改進的TFIDF標簽提取算法
2018-03-28 06:03:14王杰李旭健
軟件工程 2018年2期
王杰 李旭健

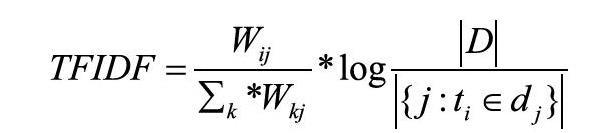
摘 要:TFIDF算法作為一種加權算法,在信息檢索和數據挖掘等自然語言處理領域發揮了巨大的作用。它的計算模型相對簡單,適合大數據并行計算,適用領域廣泛,且擁有很好的解釋性。基于以上這些特點,本文在TFIDF算法基礎之上,利用監督的學習,并通過引入加權因子和詞貢獻度,來修正TFIDF算法結果權值。利用這個算法可以在自然語言處理中有效地提取特征標簽,并且改進后的算法在這一細分領域具有極高準確度。
關鍵詞:自然語言處理;TFIDF;詞加權算法;標簽提取;監督學習
中圖分類號:TP391 文獻標識碼:A
Abstract:As a word weighting algorithm,TFIDF plays an important role in natural language processing such as information retrieval and data mining.TFIDF has relatively simple computational model,suitable for large data parallel computation,applied widely in many fields,and with good explanatory characteristics.Based on the above-mentioned characteristics,this paper proposes to amend the weighted results of TFIDF by means of supervised learning based on TFIDF algorithm as well as by introducing weighting factors and word contribution.This algorithm can effectively extract feature labels in natural language processing,and improve the degree of accuracy in this segmentation field.
Keywords:natural language processing;TFIDF;word weighting algorithm;label extraction;supervised learning
1 引言(Introduction)
互聯網每分鐘都會產生PB級別的信息。如何從這些信息大數據中提取到有用的信息,并結合快速發展并日益成熟的人工智能技術來改善產品是一個迫切需要解決的問題。移動互聯網時代,信息所呈現的特征更加個性化、主體化、終端化。數據中存在無限的價值,誰能從海量的信息數據中撅取價值,誰就可以立足于這個數據時代。
20世紀90年代興起的人工智能科學,成為信息處理相關從業者手中的一把利器。在人工智能技術中,特征提取一直是一個難點,也是一個痛點。有這么一句話在業界廣泛流傳:數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。那么特征工程到底是什么呢?顧名思義,其本質是一項工程活動,目的是最大限度地從原始數據中提取特征,以供算法和模型使用。這足以說明在人工智能尤其是機器學習中,特征提取是多么重要。
為了解決特征標簽提取的問題,本文將介紹在自然語言處理這個具體應用領域中是如何進行特征工程的。為了達到目的,第一步要對語句進行分詞[1]。第二步要對完成分詞的文章中的每個詞進行加權,通過權值的大小來表示詞的重要性[2]。在自然語言處理方向中,最著名的詞加權技術就是TFIDF。TFIDF(詞頻逆文本頻率)是一種對基于統計的加權方法,用以評估一個字詞對于一個文本或者一個語料庫的重要程度。TFIDF已經作為一個成熟的算法廣泛應用于自然語言處理的各個領域,其中最典型的就是搜索引擎。TFIDF雖然得到了廣泛的應用,但是存在一定的不足,尤其是在細分領域,比如關鍵詞提取[3]。
本文提出了一種基于TFIDF的改進加權技術,使TFIDF在自然語言處理的細分領域中的關鍵詞提取應用上達到更好的效果,通過基礎語料庫使計算出的權值結果更能表達詞對文章的代表程度。
2 TFIDF算法與不足(TFIDF algorithm and its defects)
Salton在1973年提出了TFIDF(Term Frequency&Inverse; Documentation Frequency)算法。算法提出后,Salton及其他學者論證了該算法在信息學中的有效性。TFIDF算法主要分為兩個部分,分別是詞頻(TF)和逆文本頻率(IDF)[4]。TF是指文檔中某個詞出現在文章中的頻率值越大,則表明該詞的重要性越大。逆文本頻率(IDF)是指詞出現的篇幅越多,其重要性就越低。逆文本頻率有效地避免了詞的長尾效應[5],使權值更能準確地表達詞的重要程度。TFIDF算法描述為
因為TFDIF算法容易理解并且算法復雜度低,可以使用絕大多數的編程語言計算出準確的TFIDF模型。同時TFIDF具有較好的解釋性和準確性,這些特性使得TFIDF被廣泛地應用,并被應用到自然語言處理和推薦系統領域。但在實踐中人們發現TFIDF存在很多的問題,并不能很好地處理所有的應用領域。尤其是在特殊的細分領域中,TFIDF通常表現得差強人意。本文在自然語言處理領域中的標簽提取應用中使用改進的TFIDF算法該方法有效地提高了文章標簽提取的準確度。
3 文本預處理(Text pre-processing)
對文本進行標簽提取,首先要對文本進行預處理。本文所介紹的文本標簽提取技術需要進行四個階段的預處理。通過對文本進行預處理,可以有效地減少算法的運算量,提高結果的精確度。文本預處理的四個步驟分別為:第一步,準備訓練集;第二步,對文本進行分詞;第三步,將文本使用向量模型表示[6];第四步,對向量模型進行降維[7]。
本文所介紹的算法是給予監督學習的算法,所以需要準備一個足夠豐富的訓練集,并且這個訓練集需要人為地進行標注主題。在自然語言處理中,語料庫是進行監督學習算法的基礎,就像人類學習寫文章一樣,語文老師就像一個龐大且完善的語料庫,這個語料庫會告訴你每篇文章的類型和中心思想,并監督你學習[8]。本文在進行權重計算時假設已經有一個完善的語料庫,有很多不同的主題分類[9],并且涵蓋了所有的分類。每個分類的文章盡可能多地收集到不同風格和不同作者的文章[9]。
在準備好訓練集后,需要對每篇文章進行分詞[2]。漢語是一種非形態語言,缺乏形態標記,語序和虛詞是重要的語法手段。英語語法手段是顯性的,并且英語單詞之間用空格分割,而中文與英文不同,這給中文分詞帶來了巨大的困難。目前中科院和Jieba開源項目提供了針對于中文的分詞算法,即便如此,對于某些句子的分詞還是會扭曲原句的意思[10],使關鍵詞被拆分成單個漢字。這就需要人為地對特殊句子進行人為的分詞。
分詞后,所有的文檔會形成一個字典。這個字典包括了訓練集所有的詞匯,詞匯被標示成,其中表示詞的位置,表示特定的詞語[11]。值得注意的是,詞典幾乎囊括了所有的漢語詞匯和詞組,這無疑加大了特征的緯度,所以在預處理的步驟中需要去掉停用詞。停用詞是指那些出現頻率高但是表示意義小的詞[12],比如文本中的數字和助動詞“的”,它們大量地出現在文本中,但是卻對文章的主題沒有任何影響。除了通過專家進行停用詞的挑選,在這里同樣可以借助于IDF逆文本頻率進行停用詞的判斷。通過定義一個閾值,只要超過了閾值,那么這個詞就可以看作是是一個停用詞,在文本預處理過程中就需要將這些詞從詞組中剔除。
4 詞貢獻度(Word contribution)
每篇文章都有自己的主題和中心思想,主題和中心思想可以近似地代表整篇文章。主題和中心思想同時又可以由體現文章主旨的詞匯表示,可以由公式表示由文章推出標簽特征的過程[11]。
在以上前提下可以提出一個叫主題貢獻度的概念[13]。所謂的詞匯貢獻度就是指根據潛在語義分析的概念,將詞語放入在不同的主題下的貢獻度記做,那么將一篇文檔詞袋中的詞對文章的貢獻度記做
T表示一個詞對文檔的貢獻度,C表示一個詞出現在文中的次數。
5 計算詞權重(Word weighting calculation)
第二節講述了如何分詞并進行數學表達,第三節講述了如何進行語料庫的設計。本文所介紹的加權算法就是基于以上兩節內容的基礎。詞袋模型只是將分詞后的數組按照順序排列,加權完的詞袋模型具有了新的表達形式[(*,*)……(*,*)],元祖的key代表字典索引值,元組的value代表字典的權值。
TFIDF作為一個成熟的算法,有著成熟的應用。本文提出的算法在TFIDF的基礎之上,目標是更加精確地對詞進行加權,表示一個詞在文本中出現的頻率,表示一個逆文檔頻率,在第二節中的停用詞提取就是用的IDF。
表示詞i出現在整個語料庫中的篇數。
使用求得文檔的總貢獻度,在語料庫中取出貢獻度最高主題T,并求出該主題下詞i出現的篇數。P(i)表示的是一個詞所代表主題的頻度,所以P(i)是詞i在整篇文章出現的次數和詞在最高貢獻度主題下的出現次數的比值并求負數。例如在一個語料庫中秦始皇這個詞在歷史中出現了100次,在影視中出現了50次,在其余類中總共出現了50詞,那么秦始皇這個詞P(i)分別為-0.5、
-0.25、>-0.25、……、P(i)雖然能夠很好地表示詞的主題相關性,但是數值存在差別太大的可能性,因為如果在總數很大的情況下,那么很可能出現P(i)的值也過大,計算后的誤差也會變得特別大。
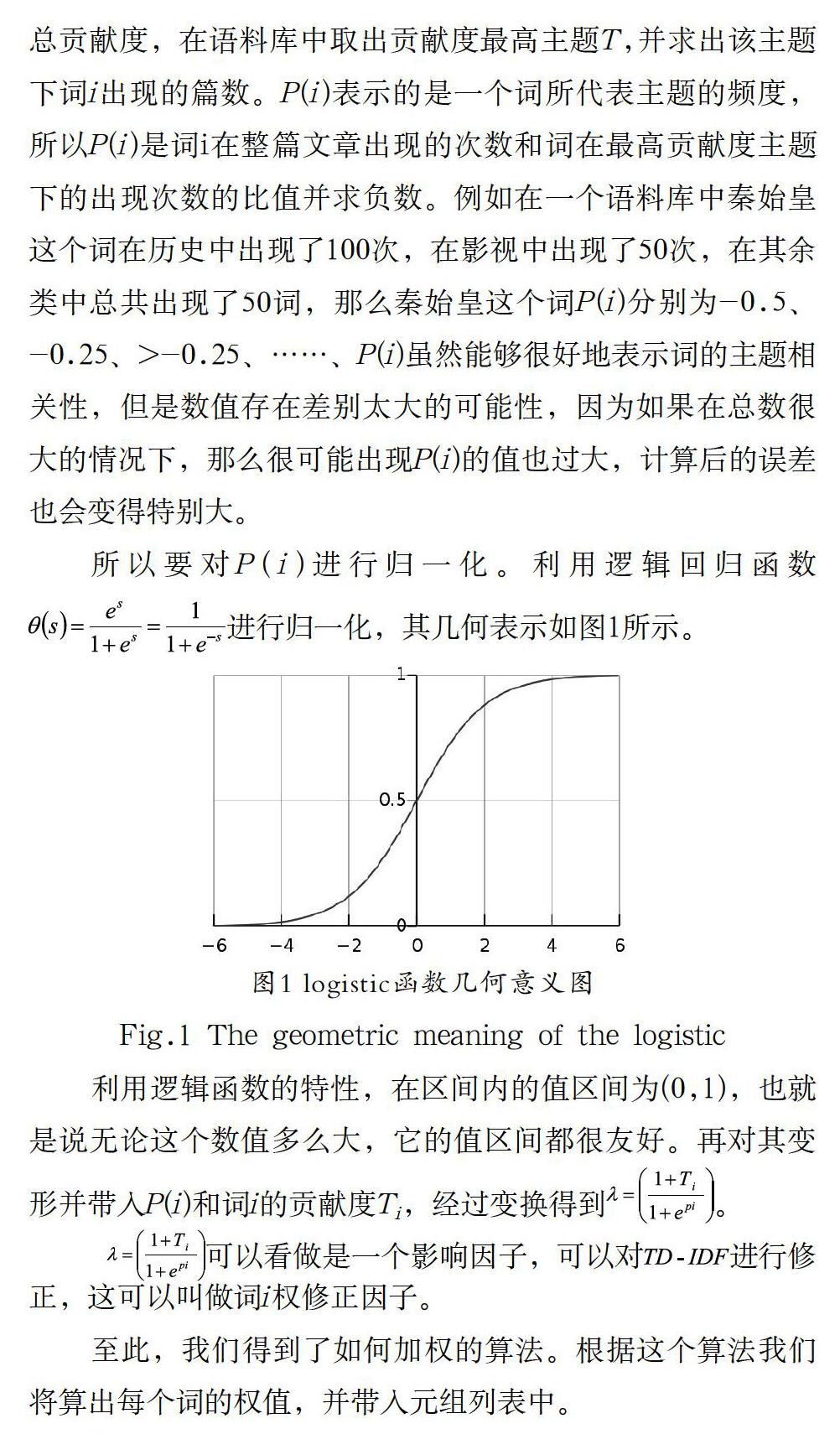
所以要對P(i)進行歸一化。利用邏輯回歸函數進行歸一化,其幾何表示如圖1所示。
利用邏輯函數的特性,在區間內的值區間為(0,1),也就是說無論這個數值多么大,它的值區間都很友好。再對其變形并帶入P(i)和詞i的貢獻度Ti,經過變換得到。
可以看做是一個影響因子,可以對進行修正,這可以叫做詞i權修正因子。
至此,我們得到了如何加權的算法。根據這個算法我們將算出每個詞的權值,并帶入元組列表中。
6 結論(Conclusion)
首先通過介紹TFIDF的算法原理以及對TFIDF算法的加權結果的解釋可知,這是一個偉大的算法,但隨著人工智能和大數據的到來,特征提取變得越發的重要,TFIDF這個在自然語言處理中近乎萬金油的算法模型已經不能很好地滿足需要,所以在TFIDF算法的基礎上進行改進。特征提取是一個復雜的過程,包括多個步驟,每一步都會對結果進行影響,比如分詞。好的分詞方法可以在分詞后不改變原意,讓后面的算法可以有效地提取出文本的特征標簽。詞典和詞向量和停用詞可以減少模型的時間復雜度和空間復雜度,在監督學習算法的前提下,模型需要大量的數據來學習,面對這些海量的數據,如果前面幾步處理的不恰當,很可能導致整個模型的可用性變得很差。
最后針對TFIDF在自然語言處理特征標簽提取應用中的不足,對算法進行改正。首先TFIDF體現出自然語言的語義。語義可以說是文本最重要的體現形式。根據TFIDF算法很可能獲取的權值較高的特征標簽中包括多組反義詞,從而導致無效的結果。因為在論證某一問題時不可能避免地會使用它的對立面語義而TFIDF又是忽略語義的,所以引入了詞貢獻度這個概念可以很好地彌補TFIDF的語義處理上的缺失。最后為了使結果更加平滑,使用邏輯回歸函數作為歸一化函數。
本文對TFIDF的改進主要在兩個方面。一是利用了詞貢獻度,二是根據詞貢獻度來得出修正因子,使結果更加準確。詞貢獻度可以合理針對于主題方面對TFIDF進行了改進,為TFIDF增加影響因子,力圖使所得到的權值更加地準確。
參考文獻(References)
[1] 韓冬煦,常寶寶.中文分詞模型的領域適應性方法[J].計算機學報,2015,38(02):272-281.
[2] 初建崇,劉培玉,王衛玲.Web文檔中詞語權重計算方法的改進[J].計算機工程與應用,2007,17(19):192-194;198.
[3] 劉勘,周麗紅,陳譞.基于關鍵詞的科技文獻聚類研究[J].圖書情報工作,2012,56(04):6-11.
[4] 施聰鶯,徐朝軍,楊曉江.TFIDF算法研究綜述[J].計算機應用,2009,29(S1):167-170;180.
[5] 陳力丹,霍仟.互聯網傳播中的長尾理論與小眾傳播[J].西南民族大學學報(人文社會科學版),2013,34(04):148-152;246.
[6] 江大鵬.基于詞向量的短文本分類方法研究[D].浙江大學, 2015.
[7] 劉欣,佘賢棟,唐永旺,等.基于特征詞向量的短文本聚類算法[J].數據采集與處理,2017,32(05):1052-1060.
[8] 劉建偉,劉媛,羅雄麟.半監督學習方法[J].計算機學報,2015,38(08):1592-1617.
[9] 譚金波,李藝,楊曉江.文本自動分類的測評研究進展[J].現代圖書情報技術,2005(05):46-49;14.
[10] 莫建文,鄭陽,首照宇,等.改進的基于詞典的中文分詞方法[J].計算機工程與設計,2013,34(05):1802-1807.
[11] 黃棟,徐博,許侃,等.基于詞向量和EMD距離的短文本聚類[J/OL].山東大學學報(理學版),2017(07):1-6.
[12] 崔彩霞.停用詞的選取對文本分類效果的影響研究[J].太原師范學院學報(自然科學版),2008,7(04):91-93.
[13] 周水庚,關佶紅,胡運發.隱含語義索引及其在中文文本處理中的應用研究[J].小型微型計算機系統,2001(02):239-243.
作者簡介:
王 杰(1993-),男,碩士生.研究領域:大數據分析,人工智能,領域驅動設計.
李旭健(1971-),男,博士,副教授.研究領域:計算機視覺,VR&AR;,大數據技術.
