面向密集人群計數的兩列串行空洞卷積神經網絡
2018-02-24 13:55:24趙傳強尚永生
電腦知識與技術 2018年34期
趙傳強 尚永生

摘要:提出了一種簡稱為DSDCNN的面向密集人群計數的兩列串行空洞卷積神經網絡。DSDCNN可以識別高度擁擠的場景,得到精確的人群估計數量和估計密度圖。DSDCNN是由兩列卷積神經網絡構成,并通過使用空洞卷積,使得每列卷積具有不同大小視野域,可以輸入不同尺寸和像素的圖片,并通過空洞卷積代替了池化層。DSDCNN網絡是由小卷積核濾波器構成,網絡架構易于搭建和訓練。實驗結果表明,DSDCNN能夠較精確得到人群計數和估計密度圖,具有較好的平均絕對誤差MAE。
關鍵詞:人群計數;估計密度圖;空洞卷積
中圖分類號:TP311? ? ?文獻標識碼:A? ? ?文章編號:1009-3044(2018)34-0164-04
1引言
現在越來越多的人群計數模型已經被開發[1-7],為我們解決人群流量監測提供了解決方案。而人群流量監測是解決很多方面問題的關鍵,例如在安全監控、災難管理、公共空間設計、情報的收集及分析等,而在不同的領域需要我們開發出各種各樣的模型,如計算、密度估計、分割、行為分析、跟蹤、場景理解和異常檢測等。而人群計數和密度估計是最基本的任務,是之前所說的各種任務模型的基礎,因此人群計數和密度估計仍需深入研究。
在過去的幾年里研究人員通過各種方法來解決人群計數和密度估計的問題,而最近基于卷積神經網絡(Convolutional Neuarl Network , CNN)的方法與傳統的方法相比有了明顯的改進,并在人群計數領域取得了很好的成績,但是這些模型還存在一些不足的地方。
因此,本文通過對張[6]和李[7]模型的借鑒和優化,提出了一種新的網絡模型:基于兩列串行空洞卷積神經網絡(double serial dilated convolutional neural network, DSDCNN)模型。DSDCNN模型是使用純卷積層作為主干,并通過使用兩列具有不同視野域的卷積層來保證可以輸入不同分辨率的圖像,同時為了限制網絡復雜性,所有的卷積層都使用小尺寸的卷積濾波器,并通過空洞卷積擴展每列卷積的視野域[7]。
2 相關工作
遵循Loy等人[14]和Vishwanath A等人[16]的論述,人群計數模型可以根據網絡的特性以及訓練方法,將基于CNN的方法大致分為四類:基于CNNs模型、基于標度感知模型、基于上下文感知模型和基于多任務框架模型。基于CNNs的模型是指在網絡中包含了基本的CNN的方法,這些方法是用于人群計數和密度估計的初始深度學習方法之一;基于標度感知模型是指在基于CNN方法之上形成的更復雜的模型,對于標度具有魯棒性;基于上下文感知模型是指將圖片中出現的ground truth和全局上下文信息合并到CNN框架中;基于多框架任務模型是指將人群計數和估計與其他人結合到一起。以下是近幾年來基于CNN 的一些解方案大部分方法是2017年之后,2017年之前的方法可以參考文獻[16]。
自2016年張[6]提出了經典的多列卷積神經網絡(MCNN)架構以來,多列卷積神經網絡被廣泛應用。Nair, V等人[8]提出了一個簡單到復雜框架,它使用初始DCNN作為分割網絡進行訓練,在基于初始DCNN以及圖像級注釋的簡單圖像的預測分割基礎上,進行網絡監督學習。Sindagil[5]提出了一種稱為上下文金字塔CNN的方法,它使用CNN網絡在不同級別估計上下文,以實現更低的計數誤差和更好質量的估計密度圖。
而Lokesh Boominathan等人[15]提出一種新穎的深度卷積神經網絡結構,通過使用深度可分離卷積,在不增加容量的前提下,使得性能增益,更有效地使用模型參數。Fisher Yu等人[9]則是在深度卷積上使用分類網絡來解決弱監督語義分割問題。[15]提出了一種深度學習框架,通過使用深度、淺度多尺度完全卷積的網絡組合來預測給定人群圖像的密度圖,它即可以有效地捕獲高級語義信息(面部/身體檢測器),也可以捕獲低級特征(斑點檢測器)。李[7]則是在他們的基礎上提出了CSRNet網絡模型,它是通過使用卷積神經網絡(CNN)進行特征提取,并作為深度卷積神經網絡結構的前端,并使用空洞卷積來作為深度卷積神經網絡結構的后端。
3 DSDCNN設計
綜合相關文獻[6]、[7]、[14],基于卷積神經網絡的人群計數的一般流程分為:原始圖像經過CNN模型,得到其密度圖,進行求和,得到人數。在整體流程中核心部分為CNN模型,因為CNN模型的性能直接決定了人群計數的性能;而不同的CNN模型是由不同的網絡架構進行訓練得到,因此網絡結構的搭建至關重要。
3.1 網絡架構
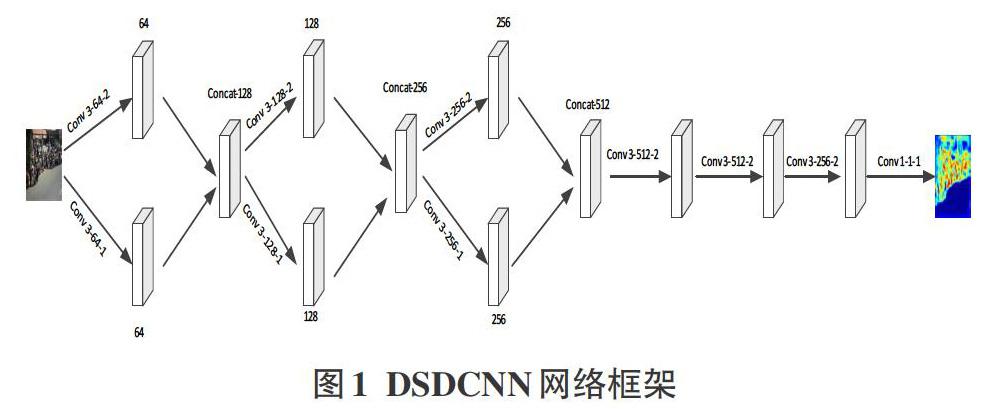
在構建網絡架構時,本文借鑒了文獻[6]的MCNN網絡架構以及文獻[7]的CRSCNN網絡架構。選取MCNN中的多列分支架構,又通過選取CSRCNN網絡中的小核卷積以及空洞卷積,搭建兩列分支的串行空洞卷積神經網絡架構(DSDCNN),具體架構如圖1所示。圖中卷積層的參數表示為Conv X-Y-Z, X是指卷積層的卷積核大小,都設置為3;Y是指每層卷積所學習的特征值的個數;Z是指空洞卷積的空洞率大小值。
DSDCNN是由兩列卷積神經網絡構成,又通過利用空洞卷積使得每一列卷積神經網絡在保持小卷積核的前提下具有不同大小的感受域,因此可以輸入任意大小或分辨率的圖像,同時網絡中所有的卷積層都是使用padding來維持輸入和輸出圖片大小一致。
3.1.1 具體參數
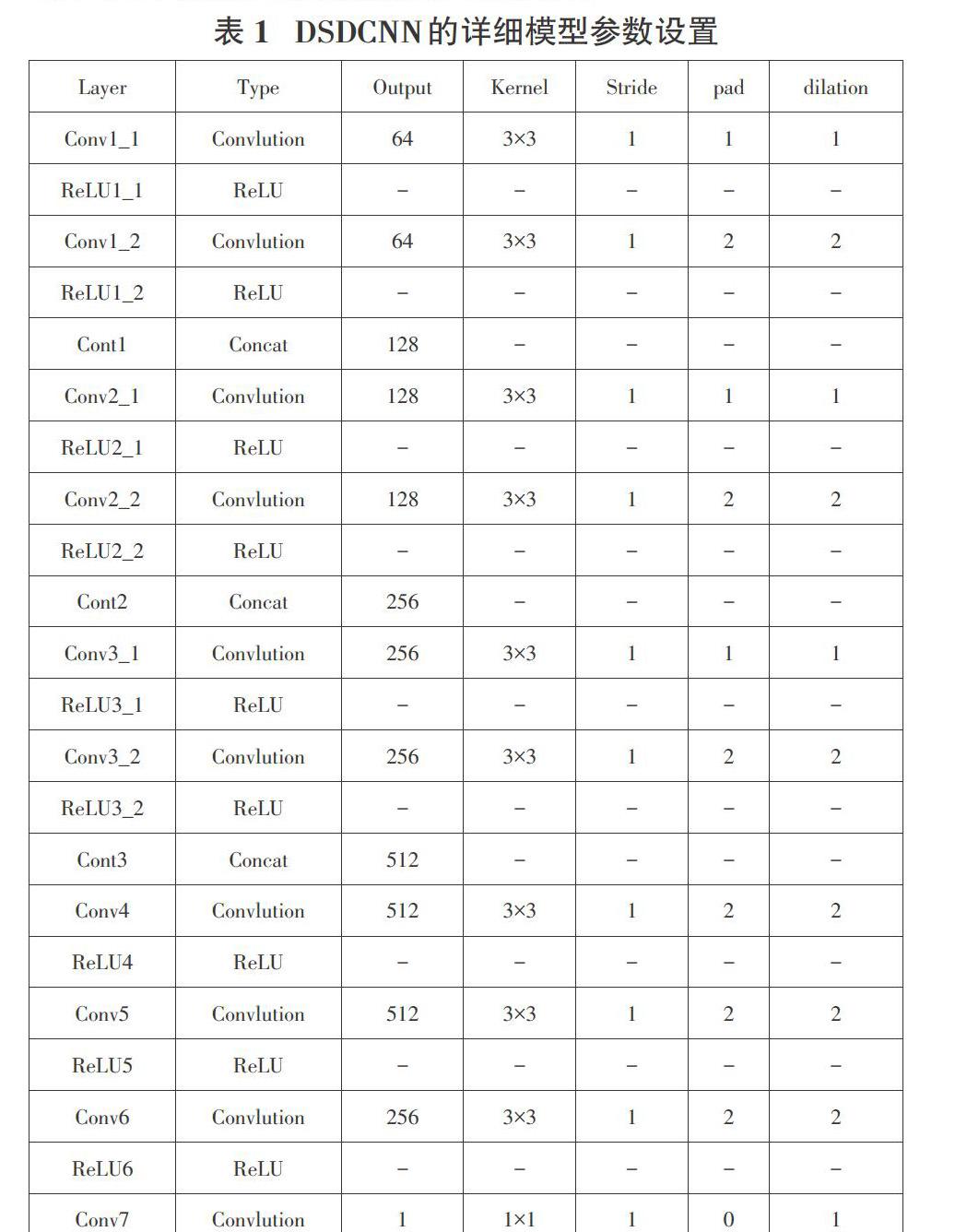
本文所提出的網絡架構如圖1所示,大體可分為兩部分,第一部分是由三個并列卷積層構成;在第一部分第一小模塊中,包含了兩個濾波器大小均為3×3,不過第一個濾波器的空洞率設置為1,第二個濾波器的空洞率設置為2,然后每一個卷積層將會產生64個特征映射,然后通過線性函數進行加權生成128個特征圖;第二小部分開始時,每個卷積層將會輸入128個特征映射,并經過兩層映射后,經線性函數加權生成256個特征圖;同樣在第三小部分中,每層卷積會被輸入256個特征映射,然后加權生成為512個特征圖。在第二部分中,是由三個卷積層串行組成;第一小部分是由3X3的濾波器構成,其空洞率為2,具有512個特征圖;第二小部分和第三小部分同第一部分構成是一樣的,同樣具有512個特征圖,不過第三小部分具有256個特征圖。最后,使用1×1濾波器生成單個特征圖,即生成的密度圖。在整體模型中,只有最后1×1卷積層沒有應用激活函數(Relu)[8],其余卷積層都設置一個Relu層來作為激活函數。表1列出模型架構的詳細參數設置。
3.1.2 空洞卷積
空洞卷積又可以稱之為擴張卷積,是本文網絡架構的關鍵部分之一。在本文中,我們通過使用空洞卷積代替了卷積層和pooling層,因為使用空洞卷積可以在不增加網絡架構的卷積層層數或計算量的情況下擴大了感受野,這從根本上降低網絡架構的復雜程度;同時空洞卷積允許靈活地聚合多尺度上下文信息,保持相同的分辨率[9,10,11],最重要的是,空洞卷積相對于Pooling和卷積層,它輸出以及包含的信息更詳細[7]。
空洞卷積是將具有k×k小卷積核的濾波器[7],擴大為KX×KX卷積核的濾波器,KX =k + (k-1)×(r-1),其中K為原濾波器的卷積核大小,r為空洞卷積的空洞率,KX為擴張之后濾波器的卷積核大小。
3.2 訓練過程
在這一小節,我們闡述了具體的DSICNN訓練細節,與常規的基于CNN的網絡相比較,DSICNN是一種很方便搭建和能快速部署的網絡結構。
4 實驗結果以及分析
4.1條件環境平臺
本文實驗是在PC機上進行的,PC機的硬件包含了一個CPU(Intel i7-7700),一個GPU(4G顯存NVIDIA GTX 1070Ti)和8G內存,DSICNN是基于Caffe平臺[11]來訓練的,PC機的操作系統是Ubuntu14.04。使用的隨機梯度下降(SGD)優化訓練網絡,這個網絡的學習率為10-7,momentum是0.9。
小為x,y,其中μx是x的平均值,μy是y的平均值,σ2x是x的方差,σ2y是y的方差,σxy是x和y的協方差,C1=(k1L)2,C2=(k2L)2,L為像素的動態范圍,k1=0.01,k2=0.03。
4.4 實驗結果
本文分別使用了Shanghaitech數據集中的PartA,PartB數據圖像,得到相對應的密度圖,圖2中的a,b,c,e,f,g分別對應PartA,PartB中的原圖、 ground truth對應的密度圖以及網絡模型訓練得到的密度圖。
為了評估所生成密度圖的質量,使用A部分數據集將我們的方法與MCNN和CP-CNN生成的密度圖通過PSNR和SSIM標準進行比較,結果如表3所示,表明DSDCNN實現了較高的SSIM和PSNR。
我們通過MAE和MSE對本文的方法進行評估,并通過與其他五個最近相似工作進行比較,其評估參數表4所示(其結果來自原始結果)。
4.5 實驗分析
如表4所示,我們的網絡結果略好于其他幾個網絡。通過查閱相關文獻,可以得知在基于CNN的方法中,網絡性能的改進主要通過網絡結構的調整,以及改進密度圖質量來實現。我們的網絡架構是通過采用小核濾波器來限制網絡的復雜程度,并通過空洞卷積從更多維度中提取多尺度特征信息,并不斷對其進行整合,以獲得新的尺寸特征信息,從而獲得更好的實驗結果。
5 結束語
在本文中,我們提出了一個新的架構,稱之為DSDCNN,用于人群計數和生成密度圖。與其他模型相比,我們是通過空洞卷積來聚合擁擠場景的多尺度上下文信息,并通過多列卷積來整合不同尺度和像素圖片信息。我們將我們使用的方法與其他使用Shanghaitech數據集的方法進行比較。DSDCNN模型由于文獻中的大部分模型,具有良好的性能。
參考文獻:
[1] Beibei Zhan, Dorothy N Monekosso, Paolo Remagnino, Sergio A Velastin, and Li-Qun Xu[
j]. Crowd analysis: a survey.Machine Vision and Applications, 19(5-6):345–357, 2008.
[2] Teng Li, Huan Chang, Meng Wang, Bingbing Ni, Richang Hong, and Shuicheng Yan. Crowded scene analysis: A survey[J]. IEEE transactions on circuits and systems for video technology, 25(3):367–386, 2015.
[3] Cong Zhang, Hongsheng Li, Xiaogang Wang, and Xiaokang Yang. Cross-scene crowd counting via deep convolutional neural networks[C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 833–841,2015.
[4] Deepak Babu Sam, Shiv Surya, and R Venkatesh Babu. Switching convolutional neural network for crowd counting[C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 1, page 6, 2017.
[5] Vishwanath A Sindagi and Vishal M Patel. Generating high quality crowd density maps using contextual pyramid CNNs[C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1861–1870, 2017.
[6] Zhang, Y., Zhou, D., Chen, S., et al.: 'Single-image crowd counting via multi-column convolutional neural network'[C]. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 589–597
[7]Li Y, Zhang X, Chen D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes[J]. 2018.
[8] Nair V, Hinton G E. Rectified linear units improve restricted boltzmann machines[C]// International Conference on International Conference on Machine Learning. Omnipress, 2010:807-814.
[9] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. In ICLR, 2016.
[10] L. C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, PP(99):1–1, 2017.
[11] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. CoRR, abs/1706.05587, 2017.
[12] Mark Marsden, Kevin McGuiness, Suzanne Little, and Noel E OConnor. Fully convolutional crowd counting on highly congested scenes. arXiv preprint arXiv:1612.00220,2016.
[13] Vishwanath A Sindagi and Vishal M Patel. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting[C]. In Advanced Video and Signal Based Surveillance (AVSS), 2017 14th IEEE International Conference on, pages 1–6. IEEE, 2017.
[14] Chen Change Loy, Ke Chen, Shaogang Gong, and Tao Xiang. Crowd counting and profiling: Methodology and evaluation[C]. In Modeling, Simulation and Visual Analysis of Crowds, pages 347–382. Springer, 2013.
[15] Lokesh Boominathan, Srinivas SS Kruthiventi, and R Venkatesh Babu. Crowdnet: a deep convolutional network for dense crowd counting[C]. In Proceedings of the 2016 ACM on Multimedia Conference, pages 640–644. ACM, 2016.
[16] Sindagi V A, Patel V M. A survey of recent advances in CNN-based single image crowd counting and density estimation[J]. Pattern Recognition Letters, 2017.
【通聯編輯:梁書】
