巧妙區分中文和英文字符
2018-02-24 19:36:55王志軍
電腦知識與技術·經驗技巧 2017年9期
王志軍
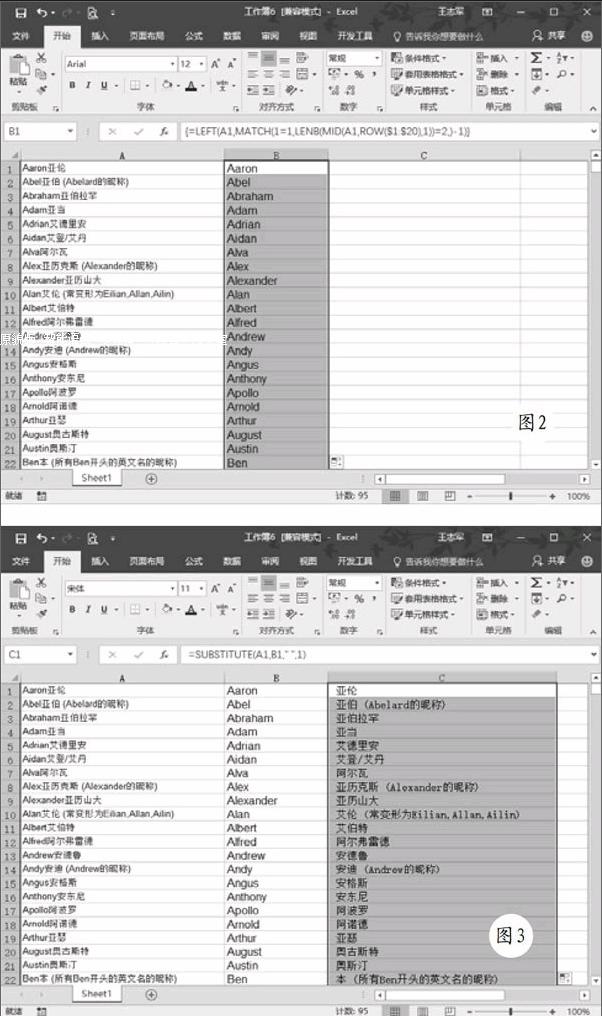

最近在工作中遇到一個問題,如圖1所示,A列是包含中文和英文的混合字符串,現在需要將其區分開來,例如“Abel亞伯(Abelard的昵稱)”分隔為“Abel”和“亞伯(Abelard的昵稱)”,雖然可以復制到Word利用替換功能查找替換為空,但由于源數據還混雜了一些類似于“Ahdard的昵稱”的字符串,因此這一方法并不現實。那么除了手工操作之外,有沒有簡單一些的方法呢?
我們可以借助數組公式完成上述任務,選擇B1單元格,在編輯欄輸入公式“=LEFT(A1,MATCH(1=1,LENB(MID(A1,ROW($1:$20),1))=2,)-1)”,這里的ROW函數可以返回一個引用的行號,MID函數可以從文本字符串中指定的起始位置起返回指定長度的字符,LENB函數則可以返回文本中所包含的字符數,此時漢字按2個字節進行計算,MATCH函數可以返回符合特定值特定順序的項在數組中的相對位置,最后利用LEFT函數從第一個字符開始返回指定個數的字符,按下“Ctrl+Shift+Enter”組合鍵轉換為數組公式。公式執行之后向下拖拽或雙擊填充柄,很快就可以看到圖2所示的效果。后面的內容則可以使用SUBSTITUTE函數進行替換,在C2單元格輸入公式“=SUBSTITUTE(Al,Bl,””,1)”,這里的第三參數“1”不可省略,否則會導致后面的英文字符也被同時替換,例如“Abel亞伯(Abelard的昵稱)”得到“亞伯(ard的昵稱)”的效果,那么就不是我們的原意了,公式執行之后向下拖拽或雙擊填充柄,最終效果如圖3所示。
C列的字符串,也可以使用“=MID(A1,MATCH(1=1,LENB(MID(A1,ROW($1:$20),1))=2,),99)”的數組公式,效果完全相同。endprint
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
Coco薇(2016年8期)2016-10-09 02:11:50
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
中國遠程教育(2016年2期)2016-03-21 10:31:21
中國遠程教育(2016年1期)2016-02-26 10:37:15
