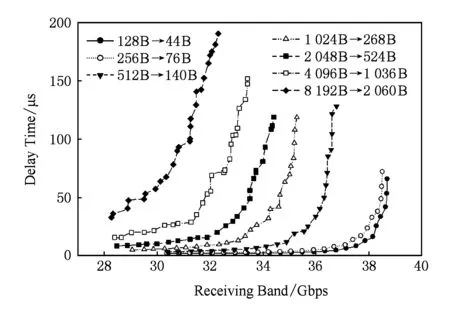
Fig. 11 Network latency performance of multi-rail in 4×10 Gbps圖11 4×10 Gbps多軌網絡延遲性能
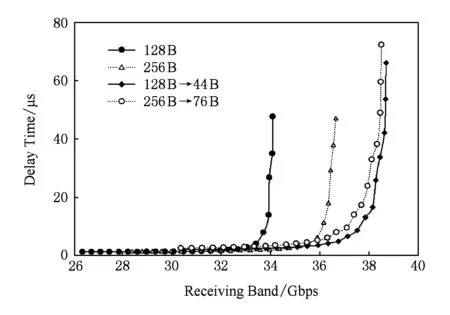
Fig. 12 The performance of light load圖12 輕重量數據載荷性能對比

Fig. 13 The performance of medium load圖13 中等重量數據載荷等性能對比
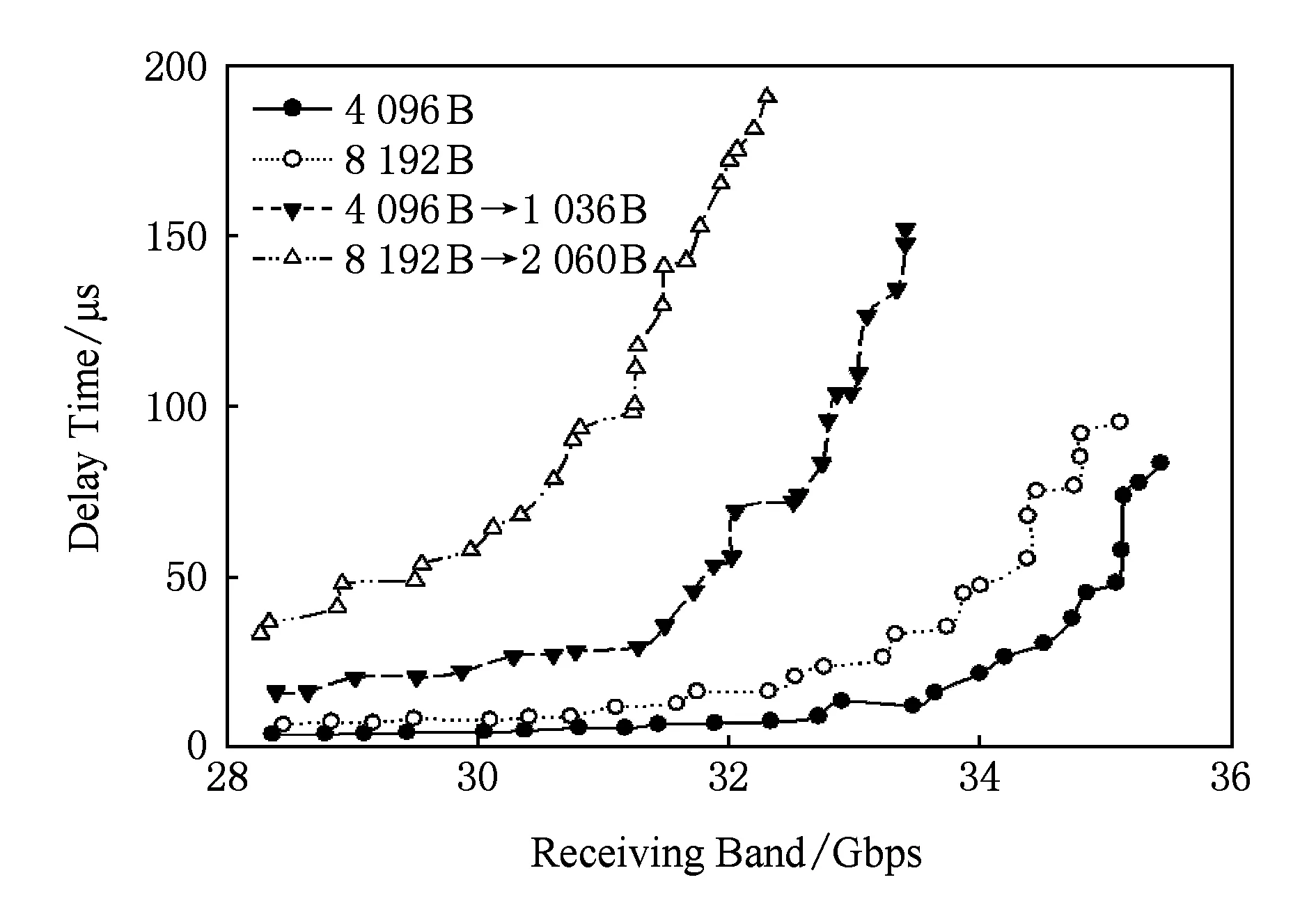
Fig. 14 The performance of weight load圖14 重度重量數據載荷度性能對比
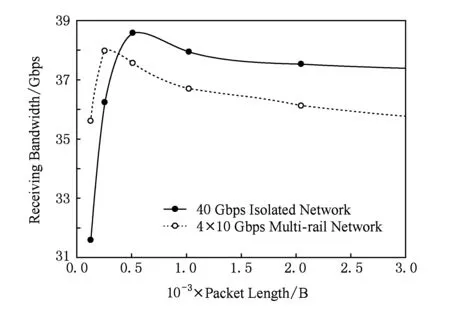
Fig. 15 The bandwidth variation of maximum load圖15 網絡的最大負載帶寬變化曲線
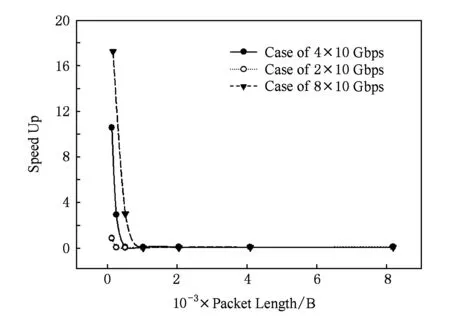
Fig. 16 Practical improvement of multi-real network圖16 多軌網絡的實際性能提升倍數
4×10 Gbps多軌網絡進行不同數據大小傳輸下的網絡延遲性能,如圖11曲線所示.多軌網絡的網絡傳輸性能隨網絡負載數據包的包長逐步增大,網絡出現擁塞的情況就會更早地出現,且網絡負載數據包越長,網絡最大流量帶寬隨之降低.結合圖1中的數據可體現出網絡最大流量帶寬的范圍.
40 Gbps高帶寬胖樹網絡與4×10 Gbps多軌網絡在輕重量數據載荷傳輸情況下網絡性能對比結果,如圖12所示.圖12中128 B→44 B與256 B→76 B兩條線表示在4×10 Gbps分割網絡中分別傳輸44 B和76 B兩種數據流量情況下的網絡延遲性能,分別與128 B和256 B兩種數據負載在40 Gbps高帶寬胖樹網絡中的網絡性能進行對比.圖12顯示,128 B和256 B這2種數據負載屬于輕重量數據載荷;在這種負載情況下,多軌網絡表現出網絡傳輸性能優勢的現象,且多軌網絡的接收帶寬也比單獨高帶寬網絡要高.
40 Gbps高帶寬胖樹網絡與4×10 Gbps多軌網絡在中等重量數據載荷傳輸情況下網絡性能對比結果,如圖13所示.從圖13中可以看出,在512 B,1 024 B,2 048 B這3種數據負載屬于中等重量數據載荷;在這種負載情況下,多軌網絡表現出網絡傳輸性能出現劣勢的現象,且多軌網絡的接收帶寬也比單獨高帶寬網絡要低.
40 Gbps高帶寬胖樹網絡與4×10 Gbps多軌網絡在重度重量數據載荷傳輸情況下網絡性能對比結果,如圖14所示.從圖14中可以看出,在4 096 B和8 192 B這2種數據負載屬于重度重量數據載荷;在這種負載情況下,多軌網絡表現出網絡傳輸性能出現更加劣勢的現象,多軌網絡的接收帶寬不僅比單獨高帶寬網絡要低,而且比中等載荷仿真中更加明顯.
40 Gbps高帶寬胖樹網絡與4×10 Gbps多軌網絡在不同數據包長載荷情況下網絡的最大負載帶寬情況,如圖15所示.從圖15中看到,在較低負載情況下虛線的多軌網絡接收帶寬還處于較高的位置,但在數據負載大于400 B后,表明多軌網絡的整體網絡處理能力的最大負載帶寬要低于高帶寬胖樹網絡,且隨著網絡負載包長的增加,最大負載帶寬有進一步降低的趨勢.從圖15中的波峰位置可以看出,無論是高帶寬胖樹網絡還是多軌網絡,2種網絡都有最佳網絡負載點,低于或高于該點網絡整體性能都會有所下滑.針對同一總網絡帶寬情況下網絡分割程度不同,如何影響最佳網絡負載點的移動,還需對如40 Gbps高帶寬胖樹網絡與8×5 Gbps多軌網絡對比仿真的類似仿真進行分析.
單鏈路帶寬20 Gbps,40 Gbps,80 Gbps的3種網絡的高帶寬胖樹網絡與相應的10 Gbps多軌網絡在不同數據包長載荷情況下的實際策略性能提升倍數,如圖16所示.結合第2節的理論分析可以證實,理論分析的整體趨勢確實存在,但是受到網絡擁塞和多軌網絡流量分配策略誤差等綜合情況的影響,提升倍數與理論分析結果間存在差異.
5 總結及下一步工作
在交換芯片聚合帶寬確定的條件下,本文所提出的多軌分割網絡的每條子網帶寬需要根據分割度進行等比例縮減.網絡多軌分割后,帶寬分配的網絡可擴展性更好.應對多發性局部流量擁塞造成的網絡阻塞情況,單一的高帶寬網絡拓撲結構由于流量分配、擁塞避免算法的路徑切換顆粒度不夠小,無法避免多發性擁塞造成的擁塞情況.
輕載荷網絡負載下的網絡延遲性能根據分割度的提升也展現出了正比優勢.在實際的系統中,短消息占據了數據中心網絡的大部分流量.在文獻[11]中,根據Facebook數據中心對數據負載情況的統計結果,主要數據負載集中在長度小于200 B的數據包上,基于Hadoop的大數據應用也存在同樣的負載特征.以PageRank為例,在map,shuffle,reduce在內的3個主要工作階段中數據負載包長接近60%的負載流量都集中在小于128 B區間.
分析結果表明,本文的多軌分割網絡有利于提高短消息的延遲性能,因此該結論對于優化實際網絡系統的性能有重要指導意義.評測結果客觀體現了多軌分割網絡自身固有的性能局限.在網絡擁塞狀態下,相較于高帶寬網絡,多軌分割網絡會出現更快的網絡性能下降現象.而該現象的主要成因是網絡流量處于非絕對平均狀態,且多軌策略鋪設了更多的網絡路徑,鏈路出現擁塞的概率得到增加.所以,網絡設計者在進行多軌網絡設計時,除了需要根據網絡路徑和端口虛通道流量分配策略進行體系結構設計,還需要結合網絡流量的實際熱點特征,針對網絡熱點端口,加大網絡端口隊列緩沖深度或提升關鍵路徑的路徑帶寬,來緩解多軌化分割后熱點路徑的擁塞問題.本文對多軌分割網絡的研究還僅僅處于初步探索階段.未來工作中會將非對稱網絡與網絡多軌化相結合.深入網絡局部性多軌化策略以及非對稱交換機方面的研究,針對實際大規模計算集群部署時出現的問題展開新的工作.同時,也將會進一步深入到目前實際集群應用的相關通信特性分析,探討針對各種實際應用使用下的網絡多軌優化設計方法和相應的優化策略.網絡多軌化策略目前值得進一步研究的問題還有很多,該思想會逐步成為高性能計算和大數據網絡體系結構的重要研究熱點.
致謝感謝中國科學院國有資產經營有限責任公司對本論文的大力支持!感謝中科院計算所的王展博士對本論文在網絡體系結構方面的技術指導!
[1]Wang Dawei, Cao Zheng, Liu Xinchun, et al. Research and design of high performance interconnection network switch [J]. Journal of Computer Research and Development, 2008, 45(12): 2069-2078 (in Chinese)(王達偉, 曹政, 劉新春, 等. 高性能互聯網絡交換機研究與設計[J]. 計算機研究與發展, 2008, 45(12): 2069-2078)
[2]Cao Zheng. Research on interconnection network of dawning 5000 high productivity computer[D]. Beijing: Institute of Computing Technology, Chinese Academy of Sciences, 2009 (in Chinese)(曹政. 曙光5000高效能計算機系統的互連網絡研究[D]. 北京: 中國科學院計算技術研究所,2009)
[3]Brunet E, Trahay F, Denis A. A multicore-enabled multirail communication engine[C]Proc of IEEE Int Conf on Cluster Computing. Piscataway, NJ: IEEE, 2008: 316-321
[4]Liu Jiuxing, Vishnu A, Panda D K. Building multirail infiniband clusters: MPI-level design and performance evaluation[C]Proc of the 2004 ACMIEEE Conf on Supercomputing. Los Alamitos, CA: IEEE Computer Society, 2004: 33
[5]Salvador C. Static allocation of multirail networks [EBOL]. (2012-08-16)[2015-07-18].https:www.researchgate.netpublication2546969_Static_Allocation_of_Multirail_Networks
[6]Raikar S, Subramoni H, Kandalla, K, et al. Designing network failover and recovery in MPI for multi-rail infiniband clusters[C]Proc of IEEE Parallel and Distributed Processing Symp Workshops. Piscataway, NJ: IEEE, 2012: 1160-1167
[7]Qian Ying, Afsahi A. Efficient RDMA-based multi-port collectives on multi-rail QsNet II clusters[C]Proc of the 20th Int Conf on Parallel and Distributed Processing. Los Alamitos, CA: IEEE Computer Society, 2006: 273
[8]Qian Ying, Afsahi A. High performance RDMA-based multi-port all-gather on multi-rail QsNet Ⅱ[C]Proc of the 21st Int Symp on High Performance Computing Systems and Applications (HPCS 2007). Piscataway, NJ: IEEE, 2007: 3
[9]Qian Ying, Afsahi A. RDMA-based and SMP-aware multi-port all-gather on multi-rail QsNet Ⅱ SMP clusters[C]Proc of the 42nd Int Conf on Parallel Processing. Piscataway, NJ: IEEE, 2007: 48
[10]Cai Jie, Rendell A P, Strazdins P E. Non-threaded and threaded approaches to multirail communication with uDAPL[C]Proc of the 6th IFIP Int Conf on Network amp; Parallel Computing (NPC 2009). Piscataway, NJ: IEEE, 2009: 233-239
[11]Arjun R, Hongyi Z, Jasmeet B, et al. Inside the social network’s (datacenter) network [J]. ACM SIGCOMM Computer Communication Review, 2015, 45(5): 123-137
[12]Theophilus B, Ashok A, Aditya A, et al. Understanding data center traffic characteristics [J]. ACM SIGCOMM Computer Communication Review, 2010, 40(1): 92-99

ShaoEn, born in 1988. PhD candidate, engineer. His main research interests focus on SDN, big data, high performance interconnection, and optical network.

YuanGuojun, born in 1983. PhD candidate, engineer. His main research interests include computer architecture and optical flexible network.

HuanZhixuan, born in 1990. MSc candidate. His main research interests include inter-connection networks, computer architec-ture and parallel computing.

CaoZheng, born in 1982. PhD, associate professor. His main research interests include high performance computer archi-tecture, high performance interconnection, and optical interconnection.

SunNinghui, born in 1968. PhD, professor, PhD supervisor. His main research interests include computer architecture, high perfor-mance computing and distributed OS.
ASlicedMulti-RailInterconnectionNetworkforLarge-ScaleClusters
Shao En1,2, Yuan Guojun1,2, Huan Zhixuan1,2, Cao Zheng1, and Sun Ninghui1
1(State Key Laboratory of Computer Architecture (Institute of Computing Technology, Chinese Academy of Sciences), Beijing 100190)2(University of Chinese Academy of Sciences, Beijing 100049)
In large-scale clusters, the design of interconnection network is facing greater challenges. Firstly, the increasing computing capacity of a single node requires the network providing higher bandwidth and lower latency. Secondly, the increasing number of nodes requires the network to have extremely better scalability. Thirdly, the increasing scale of system leads to worse performance of collective communication, which is harmful to the performance and scalability of applications. Fourthly, the increasing number of devices requires the network to have better reliability. As the performance of computing nodes keeps increasing, interconnection network has gradually become the bottleneck of large-scale computing system. However, switch chip, the core component of interconnection network, can offer limited aggregate bandwidth because of the constraint of physical processes and packaging technologies. With the co-design of network architecture and switch micro-architecture, this paper proposes a sliced multi-rail network architecture regarding the given aggregate bandwidth. Through mathematical modeling and network simulation, we studies the performance boundaries of sliced multi-rail network. Evaluation results show that the average latency of the short message (less than 128B)can be increased by more than 10 times.
large-scale clusters; multi-rail network; bandwidth division; data center network; large-scale network simulation
2015-12-09;
2016-05-25
國家重點研發計劃項目(2016YFB0200300,2016YFGX030148,2016YFB0200205,2016GZKF0JT006);國家自然科學基金項目(61572464,61331008,61402444);國家“八六三”高技術研究發展計劃基金項目(2015AA01A301);華為科研基金項目(YB2015070066);中國科學院戰略性先導科技專項(XDB24060600)
This work was supported by the National Key Research and Development Program of China (2016YFB0200300, 2016YFGX030148, 2016YFB0200205, 2016GZKF0JT006), the National Natural Science Foundation of China(61572464, 61331008, 61402444), the National High Technology Research and Development Program of China (863 Program) (2015AA01A301), the Scientific Research Foundation of Huawei (YB2015070066), and the CAS Strategic Priority Program (XDB24060600).
TP303
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
