Scrapy分布式爬蟲搜索引擎
2018-02-24 13:55:24劉思林
電腦知識與技術 2018年34期
劉思林
摘要:隨著大數據時代的到來,信息的獲取與檢索尤為重要。如何在海量的數據中快速準確獲取到我們需要的內容顯得十分重要。通過對網絡爬蟲的研究和爬蟲框架Scrapy的深入探索,結合Redis這種NoSQL數據庫搭建分布式爬蟲框架,并結合Django框架搭建搜索引擎網站,將從知乎,拉鉤,伯樂等網站抓取的有效信息存入ElasticSearch搜索引擎中,供用戶搜索獲取。研究結果表明分布式網絡爬蟲比單機網絡爬蟲效率更高,內容也更豐富準確。
關鍵詞:網絡爬蟲;Scrapy;分布式;Scrapy-Redis;Django;ElasticSearch
中圖分類號:TP311? ? ?文獻標識碼:A? ? ?文章編號:1009-3044(2018)34-0186-03
1 引言
爬蟲的應用領域非常廣泛,目前利用爬蟲技術市面上已經存在了比較成熟的搜索引擎產品,如百度,谷歌以及其他垂直領域搜索引擎,這些都是非直接目的的;還有一些推薦引擎,如今日頭條,可以定向給用戶推薦相關新聞;爬蟲還可以用來作為機器學習的數據樣本。
論文研究的主要目的是更加透徹的理解爬蟲的相關知識;在熟練運用Python語言的基礎上,更加深入的掌握開源的爬蟲框架Scrapy,為后續其他與爬蟲相關的業務奠定理論基礎和數據基礎;進一步理解分布式的概念,為大數據的相關研究和硬件條件奠定基礎;熟練理解python搭建網站的框架Django,深入理解基于Lucene的搜索服務器ElasticSearch,最終在上述基本知識的基礎上,搭建出一個簡易版本的搜索引擎,實現從網絡上爬取數據,存儲到分布式的Redis數據庫,并最終通過Django和ElasticSearch,實現搜索展現的目的。
2 爬蟲基本原理
網絡爬蟲是一種按照一定規則,自動抓取萬維網信息的程序或者腳本。如果把互聯網比作一張大的蜘蛛網,數據便是存放于蜘蛛網的各個節點,而爬蟲就是一只小蜘蛛,沿著網絡抓取自己的獵物(數據)。爬蟲指的是,向網站發起請求,獲取資源后分析并提取有用數據的程序。
從技術層面來說就是通過程序模擬瀏覽器請求站點的行為,把站點返回的HTML代碼,JSON數據,二進制數據(圖片、視頻)等爬到本地,進而提取自己需要的數據,存放起來供后期使用。
3 Scrapy-Redis分布式爬蟲
3.1 Scrapy
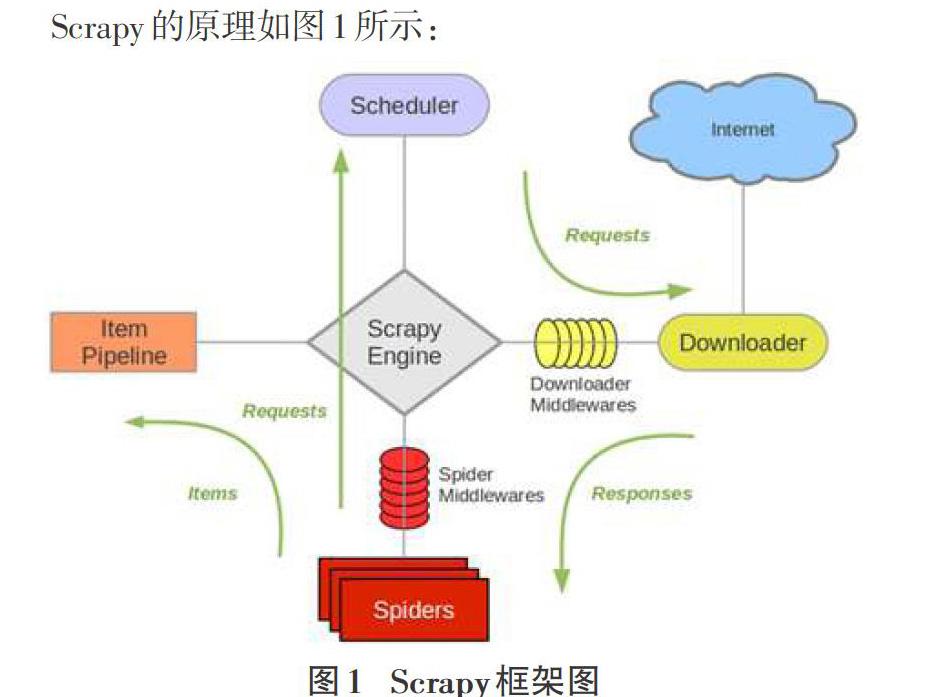
Scrapy的原理如圖1所示:
各個組件的解釋如下:Scrapy Engine(引擎):負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等,相當于人的大腦中樞,機器的發動機等,具有顯著的作用。Scheduler(調度器):負責接收引擎發送過來的Request請求,并按照一定的方式邏輯進行整理排列,入隊,當引擎需要時,再交還給引擎。Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理。Spider(爬蟲):負責處理所有的Responses,從中分析提取數據,獲取Item字段需要的數據,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器)。Item Pipeline(管道):負責處理Spider中獲取到的Item,并進行后期處理(詳細分析、過濾、存儲等)。Downloader Middlewares(下載中間件):可以當作是一個可以自定義擴展下載功能的組件。Spider Middlewares(Spider中間件):可以理解為是一個可以自定義擴展和操作引擎以及Spider中間通信的功能組件(例如進入Spider的Responses;和從Spider出去的Requests)。
整個Scrapy爬蟲框架執行流程可以理解為:爬蟲啟動的時候就會從start_urls提取每一個url,然后封裝成請求,交給engine,engine交給調度器入隊列,調度器入隊列去重處理后再交給下載器去下載,下載返回的響應文件交給parse方法來處理,parse方法可以直接調用xpath方法提取數據了。
3.2 Redis
Redis 是完全開源免費的,遵守BSD協議的,高性能的key-value數據庫。Redis 與其他key - value 緩存產品有以下三個特點:(1)Redis支持數據的持久化,可以將內存中的數據保存在磁盤中,重啟的時候可以再次加載進行使用。這樣可以防止數據的丟失,在實際生產應用中數據的完整性是必須保證的。(2)Redis不僅僅支持簡單的key-value類型的數據,同時還提供list,set,zset,hash等數據結構的存儲。這些功能更強大的數據存儲方式極大地節約了存儲空間,優化了查詢的性能,大大提高了查詢效率。存儲的目的是為了后期更好的取出,Redis很好地做到了這一點。(3)Redis支持數據的備份,即master-slave模式的數據備份。主從結構目前是大數據里面的主流結構,主從模式能保證數據的健壯性和高可用。當出現電腦宕機,硬盤損壞等重大自然原因時,主從模式能很好的保證存儲的數據不丟失,隨時恢復到可用狀態。正是考慮到Redis的以上強大特點,才選擇Redis作為分布式存儲的數據庫。
4 Django搭建搜索網站
Django是一個開放源代碼的Web應用框架,由Python開發的基于MVC構造的框架。在Django中,控制器接受用戶輸入的部分由框架自行處理,因此更加關注模型,模板和視圖,即MVT。模型(Model),即數據存取層,處理與數據相關的所有事物:包括如何存取,如何驗證有效性,數據之間的關系等。視圖(View),即表現層,處理與表現相關的邏輯,主要是顯示的問題。模板(Template),即業務邏輯層,主要職責是存取模型以及調取恰當模板的相關邏輯。控制器部分,由Django框架的URLconf來實現,而URLconf機制恰恰又是使用正則表達式匹配URL,然后調用合適的函數。因此只需要寫很少量的代碼,只需關注業務邏輯部分,大大提高了開發的效率。使用Django搭建搜索引擎的界面,簡單便捷且界面交互效果良好,適應需求,無須成本。
5 ElasticSearch搜索引擎
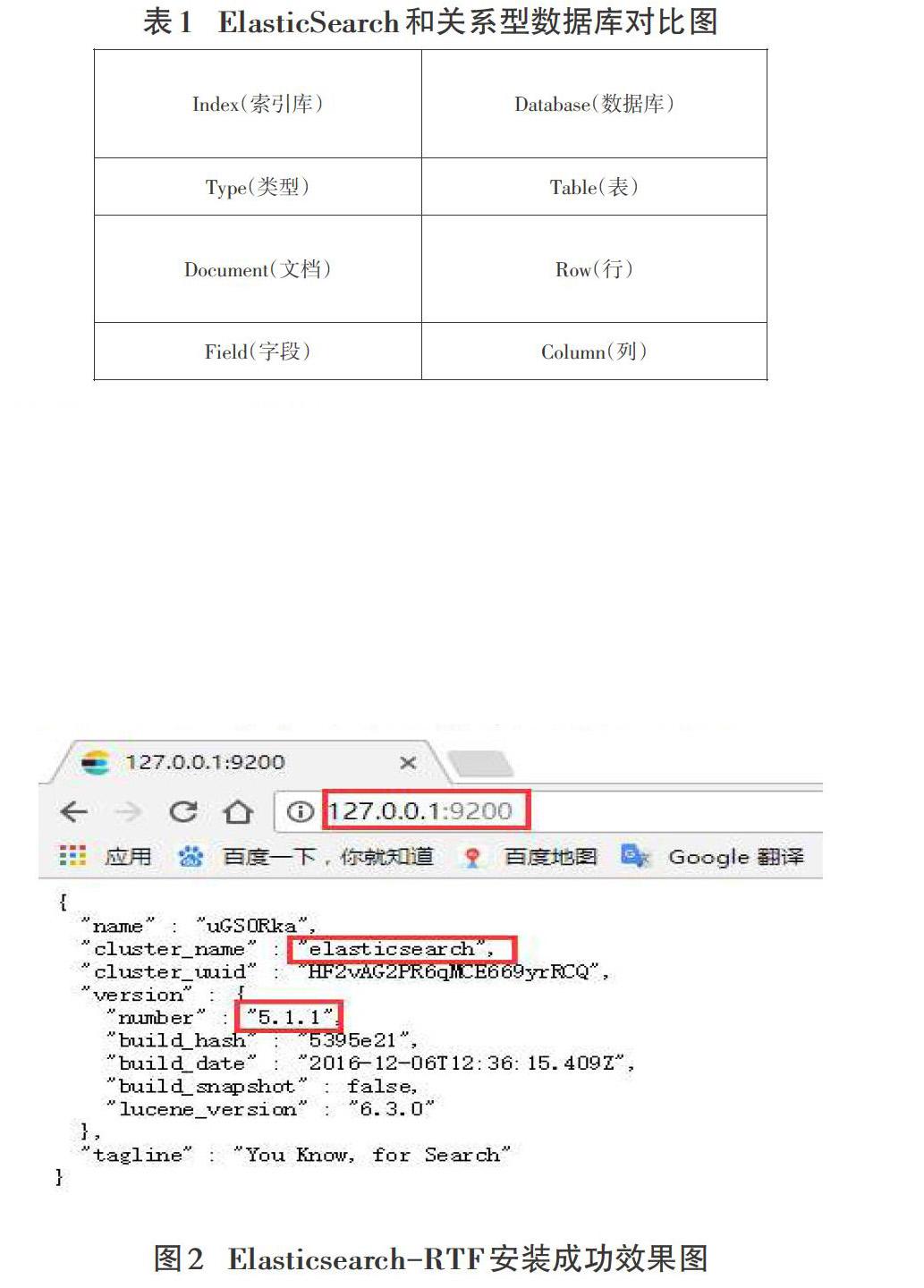
ElasticSearch是一個基于Lucene的實時的分布式搜索和分析引擎,設計用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用非常方便。基于RESTful接口。ElasticSearch具有廣泛的用戶,如DELL,GitHub,Wikipedia等。ElasticSearch和關系型數據庫之間的對比如表1所示:
5.1 Elasticsearch-RTF
RTF是Ready To Fly的縮寫,在航模里面,表示無需組裝零件即可直接上手即飛的航空模型。Elasticsearch-RTF是針對中文的一個發行版,即使用最新穩定的Elasticsearch版本,并且下載測試好對應的插件,如中文分詞插件等,目的是可以下載下來就可以直接的使用。項目構建過程中選擇的是Elasticsearch-RTF 5.1.1版本。安裝后啟動,效果如圖2所示:
5.2 Elasticsearch-head
ElasticSearch-head是一個Web前端插件,用于瀏覽ElasticSearch集群并與之進行交互,它可以作為ElasticSearch插件運行,一般首選這種方式,當然它也可以作為獨立的Web應用程序運行。它的通用工具有三大操作:ClusterOverview,顯示當前集群的拓撲,并允許執行索引和節點級別的操作;有幾個搜索接口可以查詢原生Json或表格格式的檢索結果;顯示集群狀態的幾個快速訪問選項卡;一個允許任意調用RESTful API的輸入部分。
5.3 Kibana
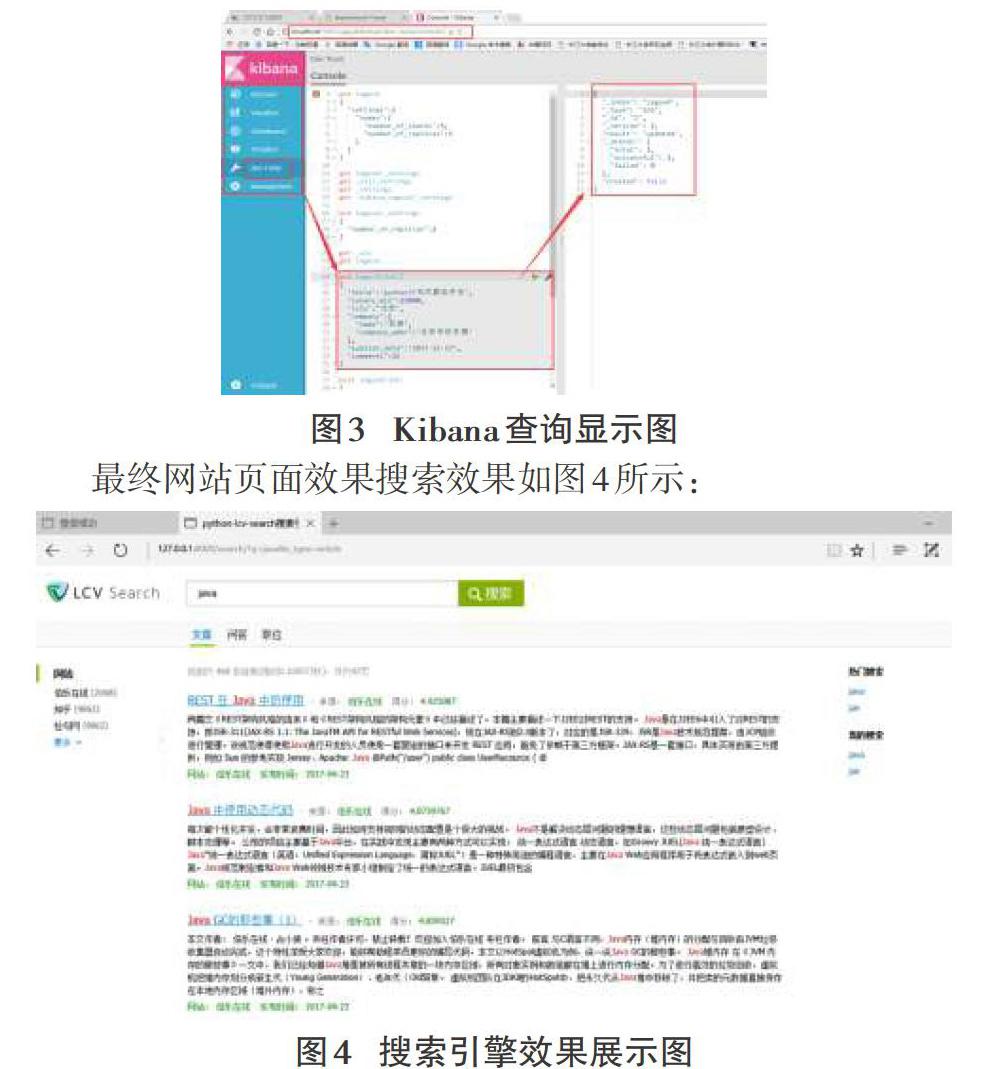
Kibana是一個開源的分析與可視化平臺,設計出來用于和Elasticsearch一起使用的。可以用kibana搜索、查看、交互存放在Elasticsearch索引里的數據,使用各種不同的圖表、表格、地圖等。kibana能夠很輕易地展示高級數據分析與可視化。Kibana使理解大量數據變得容易。它簡單、基于瀏覽器的接口能快速創建和分享實時展現Elasticsearch查詢變化的動態儀表盤。Kibana啟動完成后,可看到插入數據和頁面查詢顯示結果如圖3所示:
6 結論
通過對爬蟲理論的相關理解,將互聯網上海量的信息按需要加以分類和存儲,并最終展示給特定用戶的特定領域需求的信息,避免網上海量信息的視覺沖擊,從而達到準確,高效檢索的目的。利用Python語言以及其豐富的知識庫,結合開源的Scrapy爬蟲框架,能夠高效的將網上海量的信息爬取下來,并利用Redis分布式數據庫的特點,將數據安全,快速的存入,方便后期的獲取與檢索,使用開源的Django框架搭建搜索引擎網站,提供靈活便捷的可視化操作界面,方便廣大用戶的使用,結合ElasticSearch強大的搜索功能,將所有組件結合到一起,完成搜索引擎的全部功能,最終達到搜索的目的。
參考文獻:
[1] 郭一峰.分布式在線圖書爬蟲系統的設計與實現[D].北京交通大學,2016.
[2] 王敏.分布式網絡爬蟲的研究與實現[D].東南大學,2017.
[3] 胡慶寶,姜曉巍,石京燕,程耀東,梁翠萍.基于Elasticsearch的實時集群日志采集和分析系統實現[J].科研信息化技術與應用,2016,7.
[4] 曾亞飛.基于Elasticsearch的分布式智能搜索引擎的研究與實現[D].重慶大學,2016.
[5] 姚經緯,楊福軍.Redis分布式緩存技術在Hadoop平臺上的應用[J].計算機技術與發展,2017,27(6):146-150+155.
[6] 馬聯帥.基于Scrapy的分布式網絡新聞抓取系統設計與實現[D].西安電子科技大學,2015.
[7] 吳霖.分布式微信公眾平臺爬蟲系統的研究與應用[D].南華大學,2015.
[8] 李春生.基于WEB信息采集的分布式網絡爬蟲搜索引擎的研究[D].吉林大學,2009.
【通聯編輯:梁書】
猜你喜歡
商周刊(2017年22期)2017-11-09 05:08:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國衛生(2015年12期)2015-11-10 05:13:38
河南電力(2015年5期)2015-06-08 06:01:46
皖西學院學報(2015年5期)2015-02-28 17:52:46
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
