Web服務中信譽度評價模型研究
2018-02-28 10:55:05孫其博李靜林
無線電通信技術 2018年2期
袁 翔,孫其博,周 傲,李靜林
(北京郵電大學 網絡與交換技術國家重點實驗室,北京 100876)
0 引言
隨著互聯網技術的發展以及Web服務標準和技術的成熟,構建Web服務變得越來越容易,出現了越來越多提供相同或者相似功能的服務。所以在選擇使用一個服務之前,需要對其綜合服務能力進行評價。在實現相同或者相似功能的服務中,選擇評價高的服務。一個服務的優劣可以通過信譽度來評價,Gambetta、Abdul-Rahman以及Halie給予信譽的定義為:信譽是個體對服務方一定程度的期望,表現為服務的一種主觀能動性,而對信譽的定義是考察服務方的歷史行為并分析使用者對其評價的信息[1-5]。利用相關的計算模型最終得出服務者將來要使用服務的期望。當前的信譽計算可以利用服務消費者評價信息、服務提供者的公告信息,以及使用相同服務的消費者的推薦信息等。而具體模型又可以在不同程度上綜合利用以上信息,不同模型在不同的場景下有著不同的優勢和特點。具體選用哪一種模型不僅需要考慮到算法評價的準確客觀性,也需要考慮實際的使用場景。目前,學者們對于Web信譽評估提出了多種評估模型,其建模原理反應了人們對信譽的認知,主要包括基于反饋信息的評估模型[6-8]、基于QoS的信譽評估模型[9]、基于社會網絡中心性測度的模型[10]等。模型的發展有效地推動Web信譽評估的發展,極大地豐富了人們對信譽關系的理解。本文對當前Web服務信譽評估模型進行了分析和研究,為各個模型進行了對比,并且展望了新的研究契機。
1 Web服務基于主觀源的信譽度評估模型
1.1 基于交易反饋的網絡服務
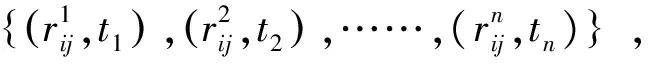
局部信譽是利用本地信息計算得出的信譽,只能代表單個用戶對此服務的觀點。這種信譽不夠公正客觀,為了解決這個問題,模型引入了服務的全局信譽計算。全局信譽計算也叫做信譽的合成,主要目的是把各個用戶單獨的信譽合理地結合起來,從而在全網中給予服務一個客觀公正的評價。在該模型中認為計算全局信譽的重點在于找出每個服務使用者對于其使用者評價的可靠性C(i,j)。模型通過利用評價中心值以及偏差的概念來進行可靠性的C(i,j)的計算。最終結合各個用戶的可靠性以及局部信譽,最終得出服務的Sj的全局信譽為:
(1)
該模型通過分析用戶的歷史行為數據,通過簡單的算法計算局部信譽,這種局部信譽計算方法避免了復雜的運算并減少了數據通信量。而整個系統對于服務Sj的全局信譽,文中通過自定義的匯集函數來綜合各局部信譽的值,從而得出最終對服務Sj的評價。綜合來看,該模型信任來源僅僅為服務消費者的歷史行為數據。
1.2 基于small-world networks模型的網絡服務
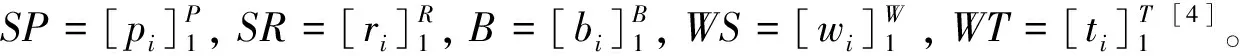
在small-world network中,服務提供者被不同的社會因素分為幾個類,與此同時服務消費者也根據不同的社會因素而分類。因此基于社會觀點來看,當選擇一個服務時,有兩個方面的因素需要考慮,第一個就是服務消費者所在的small-world network里的SR的信譽,另一個就是來自與服務提供者的信譽。在此模型假設在同一個small-world里的每一個實體都存在信任關系,并且每個成員的評價都是主觀可信的,于是定義一個評價C(r,w)={b,d,u}。其中b、d、u代表訪問的平均滿意程度。當一個服務請求者r∈SR請求一個t∈WT種類的服務時,模型首先會在SB中尋找信譽最高的用戶b∈SB,然后通過b來進行檢索并且返回一個滿足w.t=t的服務w∈WS。因此,基于p=wp關于服務w的全局信譽評價可用如下公式計算:
C(r,b,p,w)=C(r,p,w)⊕C(r,b,w)⊕C(b,p,w),
(2)
式中,⊕代表信任合成運算,在得到全局信譽之后,模型會將此信譽值與臨界值θ來比較。如果C(r,b,p,w)>θ則說明服務w滿足用戶r的要求,用戶將會選擇此服務,否則用戶將會重新計算其他服務的信譽值并且做出選擇。
2 Web服務基于客觀源的信譽度評估模型
2.1 基于質量平均算法的網絡服務
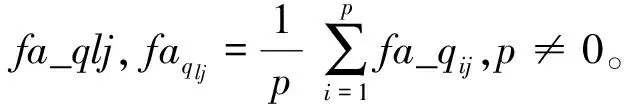
(3)
當屬性為正相關時:
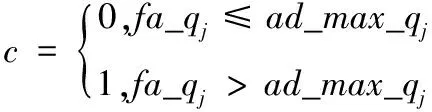
(4)
當屬性為負相關時:
(5)
模型從相似度之中可以得出信譽的好壞,通過相似度和信譽的映射,可以得出信譽值。用戶在選擇服務的時候就要選擇相似度高的服務。該模型計算較為簡單可行,通過計算服務質量的相似度得到信譽,結果較為主觀。
2.2 基于質量相似度的網絡服務
付曉東等人在現有面向服務的架構(Service-Oriented Architecture,SOA)的指導框架上加入了一個信譽評價中心的角色[13],通過信譽評價中心來計算服務的信譽度[6],而實際采用的算法則是通過比較QoS指標的底層實際值和服務提供者的公告值的相似度。本文為了使信譽度量模型中各個角色對信譽的度量有著一致性理解,提出了上下兩層的QoS模型,其中上層模型用于描述與質量有關的各個QoS的概念,下層模型用來描述具體QoS的指標體系。對于模型中一個實際的QoS節點,由于其評價指標不同,因此分為效益型節點和成本型節點,效益型節點的指數越大越好,而成本型節點的指數當然越小越好。如一個QoS有若干指標Item,例如性能(Item)包括錯誤率、響應時間、吞吐量等指標,實際值為Value,公告值為Adv。
則效益型節點的相似度計算如下:
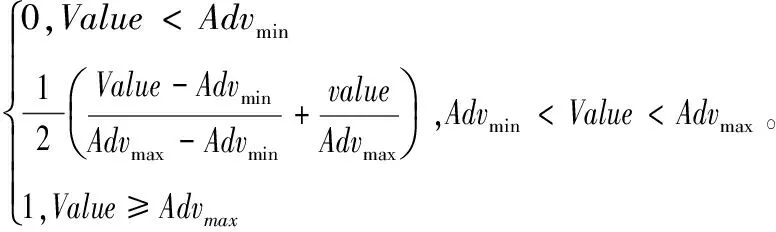
(6)
成本型節點的相似度計算如下:
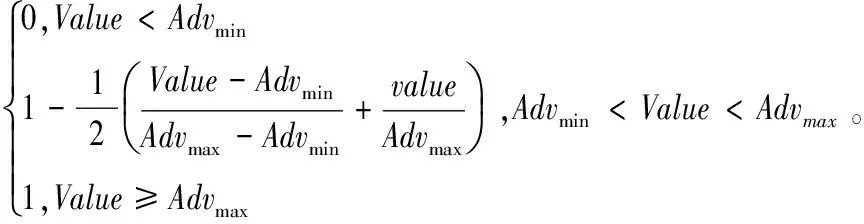
(7)
(8)
模型還考慮了信譽度的波動情況,按照大眾的觀點,在服務信譽相同的情況下,評價較為穩定的服務較為可信。于是模型引入了波動因子γ,通過計算服務相似度的標準差s來修正模型,并且由波動因子來確定標準差的調節力度。由此得到最終信譽計算模型為:
(9)
該方法提出了一個計算質量相似度的信譽計算模型。可以計算任意服務質量指標的信譽度,并且考慮了信譽波動的情況,因此該算法有著較好的魯棒性。
3 Web服務主客觀融合的信譽度評估模型
3.1 分布式網絡服務
劉彬等人提出了一種分布式信譽計算評估模型[14]。在傳統信譽評估中,一般在服務注冊機構上加一個信譽管理機構,這樣就可以集中式地對信譽進行管理。這種全局方法優點是簡單、易于計算。但由于信任集中管理,如果信譽中心被攻擊,就容易出現較大的問題[7]。基于此劉彬等人引入了一種分布式的信任評估管理模型,該模型信任來源為服務使用者的歷史交互信息、服務提供商的注冊信息。通過計算服務的初始信譽值、來自服務直接使用者的直接信譽和其他使用相同服務使用者的間接信譽,然后合成為最終信譽值。假設帶評估的網絡服務有m個,每個網絡服務有n個QoS屬性。則QoS屬性可以表示為{qi1,qi2,qi3,….qin},i∈{1,2,3,4…n}。由于QoS屬性有正屬性和負屬性,所以需要進行相應的變換。正屬性用式(10)變換,負屬性用式(11)進行變換。
(10)
(11)
由于各個用戶對于服務的不同QoS屬性的偏好程度不同,該模型引入了服務偏好程度wj。由此服務的初始信譽值可得:
(12)
而對于來自經驗的信譽模型分為兩種情況進行了討論,分別是來自服務直接使用者的直接經驗得到的直接信譽Td(i),以及其他推薦者的間接經驗得到的間接信譽Tr(i)。雖然直接信譽和間接信譽的獲取方法不同,但其均來自于使用者每次使用完服務后對服務QoS的評價。在得到直接信譽、間接信譽以及初始信譽的條件下,最終信譽合成為:
T(i)=σε-n/NTp(i)+(1-e-n/N)Te(i)。
(13)
該模型提出了分布式的信譽計算方法,不同于傳統信譽中心管理信譽的方法,分布式方法對規模比較大的服務集群時有著較大的優勢。并且由于不依賴于信譽中心,所以不存在信譽中心欺詐以及信譽中心被攻擊而使全局服務評價崩潰的情況。
3.2 基于貝葉斯網絡的網絡服務
Hien Trang Nguyen等人提出了一種基于貝葉斯網絡的信譽評估模型[15]。該模型通過把用于數據分析領域的貝葉斯網絡用于服務信譽的計算,模型對每一個服務按照服務質量指標分解成貝葉斯網絡。通過分析用戶主觀評價得到先驗條件,再根據先驗條件和貝葉斯公式計算出信譽。該模型中信譽來自于三部分,分別是直接信譽、推薦信譽和一致性信譽。在直接信譽計算中,模型通過把服務按照服務質量指標進行分解,并在此引入了貝葉斯網絡。
在貝葉斯網絡信任模型中,根節點S是對網絡服務滿意度評價。S的值可以為1(滿意)或者為0(不滿意)。每個分解節點Lqj,其代表質量指標j的水平,并且Lqj∈{1,2,3,4,5}[8]。每個服務分解成的貝葉斯網絡。當計算一個用戶x對服務i的信譽度時,可以使用貝葉斯方法得到直接信譽計算公式:
Tdx(i,Lqj≥a)=Px,i(S=1|Rqj>a)×Px,i(Rqj≥a)=
Px,i(Rqj≥a|S=1)×Px,i(S=1)。
(14)
對網絡服務的每一個質量指標,用戶都會為其指定一個興趣度Wqj,表示用戶對該質量指標的感興趣程度。Wqj∈{0,1,2}分別代表不感興趣、感興趣、非常感興趣。要想計算可信度,必須先知道條件S的取值。在此模型引入用戶x對服務的評分R(x,i,u):
(15)
式中,TF(x,i,u)∈[0-1]為交易時上下文因素。通過最終計算出的R(x,i,u)值和預先的臨界值相比較,就可以給出S值并計算主觀的直接信譽。對于客觀評價,模型通過計算推薦信譽來獲得,推薦信譽的計算方法為:
(16)
式中,Tdy是所有和x使用過相同服務的其他用戶的信譽度(不包括x用戶自身)。Crx(y)是x對y的信任程度。因為其他用戶可能進行惡意推薦,所以模型對每個推薦用戶都給與一個信任度的評價因子,通過此參數來削弱惡意推薦的影響力,并且強化優質推薦用戶的作用。以上直接信譽和推薦信譽都是基于用戶評價。為了使得模型更加客觀公正,在此引入了QoS一致性判斷,其通過比較實際QoS值和公告的QoS值的一致性來計算出一致性信譽Tcx,由此該模型計算出3種信譽值。通過對3種信譽可以合成最終用戶x對服務i的信譽值:Tx(i)=Trx(i)×wd+Trx(i)×wr+Tcx(i)×wc。其中,wd、wr、wc分別為3種信譽的權重值,且wd+wr+wc=1。
該模型通過3種來源的信息計算信譽值,較為全面地考慮了信譽度的各類情況,可以聯合考慮在多重指標的信譽度。信譽計算結果也比較客觀公正,但是通過貝葉斯網絡的方法計算有著較大的復雜性。表1為各模型對比。
表1 各模型對比
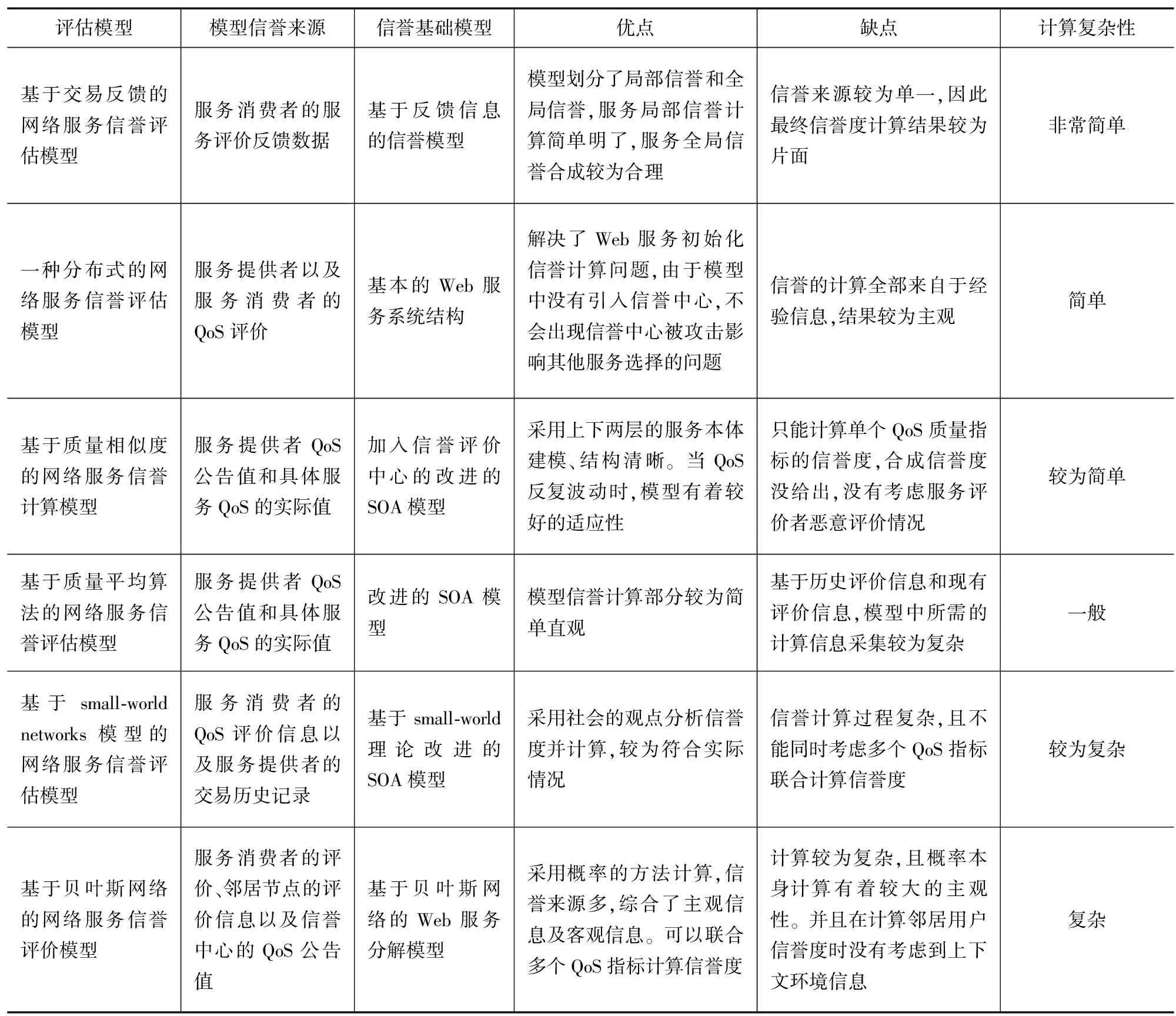
評估模型模型信譽來源信譽基礎模型優點缺點計算復雜性基于交易反饋的網絡服務信譽評估模型服務消費者的服務評價反饋數據基于反饋信息的信譽模型模型劃分了局部信譽和全局信譽,服務局部信譽計算簡單明了,服務全局信譽合成較為合理信譽來源較為單一,因此最終信譽度計算結果較為片面非常簡單一種分布式的網絡服務信譽評估模型服務提供者以及服務消費者的QoS評價基本的Web服務系統結構解決了Web服務初始化信譽計算問題,由于模型中沒有引入信譽中心,不會出現信譽中心被攻擊影響其他服務選擇的問題信譽的計算全部來自于經驗信息,結果較為主觀簡單基于質量相似度的網絡服務信譽計算模型服務提供者QoS公告值和具體服務QoS的實際值加入信譽評價中心的改進的SOA模型采用上下兩層的服務本體建模、結構清晰。當QoS反復波動時,模型有著較好的適應性只能計算單個QoS質量指標的信譽度,合成信譽度沒給出,沒有考慮服務評價者惡意評價情況較為簡單基于質量平均算法的網絡服務信譽評估模型服務提供者QoS公告值和具體服務QoS的實際值改進的SOA模型模型信譽計算部分較為簡單直觀基于歷史評價信息和現有評價信息,模型中所需的計算信息采集較為復雜一般基于small?worldnetworks模型的網絡服務信譽評估模型服務消費者的QoS評價信息以及服務提供者的交易歷史記錄基于small?world理論改進的SOA模型采用社會的觀點分析信譽度并計算,較為符合實際情況信譽計算過程復雜,且不能同時考慮多個QoS指標聯合計算信譽度較為復雜基于貝葉斯網絡的網絡服務信譽評價模型服務消費者的評價、鄰居節點的評價信息以及信譽中心的QoS公告值基于貝葉斯網絡的Web服務分解模型采用概率的方法計算,信譽來源多,綜合了主觀信息及客觀信息。可以聯合多個QoS指標計算信譽度計算較為復雜,且概率本身計算有著較大的主觀性。并且在計算鄰居用戶信譽度時沒有考慮到上下文環境信息復雜
4 結束語
通過對Web信譽模型的研究,明確了信譽來源對于一個Web服務信譽評估模型的重要性,設計優良的信譽模型采用的信譽證據應該既要包含主觀信息,也要包括客觀因素。與此同時,對信譽的描述需要反映信譽動態性以及模糊性的特點,典型的就是以社會學觀點以及貝葉斯的概率論觀點來建模。通過對信譽模型各個建模因素的分析,為后續對Web信譽模型的研究提供了參考。
[1] 陳衛東,李敏強,趙慶展.基于P2P環境下的Web服務選擇信任模型研究[J].計算機科學,2015,42(1):113-118.
[2] Maximilien E M.Conceptual Model of Web Service Reputation[J].Acm Sigmod Record,2002,31(4):36-41.
[3] Wang S G,Sun Q B,Yang F C.Reputation Evaluation Approach in Web Service Selection[J].Journal of Software,2012,23(6):1350-1367.
[4] 孫素云.Web服務信譽度評估模型的研究[J].計算機工程與設計,2008,29(9):2259-2261.
[5] Wang S,Zheng Z,Wu Z,et al.Reputation Measurement and Malicious Feedback Rating Prevention in Web Service Recommendation Systems[J].IEEE Transactions on Services Computing,2015,8(5):755-767.
[6] Wang S,Sun Q,Zou H,et al.Reputation Measure Approach of Web Service for Service Selection[J].Iet Software,2011,5(5):466-473.
[7] Alsharawneh J,Williams M A,Goldbaum D.Web Service Reputation Prediction Based on Customer Feedback Forecasting Model[C]∥ Enterprise Distributed Object Computing Conference Workshops.IEEE,2010:33-40.
[8] 尚廣,孫其博,楊放春.Web服務選擇中信譽度評估方法[J].軟件學報,2012,23(6):1350-1367.
[9] 呂福軍.一種基于QoS與用戶推薦的Web服務信譽度評價模型[D].秦皇島:燕山大學,2010.
[10] Bansal S K,Bansal A.Reputation-Based Web Service Selection for Composition[C]∥ Services.IEEE,2011:95-96.
[11] Liu F,Wang L,Gao L,et al.A Web ServiceTrust Evaluation Model Based on Small-world Networks[J].Knowledge-Based Systems,2014,57(2):161-167.
[12] Zhang H,Shao Z,Zheng H,et al.Web Service Reputation Evaluation Based on QoS Measurement[J].The Scientific
World Journal,2014(1):145-156.
[13] 付曉東,鄒平,姜瑛.基于質量相似度的Web服務信譽度量[J].計算機集成制造系統,2008,14(3):619-624.
[14] 劉彬,張仁津.用于Web服務的分布式信任和聲譽模型[C]∥ 2011全國開放式分布與并行計算學術年會,2011.
[15] Nguyen H T,Zhao W,Yang J.A Trust and Reputation Model Based on Bayesian Network for Web Services[C]∥ IEEE International Conference on Web Services.IEEE,2010:251-258.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
