基于局部特征的卷積神經網絡模型
2018-03-03 01:26:24顧大權趙章明
計算機工程 2018年2期
施 恩,李 騫,顧大權,趙章明
(解放軍理工大學 氣象海洋學院,南京 211101)
0 概述
大數據的發展促使深度學習在語音識別、圖像分類、文本理解等眾多領域得到了廣泛應用,深度學習的計算模式是先從訓練數據出發,經過一個端到端的模型,然后直接輸出得到最終結果[1]。卷積神經網絡(Convolutional Neural Network,CNN)是深度學習的重要分支,由于CNN具有特殊的網絡結構,因此其在圖像處理領域具有深遠的研究前景,近年來得到高度重視并引起廣泛研究[2]。
卷積神經網絡起源于Hbbel和Wiesel對貓的視覺皮層神經元細胞研究[3],并在多層感知器的基礎上發展成為一種深層神經網絡。紐約大學的LeCun Yann提出了經典卷積神經網絡模型LeNet[4-5],該網絡模型采用后向傳播算法(Back Propagation,BP)更新網絡權值參數,對此后的研究工作有著深遠的影響。此后,AlexNet網絡模型[6]被認為是對卷積神經網絡改進工作中的重大突破。此后還出現了GoogleNet、ResNet等新的網絡模型,它們的主要改進思路是增加網絡深度。
由于卷積神經網絡受生物視覺認知方式啟發而來,具有特殊的網絡結構,與BP神經網絡等其他神經網絡相比,卷積神經網絡在處理圖像時具有直接性和高效性:直接性體現在卷積神經網絡可以直接將原始圖像作為輸入,避免了對圖像的復雜前期預處理,提高了算法效率;高效性體現在卷積神經網絡的權值參數少、收斂速度快,很大程度上加快了網絡的訓練過程。同時,卷積神經網絡因其學習和記憶特性,在識別圖像時無需給出經驗知識和判別函數,只需通過樣本訓練網絡,并根據網絡輸出與樣本目標輸出的差值調整權值參數,利用訓練好的網絡能夠對輸入圖像進行分類,達到識別目的。
傳統的卷積神經網絡在處理特征模糊、歧義性大的輸入圖像時容易受到圖像中不相關信息誤導,難以保證較高的識別率。若能將圖像中不相關的信息屏蔽,提高特征明顯的局部圖像對整幅圖像輸出結果的影響權重,即能有效提高對于特征模糊圖像的識別率。基于上述思想,本文構建基于局部特征的卷積神經網絡模型(Convolutional Neural Network Model Based on Local Feature,CNN-LF)。
1 卷積神經網絡
卷積神經網絡作為深度學習的重要分支,被廣泛應用于圖像處理、模式識別等領域。該網絡最大的特點在于采用局部連接、權值共享、下采樣的方法來模擬生物視覺神經元細胞的工作機制,對輸入圖像的形變、平移和翻轉具有較強的適應性。其中局部連接使網絡中的每一個神經元只與上一層網絡中鄰近的部分神經元相連,簡化了網絡模型;權值共享使得卷積濾波器共享相同的權重矩陣和偏置項,很大程度上減少了需要訓練的權值參數數量;下采樣能夠減小特征圖的分辨率,從而降低計算復雜度,并使網絡對圖像的平移、形變不敏感[7-10]。
與其他神經網絡相比,卷積神經網絡的獨特性在于采用卷積層和下采樣層交替的方式提取圖像特征,從而減少訓練參數的數量,在保持網絡學習能力的同時,降低網絡訓練難度[11]。
1.1 卷積層
在卷積層中,輸入特征圖與卷積濾波器相卷積,卷積結果加上一個偏置項作為激活函數的輸入,經過激活函數處理后得到該層的輸出特征圖。為一個k階矩陣,包含k×k個可訓練參數。對于一個大小為m×n的輸入特征圖,與k×k的卷積核相卷積之后,輸出特征圖大小為(m-k+1)×(n-k+1)。卷積層的表達形式為:
(1)
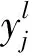
圖1展示了一個5×5的輸入圖像與3×3的卷積核相卷積的過程。
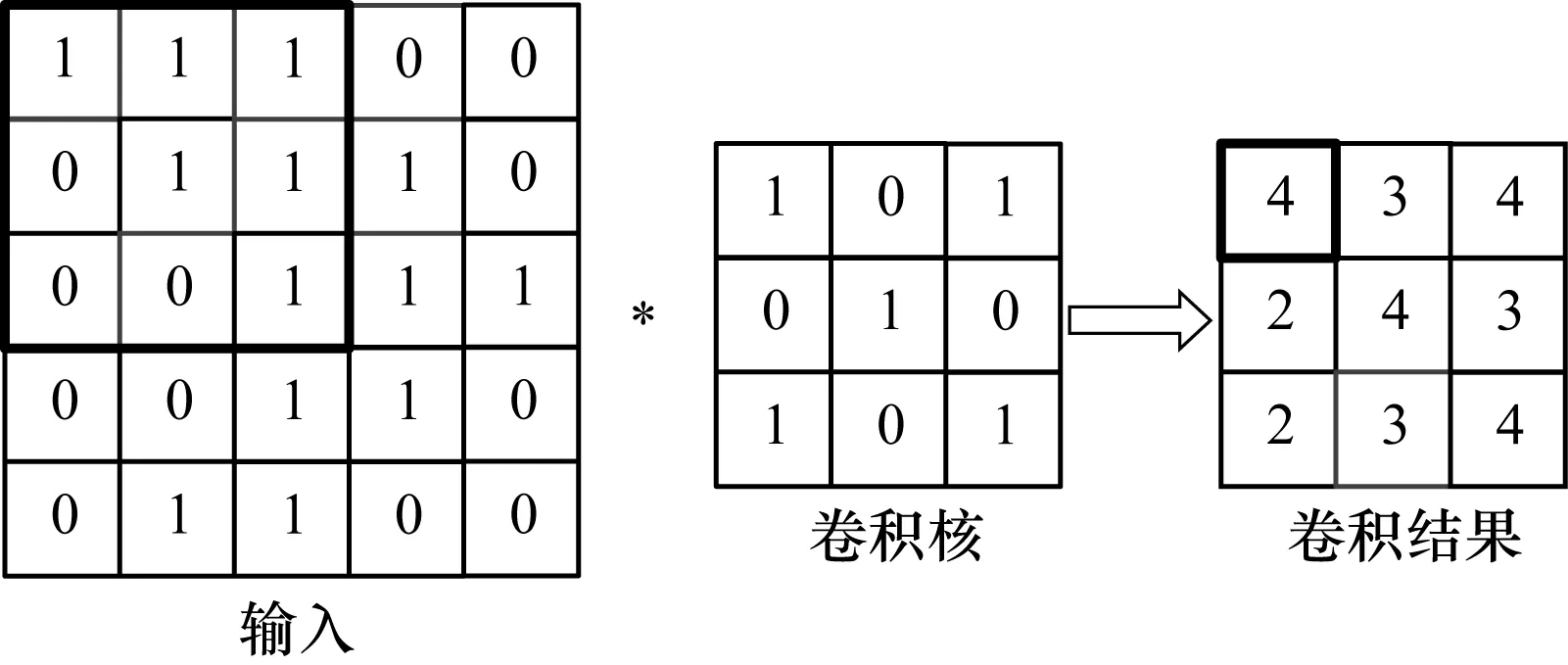
圖1 卷積操作示意圖
1.2 下采樣層
在下采樣層中,要對輸入特征圖進行降分辨率。將提取到的圖像特征映射到更小的平面范圍中,以簡化網絡結構,降低計算規模。下采樣是以一定步長對輸入特征圖進行采樣,而非連續采樣,一般情況下采樣步長與采樣核寬度相一致。若采樣核大小為s×s,則需要將輸入特征圖劃分為若干個s×s的子區域進行映射,每個區域經過采樣函數后輸出一個特征值,這就使輸出特征圖的尺寸降為輸入特征圖的1/s。下采樣層的表達形式為:
(2)

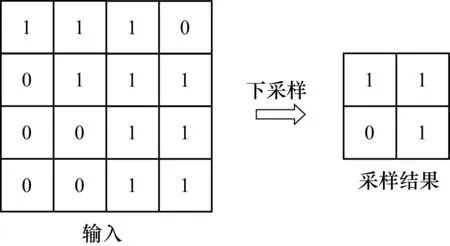
圖2 下采樣示意圖
2 CNN-LF模型
2.1 改進思想
卷積神經網絡在識別圖像過程中有時會因為輸入圖像中存在干擾信息而影響識別結果,圖3為包含干擾信息的2張手寫數字圖像。在圖3(a)中,右側圖像是左側圖像取左下部分的局部圖像,在圖3(b)中,右側圖像是左側圖像取右下部分的局部圖像。當圖像中存在干擾信息時,容易影響卷積神經網絡的識別結果,如圖3中的數字“8”和“0”容易被識別為數字“6”。若對歧義性大的圖像中特征較為明顯的局部進行識別,則能有效解決這一問題,如圖3中右側的2張局部圖像,其圖像特征明顯,不存在干擾信息,便于卷積神經提取圖像特征。

圖3 包含干擾信息的數字圖像
基于上述思想,本文設計一種基于局部特征的卷積神經網絡模型(CNN-LF),通過對特征明顯的局部圖像進行識別,屏蔽輸入圖像中的干擾信息。
2.2 CNN-LF模型結構
CNN-LF基于經典卷積神經網絡模型LeNet-5。LeNet網絡模型首次引入部分連接、權值共享以及下采樣方法,被認為是真正意義上的卷積神經網絡,在此基礎上發展的LeNet-5最早被應用銀行支票上的手寫數字識別,識別率達到了99.2%[12-13]。與LeNet-5相比,CNN-LF在激活函數的選取和全連接分類層的構造上進行改進,并增加局部特征提取 (Local Feature Extration,LFE) 層和概率權重綜合 (Probability Importance Synthesis,PIS) 層,CNN-LF的總體結構如圖4所示。
圖4 CNN-LF模型總體結構
CNN-LF由3個部分組成:改進的LeNet-5作為子網絡,LFE層,PIS層,下面分別進行詳細說明。
2.3 改進的LeNet-5模型
CNN-LF的子網絡由經改進后的LeNet-5構成,該網絡包含7層結構,除輸入層和輸出層以外,還包含2層卷積層(C1,C2)、2層下采樣層(S1,S2)和1層全連接層(F1),其網絡結構示意如圖5所示。
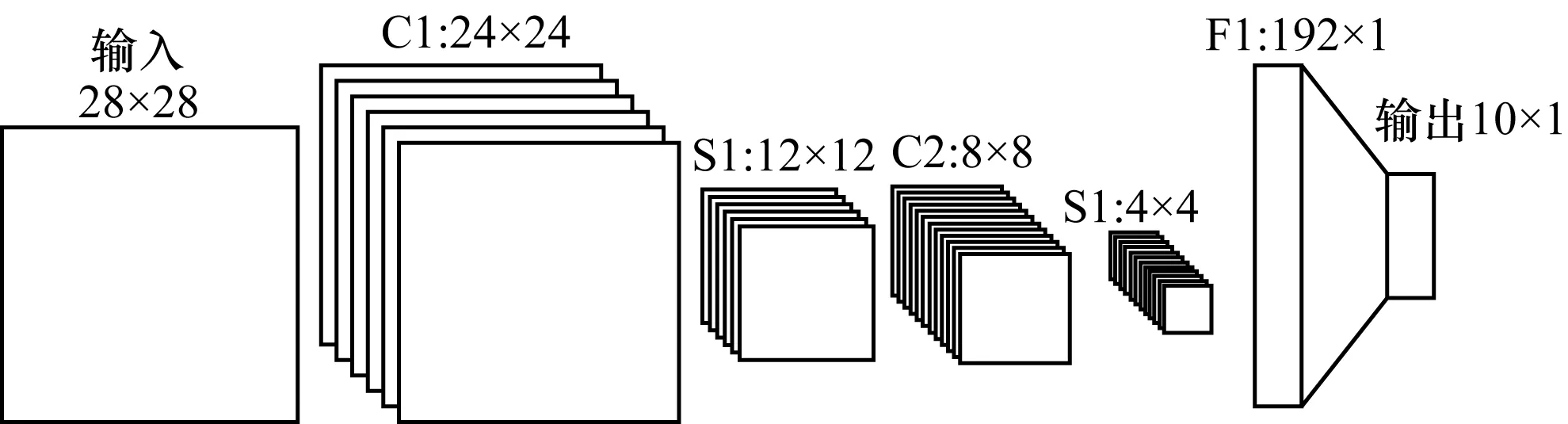
圖5 改進的LeNet-5模型結構
卷積層C1中包含6個大小為5×5的卷積核,得到6幅大小為24×24的輸出特征圖;卷積層C2中包含12個大小為5×5的卷積核,得到12幅大小為8×8的輸出特征圖;下采樣層S1與S2都是對輸入特征圖進行平均值采樣(Mean-Pooling),經采樣后輸出特征圖的分辨率降為輸入特征圖的1/4。
LeNet-5是卷積神經網絡的經典模型,該網絡模型在文獻[2-3]中有詳細的說明,本文對LeNet-5的改進主要包括以下3點:
1)調整網絡結構、網絡層間連接方式。改進后的網絡中C2層的卷積核數量為12,得到12幅輸出特征圖且每一幅輸出特征圖都與S1層的6幅輸出特征圖存在連接,而原LeNet-5中該層次卷積核數量為16,每一幅輸出特征圖只與上一采樣層的部分輸出特征圖存在連接。
2)對網絡高層結構進行簡化。LeNet-5的高層包括2層全連接層,并用徑向基(RBF)函數處理得到網絡輸出。由于全連接層中包含大量權值參數,因此減少全連接層的數量有利于降低計算復雜度。改進后的LeNet-5僅包含一層全連接層F1,F1為S2的12個特征圖展開形成的列向量。輸出層采用Softmax函數,Softmax函數常用于多分類問題中,由于其的歸一化特性,改進后的LeNet-5的輸出可以視為概率向量,該向量中的每一個元素代表對應分類的概率。
3)對激活函數的選擇進行優化。LeNet-5中激活函數采用tanh雙曲正切函數,該函數作為激活函數存在梯度飽和問題,即當輸入很大或很小時,求得的梯度值接近于0,使得網絡收斂緩慢[8-9]。本文借鑒AlexNet的做法,以ReLU函數作為激活函數,該函數具有單側抑制、相對寬闊的激活范圍以及稀疏激活性的特點,與tanh相比效果更優。
2.4 LFE層
LFE層主要用于提取輸入圖像的局部特征,作用于子網絡之前,不包含需要訓練的權值參數。由于輸入圖像的中間部分包含圖像的主要特征,在提取局部特征時,若簡單地對對輸入圖像進行等分,容易破壞圖像特征,因此需要根據圖像大小采取相應的劃分策略,以盡量保留圖像中間部分的特征。此外,還需要用空白信息,將提取到的局部特征圖拓展到與原輸入圖神經網絡對于輸入圖像具有平移不變性,因像相同的分辨率,以保證網絡結構的一致性,由于卷積此對局部圖像進行填充并不會影響網絡識別圖像特征。LFE層對輸入圖像的處理過程如圖6所示。由于實驗中的輸入圖像分辨率為28×28,因此設置提取局部特征的窗口大小為18×18,能夠包含輸入圖像中間部分的主要特征。經過LFE層之后,得到4幅與輸入圖像同分辨率的局部圖像。
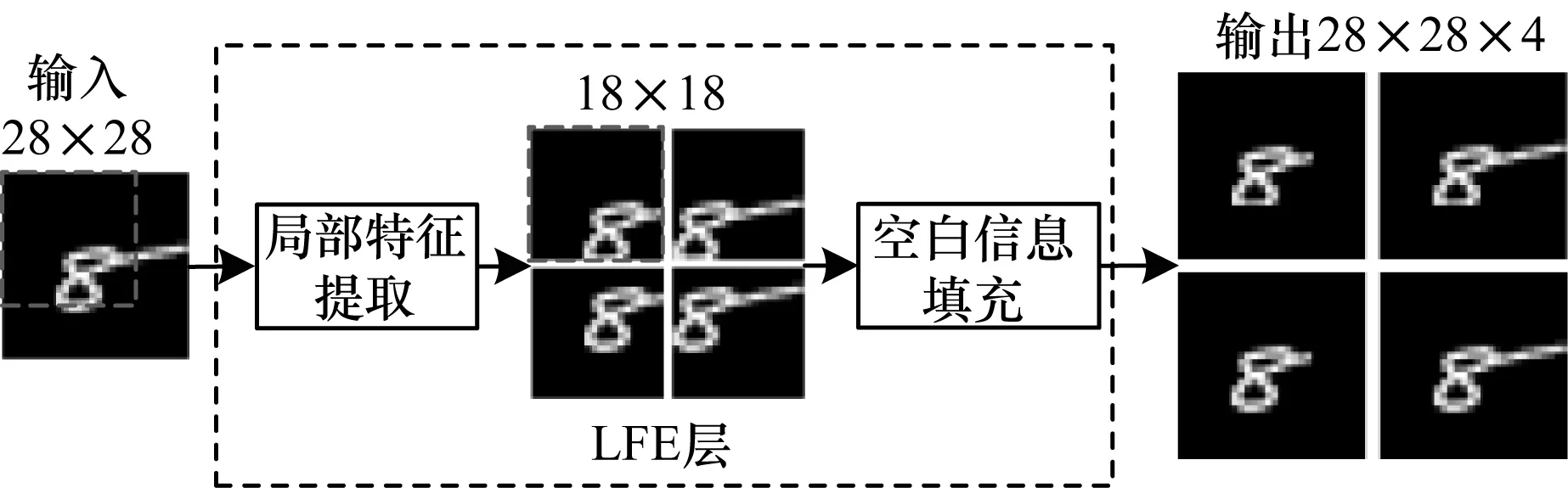
圖6 LFE層數據處理過程
2.5 PIS層
PIS層對子網絡輸出的概率向量進行綜合計算,首先用softplus函數處理輸入的概率向量,再對概率向量進行求和,得到最終的輸出向量,輸出向量中的最大元素對應的序號即為CNN-LF的分類結果。softplus函數的數學表達形式如下:
f(x)=ln(1+ex)
(3)
softplus函數曲線如圖7所示,其中虛線為對照直線。
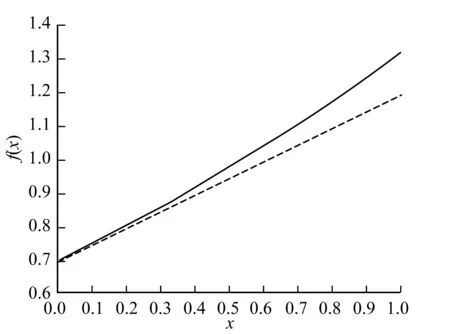
圖7 softplus函數曲線
由圖7可知,當自變量取值為0~1時,softplus函數的斜率隨自變量的增大而增大,因此,softplus函數能夠進一步增大強信號與弱信號之間的差異。輸入的概率向量經softplus函數處理后,向量中較大的元素能夠獲得更大的權重。圖8為PIS層對輸入的概率向量綜合處理得到輸出的過程。PIS層輸入的概率向量和CNN-LF最終的輸出都為列向量(10×1),圖8中僅將分類值為“6”和“8”(向量中第6個和第8個元素)的元素值列出,網絡最終的識別結果為輸出向量中最大元素對應分類值。
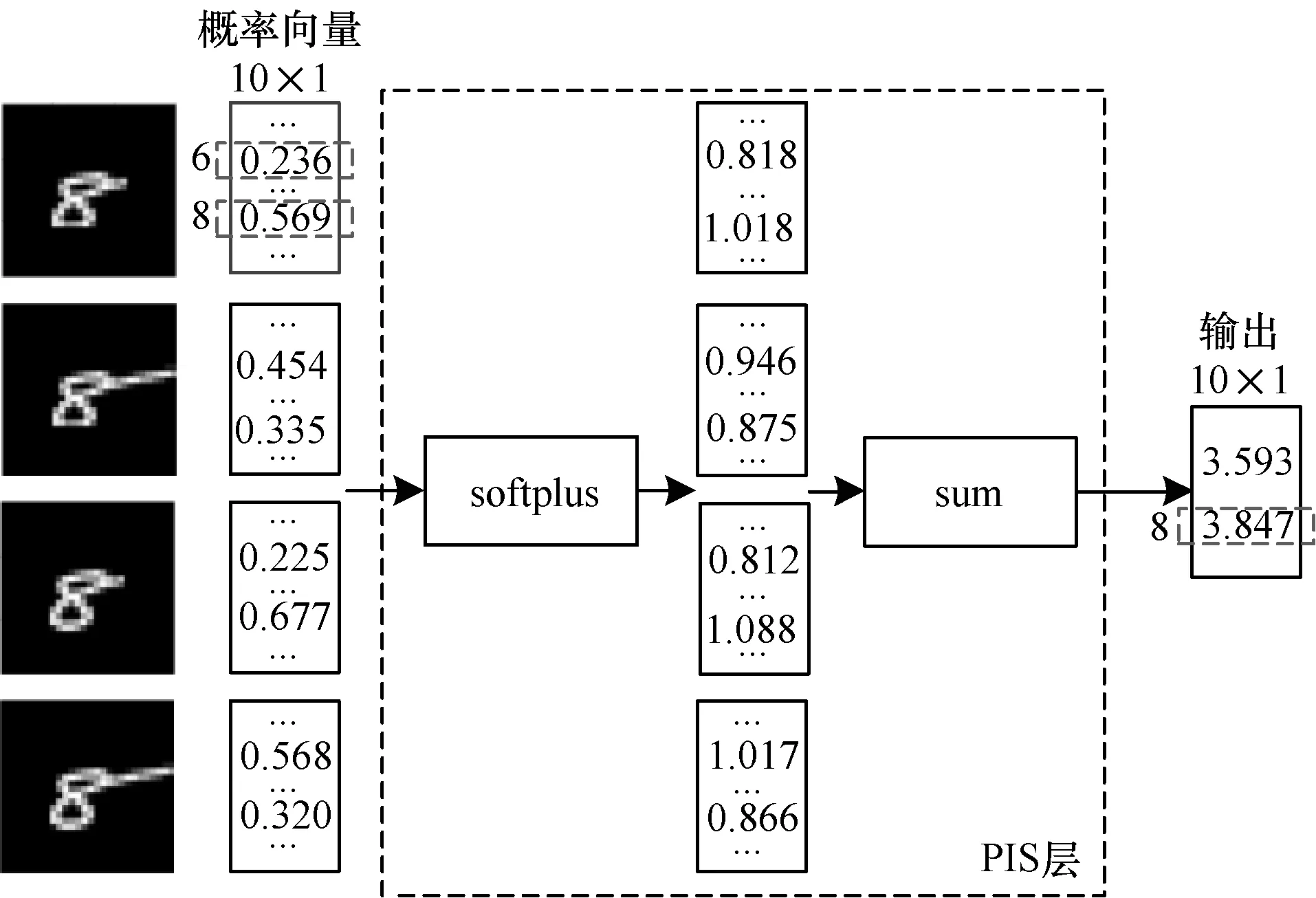
圖8 PIS層數據處理過程
3 實驗與結果分析
為驗證CNN-LF的性能,本文在MNIST手寫數字數據集上進行實驗,分別用CNN-LF和LeNet-5實現了手寫數字識別,針對實驗結果進行對比分析。
3.1 實驗數據
MNIST手寫數字數據集由Google實驗室的Corinna Cortes和紐約大學的Yann LeCun建立,共包含70 000幅樣本圖像,其中60 000幅為訓練集,10 000幅為測試集。MNIST數據集中的每一個手寫數字樣本都是一幅分辨率為28×28的灰度圖像,由于采集樣本的對象不同,對于同一數字,不同樣本之間存在很大差異性。圖9是從MNIST數據集中分別提取數字“0”和數字“1”的16個樣本。

圖9 MNIST數據集中的數字“0”和“1”
3.2 實驗結果
設計實驗將CNN-LF與經典卷積神經網絡LeNet-5進行對比。對比實驗中,除了兩者的網絡結構不同以外,保持其他的網絡參數相一致,依據Xavier初始化方法對兩者的卷積核進行初始化[14-16],訓練過程采取隨機梯度下降方法,每次輸入20個樣本進行訓練(即每識別20個樣本調整一次權值),學習率為0.01,使用帶動量項的BP算法更新權值,動量系數取0.9[17]。圖10為LeNet模型和CNN-LF模型的實驗結果對比。實驗中CNN-LF在訓練階段每迭代一次(處理60 000個樣本)耗時約為2 min,訓練網絡時網絡迭代次數越大,訓練后的網絡識別率就越高。
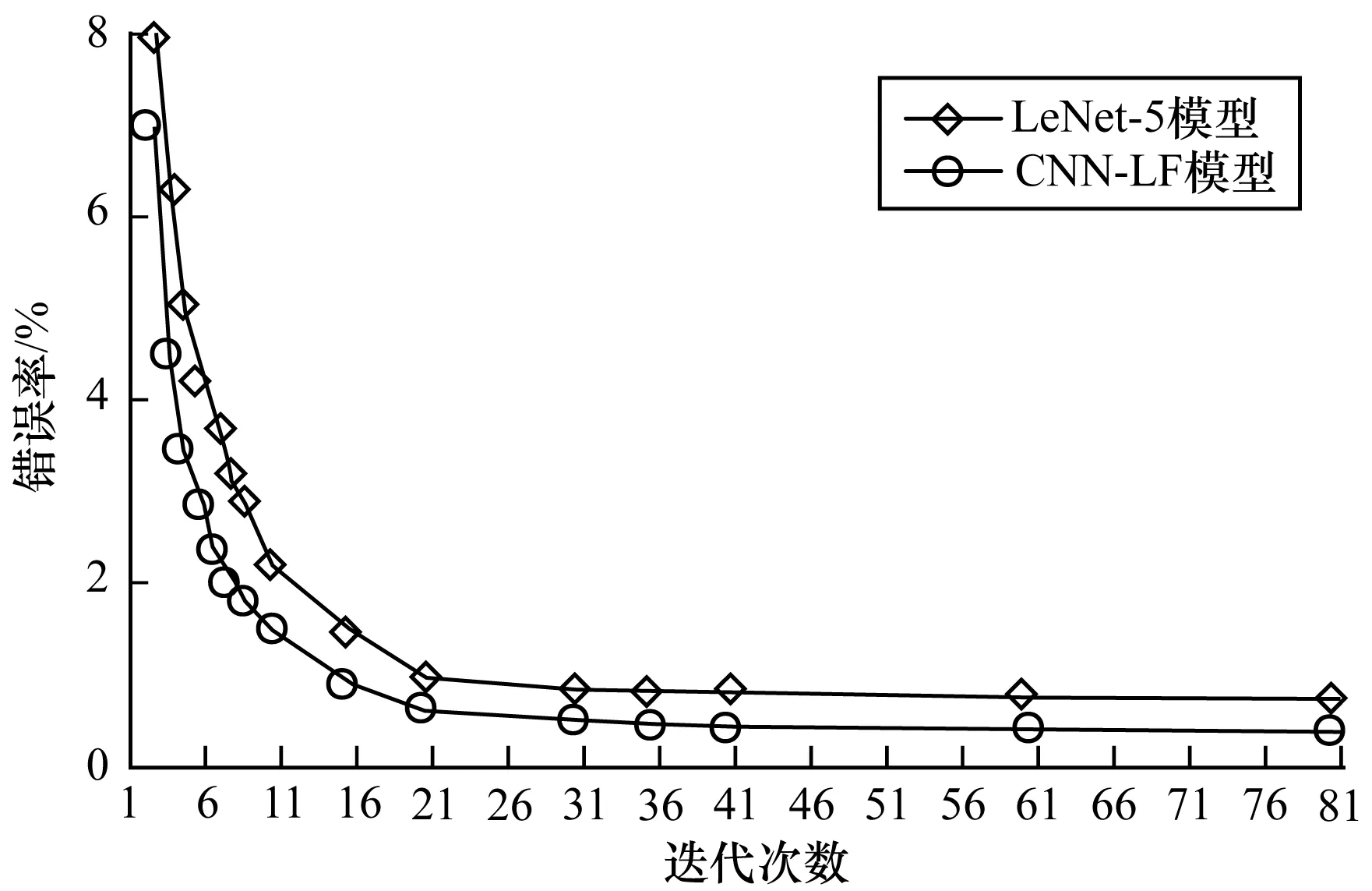
圖10 訓練迭代次數與識別率
由圖10可以看出,與LeNet-5相比,CNN-LF的識別錯誤率更低,尤其是在迭代次數較小的情況下,CNN-LF能夠將識別錯誤率降低1.0%~1.5%。當訓練迭代次數達到40次時,CNN-LF基本達到收斂狀態,此時的錯誤率為0.45%。由于CNN-LF增加了LFE層和PIS層,網絡結構更為復雜,因此在對比實驗中CNN-LF在訓練階段的耗時高于LeNet-5模型。
3.3 采樣分析
為進一步驗證CNN-LF性能,本文根據LeNet-5的測試結果對測試樣本進行重采樣,獲取迭代次數為20 時LeNet-5識別錯誤的數據集(Testing Error set)。Testing Error set中的圖像特征較為模糊,歧義性較大,圖11為Testing Error set中的部分樣本圖像。

圖11 Testing Error set中部分樣本
在Testing Error set上對不同迭代次數下的CNN-LF和LeNet-5進行測試,實驗結果如表1所示。表1中Iterations表示用于測試的CNN-LF在訓練階段的迭代次數,其中結果表明,CNN-LF在識別特征不明顯的圖像時能夠保持較高的識別率,在迭代次數相同的情況下,CNN-LF與傳統卷積神經網絡相比,識別錯誤率更低。
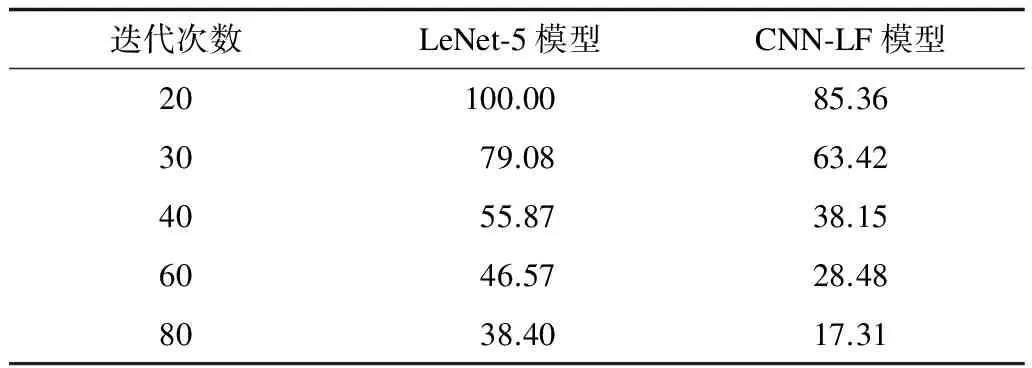
表1 在Testing Error set上的識別錯誤率 %
4 結束語
本文在傳統卷積神經網絡的基礎上,構建一個新的網絡模型CNN-LF。通過增加局部特征提取層和概率權重綜合層對圖像的局部特征進行識別,并根據輸出的概率向量將局部圖像的識別結果以一定的權重進行累加,得到最終的網絡輸出。通過在MNIST數據集上進行對比實驗,并在重采樣得到的Testing Error set上進一步分析,證明該模型比傳統的卷積神經網絡模型識別率更高,尤其對于特征模糊的圖像具有較高的適用性。后續工作是進一步優化CNN-LF模型,并將其應用于其他圖像識別領域。
[1] 鄭 胤,陳權崎,章毓晉.深度學習及其在目標和行為識別中的新進展[J].中國圖象圖形學報,2014,19(2):175-184.
[2] 周志華,陳世福.神經網絡集成[J].計算機學報,2002,25(1):1-8.
[3] RUMELHART D,MCCLELLAND J.Parallel Distributed Processing:Explorations in the Microstructure of Cognition:Foundations [M].Cambridge,USA:MIT Press,1987.
[4] LeCUN Y,BOTTOU L,BENGIO Y.Gradient-based Learning Applied to Document Recognition[J].Proceedings of the IEEE,1998,86 (11):2278-2324.
[5] LECUN Y,HUANG F J.Large-scale Learning with SVM and Convolutional for Generic Object Categorization[C]//Proceedings of IEEE Computer Society Conference on Computer Vision & Pattern Recognition.Washington D.C.,USA:IEEE Press,2006:284-291.
[6] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet Classification with Deep Convolutional Neural Networks[M]//PEREIRA F,BURGES C J C,BOTTOU L,et al.Advances in Neural Information Processing Systems 25.[S.l.]:Neural Information Processing Systems Foundation,Inc.,2012:1097-1105.
[7] 常 亮,鄧小明,周明全,等.圖像理解中的卷積神經網絡[J].自動化學報,2016,42(9):1300-1312.
[8] KALCHBRENNER N,GREFENSTETTE E,BLUNSOM P.A Convolutional Neural Network for Modelling Sentences[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics.[S.l.]:Association for Computational Linguistics,2014:655-665.
[9] JI Shuiwang,XU Wei,YANG Ming,et al.3D Convolutional Neural Networks for Human Action Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231.
[10] YANG Weixin,JIN Lianwen,TAO Dacheng.DropSample :A New Training Method to Enhance Deep Convolutional Neural Networks for Large-scale Unconstrained Handwritten Chinese Character Recognition[J].Pattern Recognition,2010,20(1):17-21.
[11] 張佳康,陳慶奎.基于CUDA技術的卷積神經網絡識別算法[J].計算機工程,2010,36(15):179-181.
[12] LeCUN Y,BENGIO Y,HINTON G.Deep Learning[J].Nature,2015,521(7553):436-444.
[13] GARCIA C,DELAKIS M.Convolutional Face Finder:A Neural Architecture for Fast and Robust Face Detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(11):1408-1423.
[14] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2014:580-587.
[15] KARPATHY A,TODERICI G,SHETTY S,et al.Large-scale Video Classification with Convolutional Neural Net-works[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2014:1725-1732.
[16] DONAHUE J,JIA Yangqing,VINYALS O,et al.DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition[J].Computer Science,2013,50(1):815-830.
[17] ZAMORA-MARTNEZ F,FRINKEN V,ESPAABOQUER A S,et al.Neural Network Language Models for Off-line Handwriting Recognition[J].Pattern Recognition,2014,47(4):1642-1652.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
