智能水表讀數誤差的定位和分析
2018-02-24 13:55:24許冠軍高昌盛
電腦知識與技術 2018年34期
許冠軍 高昌盛


摘要:智能水表技術解決了用水數據獲取實時性的問題,但新的獲取用水量數據技術,在統計準確性上不如傳統方法。為定位智能水表系統的可能錯誤數據,該文提出了基于歷史數據的誤差定位方法,可以有效發現疑似誤差數據。
關鍵詞:校驗;智能水表;歷史數據
中圖分類號:G642? ? ? ? 文獻標識碼:A? ? ? ? 文章編號:1009-3044(2018)34-0193-03
1 引言
水務公司為便于分析區域用水情況和布局合理的管網等需求,對居民用水數據的實時性和準確性要求越來越高。智能水表技術有效地解決了獲取用水數據實時性的問題,但無論是超聲波智能水表還是基于圖像識別的智能抄表系統,都存在較大比例的讀數誤差。誤差數據的存在,尤其是明顯的居民用水數據錯誤,會引起客戶的投訴,造成客戶和水務公司對系統數據的不信任,嚴重影響智能水表系統的進一步推廣。
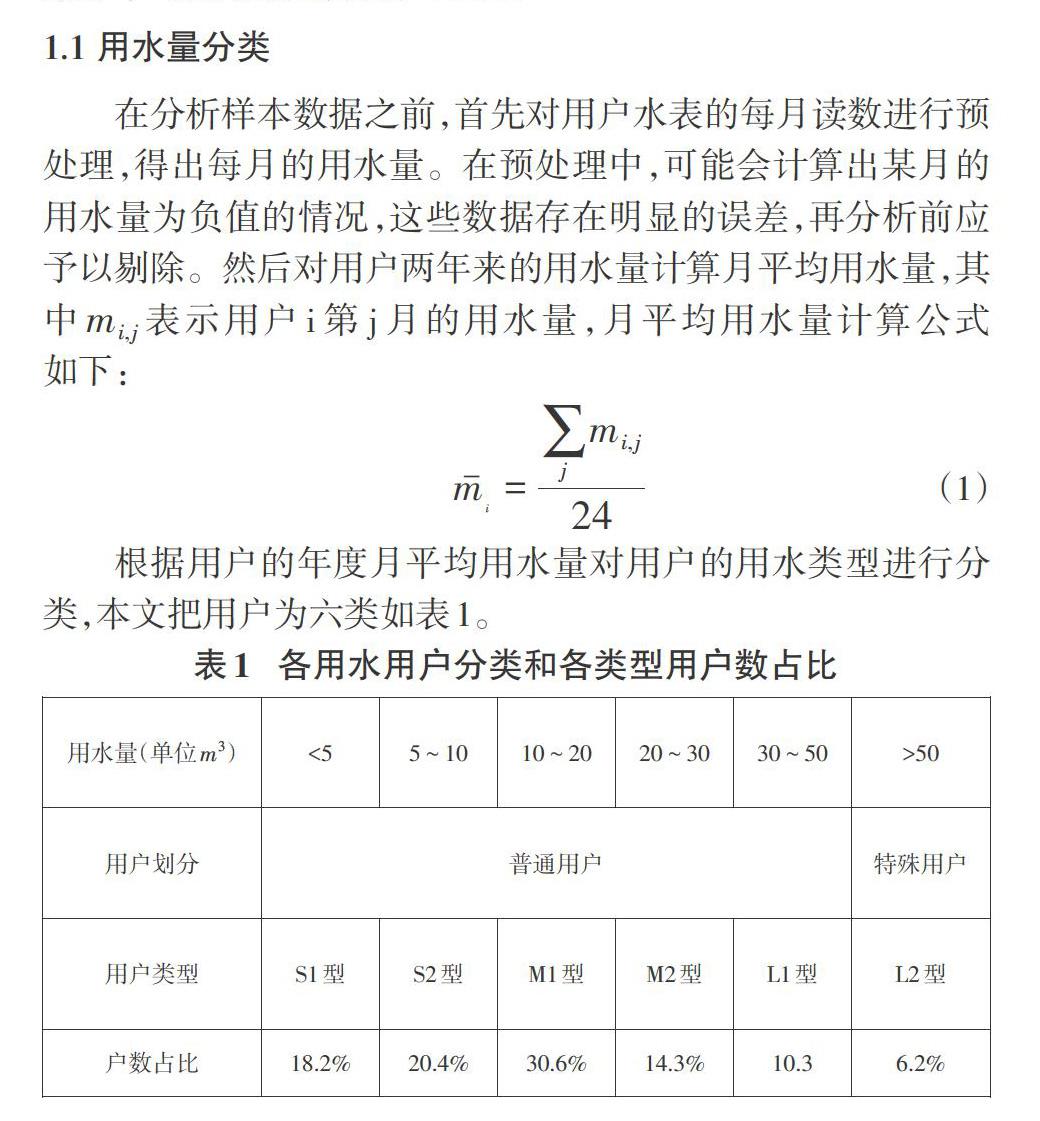
為提高用水量數據的準確性,應在初次統計的數據中,盡可能發現可能的誤差數據,結合系統重讀、人工篩查和智能預測等方法進行及時糾正。本文提出了基于歷史數據的居民用水量數據校驗和分析方法,具體實現步驟:(1)結合區域居民的歷史用水數據,對居民的用水特點進行分類,形成不同類型的居民用水類型[1-2];(2)結合一年四季的用水差別,利用已分類的用戶類型,擬合出各類型的年度月平均用水變化曲線[3];(3)結合區域用戶的年度月平均用水曲線,得出月際用水量的變化幅度[4-5]。結合用戶的歷史用水數據,對當月的系統讀數的進行合理性識別,并確定疑似誤差數據。
2 用水模式分析
本文對某市區的近萬戶居民連續兩年用水歷史數據進行分析,在用戶類型劃分和用水模式分析中,月平均用水量和用水時間波動性是最受關注的兩個因素。經過初步的數據分析發現,月平均用水量能較好地區分用戶的類別,因此,本文先利用月平均用水量劃分用戶類型。
3 數值實驗
本文的實驗數據來自基于圖像識別的自動抄表系統,一般情況下該系統的讀數自動識別正確率能達到95%,發現剩余5%的錯誤數據,是本文算法要解決的主要問題。
3.1 實驗分析
實驗中,對非樣本的生產數據進行直接驗證,本文算法與傳統的直接基于上月數據校驗算法進行比較。實驗結果對正常數據誤判率(把正常的數據標識成疑似誤差數據的比例)、錯誤數據識別率(正確識別誤差數據的比例)二組結果記錄如表4。
由表4的實驗結果可以發現,和傳統算法相比較,本文算法引入了用水量隨季節變化的用水模式因素,降低了正常數據的誤判率,且提高了錯誤數據的識別率。
3.2 算法分析
傳統的直接和上月用水量進行比較的計算方法相對簡單,可以粗略判斷數據的合法性,但由于沒有結合用水量隨季節變化的因素,在季節交替月份的檢驗效果較差。本文提出的算法,彌補了傳統算法的缺點,但相對計算量較大,具體特點如下:
1)算法依賴于往期數據的完整性。若對于不完備的用水數據或數據質量不高的情形,可以先應用傳統方法進行數據積累,當數據量積累到1年以上時,便可應用算法。
2)區分用戶類型的目標是對有相同用水模式的用戶進行分類,本文的用戶分類僅根據年度月平均用水量,相對比較粗糙,有待進一步改進。但無論何種分類方法,用水模式會隨地域和時間變化而變化,此類算法需要定期更新區域用戶用水模式數據。
3)模型只假設當月用水數據只和上月數據相關,若能考慮更多月份的用水數據和往年同期用水數據,可能會使模型更加完善。
4 小結
本文設計的用水量校驗算法是抄表系統的一個重要的輔助模塊,在系統實現中,增加了當月待核實數據的預測區間,用于抄表員及時發現疑似錯誤數據。由表4可知,該算法正常數據誤判率在7%和11%之間,錯誤數據的識別率介于86%和90%之間,取得了相對滿意的校驗效果。進一步優化用戶分類方法,形成更為精確的用水模式,將是以后的研究方向。
參考文獻:
[1] 王保義,胡恒,張少敏. 差分隱私保護下面向海量用戶的用電數據聚類分析[J]. 電力系統自動化, 2018,42(2):121-127.
[2] 劉春霞,王琰,沈磊,等. 城市典型用戶四季用水模式變化規律的確定及分析[J]. 供水技術, 2015,9(4):49-52.
[3] 趙太飛,谷偉豪,段延峰. 農村居民用水行為的識別方法[J].水資源與水工程學報, 2016,27(4):70-74.
[4] 屈曉淵,張永恒,張鋒,等. 礦區水環境數據預測模型研究[J]. 電子設計工程, 2016,24(10):45-48.
[5] 陳佳袁,閆杰. 基于ARMA模型的水文數據預測[J]. 浙江水利科技,2017(6):27-30.
【通聯編輯:王力】
