基于U-Net的乳腺癌病理切片中癌細胞檢測方法
2018-02-13 09:58:30
精準醫學雜志 2018年6期
(1 北京航空航天大學計算機學院,北京 100083; 2 青島大學附屬醫院,山東省數字醫學與計算機輔助手術重點實驗室,山東省高等學校數字醫學臨床診療與營養健康協同創新中心; 3 北京建筑大學電氣與信息工程學院)
隨著計算機視覺技術與存儲技術的快速發展,研究人員已經在醫學影像領域提出了很多基于圖像的分析、輔助診斷工具,例如自動并且高效地完成一些常規的病理圖像分析任務,或精確地對一腫瘤組織給出定位或病理等級等等。近年來,隨著深度學習技術特別是卷積神經網絡(CNN)模型在目標檢測以及分割方面的發展,基于CNN的方法連續在MICCIA的病理全切片腫瘤細胞識別挑戰賽中取得了很好的成績[1],CIREGAN等[1]基于CNN的概率圖加后處理技術實現了對乳腺癌病理圖像有絲分裂細胞的檢測,借助非極大值抑制(NMS)提升最終的檢測效果。DONG等[2]提出了一個9層的CNN結構,基于圖像的YUV色彩空間信息對斑馬魚細胞進行探測。MAO等[3]提出了一個基于7層CNN的探測方法,并實現針對圓形腫瘤細胞的不同模態顯微圖像的探測。有學者將細胞檢測問題轉化為逐級優化問題,并實現了對神經細胞和肺癌細胞核的探測[4]。全切片技術可以對細胞進行多尺度成像,SONG等[5]針對此類細胞圖像提出了一個多尺度CNN框架,從而實現了對細胞的多尺度交叉探測。本研究提出了一種基于U-Net的乳腺癌淋巴結病理切片中的細胞檢測方法,用以輔助醫生進行乳腺癌細胞的篩查。現將結果報告如下。
1 材料與方法
1.1 材料來源
樣本來源于凱斯西儲大學49例淋巴結陰性和雌激素受體陽性的乳腺癌病人[6]。每幅圖像的尺寸為2 200×2 200像素,每張圖片大約有1 500個核。HE染色乳腺組織病理學玻片,采用高分辨率全玻片掃描儀Aperio ScanScope digitizer在40倍光學放大率下掃描并輸入至計算機。將圖像隨機分為兩組進行訓練。
1.2 數據預處理
將數據集中標注癌細胞的區域裁剪出來(圖1A),并在標注為癌細胞的位置作出癌細胞的mask(圖1B),作為訓練過程的原始圖像與目標圖像(像素值均縮放到0~1范圍內)。
1.3 研究方法
采用深度學習中的U-Net[7]網絡架構對乳腺癌細胞的病理切片進行分割,并對乳腺癌細胞進行自動檢測。
1.4 深度學習網絡結構
在自然圖像和醫學圖像領域,圖像分割都是一個重要的步驟。CNNs將每個像素點用其周圍的像素所表示來對每個像素進行單獨的分類。原始的滑動窗口方法因為其每次計算相鄰像素時都會有重疊部分,這使得相同的計算會重復多次。因為卷積和內積操作都是線性算子,所以將全連接層重寫為卷積層,將大大提高卷積網絡的效率。CNNs可以接受比其訓練時尺寸更大的圖像的輸入,并且產生一個概率譜圖。
然而,因為池化層的存在,將會導致輸出的結果比輸入圖片的分辨率低。“轉移和合并”是LONG等[8]在2015年提出的一種防止圖片分辨率下降的方法。FCN通過將輸出結果合并在一起,得到了高分辨率的輸出結果,減少了由于有效卷積操作而帶來的像素損失。
RONNEBERGER等[7]在同年吸取了FCN的優點,進一步地提出了U-Net結構。U-Net在基礎的FCN結構之后又加入了上采樣操作,將整個結構分為圖像的收縮和擴張兩個部分。雖然這不是首次提出在網絡結構中加入上采樣操作,但是U-Net在收縮和擴張兩個過程之間加入了聯結操作,使得輸出的結果能夠更加地逼近預期。FROMER等[9]在2016年將此方法運用在三維數據中并取得良好效果。MILLETARI等[10]同年基于U-Net延伸出了加入殘差模塊和Dice損失函數的V-Net,由于不再采用交叉熵損失函數,得到的分割結果更加接近于預期結果。
采用U-Net的端到端網絡結構對數據集進行訓練,U-Net結構圖如圖2。深度學習中主要通過卷積操作來獲取圖片中的信息,并通過這些信息來對結果進行預測。本文所用到的U-Net結構首先通過卷積操作來對乳腺癌病理圖像進行信息提取(癌細胞的紋理、大小、形狀、色澤等),再通過上采樣操作使富集的信息“翻譯”到整張圖片上,得到每一個像素點處屬于癌細胞的概率。
1.5 實驗過程
通過數據增強來增加訓練數據,本研究采用旋轉和數據正則化兩個操作來構建網絡輸入的生成器,使得訓練及測試數據擴大了4倍。為了使得預測結果更加接近真實結果,本研究采用U-Net網絡中常用的損失函數Dice:
其中,P為網絡預測的結果,T為真實的癌細胞圖像的mask。
通過損失函數Dice,網絡的預測結果將逐漸逼近真實結果,在經過500次訓練之后,將最后20次迭代的模型融合,得到較為準確的預測模型。見圖3。
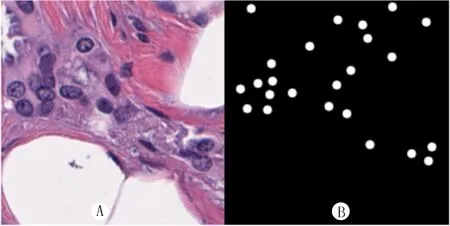
A:原始癌細胞圖像;B:癌細胞的mask。
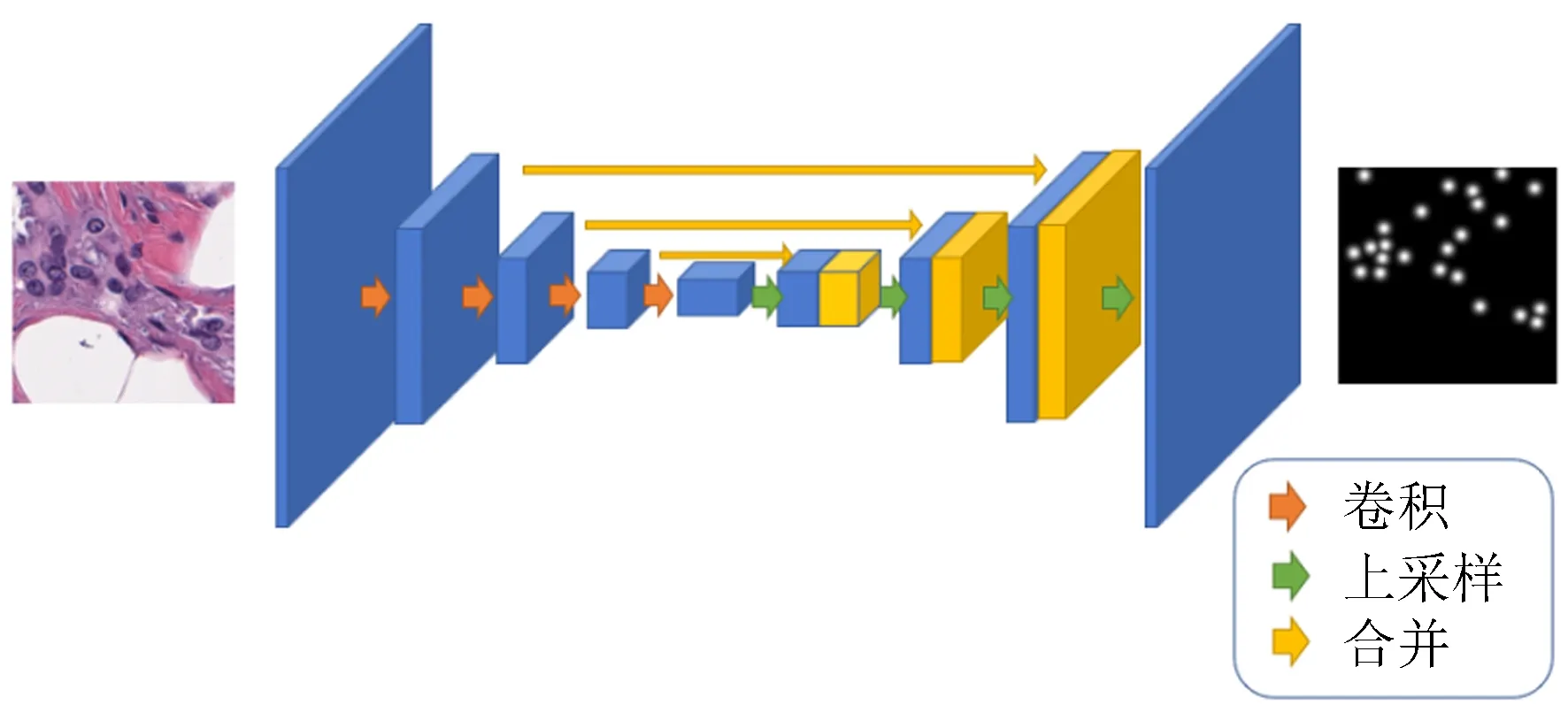
圖2 U-Net結構圖

A:原圖像,B:預測結果,C:真實結果。
本實驗采用十等分交叉驗證對模型進行評估,即將訓練集圖片十等分,每次取其中9份作為訓練集,剩下的1份作為驗證集,最終將模型在測試集上進行評估。
2 結 果
Dice得到的準確率衡量預測結果與真實結果的重合程度,是對整張圖片的度量,但由于癌細胞形狀不都為規則的圓形,所以本文采用檢測準確率對模型進行進一步評估,即對圖片中每個細胞進行進一步的評估。
對每個癌細胞預測的準確率(p)作為評估標準。p=c_s-c_p,其中c_s為真實結果中癌細胞圓心所在位置的像素值(0~1),c_p為預測結果中癌細胞圓心所在位置的像素值(0~1)。將所有癌細胞進行統計分析,結果見表1。通過表1可以看出模型對于癌細胞非常敏感,圖片中存在的癌細胞基本可以檢測到。
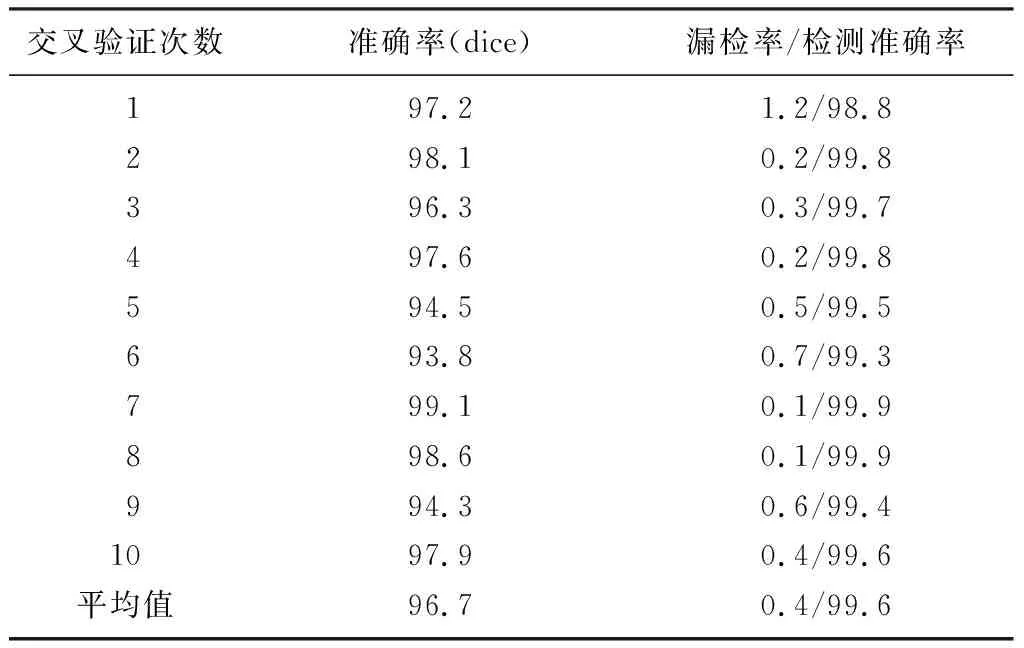
表1 癌細胞檢測結果(χ/%)
注:準確率為模型對每張圖片擬合效果的度量結果;檢測準確率為測試階段針對每個細胞的度量結果。
3 討 論
深度學習方法目前已經在很多實際任務上有所突破,并且這些任務可以應用到醫學問題中,進而解決相應的醫學問題[11-16]。同時,一些特定的醫學領域如放射基因組學、預后評估等都可以用機器學習及深度學習來解決[17-20]。
本研究模型在不考慮假陽性的情況下達到了100%的準確率,通過實驗結果可以看出,本模型漏診概率小,但是會檢測出相當一部分假陽性的細胞。有以下幾種原因:①醫生在進行判斷時會對病人進行綜合考慮,比如病人的病狀、并發癥等等,但網絡只能從圖片中獲取信息。②標注的病理圖像中有許多類似但標注不同的細胞,導致模型無法識別。③沒有精確的mask給予網絡進行學習。
本研究實驗結果表明,深度學習在病理圖像的細胞檢測及分割方面具有良好的表現;模型泛化效果較好,對于不明顯的細胞也能給出其為癌細胞的概率(通過結果中的顏色深淺表示)。
本實驗說明深度學習可以比人識別得更快,雖然會有假陽性的出現,但這會大大減少病理醫生的工作量。在醫學圖像方面還有很大的空間可以發揮深度學習的作用,如CT、MRI等圖像都可以通過深度學習來進行疾病預測、病灶分割等實際應用。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中國生殖健康(2019年2期)2019-08-23 08:11:42
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
中國生殖健康(2019年6期)2019-01-06 09:20:12
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
