基于面向對象與深度學習的典型地物提取
2018-03-06 06:04:27金永濤楊秀峰郭會敏劉世盟
自然資源遙感 2018年1期
金永濤,楊秀峰,高 濤,郭會敏,劉世盟
(1.北華航天工業學院,廊坊 065000; 2.航天恒星科技有限公司,北京 100086;3.河北省航天遙感信息處理與應用協同創新中心,廊坊 065000)
0 引言
遙感圖像解譯有兩大難點,即不同地物難以分割且地物類型難以精準識別。目前,遙感影像的分類方法按其分類基本單元的不同可分為基于像元的分類方法和面向對象的分類方法2大類[1]。基于像元的分類方法以影像單一像元為基本單元,主要利用影像的光譜特征進行分類[2],分類結果容易出現椒鹽現象,而且由于影像存在“同物異譜”或“異物同譜”現象,易造成地物類別的錯分和漏分,導致分類結果精度較低。面向對象的分類方法是利用“同質均一”的多個像元為基礎分類對象,利用影像的光譜和空間紋理特征,突破了基于像元分類方法的限制[3],很大程度上解決了農作物、林地、水體、道路及建筑物等典型地物區分不開的問題。
深度學習是計算機科學機器學習領域中一個新的研究方向。其概念源于人工神經網絡的研究,含多隱層的多層感知器就是一種深度學習結構[4-7]。Lecun 等在 1998 年提出的卷積神經網絡是第一個真正的多層結構學習算法,它利用空間相對關系減少參數數目以提高樣本訓練性能[8-9]。深度學習可通過學習一種深層非線性網絡結構,實現復雜函數的逼近,展現了強大的從少數樣本集中學習數據集本質特征的能力[10-13]。
本文結合面向對象與深度學習的技術特點提出了一種新的典型地物信息提取方法。首先,采用面向對象方法提取典型地物對象特征; 然后,選用卷積神經網絡Caffe框架對分割后的不同尺度對象進行深度學習,獲取不同對象的形狀和紋理特征,用以指導對象分類; 最后,有效解決典型地物信息提取分不準的問題。
1 研究區概況及數據源
本研究選擇廊坊市永清縣龍虎莊鄉為試驗區。該區位于E116°22′~116°36′,N39°11′~39°23′之間,主要土地利用類型為農作物、林地、水體、道路和建筑物等。選取了2016年8月27日2景國產高分二號(GF-2)衛星晴空影像數據,首先,對數據進行了幾何精校正處理,將各波段數據進行影像的自動配準和鑲嵌; 然后,對全色影像和多光譜(紅、綠、藍波段)影像采用ENVI Gram-Schmiddt Spectral Sharpening 方法進行了融合,使多光譜影像具備了豐富的紋理特征,最后通過矢量裁剪出試驗區域,結果如圖1所示。
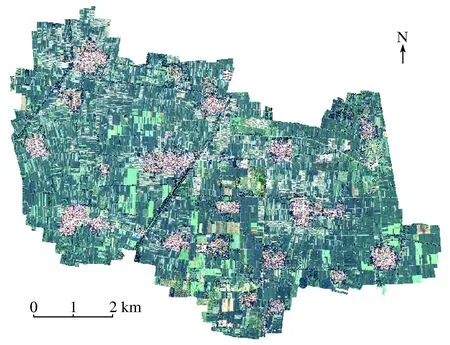
圖1選取的實驗樣本區域GF-2影像
Fig.1GF-2imageoftheselectedsamplearea
2 研究方法
2.1 技術流程
傳統的面向對象方法根據不同類對象在特征上表現出來的差異建立模糊規則。對象特征包括顏色、光譜特征(如亮度值、歸一化水體指數(normalized difference water index,NDWI)和歸一化植被指數(normalized difference vegetation index,NDVI))、形狀紋理(如邊界指數、緊致度、長寬比)等,但對于特征描述得不夠全面、準確。深度學習方法可以通過樣本訓練,掌握不同地物的形狀、紋理、背景等特性,但也需要大量的標簽,人工標識工作量大。表1對2種方法的優缺點進行了對比分析。典型地物目標識別技術流程見圖2。

表1 面向對象與深度學習方法優缺點對比分析Tab.1 Advantages and disadvantages of object-oriented and in-depth learning methods

圖2 典型地物目標識別技術流程圖Fig.2 The flow chart of typical objects recognition technology
在表1基礎上,對GF-2影像全色波段和多光譜波段進行融合處理后,首先采用多尺度分割算法對試驗區影像進行圖像分割; 然后在面向對象分割結果的基礎上,構建耕地、林地、水體、道路、建筑物等典型地物對象特征規則集,對分割對象進行分類提取,得到訓練樣本,形成典型地物學習樣本庫; 之后根據訓練樣本進行深度學習,得到訓練結果,并進一步對訓練樣本進行分類; 最后對提取的典型地物目標結果進行精度評價與分析。典型地物目標識別技術流程圖如圖2所示。
2.2 多尺度面向對象分割算法
多尺度面向對象分割算法將圖像看作是一個由區域和區域之間的拓撲關系組成的一張區域鄰接圖[14],根據指定尺度進行分割,采用從單像元大小的區域開始,相鄰影像區域兩兩合并增長的方法,設定閾值控制合并區域,保證生成高度同質性(或異質性最小)的影像分割區域(影像對象)[15],從而適于最佳分離和表示地物目標。
算法的基本思想是: 從單一像元開始,與鄰近像元分別進行差異性度量計算,降低異質性,完成一輪合并后,以上一輪生成的對象為基本單元,繼續與相鄰對象分別進行計算,直到在規定的尺度上已經不能再進行任何對象的合并為止。這種異質性是由對象之間的光譜和幾何形狀差異決定的。初始時, 每個像素作為一個區域,差異性度量準則(f)的計算公式為
f=w1x+(1-w1)y,
(1)
式中:w1為權值,0≤w1≤1;x為光譜異質性;y為形狀異質性;x與y的計算采用
(2)
y=w2u+(1-w2)v,
(3)
式中:pi為第i影像層的權值;σi為第i影像層光譜值的標準差;u為影像區域整體緊密度;v為影像區域邊界平滑度;w2為權值,0≤w2≤1。u,v的計算式為
(4)
v=E/L,
(5)
式中:E為影像區域實際的邊界長度;N為影像區域的像元總數;L為包含影像區域范圍的矩形邊界總長度。
在影像區域的合并過程中, 從區域鄰接圖中的每個區域入手, 尋找滿足局部最優合并條件的區域對, 將這2個區域合并, 并更新與原來2個區域相連的所有區域的特征值及其與新區域的合并代價。當合并相鄰的2個區域時,合并新生成的更大影像區域對象的異質性f′的計算式為
f′=w1x′+(1-w1)y′,
(6)
式中:x′,y′分別為合并新生成的更大影像區域的光譜異質性和形狀異質性,即
(7)
y′=w2u′+(1-w2)v′,
(8)
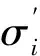
(9)
(10)
式中:E′和L′分別為合并新生成的更大影像區域的實際邊界長度和包含該新生成影像區域范圍的矩形邊界總長度;E1和L1分別為合并前的相鄰影像區域1的實際邊界長度和包含該影像區域范圍的矩形邊界總長度;E2和L2分別為合并前的相鄰影像區域2的實際邊界長度和包含該影像區域范圍的矩形邊界總長度。不同尺度的地類分割的結果如圖3所示。

(a) 實驗區真彩色原始影像 (b) 分割尺度45、顏色0.7、平滑度0.5 (c) 分割尺度65、顏色0.7、平滑度0.5 (d) 分割尺度100、顏色0.7、平滑度0.5
圖3多尺度分割結果示意圖
Fig.3Schematicdiagramofmultiscalesegmentation
2.3 基于多尺度規則集的樣本庫構建
結合試驗區地表下墊面類型,通過對象的特征信息與地物之間的對應關系,建立樣本分類選取的層次結構,即利用多尺度的分層分割,不同的地物采取不同的尺度進行分割; 然后,根據對象的光譜特征、幾何紋理特征以及拓撲結構特征設置分類規則。建筑物、道路、水體和植被(包括農作物、林地)大類在大尺度分割層(分割尺度100、顏色0.7、平滑度0.5)中,分別利用亮度值、NDWI和NDVI作為判斷依據進行初步提取; 再在植被大類的影像對象上選取適合其子類的分割尺度(分割尺度65、顏色0.7、平滑度0.5)來進行分割,考慮耕地的形狀比林地規則,綜合兩者對象的邊界指數、緊致度、長寬比等形狀指數進行區分,具體的對象規則集如表2所示。
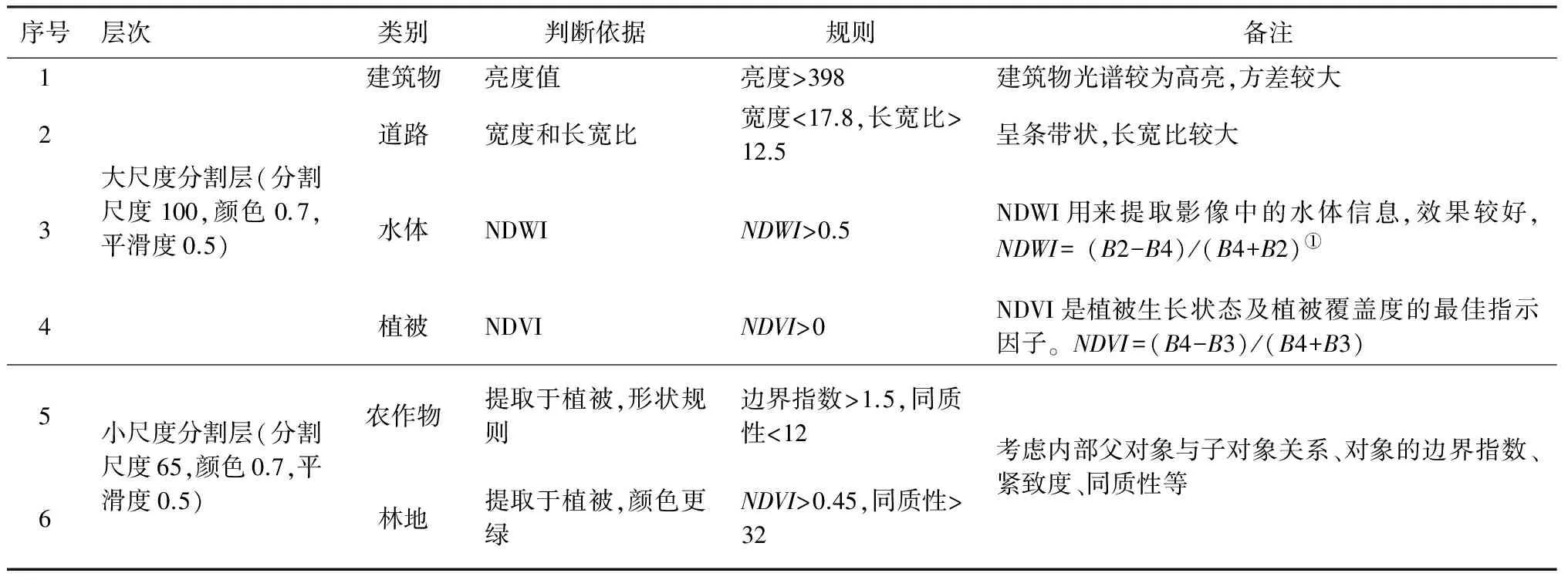
表2 對象規則集Tab.2 The rule set of objects
①式中B2,B3,B4分別為2,3,4波段亮度值。
基于對象判定規則,通過程序自動追蹤各個類別下的樣本邊界,建立了包括耕地、林地、水體、道路及建筑物等主要典型地物信息遙感影像特征集,獲取訓練樣本集。如表3所示。
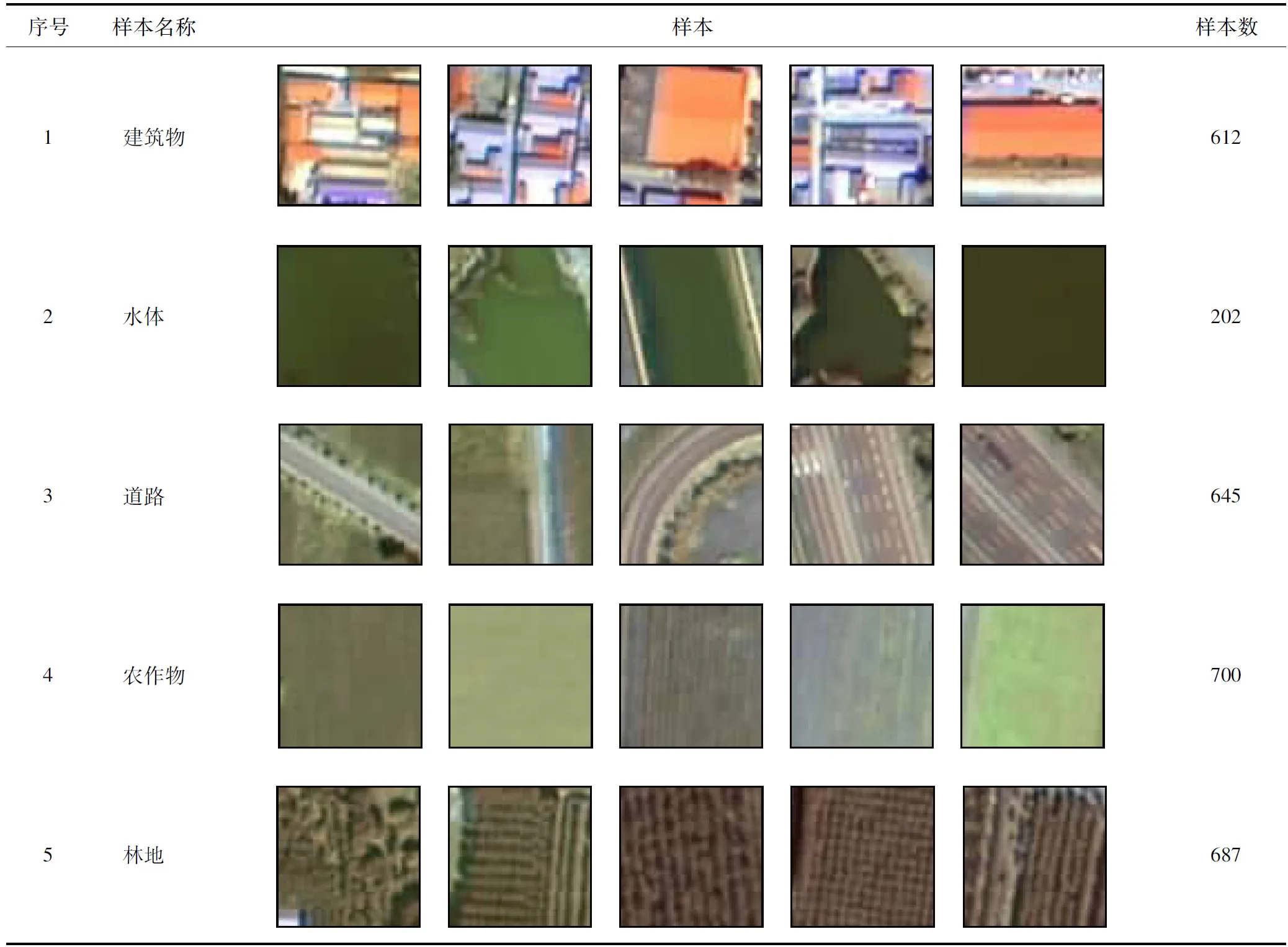
表3 典型地類訓練樣本Tab.3 The training sample of typical objects
2.4 基于深度學習的典型地物自動識別
利用實驗區各個類別的樣本圖片作為訓練數據,將深度學習與面向對象的方法相結合,選用卷積神經網絡模型,對訓練樣本數據進行深度學習,自動獲取樣本特征,利用面向對象分割結果實現典型地物的自動識別分類。其中,卷積神經網絡的結構設計是問題關鍵,本文的深度學習框架采用Caffe框架,用到的卷積神經網絡結構如圖4所示。
2.4.1 卷積神經層
卷積神經層是對圖像的每個像素點進行卷積運算,卷積核作為訓練參數,經過幾次處理之后,能夠提取出圖像的“特征值”。卷積神經層中,卷積核越大,對圖像“抽象”的效果越好,但需要訓練的參數就越多; 卷積核越小,越能夠精細地處理圖像,但要達到同樣的“抽象”效果,需要更多的層數[16]。圖像卷積過程如圖5所示。在經典的神經網絡結構中,采用11×11的卷積核。為達到預期結果,需引入大量參數,在不考慮偏置的情況下,11×11的卷積核參數是3×3卷積核的(11×11+1)/(3×3+1)=12.2倍,且每個輸出點對應11×11次乘法和11×11次加法,計算量大,從而導致算法性能的降低,因此,本文采用3×3 和5×5 較小的卷積核。
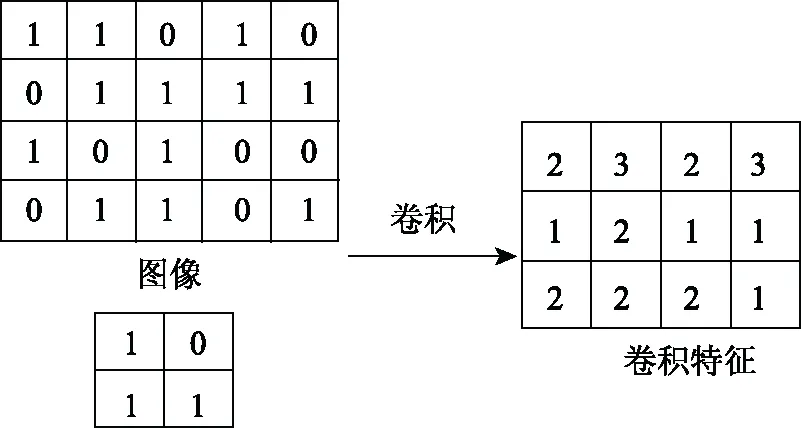
圖5 圖像卷積過程示意圖Fig.5 Imagine convolution process diagram
2.4.2 ReLU層
深度卷積網絡一般都需要大量的數據進行訓練,如果使用傳統的激活函數(如sigmoid 函數和 tanh函數),數據計算量大,幾乎不能夠配合卷積神經層完成訓練,因此,本文采用了線性激活函數(Rectified Linear Units,ReLU),不僅減少了訓練時間,而且提高了算法性能。在ReLU中,對于給定的一個輸入值x,如果x> 0,ReLU層的輸出為x; 如果x< 0,ReLU層的輸出為0。sigmoid 函數、 tanh函數、ReLU函數公式分別為:
sigmoid 函數:f(x) = 1 /[1+exp(-1)]g′(x) =[1-g(x)]g(x)。
(11)
tanh函數 :f(x) = sinh(x)/cosh(x)=[exp(x)- exp(-x)]/[exp(x) + exp(-x)] 。
(12)
Rectified 函數:f(x)=max(0,x)。
(13)
2.4.3 池化層
輸入圖像經過卷積神經層和ReLU 處理之后,圖像中的每個像素點都包含了相鄰區域的信息,造成了信息冗余,繼續計算不僅會降低算法性能,還會破壞算法的平移不變性。為了提升算法的性能和魯棒性,需要對圖像進行二次采樣[17],在深度卷積網絡中,這種操作稱為池化(pooling),即將圖像分成一小塊一小塊的區域,對每個區域計算出一個值,然后將計算出的值依次排列,輸出為新的圖像。如果劃分的區域之間互不重疊,其算法稱為非重疊型池化,否則稱為重疊性池化。對每個區域計算輸出的方法也分為2種: 求平均值(mean pooling)或者取最大值(max pooling)。本文采用可重疊的、取最大值的池化運算,可以在一定程度上降低過度擬合。池化計算過程如圖6所示。
2.4.4 規范化神經層
為了讓圖像更加具有對比性,需要設計規范化神經層。規范化神經層的作用類似于對圖像進行“增加對比度”的操作。本文選用局部響應歸一化(local response normalization,LRN)算法,選擇通道內空間區域歸一化,局部區域在空間上擴展,將每個輸入值都除以
(14)
式中,α為縮放因子,默認值為1; β為指數項,默認值為5;n為局部尺寸大小,默認值為5。如此完成“臨近抑制”操作后,可有效提高主體部分與其他部分的區分度。
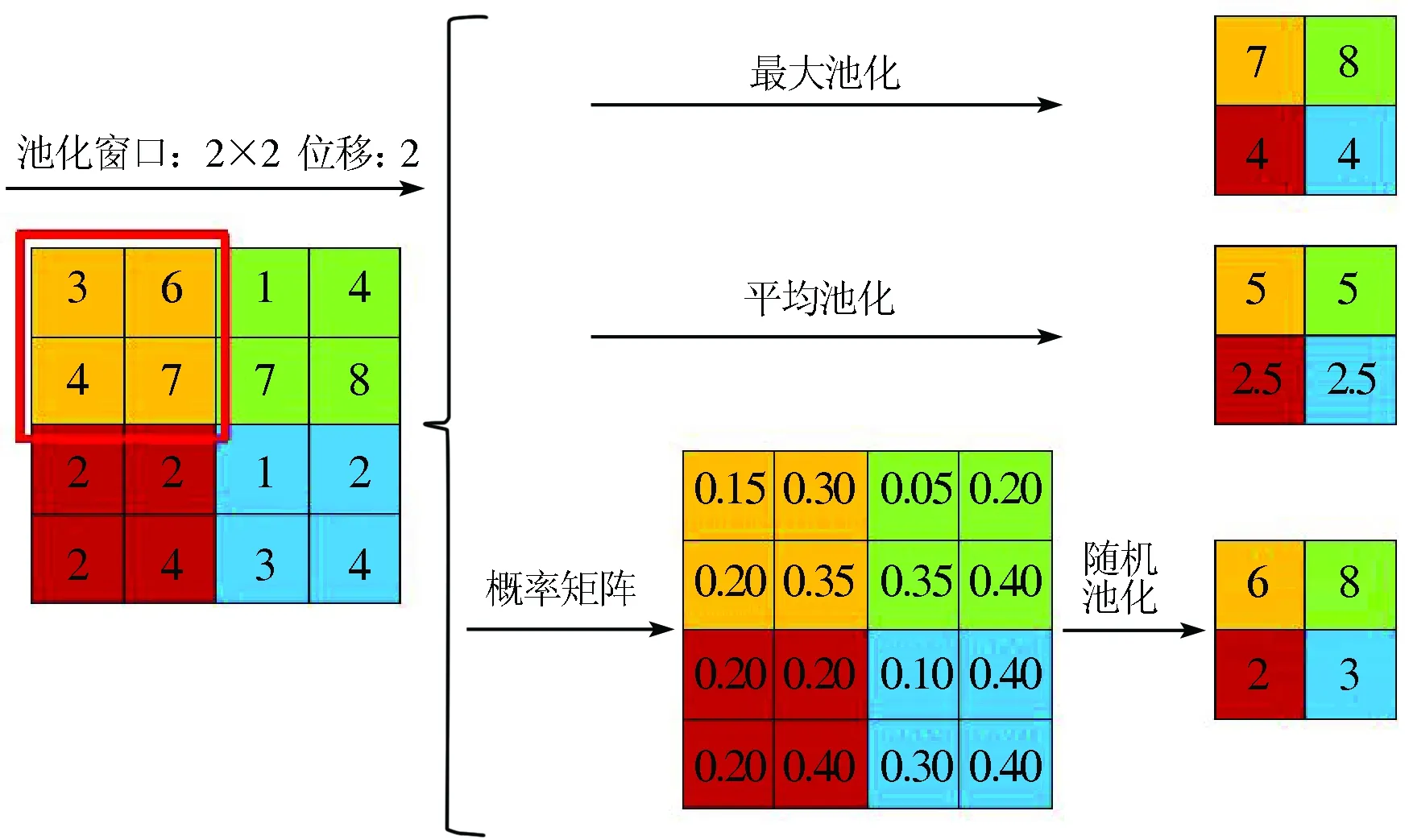
圖6 池化運算Fig.6 Pooling operation
3 結果與分析
根據龍虎莊鄉試驗區下墊面類型特征,將影像分類為建筑物、道路、水體、林地、農作物及其他6種類別。基于面向對象和結合深度學習模型的面向對象分類方法的典型地區提取結果如圖7和8所示。
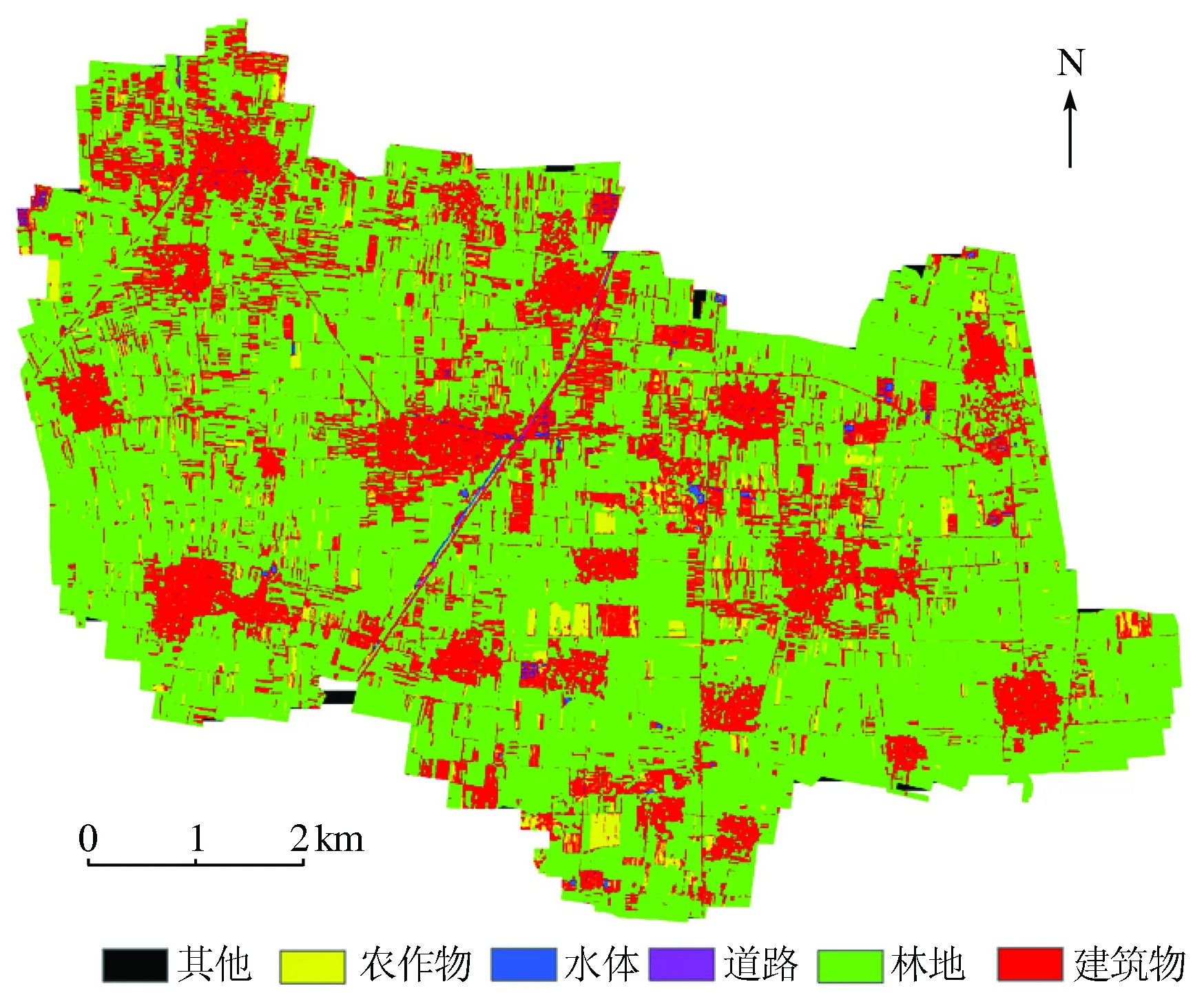
圖7 基于面向對象分類方法的典型龍虎莊鄉地物提取結果圖Fig.7 Typical class selection result of Longhuzhuang township by Object-Oriented method
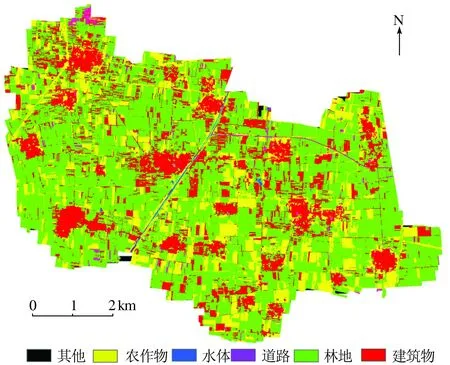
圖8 結合深度學習模型的龍虎莊鄉典型地物提取結果圖Fig.8 Typical class selection result of Longhuzhuang township by deep learning method
本文采用隨機抽樣方法進行精度評價[18],在龍虎莊鄉試驗區GF-2衛星融合影像中隨機選擇了300個樣本點像元,以目視解譯結果為標準進行評價。隨機點分布效果如圖9所示。然后,通過混淆矩陣計算出用戶精度、制圖精度、錯分誤差、漏分誤差、總體精度、Kappa系數等精度指標,對分類結果進行精度評價,計算結果如表4—表7所示。

圖9 龍虎莊鄉試驗區隨機點分布圖Fig.9 Random point distribution of Longhuzhuang township
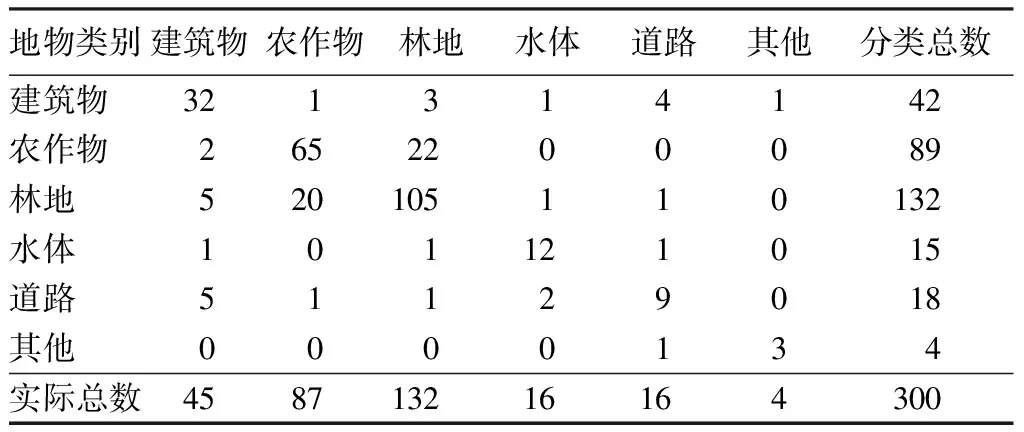
表4 基于面向對象分類方法的典型地物分類混淆矩陣Tab.4 Confusion matrix of typical classification by object-oriented method (個)
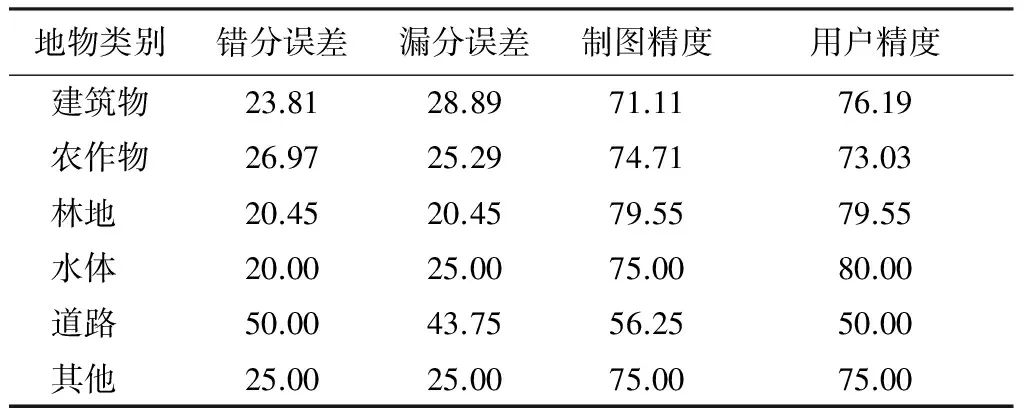
表5 基于面向對象分類方法的地物分類錯分誤分、漏分誤分、制圖精度與用戶精度Tab.5 Commission and omission error,production and user precision by object-oriented method (%)
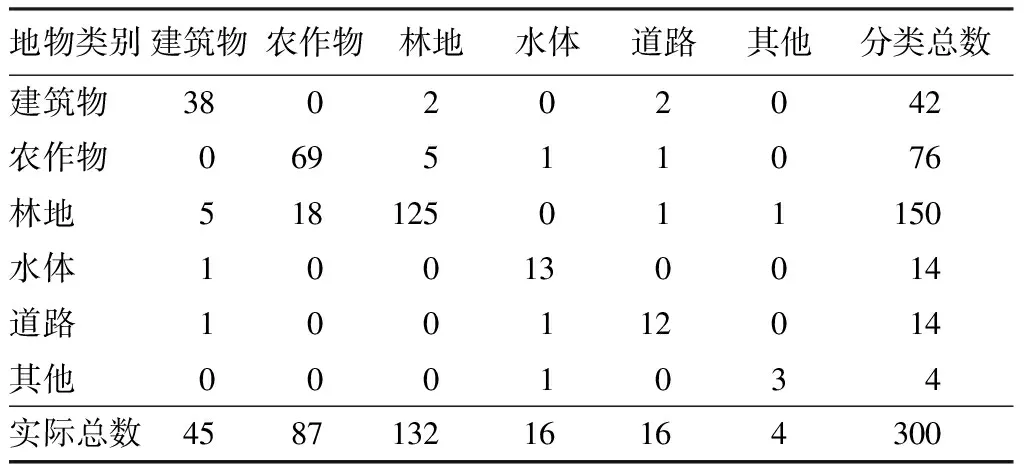
表6 結合深度學習模型分類方法的典型地物分類混淆矩陣Tab.6 Confusion matrix of typical classification by deep learning method (個)
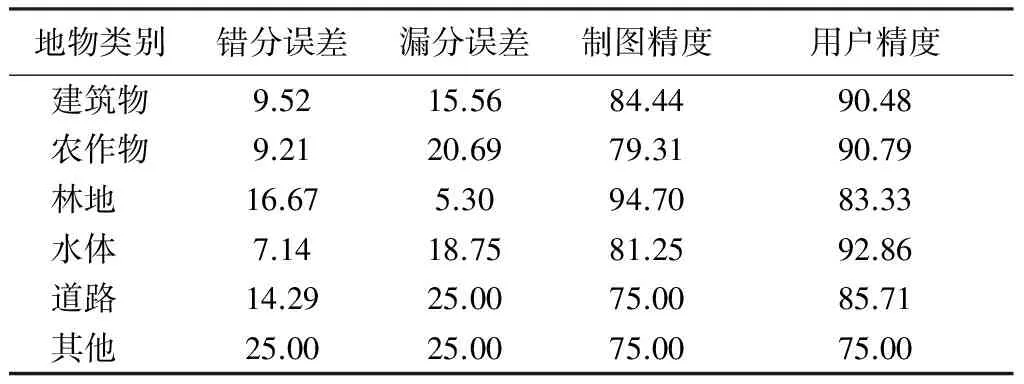
表7 結合深度學習模型分類方法的地物分類錯分誤分、漏分誤分、制圖精度與用戶精度Tab.7 Commission and omission error,production and user precision by deep learning method (%)
根據2種分類結果的混淆矩陣計算得到,基于面向對象分類方法的分類總精度為75.33%,Kappa系數為0.96; 結合深度學習模型面向對象分類方法的分類總精度為84.40%,Kappa系數為0.97,分類結果優于前者,主要是新提出的分類方法考慮利用了對象之間的相鄰關系模型,可以很好地切割地物邊界線,較好地劃分了農作物和林地,建筑物和道路等易混淆地區,優于基于單一對象特征的分類方法。
4 結論
針對農作物、林地、水體、道路、建筑物等典型地物信息提取,提出了一種將面向對象與深度學習相結合的新方法。新方法將圖像多尺度分割基礎上構建通用規則集獲取的典型地物樣本特征為輸入,然后通過深度學習方法進一步進行樣本訓練和特征提取,最后再將學習后的樣本特征運用于分割結果完成遙感影像的信息提取。選取廊坊市永清縣龍虎莊鄉為試驗區進行實驗和精度驗證,精度為84.40%。實驗結果表明,新方法將面向對象與深度學習進行了合理、高效的結合,有效解決了典型地物分不準的問題,分類精度高于面向對象分類方法。但是新方法在通用規則集構建和深度學習結構設計方面尚不完善,有待進一步改進。
[1] 鄭 毅,武法東,劉艷芳.一種面向對象分類的特征分析方法[J].地理與地理信息科學,2010,26(2):19-22.
Zheng Y,Wu F D,Liu Y F.A feature analysis approach for object-oriented classification[J].Geography and Geo-Information Science,2010,26(2):19-22.
[2] 趙英時.遙感應用分析原理與方法[M].北京:科學出版社,2003.
Zhao Y S.Theory and Methods of Remote Sensing Application Analysis[M].Beijing:Science Press,2003.
[3] 黃慧萍.面向對象影像分析中的尺度問題研究[D].北京:中國科學院研究生院遙感應用研究所,2003.
Huang H P.Scale Issues in Object-oriented Image Analysis[D].Beijing:Institute of Remote Sensing Applications Chinese Academy of Sciences,2003.
[5] Deng L.An overview of deep-structured learning for information processing[C]//Proceedings of Asian-Pacific Signal & Information Processing Annual Summit & Conference (APSIPA-ASC).Xi’an:Chinese Information Processing Society of China,2011:301-313.
[6] Arel I,Rose D C,Karnowski T P.Deep machine learning-a new frontier in artificial intelligence research[research frontier][J].IEEE Computational Intelligence Magazine,2010,5(4):13-18.
[7] Do V H,Xiao X,Chng E S.Comparison and combination of multilayer perceptrons and deep belief networks in hybrid automatic speech recognition systems[C]//Proceedings of Asian-Pacific Signal & Information Processing Annual Summit & Conference(APSIPA-ASC).Xi’an:Chinese Information Processing Society of China,2011.
[8] Farabet C,Couprie C,Najman L,et al.Learning hierarchical features for scene labeling[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1915-1929.
[9] Kavukcuoglu K,Sermanet P,Boureau Y L,et al.Learning convolutional feature hierarchies for visual recognition[C]//Proceedings of the 23rd International Conference on Neural Information Processing Systems.Vancouver,British Columbia,Canada:ACM,2010:1090-1098.
[10] Charalampous K,Kostavelis I,Amanatiadis A,et al.Sparse deep-learning algorithm for recognition and categorisation[J].Electronics Letters,2012,48(20):1265-1266.
[11] Olshausen B A,Field D J.Emergence of simple-cell receptive field properties by learning a sparse code for natural images[J].Nature,1996,381(6583):607-609.
[12] Olshausen B A,Field D J.Sparse coding with an overcomplete basis set:A strategy employed by V1?[J].Vision Research,1997,37(23):3311-3325.
[13] Goodfellow I,Courville A,Bengio Y.Large-scale feature learning with spike-and-slab sparse coding[J].arXiv preprint arXiv:1206.6407,2012.
[14] 王衛紅,何 敏.面向對象土地利用信息提取的多尺度分割[J].測繪科學,2011,36(4):160-161.
Wang W H,He M.Multi-scale segmentation in land-use information extraction based on object-oriented method[J].Science of Surveying and Mapping,2011,36(4):160-161.
[15] Woodcock C E,Strahler A H.The factor of scale in remote sensing[J].Remote Sensing of Environment,1987,21(3):311-332.
[16] Alain G,Bengio Y,Rifai S.Regularized auto-encoders estimate local statistics[J].arXiv:1211.4246,2012:1-17.
[17] Rifai S,Bengio Y,Dauphin Y,et al.A generative process for sampling contractive auto-encoders[J]. arXiv:1206.6434,2012:2.
[18] Zhan Q M,Molenaar M,Tempfli K,et al.Quality assessment for geo-spatial objects derived from remotely sensed data[J].International Journal of Remote Sensing,2005,26(14):2953-2974.
[19] 宮 鵬,黎 夏,徐 冰.高分辨率影像解譯理論與應用方法中的一些研究問題[J].遙感學報,2006,10(1):1-5.
Gong P,Li X,Xu B.Interpretation theory and application method development for information extraction from high resolution remotely sensed data[J].Journal of Remote Sensing,2006,10(1):1-5.
[20] 曹 雪,柯長青.基于對象級的高分辨率遙感影像分類研究[J].遙感信息,2006(5):27-30,51.
Cao X,Ke C Q.Classification of high-resolution remote sensing images using object-oriented method[J].Remote Sensing Information,2006(5):27-30,51.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
