基于計算聽覺場景分析的說話人轉(zhuǎn)換檢測
2018-03-02 09:23:30楊登舟夏善紅
計算機工程 2018年2期
楊登舟,劉 加,夏善紅
(1.中國科學(xué)院電子學(xué)研究所,北京 100190; 2.中國科學(xué)院大學(xué),北京 100049;3.清華大學(xué) 電子工程系,北京 100084)
0 概述
隨著電子通信和計算機技術(shù)的快速發(fā)展,大量的語音數(shù)據(jù)被存儲,如何快速地建立語音檢索是亟需解決的問題。說話人轉(zhuǎn)換檢測(Speaker Change Detection,SCD),也稱說話人分割[1],是語音信號處理中的一項實用技術(shù),從一段語音中將不同說話人說話的時刻檢測出來,將語音分割出滿足要求的片段,可以很方便地建立索引,為信息的進一步處理提供便利[2-3]。
語音切分類問題可以抽象成模型判別問題,用特定長度的窗(定長窗或者變長窗)掃描整段語音,當窗內(nèi)左右兩部分的語音之間的差異達到某個閾值,認為在窗左半部分和右半部分發(fā)生了明顯的改變,有理由懷疑此處語音的聲源發(fā)生了變化[4]。在說話人轉(zhuǎn)換檢測的研究中,窗左右兩側(cè)語音之間的差異度量方式主要有模型差異、參數(shù)差異以及模型和參數(shù)相結(jié)合[5-6]這三大類。在基于模型的方法中,從訓(xùn)練數(shù)據(jù)中挑選出不同的發(fā)聲源,訓(xùn)練出各自的模型,同時訓(xùn)練出所有聲源的全局模型,通過分析全局模型和個體模型的不同之處,得到模型間轉(zhuǎn)化關(guān)系或者找到可區(qū)分的模型差異,常用的模型包括通用背景模型(Universal Background Model,UBM)、樣本說話人模型(Sample Speaker Model,SSM)、隱馬爾科夫模型(Hidden Markov Model,HMM)。基于參數(shù)的方法,使用較多的特征主要包括時域短時能量、過零率、頻域的子帶能量、倒譜特征、線性預(yù)測系數(shù)等。通常使用差異度量準則有貝葉斯信息準則(Bayesian Information Criterion,BIC)、廣義似然比(Generalized Likelihood Ratio,GLR)、KL散度(Kullback-Leibler divergence)、歸一化交叉似然比(Normalized Cross Likelihood Ratio,NCLR)等。
在說話人識別問題中,由于事先可以獲取訓(xùn)練數(shù)據(jù),可以事先訓(xùn)練出多個不同的說話人模型,在判決階段只要將一段語音的特征和所有參考模型做比較,和哪一個更近就判別成哪個,在閉集測試中,性能較好[7]。而說話人轉(zhuǎn)換檢測比說話人識別難度大,主要難點在于對一段語音做切分任務(wù),并不會提供該語音中所包含的說話人的訓(xùn)練語料,因此不能準確獲取到說話人的模型,特別是在短時說話人迅速轉(zhuǎn)變的對話口語語音中完成穩(wěn)定說話人建模難度更大,需要挖掘短時說話人差異區(qū)分性大、能全面描述說話人發(fā)聲特性的特征。計算聽覺場景分析(Computational Auditory Scene Analysis,CASA)[8]根據(jù)聽覺生理學(xué)和聽覺心理學(xué)的研究成果,利用計算機模擬人耳耳蝸的聽覺處理機制來處理接收到的語音信息,該理論能夠較好地解決諸如同信道語音分離問題,充分利用語音的周期性和短時連續(xù)性2個重要的線索來區(qū)分不同的聲源。
本文提出一種基于聽覺場景分析的說話人轉(zhuǎn)換檢測方法,將語音分割成相鄰的若干語音子段,提取伽馬音能量倒譜系數(shù)特征,在貝葉斯信息準則的判決下得到初始說話人轉(zhuǎn)換點,最后利用濁音的基頻特征對漏檢和錯檢的轉(zhuǎn)換點進行后處理,以達到較好的檢測結(jié)果。
1 計算聽覺場景分析
人每天在各種復(fù)雜的聲學(xué)環(huán)境中傾聽語音,提取需要的信息,可以從周圍嘈雜的多人說話環(huán)境中鎖定自己感興趣的聲源對象,只要信噪比合適,人耳可以將目標聲源的聲音從背景語音中完全分離出來,并且做得非常出色,取決于人類具有聽覺場景分析(Auditory Scene Analysis,ASA)[9]的能力。
人耳的耳蝸基底膜就好像是一個初級的頻率分析器,可以將聲音中的各種頻率在基底膜上的位置進行編碼。當基底膜上下振動,其柯蒂氏器(Corti)也隨之產(chǎn)生相同的振動模式,并促使毛細胞纖毛發(fā)生彎曲形變,毛細胞去極化并在其頂部產(chǎn)生耳蝸電位,該電位會引起毛細胞底部神經(jīng)纖維的應(yīng)激反應(yīng),釋放出化學(xué)物質(zhì),引導(dǎo)神經(jīng)末梢興奮,傳輸至中樞神經(jīng)。人耳除了具有頻率分析特性,對聲波強度的編碼也非常高效,通過神經(jīng)單元興奮后發(fā)放神經(jīng)沖動的數(shù)量來確定強度。
1.1 Gammatone濾波器組模型模擬耳蝸的頻率分析
聽覺場景分析中將原始語音信號拆分成多個子帶信號的過程是通過Gammatone濾波器組[10]來實現(xiàn)的。Gammatone濾波器組是由一系列不同帶寬不同中心頻率的帶通濾波器組成,Gammatone濾波器的沖激響應(yīng)為:
gc(t)=
(1)
其中,τ是濾波器的階數(shù),φ是初始相位,B(fc)是濾波器組的帶寬,fc是中心頻率。當τ=4時和人耳聽覺濾波器非常吻合。濾波器的帶寬由中心頻率對應(yīng)的等價直角帶寬(Equivalent Rectangular Bandwidth,ERB)確定:
ERB(f)=24.7×(4.37f/1 000+1)
(2)
B(f)=1.019×ERB(f)
(3)
線性頻率f和“ERB-rate”尺度頻率FERB的換算關(guān)系為:
FERB(f)=21.4×lg(0.004 37f+1)
(4)
將線性頻率80 Hz~5 000 Hz轉(zhuǎn)化為“ERB-rate”尺度頻率,并在“ERB-rate”尺度下均勻取出128個,生成子帶數(shù)C=128的Gammatone濾波器組。將原始語音信號s(t)通過濾波器組濾波,輸出C個子帶信號uc(t):
uc(t)=s(t)×gc(t),c=1,2,…,C
(5)
1.2 毛細胞觸發(fā)模型模擬耳蝸的強度分析
原始語音信號s(t)經(jīng)過Gammatone濾波器濾波后得到uc(t),c=1,2,…,C(為表述方便,下文將省略子帶下標c,并不影響理解)。將u(t)經(jīng)過Meddis毛細胞模型[11],可以得到描述聽覺神經(jīng)觸發(fā)概率的信號v(t)。毛細胞觸發(fā)概率的計算過程通過以下4個方程完成:
(6)
(7)
(8)
(9)
在式(6)~式(9)中,g、r、l、h、A、B、x、y是模型常數(shù),q(t)、c(t)、w(t)是中間變量,在毛細胞傳導(dǎo)模型中有具體意義,聽覺末梢發(fā)放概率v(t)=h·c(t)。
2 區(qū)分性特征提取
2.1 伽馬通能量倒譜系數(shù)
在語音識別、說話人識別和語種識別中都可以見到梅爾頻率倒譜系數(shù)(Mel-frequency Cepstral Coefficients,MFCC)[12]發(fā)揮的重要作用。梅爾頻率倒譜系數(shù)是將語音幀的快速傅里葉變換(Fast Fourier Transformation,FFT)頻譜通過相互交疊且中心頻率沿梅爾頻率線性分布的24個三角濾波器組,對三角頻窗內(nèi)的能量計算對數(shù),對數(shù)譜計算離散余弦變換(Discrete Cosine Transform,DCT)得到梅爾頻率倒譜系數(shù)。伽馬通頻率倒譜系數(shù)[13]借鑒了梅爾頻率倒譜系數(shù)特征提取的原理。MFCC中對能量求對數(shù)得到倒譜,在GFCC中變成了計算響度壓縮,本文建立了一個介于GFCC和MFCC之間的特征,伽馬通能量倒譜系數(shù)(Gammatone Energy Cepstral Coefficients,GECC),它和GFCC的提取不同之處如圖1所示,GECC僅在于利用響度和能量的差異。
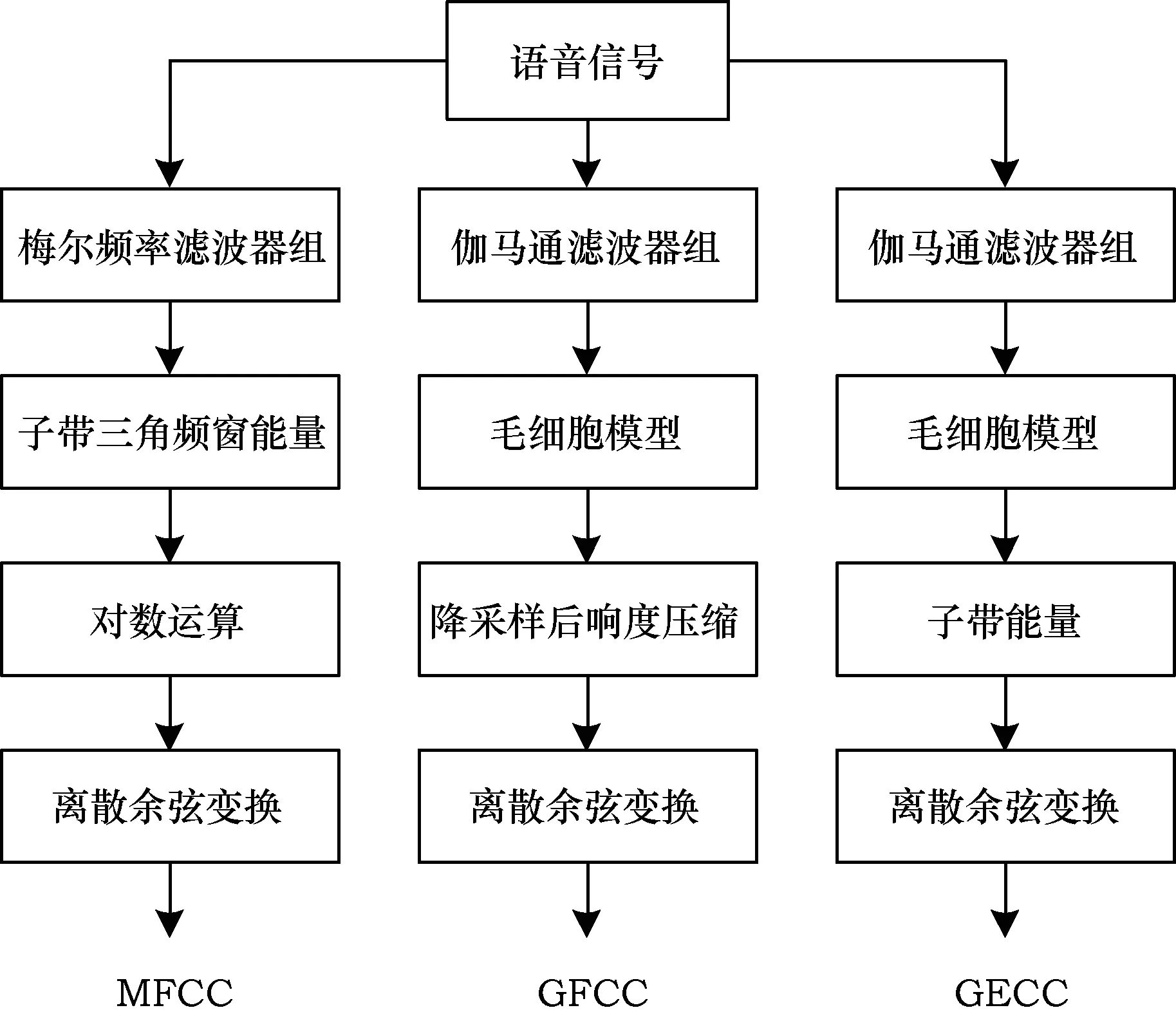
圖1 特征提取流程
對毛細胞觸發(fā)模型的輸出v(t)進行100 Hz降采樣,得到分幀信號w(m),m=1,2,…,M,M是幀數(shù)。各幀能量記為Gc(m),對Gc(m),c=1,2,…,C計算M階的離散余弦變換來降低M個子帶間的數(shù)據(jù)相關(guān)性,取前D維的數(shù)據(jù),得到GECC特征:
m=1,2,…,2M,k=0,1,…,D-1
(10)
2.2 音高
從人的發(fā)音結(jié)構(gòu)和語音的形成過程,可以把語音信號等效成激勵-濾波器模型,聲門產(chǎn)生激勵,聲門激勵滿足準周期性就可以產(chǎn)生有固定諧波結(jié)構(gòu)的語音信號,這類語音稱之為濁音[14];將不具有周期性且與噪聲類似的聲門激勵生成的語音信號稱為清音。聲帶、嘴唇、口腔的作用可以等效成聲道濾波器響應(yīng)。聲道濾波器反映的主要是語義信息(音素,詞匯),說話人的特性主要取決于聲門激勵。濁音的基頻在聽覺的感受就表現(xiàn)在音高上,每個人的音高略有不同,分布在50 Hz~500 Hz的范圍內(nèi),男性的音高比女性要低,成人的音高比小孩的要低。音高的差異可以作為說話人區(qū)分的一個重要特征。
對應(yīng)某個特定子帶c、時間幀m內(nèi)的毛細胞觸發(fā)輸出v(t)的自相關(guān):
vc(mN/2-k-τ)×h2(k+N/2)
(11)

(12)
通常人類的基音范圍在80 Hz ~500 Hz,對應(yīng)的延時區(qū)間是τ∈[2 ms,12.5 ms],通過搜索最大值得到音高Pm:
(13)
對檢測的音高序列做平滑處理,得到連續(xù)的基音軌跡。
3 說話人轉(zhuǎn)換檢測系統(tǒng)
本文基于聽覺場景分析的說話人轉(zhuǎn)換檢測由聽覺外圍處理、特征提取、轉(zhuǎn)換點判決3個部分組成,如圖2所示。聽覺外圍處理將語音信號經(jīng)由伽馬通濾波器組濾波,再用Meddis毛細胞觸發(fā)模型得到聽覺神經(jīng)末梢的發(fā)放概率。對發(fā)放概率按幀能量檢測對應(yīng)幀是濁音、清音還是靜音,各幀的屬性標記以后,得到濁音的連續(xù)片段,稱為子段,記為S。對所有相鄰的子段對(Si,Si+1)進行貝葉斯信息準則判決,得到分割初步判決結(jié)果。經(jīng)過貝葉斯信息準則判決后,已經(jīng)得到一定數(shù)量的說話人轉(zhuǎn)換點,區(qū)間驗證的作用是試圖利用音高信息,對可疑的轉(zhuǎn)化點進行剔除,并嘗試找回已經(jīng)被遺漏的轉(zhuǎn)化點。

圖2 基于聽覺場景分析說話人轉(zhuǎn)換檢測系統(tǒng)
3.1 清濁音檢測
對毛細胞觸發(fā)模型的輸出v(t)進行短時分幀,并計算在各子帶內(nèi)每幀的能量圖E(c,m)。沿時間軸方向?qū)ψ訋芰窟M行能量規(guī)整:
(14)
c=1,2,…,C,m=1,2,…,M
(15)
其中,th0為低能量判決門限,th1為高能量判決門限。
首先檢測濁音,在頻率小于950 Hz的低頻區(qū)(中心頻率離950 Hz最近的子帶記為Cs),濁音一定會有能量中心,而清音或者背景噪聲在此區(qū)域內(nèi)的能量與濁音的諧波能量相比,幾乎可以忽略不計[15]。按以下約束對各幀進行標記:
c=1,2,…,Cs,m=1,2,…,M-1
(16)
其中,V表示濁音,X表示未定。標記為V的所有幀記為集合setV,標記為X的所有幀記為集合setX。
清音在高頻區(qū)(頻率大于950 Hz)雖然沒有能量中心,但和靜音相比有明顯的能量分布,在setX中各幀按照以下約束進行標記:
c=Cs…C,m∈setX
(17)
其中,U表示清音,S表示靜音,清音幀的集合記為setU,靜音幀的集合記為setS。
3.2 分割初判決
對分幀信號標記濁音、清音、靜音以后,可以得到語音的連續(xù)片段,稱為子段,記為S,Si={x1,x2,…,xMi},xj是第j幀的特征矢量,Mi是第i段的幀數(shù)。說話人A說了一串語音,該段語音中包含若干A的子段,然后轉(zhuǎn)變成B的若干子段。屬于同一說話人的子段之間相似度較高,而不同說話人之間的相似度較低。對完整語音按照說話人不同進行分割,就可以通過檢驗相鄰的子段對(Si,Si+1),對以下2種假設(shè)做出判決:
(18)
這是模型選擇問題,如果p(H0)>p(H1),則假設(shè)H0成立,反之亦然。對子段的特征訓(xùn)練單高斯模型,Si~N(μi,Σi),Si+1~N(μi+1,Σi+1),Si∪Si+1~N(μ,Σ),單高斯模型對特征進行似然度打分:
(19)
(20)
(21)
此時判決結(jié)果可以表示為:
(22)
貝葉斯信息準則(BIC)在模型選擇問題上具有較好的性能,并有廣泛的應(yīng)用[16],貝葉斯信息準則滿足:
(23)
其中,D是GECC特征維度,λ是調(diào)節(jié)因子,一般設(shè)為1即可。
對所有相鄰的子段對(Si,Si+1)進行貝葉斯信息準則判決,得到分割初步判決結(jié)果。
3.3 區(qū)間驗證
經(jīng)過貝葉斯信息準則判決后,已經(jīng)得到一定數(shù)量的說話人轉(zhuǎn)換點,區(qū)間驗證的作用是試圖利用音高信息,對可疑的轉(zhuǎn)化點進行剔除,并嘗試找回已經(jīng)被遺漏的轉(zhuǎn)化點。
根據(jù)貝葉斯信息準則判決產(chǎn)生的相鄰轉(zhuǎn)換點之間的時間幀區(qū)間內(nèi)存在的子段個數(shù)N,采用不同的處理策略。
當N=1時,兩相鄰轉(zhuǎn)換點之間有一個孤立子段,此時判斷孤立子段兩側(cè)轉(zhuǎn)換點之間的時間間隔是否足夠小,如果小于1 s且孤立子段的音高和左右兩側(cè)有一邊比較吻合,就剔除掉吻合度較低的那一側(cè)的轉(zhuǎn)化點。當1
4 實驗設(shè)置與數(shù)據(jù)分析
測試數(shù)據(jù)庫選用conTIMIT數(shù)據(jù)集[17],一共包含55條語音波形文件,統(tǒng)計語音時長3 675 s,有效分割點數(shù)1 071個,平均每個說話人段長3.29 s,最短1.14 s,最長11.75 s,標準差1.75 s。語音采樣頻率為16 000 Hz,實驗中語音分幀幀長20 ms,幀移10 ms,GFCC特征選擇23維基本特征加一階差分特征,MFCC特征選擇13維基本特征加一階差分特征。
對說話人轉(zhuǎn)化檢測的性能評價,用等錯率和F1值。當虛警率(False Alarm Rate,FAR)和漏報率(Miss Detection Rate,MDR)相等時,得到等錯率(Equal Error Rate,EER):
(24)
(25)
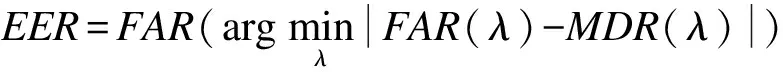
(26)
用召回率(Recall)和準確率(Precision)計算F1值:
(27)
(28)
(29)
其中,FA是轉(zhuǎn)換點虛報個數(shù),MD是未檢測出的轉(zhuǎn)換點個數(shù),GT是實際的轉(zhuǎn)換點個數(shù),GD是正確檢測出的轉(zhuǎn)換點個數(shù)。
在數(shù)據(jù)集上用貝葉斯信息準則作為距離準則得到說話人轉(zhuǎn)換點,并和加權(quán)距離度量(Weighted Distance Measure,WDM)[18]準則檢測的性能做對比。表1給出濁音子段、清音子段、語音子段(包含濁音和清音)的段長統(tǒng)計信息。分別計算分割邊界轉(zhuǎn)換點的漏報率-虛警率曲線,如圖3~圖5所示,對應(yīng)的等錯率結(jié)果如表2所示。單獨計算濁音子段,BIC和WDM兩種方法的轉(zhuǎn)換點與檢測點都是非常差的,80%的子段段長落在0.1 s~0.5 s范圍內(nèi),造成BIC失效。在同樣極短時間的條件下,清音子段的表現(xiàn)比濁音好得多。把相鄰濁音和清音連接成語音子段,段長平均達到1.34 s,與說話人識別的最低2 s的要求已經(jīng)比較接近,GECC特征在BIC準則下達到最好檢測效果,等錯率降到26.8%。

表1 濁音、清音、語音段長統(tǒng)計 s

圖3 濁音子段(V-S)虛警率和漏報率曲線

圖4 清音子段(U-S)虛警率和漏報率曲線

圖5 語音子段(UV-S)虛警率和漏報率曲線

表2 不同特征、不同子段類別切分等錯率 %
濁音子段的音高特征在說話剛開始時會出現(xiàn)跳高音陡降至穩(wěn)態(tài)基頻區(qū)的過程,在說話結(jié)束時幾乎都會發(fā)生從穩(wěn)態(tài)基頻降頻的收尾效應(yīng),但在同一個說話人語音內(nèi)跳躍幅度比較平穩(wěn),在區(qū)間驗證的過程中利用這一信息,既可以剔除掉一些虛警轉(zhuǎn)換點,也可以找回一些已經(jīng)漏掉的轉(zhuǎn)換點,從表3可以看到最終的等錯率可以下降到23.2%,相應(yīng)的F1值為70.0%。

表3 結(jié)合音高補償后的檢測性能 %
5 結(jié)束語
在基于聽覺場景分析的說話人轉(zhuǎn)變檢測中,由于伽馬通濾波器和毛細胞模型對人耳聽覺系統(tǒng)的模擬,可以將語音信號按照人的聽覺感知對各個頻帶進行精細劃分,得到準確的清音和濁音信息以及穩(wěn)健的基頻軌跡。基于此,本文一種提出基于聽覺場景分析的說話人轉(zhuǎn)換檢測方法。將語音分割成相鄰的若干語音子段(包含清音、濁音、極短靜音),提取伽馬通能量倒譜系數(shù)特征,在貝葉斯信息準則的判決下得到初始說話人轉(zhuǎn)換點,最后利用濁音的基頻特征對漏檢和錯檢的轉(zhuǎn)換點進行后處理,最終得到較好的檢測結(jié)果。在conTIMIT數(shù)據(jù)集上的測試結(jié)果表明,不做音高檢測,最優(yōu)性能是選用GECC特征在BIC準則下等錯率達到26.8%,利用音高信息,得到GFCC特征在BIC準則下性能提高到23.2%,GECC和GECC特征的性能優(yōu)于MFCC,BIC準則優(yōu)于WDM準則,在短時語音說話人快速轉(zhuǎn)變的口語對話環(huán)境中,即使無法訓(xùn)練說話人模型,也可以達到一定的檢測準確性。
[1] BAZYAR M,SUDIRMAN R.A New Speaker Change Detection Method in a Speaker Identification System for Two-speakers Segmentation[C]//Proceedings of 2014 ACM Symposium on Computer Applications and Industrial Electronics.New York,USA:ACM Press,2014:141-145.
[2] MALEQAONKAR A S,ARIYAEEINIA A M.Efficient Speaker Change Detection Using Adapted Gaussian Mixture Models[J].IEEE Transactions on Audio,Speech,and Language Processing,2007,15(6):1859-1869.
[3] ZAHID S,HUSSAIN F,RASHID M,et al.Optimized Audio Classification and Segmentation Algorithm by Using Ensemble Methods[J].Mathematical Problems in Engineering,2015(11):209-214.
[4] 鄭繼明,張 萍.改進的BIC說話人分割算法[J].計算機工程,2010,36(17):240-242.
[5] KOTTI M,BENETOS E,KOTROPOULOS C.Computa-tionally Efficient and Robust BIC-based Speaker Segmenta-tion[J].IEEE Transactions on Audio,Speech,and Language Processing,2008,16(5):920-933.
[6] YANG J,HE Q,LI Y,et al.Speaker Change Detection Based on Mean Shift[J].Journal of Computers,2013,8(3):638-644.
[7] WU Z,EVANS N,KINNUNEN T,et al.Spoofing and Countermeasures for Speaker Verification:A Survey[J].Speech Communication,2015,66(1):130-153.
[8] 張學(xué)良,劉文舉,李 鵬,等.改進諧波組織規(guī)則的單通道濁語音分離系統(tǒng)[J].聲學(xué)學(xué)報,2011,36(1):88-96.
[9] CUSACK R,DECKS J,AIKMAN G,et al.Effects of Location,Frequency Region,and Time Course of Selective Attention on Auditory Scene Analysis[J].Journal of Experimental Psychology:Human Perception and Performance,2004,30(4):643-656.
[10] MAKA T.Change Point Determination in Audio Data Using Auditory Features[J].International Journal of Electronics and Telecommunications,2015,61(2):185-190.
[11] MEDDIS R.Simulation of Mechanical to Neural Transduction in the Auditory Receptor[J].The Journal of the Acoustical Society of America,1986,79(3):702-711.
[12] LI L.Performance Analysis of Objective Speech Quality Measures in Mel Domain[J].Journal of Software Engineering,2015,9(2):350-361.
[13] KAUR G,SINGH D,RANI P.Robust Speaker Recognition Biometric System a Detailed Review[J].Emerging Research in Management & Technology,2015,4(5):281-288.
[14] 王 民,任雪妮,孫 潔.一種高效的基音檢測與評估算法[J].計算機工程與應(yīng)用,2014,50(14):126-132.
[15] 胡 瑛,陳 寧.基于小波變換的清濁音分類及基音周期檢測算法[J].電子與信息學(xué)報,2008,30(2):353-356.
[16] CHEN S,GOPALAKRISHNAN P.Speaker,Environment and Channel Change Detection and Clustering via the Bayesian Information Criterion[C]//Proceedings of Broadcast News Transcription and Understanding Workshop.San Francisco,USA:Morgan Kaufmann Publishers,1998:127-132.
[17] SEO J S.Speaker Change Detection Based on a Graph-partitioning Criterion[J].The Journal of the Acoustical Society of Korea,2011,30(2):80-85.
[18] KWON S,NARAYANAN S S.Speaker Change Detection Using a New Weighted Distance Measure[C]//Pro-ceedings of the 7th International Conference on Spoken Language Processing.Washington D.C.,USA:IEEE Press,2002:2537-2540.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
