基于邏輯回歸算法的乳腺癌診斷數據分類研究
2018-03-28 06:03:14劉蕾
軟件工程 2018年2期
劉蕾
摘 要:乳腺癌是世界范圍內婦女死亡的主要原因之一,準確的診斷是乳腺癌治療中最重要的步驟之一。本文詳細講解了邏輯回歸模型的原理知識,結合Sklearn機器學習庫的LogisticRegression算法對乳腺癌威斯康辛(診斷)數據集進行了數據分類。由于該數據集分類標簽劃分為兩類(惡性、良性),能夠很好地適用于邏輯回歸模型。用基于兩個特征的邏輯回歸模型得到的分類結果表明,當選取平均半徑和最大周長兩個特征時,分類精度最高(95.72%)。與以往的方法相比,該方法在性能上有所提高。
關鍵詞:乳腺癌數據集;邏輯回歸分類算法;預測
中圖分類號:TP393 文獻標識碼:A
Abstract:Breast cancer is one of the major causes of death for women worldwide,and accurate diagnosis is one of the most important steps in the treatment of breast cancer.This paper explains the knowledge of the logistic regression model in detail,and classifies the data set of breast cancer by using the Logistic Regression algorithm of Sklearn machine learning library.The classification label of the data set is divided into 2 classes (malignant and benign),which is appropriate for the logistic regression model.The classification results based on the logistic regression model with two features show that the classification accuracy is the highest (95.72%) when the two characteristics of the mean radius and the largest perimeter are selected.In comparison to previous methods,the performance has been improved to some extent.
Keywords:breast cancer data set;logistic regression classification algorithm;prediction
1 引言(Introduction)
乳腺癌的早期診斷與治療有著重要的作用,已有多種分類方法應用于此種診斷,如C4.5決策樹算法、樸素貝葉斯算法、支持向量機、KNN等。基于乳腺癌數據,運用上述分類方法進行模型構建,分析比較各模型性能,其中支持向量機性能較優。支持向量機可有效調節算法復雜度與泛化能力之間的矛盾,其在小樣本學習領域中有著優于傳統模式識別方法的推廣能力。然而在處理較大規模數據集時,往往需要較長的訓練時間。KNN方法是一種基于實例的學習,可生成任意形狀的決策邊界,無需建立模型,但其分類中開銷很大,需逐個計算相似度,此外,當k取值較小時,對噪聲也很敏感[1]。針對上述不足,國內外研究者們也已做出相應的改進,但尚未有一個能同時實現訓練時間短、預測能力強、規則提取簡易且適應性強的分類方法[2]。本文采用的邏輯回歸分類方法是一種logistic方程歸一化后的線性回歸。這種歸一化的方法往往比較合理,能夠打壓過大和過小的結果(往往是噪音),以保證主流的結果不至于被忽視。同時模型易于解釋,便于提取規則,對噪聲干擾及冗余屬性也有著相當好的魯棒性[3]。
2 乳腺癌威斯康辛數據集(Wisconsin breast cancer data set)
本文所用的癌癥數據來自加州大學歐文分校機器學習數據集倉庫中的威斯康辛州乳腺癌數據集。該數據集共有569個數據點,每個數據點有30個屬性。屬性來源于乳房硬塊的細針穿刺(FNA)數字影像,分別是影像中細胞核的10種特征的最大值、平均值、方差。這10種特征包括半徑、周長、面積、質地、致密性、平滑度、凹度、凹點數、對稱性、分形維度等。具體屬性說明如表1所示。
breast_cancer里有兩個屬性data、target。data是一個矩陣。每一列代表30個屬性中的一個,一共30列;每一行代表某個被測量的乳房硬塊數字影像。一共采樣了569條記錄。
輸出如下所示:
[[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 ..., 2.65400000e-01
4.60100000e-01 1.18900000e-01]
[ 2.05700000e+01 1.77700000e+01 1.32900000e+02 ..., 1.86000000e-01
2.75000000e-01 8.90200000e-02]
[ 1.96900000e+01 2.12500000e+01 1.30000000e+02 ..., 2.43000000e-01
3.61300000e-01 8.75800000e-02]
...,
[ 1.66000000e+01 2.80800000e+01 1.08300000e+02 ..., 1.41800000e-01
2.21800000e-01 7.82000000e-02]
[ 2.06000000e+01 2.93300000e+01 1.40100000e+02 ..., 2.65000000e-01
4.08700000e-01 1.24000000e-01]
[ 7.76000000e+00 2.45400000e+01 4.79200000e+01 ..., 0.00000000e+00
2.87100000e-01 7.03900000e-02]]
target是一個數組,存儲了data中每條記錄屬于哪一類腫瘤,所以數組的長度是569。因為數組元素的值共有2類,所以不同值只有2個,0代表惡性,1代表良性。
輸出分類標簽的結果如下:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 1 0 1 1 1 1 1 0 0 1 0 0 1 1 1 1 0 1 0 0 1 1 1 1 0 1 0 0
……
1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0 0 0 0 1]
3 散點圖繪制(Drawing scatter plot)
散點圖是數據點在直角坐標系平面上的分布圖,適用于表示因變量隨自變量而變化的大致趨勢,據此可以選擇合適的函數對數據點進行擬合。
載入乳腺癌數據集,然后區分其中的惡性樣本數據和良性樣本數據,分別存入數據集Benign和Malignent,獲得良性樣本357個,惡性樣本212個。
從良性樣本和惡性樣本中分別提取出兩列數據,即平均半徑和平均紋理,獲取的值賦值給XB、YB、XM、YM變量。最后調用scatter()函數繪制散點圖。關鍵代碼如下:
plt.scatter(XM[:50], YM[:50], color='red', marker='o', label='malignent')繪制前50個惡性樣本,以紅色圓點標記。
plt.scatter(XB[:50], YB[:50], color='blue', marker='x', label='benign')繪制前50個良性樣本,以藍色叉號標記。
繪制的散點圖如圖1所示。
由該散點圖可以得出結論:惡性腫瘤的判別與腫瘤的半徑大小及紋理程度都有直接關聯。該圖為此論斷提供了可靠的數據依據。
4 邏輯回歸分析(Logistic regression analysis)
下面采用邏輯回歸對其進行分類預測。
獲取樣本的兩列數據,對應為平均半徑和平均紋理,每個點的坐標就是(x,y)。先取二維數組的第一列(平均半徑)的最小值、最大值和步長(設置為0.02)生成數組,再取二維數組的第二列(平均紋理)的最小值、最大值和步長生成數組,最后生成兩個網格矩陣xx和yy,如下所示。
[[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]
[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]
[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]
...,
[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]
[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]
[ 6.481 6.501 6.521 ..., 28.561 28.581 28.601]]
[[ 9.21 9.21 9.21 ..., 9.21 9.21 9.21]
[ 9.23 9.23 9.23 ..., 9.23 9.23 9.23]
[ 9.25 9.25 9.25 ..., 9.25 9.25 9.25]
...,
[ 39.73 39.73 39.73 ..., 39.73 39.73 39.73]
[ 39.75 39.75 39.75 ..., 39.75 39.75 39.75]
[ 39.77 39.77 39.77 ..., 39.77 39.77 39.77]]
將xx和yy的兩個矩陣降維成一維數組。由于兩個矩陣大小相等,因此兩個一維數組大小也相等。把第一列(平均半徑)數據按步長取等分,作為行,并復制多行得到xx網格矩陣;再把第二列(平均紋理)數據按步長取等分,作為列,并復制多列得到yy網格矩陣;最后將xx和yy矩陣都變成兩個一維數組,再組合成一個二維數組進行預測。
對于病人的特征,使用如下公式計算得到危險分數[4]。
計算得到的分數越高,風險越大;分數越低,風險越小。s的取值范圍是(-∞,+∞),但是我們想要的是一個[0,1]之間的值。因此需要一個轉換函數來把這個分數轉換成[0,1]之間的值。這個函數稱為Logistic函數,Logistic函數是一個S形的函數,形狀如圖2所示。
這個函數也稱為sigmoid函數。這個函數能夠把s映射到[0,1]之間,我們把這個函數稱為θ(s)。Logistic函數的形式為[5]:
使用Python語言機器學習庫SKLearn提供的函數LogisticRegression進行運算,獲得的預測結果如下。
[1 1 1 ..., 0 0 0]
Size:1692603
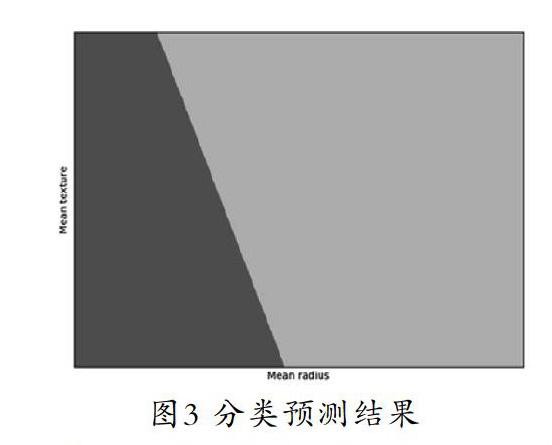
將xx、yy兩個網格矩陣和對應的預測結果繪制在圖上,可以發現輸出為兩個顏色區塊,分別表示分類的兩類區域。輸出的區域如圖3所示。
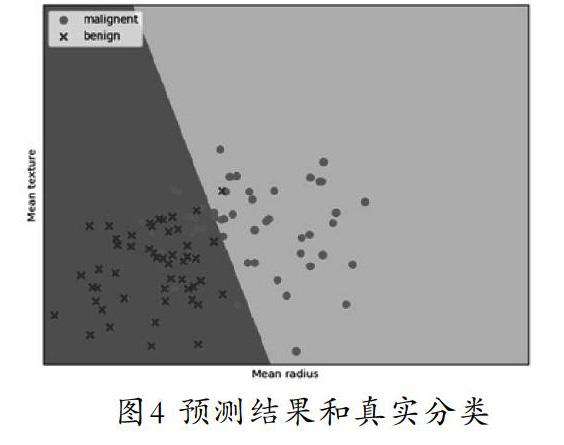
從惡性樣本、良性樣本分別獲取前50個樣本數據,調用scatter()繪制散點圖。第一個參數為第一列數據(平均半徑),第二個參數為第二列數據(平均紋理),最后標記為malignent或benign。輸出的區域如圖4所示。
圖4經過邏輯回歸后劃分為兩個區域。右側淺藍色部分,對應Malignent惡性;左側棕紅色部分,對應Benign良性。散點圖為各數據點真實的分類,紅色的圓點對應Malignent惡性,藍色星形對應Benign良性。劃分的兩個區域為數據點預測的類型,預測的分類結果與訓練數據的真實結果基本一致,可見模型能夠很好地擬合決策面。
5 結論(Conclusion)
實驗中,當選擇平均半徑和平均紋理兩個特性進行分類,使用全部訓練樣本后,分類精度最高可達到90.48%;而選擇平均半徑和最大周長兩個特性時,分類精度達到95.72%,因此,選擇更優的特征組合將提高分類精度。實驗結果表明,邏輯回歸分類模型實現了快速、簡便、高效的乳腺癌診斷,可以幫助診斷乳腺癌。本實驗采用的威斯康星乳腺癌診斷測試(WDBC)數據集來自于加利福尼亞大學Irvine機器學習庫。訓練階段從32個原始特征中提取腫瘤特征。結果不僅說明了該方法對乳腺癌診斷的能力,而且顯示了在訓練階段的時間節省。通過更好地提取不同類型腫瘤的特征屬性,能夠有效提高該方法的分類準確率,醫生也可以從抽象的腫瘤特征中獲益。
參考文獻(References)
[1] L Miclet,S Bayoudh,A Delhay.Analogical Dissimilarity:Definition,Algorithms and Two Experiments in Machine Learning[J].Journal of Artificial Intelligence Research,2014,32(3):793-824.
[2] CW Han.Breast Cancer Diagnosis using Logic-based Fuzzy Neural Networks[J].Digital Contents & Applications,2016:69-72.
[3] Emina , Abdulhamit Subasi.Breast Cancer Diagnosis using GA Feature Selection and Rotation Forest[J].Neural Computing & Applications,2017,28(4):753-763.
[4] 毛林,陸全華,程濤.基于高維數據的集成邏輯回歸分類算法的研究與應用[J].科技通報,2013(12):64-66.
[5] 謝忠紅,張穎,張琳.基于邏輯回歸算法的微博水軍識別[J].微型機與應用,2017(16):67-69.
作者簡介:
劉 蕾(1978-),女,碩士,副教授.研究領域:數據挖掘,大數據.
