基于清晰有理數均值的新匹配聚類算法
2018-03-27 09:14:09尚靖博左萬利
吉林大學學報(理學版) 2018年2期
關鍵詞:方法
尚靖博, 左萬利
(1. 吉林大學 軟件學院, 長春 130012; 2. 吉林大學 計算機科學與技術學院, 長春 130012)
聚類的本質是將本屬于同類而因某種原因分離的事物, 按照某種邏輯和方法重新聚合的過程. 聚類主要分為層次聚類、 劃分式聚類、 網格聚類和密度聚類. 層次聚類以倒樹形結構排列, 通過從根節點層層向下不斷聚合和分裂, 最終完成聚類. 由于倒樹形結構的特性, 所以更適用于小型數據集[1]. 文獻[2]的方法為典型層次聚類方法, 它先基于HTML特征和層次聚類實現Web接口查詢, 再利用Web中的各種關系和相關特性建立倒樹形結構, 最后通過層次聚類的方式完成聚類, 該方法在實驗室的準確率可達90%以上. 劃分式聚類通過預先設置好聚類的中心或數目, 經過一系列的計算最終收斂完成聚類過程. 劃分式聚類在使用頻率上有K均值聚類和模糊聚類等類型[1]. 文獻[3]的方法為典型的劃分式聚類, 它將樣本數據集高維化處理, 并結合K均值聚類的方法劃分出各時段的負荷差異, 實驗結果表明, 該方法可以在一個長周期內穩定運行. 網格聚類和密度聚類都是基于觀察樣本空間中各組成部分的疏密程度完成聚類[1], 因此更適用于圖像與視頻的聚類. 該聚類方法最典型的是文獻[4]中方法, 它利用圖像由像素點組成, 且不同圖像各部分的疏密程度必不同的原理聚類, 實驗結果表明, 該方法對噪聲數據過濾效果較好, 執行效率較高, 能更好地識別出不同類別的簇. 此外, 文獻[5]利用匹配程度的量度決定隸屬, 利用主成分分析決定縱向壓縮, 該方法壓縮率也較高. 本文通過改進文獻[6]的清晰有理數均值方法, 提出一種針對人工標注型數據的聚類算法, 稱為新匹配聚類算法.
1 算法描述
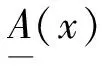
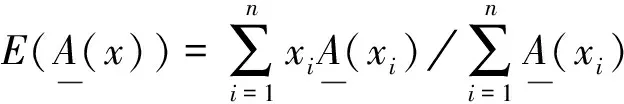
本文對清晰有理數均值方法進行如下改進: 對于論域U=(x1,x2,…,xn)(n∈), 其中x1,x2,…,xn是一組有若干重復項的自然數, 將其刪除重復項后, 論域U變為論域V=(x1,x2,…,xm}(m≤n,m∈), 其中x1,x2,…,xm稱為匹配項. 計算x1,x2,…,xm分別在論域U中的個數, 記作c1,c2,…,cm, 則x1,x2,…,xm在論域U中的概率記作p1,p2,…,pm. 計算有理數的均值計算結果僅取其整數位, 與匹配項匹配后, 標記與匹配項相關的信息, 標記結果即為聚類結果. 算法過程偽代碼描述如下:
U={以矩陣形式表示的數據集}, //導入數據集, 其行數為i, 列數為j;
forkin range (i) { //遍歷矩陣的每一行;
V=U[k].drop_duplicates( ); //刪除重復項得到匹配項;
m=V.count( ); //計算匹配值的總數目;
forsin range(m) {c[s]=U[k].count(′V[s]′)}; //計算每個匹配項的數目;
forqin range (m) {sumc=sumc([q]);} //計算所有匹配項數目總和;
forbin range (m) {p(b)=c[b]/sumc;} //計算每個匹配項的概率;
fortin range (m) {
E1+=V[t]*p[t]; //計算清晰有理數的均值分子;
E2+=p[t]; //計算清晰有理數的均值分母;
E=E1/E2; } //計算清晰有理數的均值;
if (E==V[ ]) { //計算結果依次與匹配項比較, 匹配到哪項就將目標數據名加入對應的集合, 完成聚類.
A.append( );
else:
B.append( ); }}
2 實驗結果與分析
為驗證本文新匹配聚類算法的效果, 將其應用于非欺詐網頁檢測實驗. 互聯網的飛速發展推動了搜索引擎的提升, 但由于利益的驅使, 大批量的欺詐網頁混雜于互聯網中. 欺詐者采取非正常方法, 人工干預搜索引擎的排序策略, 以獲取與其地位不相符的高排名, 擾亂用戶對信息的獲取, 甚至侵害用戶利益. 所以要將非欺詐網頁通過聚類的方式提取出來. 本文采用Webspam-uk2007數據集(http://chato.cl/webspam/datasets/), 其為一組由人工合作完成, 對UK域上的114 529個主機的105 896 555個頁面人工標記(包括S: 欺詐網頁;N: 非欺詐網頁;B: 無法確定;U: 未知)所形成的數據集, 在實驗中選取其中最終可確定是欺詐網頁或非欺詐網頁的6 053個頁面作為數據集.
首先產生原始矩陣U, 對數據集中的兩種標注情況(“欺詐網頁”、 “非欺詐網頁”)分別使用1和2替換, 缺位的用0補全, 保證數據的每一行列數相同. 然后取每一行, 刪除重復元素后確定最終的匹配項x1,x2,…,xm, 計算每個匹配項的數目, 記作c1,c2,…,cm, 計算每個匹配項的概率, 記作p1,p2,…,pm, 利用匹配項和概率計算清晰有理數均值, 記作E. 若E=1, 則標記為欺詐網頁; 若E=2, 則標記為非欺詐網頁, 其他情況則標記為未知.
為評估其性能, 本文采用準確率、 召回率和F值作為評價標準, 公式如下:
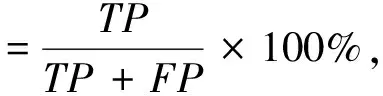
其中:TP表示非欺詐網頁樣本集中被標記正確的數量;TN表示非欺詐網頁樣本集中被標記錯誤的數量;FP表示欺詐網頁樣本集中被標記錯誤的數量;FN表示欺詐網頁樣本集中被標記正確的數量.
新匹配聚類算法在非欺詐網頁檢測問題的實驗結果: 非欺詐網頁樣本集中被標記正確的數量為5 596, 非欺詐網頁樣本集中被標記錯誤的數量為113, 欺詐網頁樣本集中被標記錯誤的數量為0, 欺詐網頁樣本集中被標記正確的數量為334, 準確率為100%, 召回率為98.02%. 由準確率為100%和召回率為98.02%, 可計算出F值為0.99, 實驗結果較好, 因此驗證了本文提出的新匹配聚類算法在反欺詐網頁領域的有效性及在人工標注型數據聚類的合理性. 使用傳統的K最近鄰算法[7]與本文算法在同一名稱但不同類型的數據集上進行對比實驗, 實驗結果如圖1所示. 由圖1可見, 本文算法在反欺詐網頁檢測問題上具有更好的效果.
[1] 孫吉貴, 劉杰, 趙連宇. 聚類算法研究 [J]. 軟件學報, 2008, 19(1): 48-61. (SUN Jigui, LIU Jie, ZHAO Lianyu. Clustering Algorithms Research [J]. Journal of Software, 2008, 19(1): 48-61.)
[2] 魏佳欣, 葉飛躍. 基于HTML特征與層次聚類的Web查詢接口發現 [J]. 計算機工程, 2016, 42(2): 56-61. (WEI Jiaxin, YE Feiyue. Discovery of Web Query Interface Based on HTML Features and Hierarchical Clustering [J]. Computer Engineering, 2016, 42(2): 56-61.)
[3] 李娜, 王磊, 張文月, 等. 基于高維數據優化聚類的長周期峰谷時段劃分模型研究 [J]. 現代電力, 2016, 33(4): 67-71. (LI Na, WANG Lei, ZHANG Wenyue, et al. Reasearch on the Partition Model of Long Period Peak and Valley Time Based on High Dimensional Data Clustering [J]. Modern Electric Power, 2016, 33(4): 67-71.)
[4] 田宇, 羅辛. 一種基于圖像去噪的多密度網格聚類算法 [J]. 智能計算機與應用, 2016, 6(1): 44-47. (TIAN Yu, LUO Xin. A Multi Mesh Density Clustering Algorithm Based on Image Denoising [J]. Intelligent Computer and Applications, 2016, 6(1): 44-47.)
[5] 馮靜, 金遠平, 馮欣. 基于主成分分析及匹配聚類分析的數據表語義壓縮方法 [J]. 東南大學學報(自然科學版), 2006, 36(6): 927-930. (FENG Jing, JIN Yuanping, FENG Xin. Semantic Compression for Data Tables Based on Principal Component and Matching Clustering Analysis [J]. Journal of Southeast University (Natural Science Edition), 2006, 36(6): 927-930.)
[6] 蘇發慧. 清晰理論基礎 [M]. 合肥: 合肥工業大學出版社, 2012: 123-126. (SU Fahui. Clear Theoretical Basis [M]. Hefei: Hefei University of Technology Press, 2012: 123-126.)
[7] Ali H, Behrouz M B. Multi-view Learning for Web Spam Detection [J]. Journal of Emerging Technologies in Web Intelligence, 2013, 5(4): 395-400.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
