一種高效的文本區間熱詞查詢算法
2018-03-03 01:26:41趙志洲何震瀛王曉陽
計算機工程 2018年2期
關鍵詞:文本
趙志洲,路 暢,何震瀛,王曉陽
(復旦大學 計算機科學技術學院,上海 200433)
0 概述
互聯網高速發展使人們獲取海量信息變為可能,但隨之帶來一些新問題,如“如何從海量Web文本信息中提取用戶感興趣的熱門話題”。
為有效進行話題檢測和跟蹤(Topic Detection and Tracking,TDT),研究者開展了大量研究工作[1-2],其中從文本數據中提取熱詞成為當前研究的熱點問題之一[3-5]。文獻[6]提出TF-IDF(Term Frequency-Inverse Document Frequency)用于詞權重計算,TF-IDF綜合考慮詞頻和反文檔頻率,弱化頻繁出現在多個文檔中的詞的重要性。文獻[7]提出TF-PDF (TF-Proportional Document Frequency)方法,TF-PDF綜合考慮詞頻和文檔頻率,將更高的權重賦予出現在多個文檔中的詞。文獻[8](下文稱Chen算法)在TF-PDF方法的基礎上,考慮詞頻隨時間的波動情況,并重新定義詞權重的計算方法。上述方法能夠有效提取與話題相關的詞,即滿足算法的有效性。文獻[9]基于熱度矩陣對微博熱點話題進行檢測。但是這些算法的一個特點是:面向挖掘任務,時間復雜度較高,因此,難以直接應用于熱詞在線查詢問題。
為此,本文對文本數據的區間熱詞在線查詢問題展開研究。熱詞的在線查詢處理方法需要同時滿足2個特性:有效提取與話題相關的詞,即在線查詢的有效性;快速獲得查詢時間范圍內的熱詞,即在線查詢的時效性。因此,設計同時滿足有效性和時效性的熱詞在線查詢方法依然是一個具有挑戰性的問題。針對上述方法時效性不足的缺點,本文提出一種文本數據區間熱詞在線查詢處理算法(EHWE),該算法可以在已劃分的數據上進行快速區間查詢處理。
1 相關工作
本文常用到的符號如表1所示。
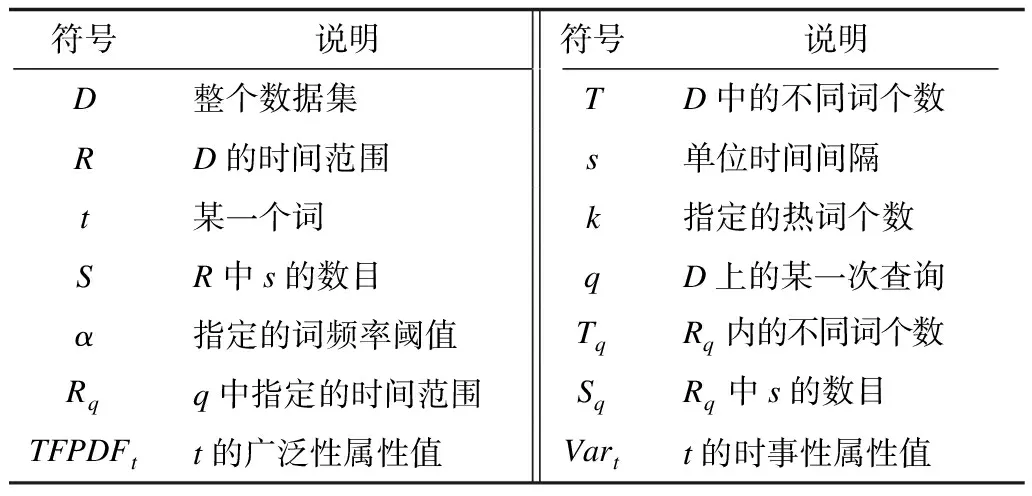
表1 符號說明
1.1 熱詞提取
熱詞提取廣泛應用于熱門話題分析。熱門話題是指在一段時間內,受到人們廣泛關注并討論的話題。在新聞報道中,話題的熱度取決于2個因素[7]:在一篇報道中熱詞出現的頻率以及包含這些熱詞的新聞報道的數量。一般而言,話題不會在所有時間中保持它的熱度,它有一個從產生、興起、成熟和衰亡的過程[10]。國內外學者在TDT的基礎上提出了很多熱門話題發現的方法,其中基于熱詞的提取并聚類的方法成為一種主流的研究方法[11-14]。
熱詞是指在一段時間內頻繁出現的詞。它用來描述熱門話題,并且會隨著熱門話題的生命周期而不斷變化。針對熱詞的提取,Chen算法綜合考慮詞頻和詞表述話題的能力。實驗結果表明,與TF-IDF[5]和TF-PDF[6]相比,Chen算法能夠有效地過濾與話題無關的詞,并賦予與話題相關的名詞短語或實體名詞更高的權重,滿足算法的有效性。Chen算法中一個詞的權重被定義如下:
(1)
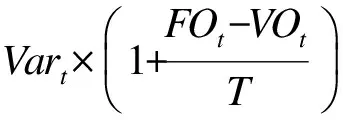
(2)
其中,t是一個詞,Ft表示詞t在數據集中出現的頻率,nt表示包含詞t的文檔個數,N表示在給定數據集中文檔的總數。熱詞的時事性用來刻畫詞的使用頻率隨著時間的變化情況。一個詞在不同時間段上的使用頻率差異越大,那么這個詞越具有時事性,計算公式如下:
(3)
Chen算法在提取熱詞時分為3個步驟:
步驟1計算所有詞的詞頻,并獲得跟蹤列表;
步驟2對于跟蹤列表中的每個詞,計算詞權重;
步驟3根據權重將詞排序,選取權重最大的k個詞作為熱詞。
Chen算法能夠有效地提取與話題相關的詞,但時間復雜度較高,在實際應用中,由于數據集的龐大以及需要多次查詢的緣故,該算法的效率低下,因此難以直接用來進行文本區間熱詞的在線查詢處理。
1.2 具有詞頻約束的區間查詢
2 文本區間熱詞的查詢處理方法
2.1 問題描述
文本區間熱詞的在線查詢問題描述如下:
對于數據集D上的任意查詢q,q={Rq,k},返回區間Rq上的k個熱詞,其中Rq=[m,n],m和n表示查詢時間范圍的起止時間;k表示指定提取的熱詞個數。例如查詢q={20160101,20160331,1000},返回2016年1月1日—2016年3月31日之間按熱度遞減排序的前1 000個詞。原始數據集中的每篇文檔都有一個時間屬性,以原始數據集中出現的最小的時間間隔作為單位時間間隔,統計每個單位時間間隔內不同詞出現的次數,并構建數據集D。它的形式化描述為D={s,t,c},其中,s表示時間間隔,t表示詞,c表示相應時間間隔s中詞t出現的次數。數據集D上的數據結構如表2所示。
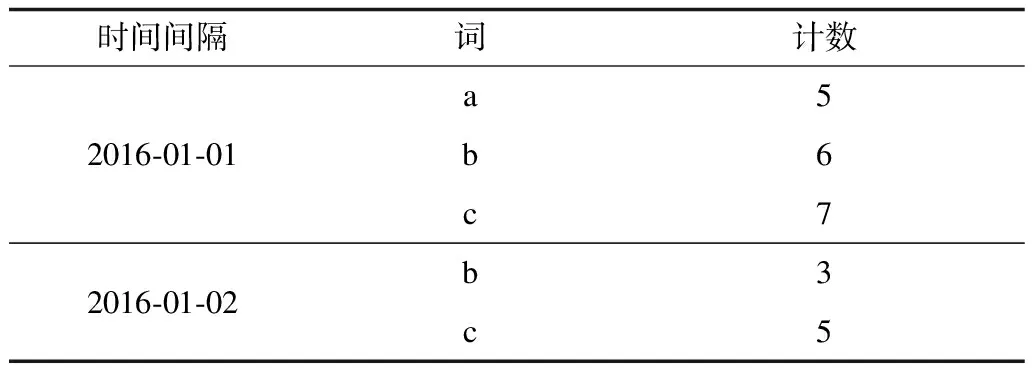
表2 數據集D的數據結構
若文本數據中時間屬性值的下限和上限分別是l和u,則l≤m≤n≤u。
2.2 EHWE算法
2.2.1 數據結構
通過對Chen算法進行分析發現,對于一個給定的查詢q,在獲得跟蹤列表時,需要計算q中所有詞在Rq中的詞頻;在計算一個詞在Rq中的詞頻和TFPDF值時,需要遍歷這個詞在查詢時間范圍內的每個單位時間間隔的計數。為減少獲得跟蹤列表時需要計算的詞數目以及優化詞的計數結構,本節分別利用數據劃分和范圍查詢的思想,對原始數據進行預處理并建立數據結構,使得獲得跟蹤列表和對查詢q中詞計數的時間復雜度分別為O(1)。
1)數據劃分
本文利用數據劃分的思想,將查詢q與一個四元組U相關聯。在獲得跟蹤列表時,只需要判斷U對應的候選詞列表C中的詞是否滿足在Rq中的詞頻大于α的條件。因為C的長度要遠小于Rq中不同詞的個數Tq,所以達到了優化目標。
在數據集中,一個時間間隔內可以有任意整數個不同詞,每個詞可以出現任意整數個數。首先為全部單位時間間隔建立索引,索引范圍為[1:S];隨后在每個單位時間間隔內,為每個不同詞依次構建索引,最大索引下標是S×T,故索引范圍為[1:ST],所以建立索引結構后,數據集D中包括:單位時間間隔si及其索引i,si中出現的詞tij,詞tij的索引j,詞出現的次數nij。假設詞tij在si上不出現時,它的計數為0。
表3是對數據集D建立的索引結構的舉例,和表2對應。
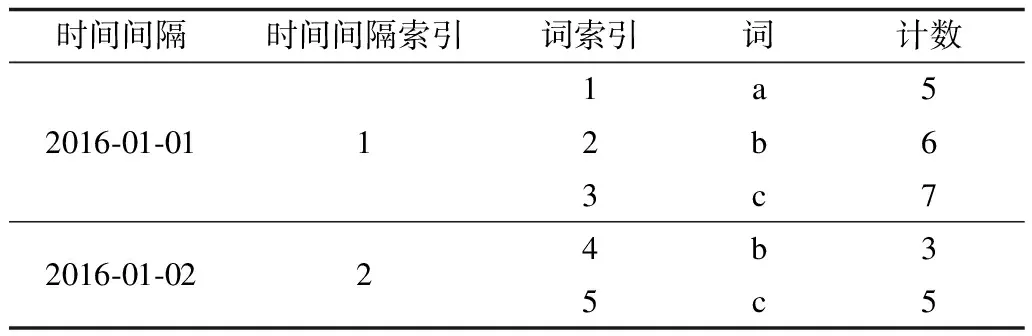
表3 對數據集D建立的索引結構
令Rq=[m:n],在計算查詢q中滿足詞頻大于α的詞時,需要根據m和n找到詞索引的范圍[jm,jn],并計算該范圍內不同詞的詞頻。算法1是對數據集劃分算法的形式化描述:
算法1數據集的劃分算法
輸入數據集D
輸出候選詞列表C
1. 構建概念上的二叉樹;
2. FOR 樹中的每層l:
3. 構建每層的全部四元組U;
4. FOR 全部層的U:
5. 計算候選詞列表;

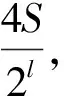
(4)
例如,當Rq=[1∶16]、l=3時,一共有8個節點,每個節點的長度為2;可以劃分為3個四元組,每個四元組的長度是8,它的劃分規則如圖1所示。
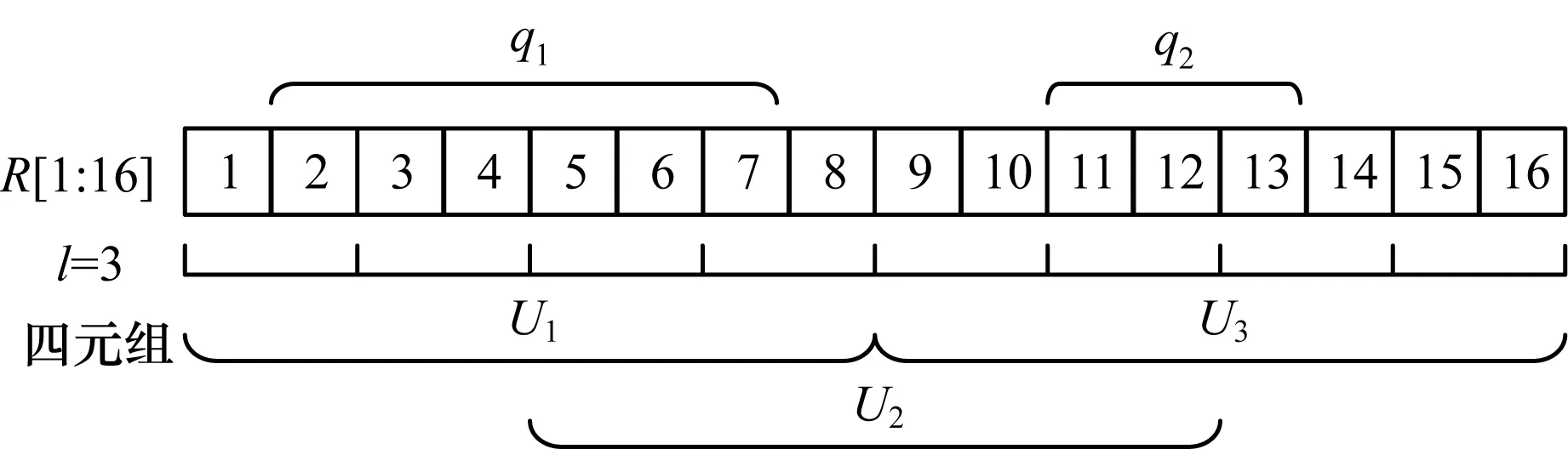
圖1 S=16、l=3時數據的劃分規則
通過對二叉樹每一層劃分四元組,可以發現對于在整個時間范圍上的任意范圍的查詢q,能夠找到一個特定的層l和四元組Up,使得查詢q至少包含這個四元組中的一個節點,至多包含2個非兄弟節點,即查詢q是和Up相關的。例如圖1中的查詢q1和q2,q1對應于l=3,p=1;q2對應于l=3,p=3。
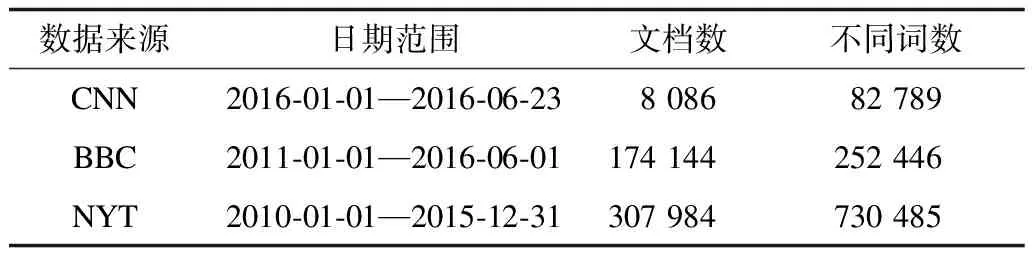
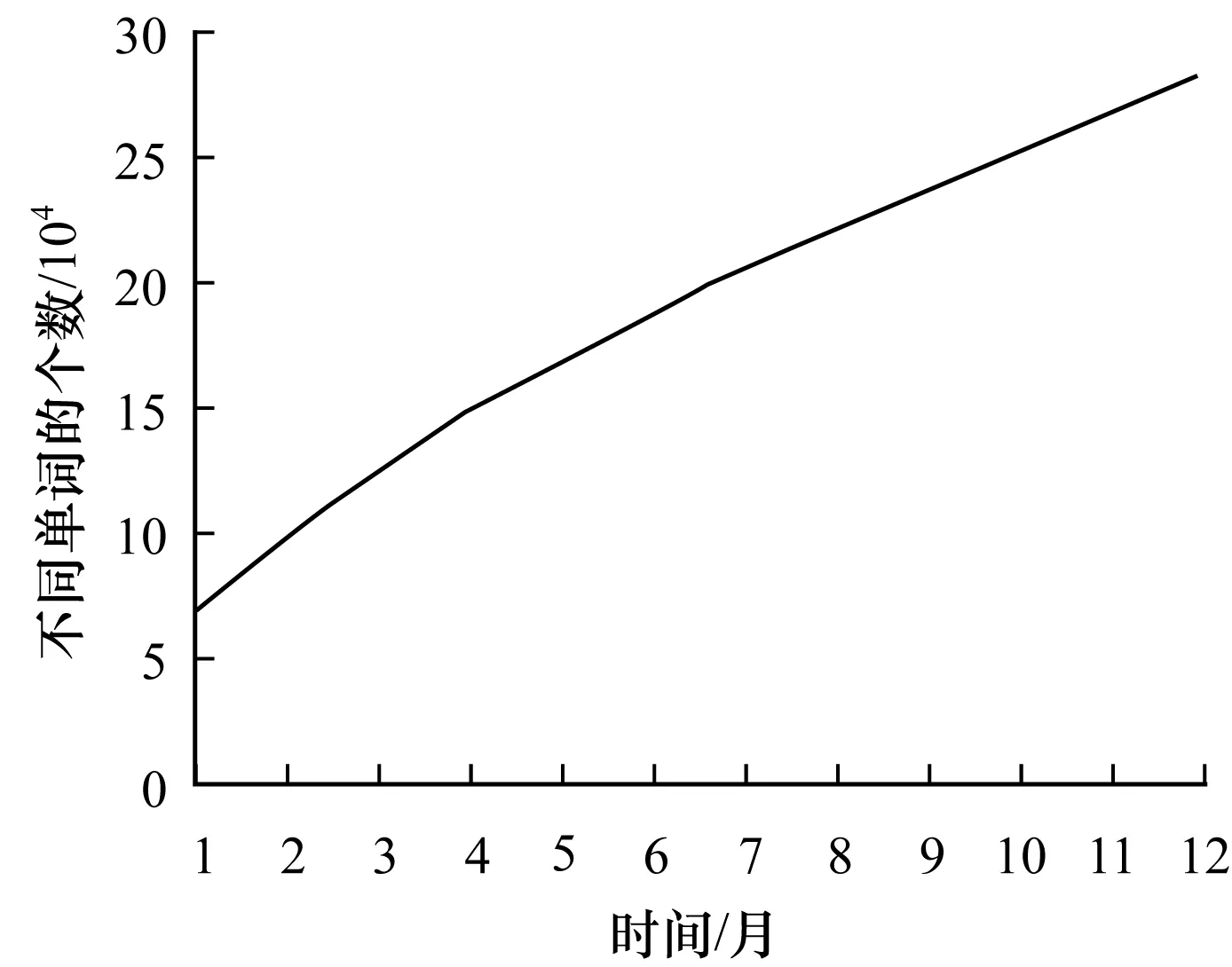
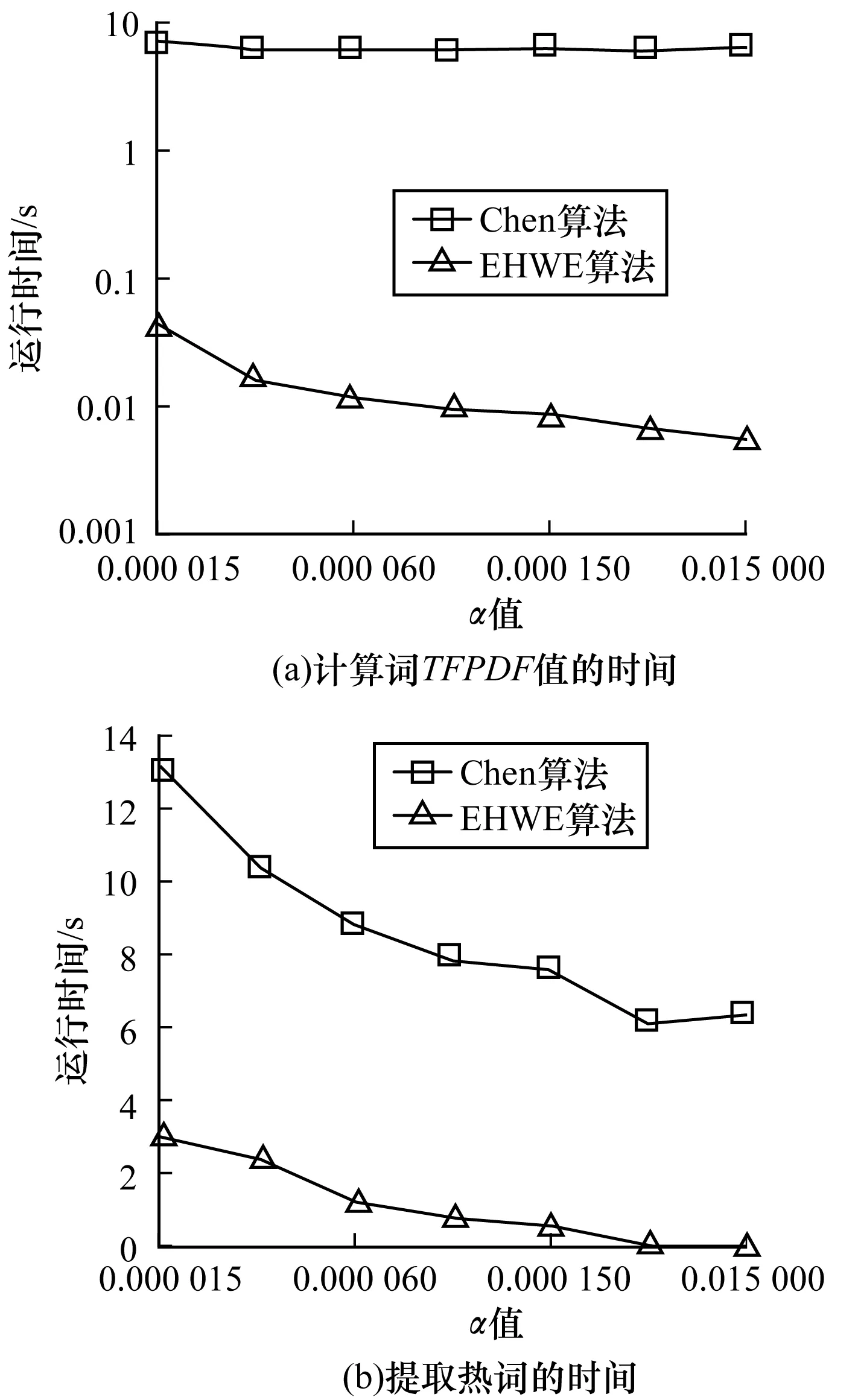
假設四元組Up對應的時間間隔中一共有σ個不同的詞(σ 2)詞計數結構 令Rq=[m:n],Up為與其相關的四元組,Cp是Up對應的候選詞列表。為獲得跟蹤列表,需要遍歷Cp中每個詞,并計算它們在Rq中的詞頻,如果滿足條件,則將其加入到跟蹤列表中。在計算一個詞的詞頻時,Chen算法需要遍歷詞在Rq內每個單位時間間隔內的計數,這個過程的時間復雜度是O(ST)。顯然,算法1雖然減少了獲得跟蹤列表時需要計算的詞數目,但整體的時間復雜度并沒有降低,仍為O(ST)。為優化計算Cp中每個詞在Rq中的詞頻的時間復雜度,算法2優化了詞計數的數據結構,使得計算一個詞t在Rq中的詞頻的時間復雜度為O(1)。這一過程的形式化描述如下: 算法2查詢q中詞計數優化算法 輸入數據集D 輸出每個單位時間間隔中詞總數的數組total;每個詞在每個單位時間間隔中的數量的數組t_c 1. FOR 每個不同的詞t: 2. t_c[t][1]=t在第一個單位時間間隔中的數量; 3. FOR s FROM 2 TO S: 4. t_c[t][s]=t_c[t][s-1]+s中t的數量; 5. total[1]=第一個單位時間間隔中所有詞的數量 6. FOR s FROM 2 TO S: 7. total[s]=total[s-1]+s中所有詞的數量 由算法2可知,當Rq=[m:n]時,詞t的詞頻freqt,m,n=countt,m,n/Totalm,n,計算freqt,m,n的時間為O(1),其中,countt,m,n=t_c[t][n]-t_c[t][m-1]、Totalm,n=total[n]-total[m-1]。 同理,在計算一個詞的TFPDF值時,可以用算法2中的數據結構來優化詞頻和文檔頻率的計算過程,使得計算的時間復雜度為O(1)。 2.2.2 EHWE算法描述 基于以上的數據結構,對于任意一個查詢Rq=[m:n],EHWE算法的形式化描述如下: 算法3EHWE算法 輸入C,total,t_c,查詢q 輸出熱詞和權重 1. 根據查詢q指定的參數m、n 2. 獲得候選詞列表Cp 3. 計算m、n范圍內詞總數Totalm,n 4. FOR Cp中的每個詞 t 5. 計算詞t在中出現的次數Countt,m,n 6. IF Countt,m,n>α×Totalm,nTHEN 7. 將詞t加入到跟蹤列表 8. FOR跟蹤列表的每個詞t 9. 計算t的權重wt(根據式(1)); 10.根據權重排序選擇前k個詞 對一個查詢Rq=[m∶n],它的長度是m-n+1,如果對應的層級是l,四元組是p,那么有: (5) (6) 由算法3可知,在EHWE算法中,計算詞權重并提取熱詞時主要分為4個步驟: 步驟1根據m、n的值,返回與查詢q相關的候選詞列表; 步驟2判斷候選列表中的詞是否滿足頻率大于α的條件,若滿足,則將其加入到跟蹤列表; 步驟3對于跟蹤列表中的每個詞,計算詞的權重; 步驟4根據權重,將詞降序排序,并返回前k個作為熱詞。 通過對2種算法的空間復雜度分析可以發現,Chen算法需要存儲整個數據集D,空間復雜度為O(ST);EHWE算法需要存儲所有四元組對應的候選詞列表C以及C中每個詞的計數數組,它的空間復雜度為O(ST)。所以,Chen算法、EHWE算法的空間復雜度保持不變。 3.1.1 數據源 本節對Chen算法和本文提出的EHWE算法進行實驗比較。實驗環境為:Intel Xeon(R) CPU E5-2650v3 @ 2.30 GHz×40,128 GHz內存和256 GB磁盤,操作系統為Ubuntu Kylin16.04,程序設計語言為Java,使用JDK1.8。實驗數據來源于美國有線電視新聞網(CNN)、英國廣播公司(BBC)和紐約時報(NYT),數據集統計信息如表4所示。 表4 數據統計信息 數據集D中最小的時間單位是d,所以本文實驗中查詢的單位時間間隔為d。在實驗之前,本文使用Stanford CoreNLP對原始的文本集進行預處理,包括去除停止詞、分詞、詞形還原。 3.1.2 數據分析 在EHWE算法中,為使任意的查詢都能找到與之相關的四元組,需要對整個數據集涉及的時間間隔構建完全二叉樹,并且保證每個葉子節點實際大小(包含的詞總數)近似相等。如果不滿足這個條件,則會使得四元組對應的候選詞數目大于上限(4/α-1)。在極端情況下,若每個四元組中都有一個節點的大小為1,那么候選詞的數目等于查詢q中詞的總數。為使候選詞列表中詞的數目小于q中詞的數目,需要將包含詞數目非常少的連續單位時間間隔合并,并重新構建完全二叉樹。 在本文實驗中,數據集的單位時間間隔是d,所以,統計了3個數據集中每天的新聞報道中詞的總數,如圖2所示為BBC數據集在2014年每天新聞報道中的出現的詞總數,可以發現詞總數在一條水平基線上波動,說明在2014年英國廣播公司每天的新聞報道中用詞數量是穩定的。 圖2 BBC 2014年每天的新聞報道中詞總數 表5中統計了3個文本集在整個時間戳上每天出現詞數目的最大值、最小值以及對數據0-1標準化后的標準差,3個數據集的標準差均小于0.2,說明這3個新聞來源每天的新聞報道數量整體上是穩定的,不需要進行合并操作,可以直接在整個時間間隔構建完全二叉樹。 表5 數據集分析 為比較Chen算法和EHWE算法運行時間,本節在上述3個數據集上分別進行實驗,實驗結果如圖3所示。 圖3 運行時間隨查詢時間長度的變化 在實驗中,頻率閾值α為0.000 015。從圖3可以看出,在CNN、BBC和NYT 3個數據集上,Chen算法和EHWE算法的運行時間會隨著查詢時間的增長而增長,與Chen算法相比,EHWE算法在3個數據集涉及的整個時間范圍上的運行時間分別減少59.7%、65.1%和75.5%。與Chen算法相比,EHWE算法減少的時間主要來源于獲得跟蹤列表并計算詞的TFPDF值時運行時間。本文統計了NYT數據集上2種算法在獲得跟蹤列表并計算詞的TFPDF值過程的時間消耗,如圖4所示。 圖4 跟蹤列表及詞TFPDF值的時間比較 從圖4可以看出,EHWE算法的這部分運行時間接近為常數,而Chen算法在這部分的運行時間隨著查詢時間的增長而增長。這是因為EHWE算法這部分的時間復雜度為O(1),而Chen算法的這部分時間復雜度是O(ST),并且T和S相關。 如圖5所示,通過統計紐約時報在2014年隨著時間按照月份依次遞增時,在數據集中出現不同詞的個數,可以發現T和S是線性相關的,所以在獲得跟蹤列表并計算詞的TFPDF值時,Chen算法的時間消耗會呈現如圖4所示的指數增長。 圖5 紐約時報2014年前n月份中出現的詞總數 α是用戶事先設定的頻率閾值,表示一個詞能成為熱詞的最低頻率。α值越大,表示滿足條件的詞個數理論上就會越少。本文實驗比較α值不同時對Chen算法和EHWE算法的影響,如圖6所示。 圖6 2種算法運行時間隨α變化的影響 圖6(a)和圖6(b)分別表示在給定不同的α值時,Chen算法和EHWE算法關于獲得跟蹤列表并計算詞TFPDF值(以下稱A過程)以及整個提取熱詞(以下稱B過程)過程中時間的消耗。實驗的數據集是NYT,查詢的時間范圍是2010年1月—2015年12月。從圖6(a)可以發現,當α值增大時,2種算法在A過程的時間消耗并沒有顯著變化,說明A過程的運行時間消耗與α的大小無關,這是因為它們的時間復雜度分別是O(ST)和O(1),并且S和T與查詢的時間范圍有關。由圖6(b)可以發現,隨著α的增加,2種算法在B過程的運行時間消耗會降低,并且趨于穩定。這是因為隨著α的增加,跟蹤列表中詞數目會減小,所以計算詞權重的時間消耗會減少。在極端情況下,當跟蹤列表中的詞數目為0時,2種算法在B過程的時間消耗會近似等于A過程的時間消耗,并且Chen算法的時間消耗大于EHWE算法。綜上所述,當α值不斷增大時,EHWE算法在數據集上的運行時間仍小于Chen算法的運行時間。 本文主要貢獻包括: 1)提出文本區間熱詞的在線查詢處理問題,與面向挖掘的熱詞提取問題相比,更加關注在線查詢的2個特性:有效性和時效性; 2)設計了EHWE算法,該算法能夠在保證計算結果準確率的前提下,降低了提取熱詞的時間復雜度; 3)理論分析和實際數據集上的實驗結果都表明EHWE算法優于Chen算法。 本文對文本區間熱詞在線查詢問題進行研究。在Chen算法基礎上,通過數據劃分和范圍查詢,對原始數據進行預處理,并提出EHWE算法,在保證準確率和空間復雜度不變的條件下,降低了提取熱詞的時間復雜度。實驗結果表明,EHWE算法在CNN、BBC、NYT3個文本集上的時間代價要小于Chen算法。本文EHWE算法中尚未考慮對計算詞Var值的優化,這將是下一步的主要工作。另外,基于熱詞的文本聚類算法以及對聚類的優化也需要進一步研究。 [1] FISCUS J G,DODDINGTON G R.Topic Detection and Tracking Evaluation Overview[M].New York:USA:Kluwer Academic Publishers,2002. [2] 洪 宇,張 宇,劉 挺,等.話題檢測與跟蹤的評測及研究綜述[J].中文信息學報,2007,21(6):71-87. [3] ALLAN J,PAPKA R,LAVRENKO V.On-line New Event Detection and Tracking[C]//Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,USA:ACM Press,1998:37-45. [4] 周亞東,孫欽東,管曉宏,等.流量內容詞語相關度的網絡熱點話題提取[J].西安交通大學學報,2007,41(10):1142-1145. [5] HISAMITSU T,NIWA Y.A Measure of Term Represent-ativeness Based on the Number of Co-occurring Salient Words[C]//Proceedings of the 19th International Con-ference on Computational Linguistics-Volume 1.Stroudsburg,USA:Association for Computational Linguistics,2002:1-7. [6] SALTON G,YANG C S.On the Specification of Term Values in Automatic Indexing[J].Journal of Documen-tation,1973,29(4):351-372. [7] BUN K K,ISHIZUKA M.Topic Extraction from News Archive Using TF*PDF Algorithm[C]//Proceedings of International Conference on Web Information Systems Engineering.Washington D.C.,USA:IEEE Computer Society,2002:73-82. [8] CHEN K Y,LUESUKPRASERT L,CHOU S T.Hot Topic Extraction Based on Timeline Analysis and Multi-dimensional Sentence Modeling[J].IEEE Transactions on Knowledge & Data Engineering,2007,19(8):1016-1025. [9] 聶文匯,曾 承,賈大文.基于熱度矩陣的微博熱點話題發現[J].計算機工程,2017,43(2):57-62. [10] CHEN C C,CHEN Y T,SUN Y,et al.Life Cycle Modeling of News Events Using Aging Theory[C]//Proceedings of European Conference on Machine Learning.Berlin,German:Springer,2003:47-59. [11] 王 林,藏冠中.基于復雜網絡社區結構的論壇熱點主題發現[J].計算機工程,2008,34(11):214-216. [12] 高 妮,周明全,耿國華,等.基于文本挖掘的話題發現技術[J].計算機工程,2009,35(19):36-38. [13] KUMARAN G,ALLAN J.Text Classification and Named Entities for New Event Detection[C]//Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,USA:ACM Press,2004:297-304. [14] 黃承慧,印 鑒,侯 昉.一種結合詞項語義信息和TF-IDF方法的文本相似度量方法[J].計算機學報,2011,34(5):856-864. [15] YAO A C.Space-time Tradeoff for Answering Range Queries[C]//Proceedings of the 14th Annual ACM Symposium on Theory of Computing.New York,USA:ACM Press,1982:128-136. [16] DUROCHER S,SHAR R,SKALA M,et al.Linear-space Data Structures for Range Frequency Queries on Arrays and Trees[J].Algorithmica,2016,74(1):344-366. [17] CHAN T M,DUROCHER S,SKALA M,et al.Linear-space Data Structures for Range Minority Query in Arrays[J].Algorithmica,2015,72(4):901-913. [18] GREVE M,JORGENSEN A G,LARSEN K D,et al.Cell Probe Lower Bounds and Approximations for Range Mode[M].Berlin,Germany:Springer,2010. [19] KARPINSKI M,NEKRICH Y.Searching for Frequent Colors in Rectangles[C]//Proceedings of the 20th Annual Canadian Conference on Computational Geometry.Vancouver,Canada:[s.n.],2008:11-19. [20] DUROCHER S,HE M,MUNRO J I,et al.Range Majority in Constant Time and Linear Space[C]//Proceedings of International Colloquim Conference on Automata,Languages and Programming.Berlin,Germany:Springer,2011:244-255. 編輯 索書志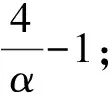


2.3 復雜度分析
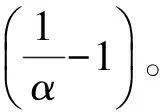
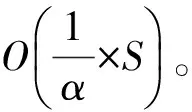
3 實驗與結果分析
3.1 數據源與數據分析
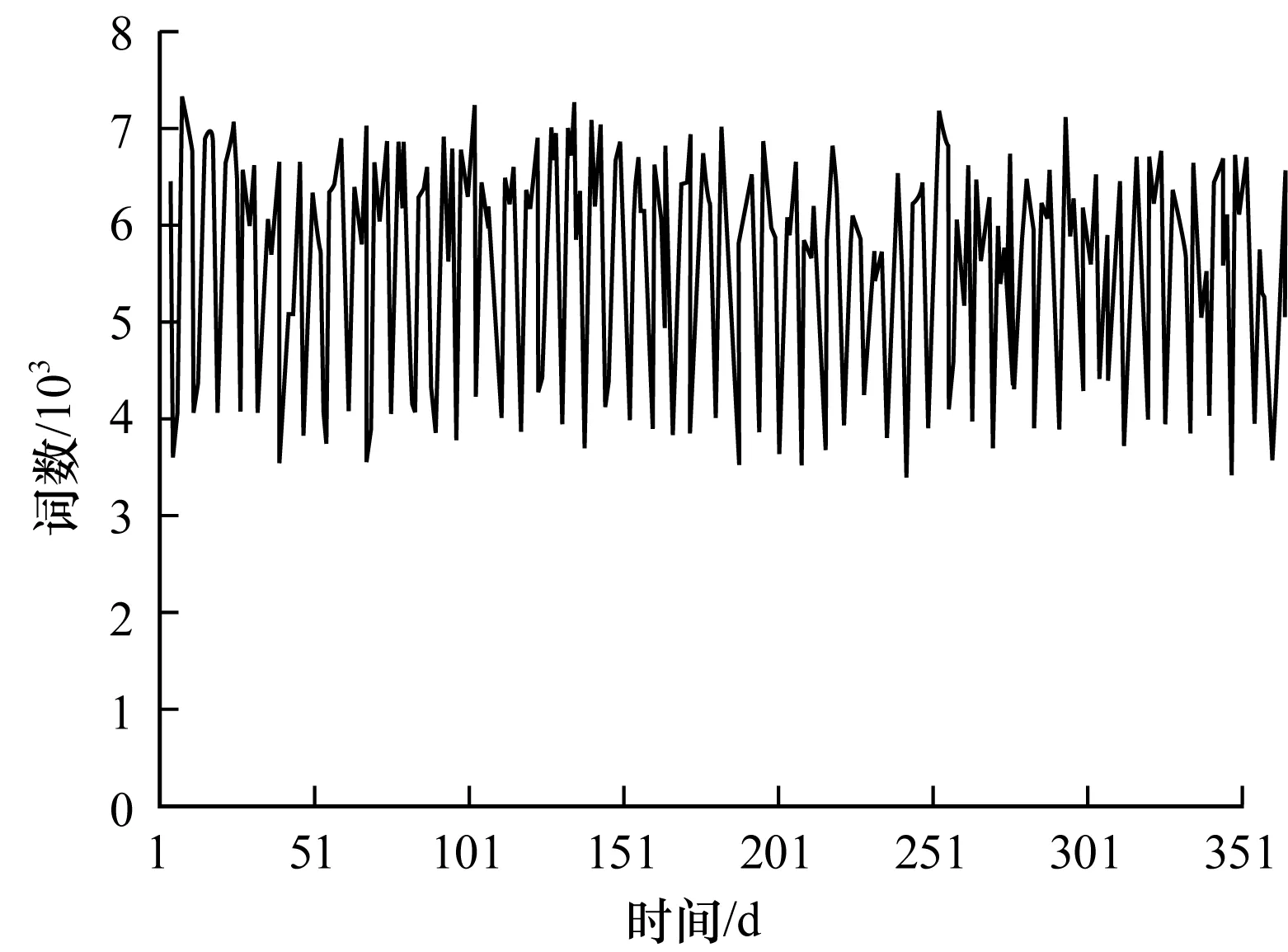
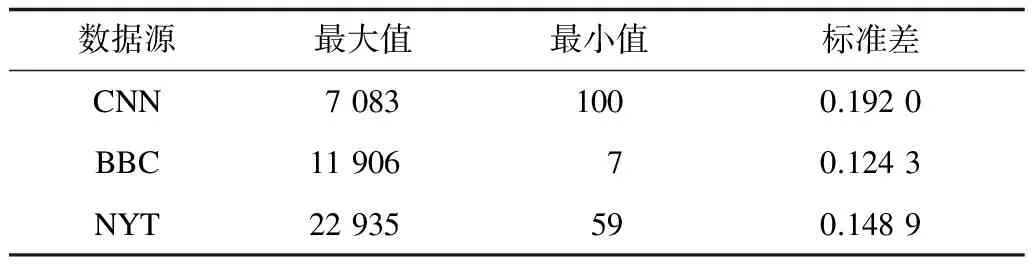
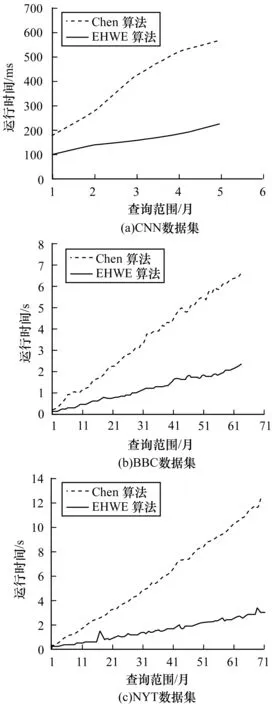
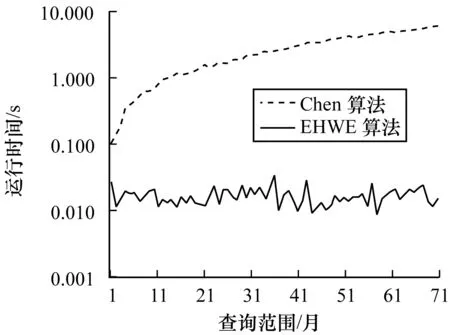
3.2 Chen算法和EHWE算法的運行時間比較
3.3 參數α的分析
4 結束語
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
