推薦算法:信息推送的王者品性與進階重點
2018-04-12 05:58:04喻國明
山東社會科學 2018年3期
喻國明
(北京師范大學 新聞傳播學院,北京 100875)
算法型推薦日漸成為內容分發領域的主流,把握其實踐范式,探究其內在機制與局限,找到它未來健康可持續發展路徑是當下學術研究領域的當務之急。
人類的信息推薦模式迄今為止大體上出現了三個主要的發展類型:1.倚重人工編輯的媒體型推薦;2.依托社交鏈傳播的關系型推薦;3.基于智能算法對于信息和人匹配的算法型推薦。這三種類型作為信息推薦的主流模式依次出現,各有其特色與擅長,也有其問題與局限。譬如,媒體型倚重人工進行信息的專業化處理和加工,這種推薦模式可以解決社會的共性需要,把那些對于全局、對于所有人具有普遍意義的信息篩選出來,并以點對面的方式傳播出去。它的價值在于解決了“頭部信息”的社會化推薦。但是它無暇顧及人的分眾化、個性化及偶然性、體驗性及高場景度的信息需求。尤其是在網絡崛起之后,在信源變得豐富而多元,渠道及內容借助人們的關系網絡幾乎無所不在、無所不至和無所不有之后,這種媒體型推薦模式在人們實際的信息獲知當中所占有的比重越來越低,許多重要信息的傳遞由于無法有效地“嵌入”日益成為主流的“社會關系渠道”而被迫中斷,被稱為“死在社會傳播的最后一公里”。
于是便出現了依托社交鏈傳播的關系型推薦模式:你的朋友、你關注的人幫你推薦、過濾信息,他們的評論、轉發形成了一種信息傳播與篩選機制。社交推薦模式最大的價值是在人類的傳播史上第一次激活了大眾傳播時代那些被忽略的極大量的“長尾信息”,依照人們社會關系之所及而采集與篩選信息,形成了對于信息服務的“利基市場”,實現了信息推薦的“千人千面”——不同的人通過不同的“朋友圈”有了個性化的信息來源及其結構。2010年Facebook主頁訪問量超過Google,可以看作是社交驅動的“關系型推薦”在全球成為主流的“拐點”,所謂“無社交不傳播”即是對關系型推薦的一種不無夸張的描述。但是這種社交驅動下的“關系型信息推薦”的問題在于,它無法解決用戶社交關系爆炸情況之下的內容生產源的爆炸所帶來的“信息超載”以及基于社交關系的推薦質量不斷降低的問題。譬如,經驗表明,在微信朋友圈中養生、微商、曬娃曬吃類的無效信息越來越多,成為一種信息污染和“公害”;而在微博上則是“大V”和營銷類賬號占據了主體流量——有研究表明,在微博平臺上,90%以上的內容是由3%左右的“大V”生產和推薦的。再加上這些年服務于利益主體的“水軍”大規模地崛起,他們為了某些特定的政治或市場營銷目標而恣意地“灌水”,嚴重污染了社交傳播的網絡空間。概言之,這種由“大V”“水軍” 把控的傳播,使得社交渠道的信息傳播越來越遠離人們真實的社會實踐的需要而顯得良莠不齊,甚至烏煙瘴氣,使人不堪其擾。
在此背景下,算法型信息推薦模式便應運而生,并漸成潮流:現在人們隨便打開一個網站或資訊app,都會有“個性推薦”或“猜你喜歡”之類的欄目,系統會根據你的瀏覽、轉發、評論及閱讀停留的時長等記錄和個性愛好,自動為你推薦內容。第三方監測機構易觀發布了一個具有標志意義的數據:早在2016年,在資訊信息推薦市場上,算法推送的內容已經超過50%。*易觀:《2016中國第三方支付市場專題研究報告-Useit知識庫》,www.useit.com.cn/thread-13552-1-1.html。它意味著,我們現在接觸到的信息,主要是由“智能算法”為我們搜索和推送的。“算法型”信息推薦之所以“流行”,有分析者認為是因為算法對流量的分配獨立于社交關系,不被“大號”壟斷;算法能夠處理的信息量幾乎沒有上限,能夠更好地激活、適配 “汝之毒藥,我之甘飴”的長尾信息;算法能夠對用戶的社交推薦機制進行二次過濾,優化推薦結果。總的說,算法型實現了對于海量信息價值的重新評估和有效適配。“汝之毒藥,我之甘飴”意味著你覺得不感興趣甚至是垃圾的信息,對于我可能極有價值。于是,信息價值不再有統一的標準,不再有絕對的高低之分。對剛生下寶寶的媽媽來說,PM值絕對比英國脫歐更重要。對旅游者來說,當地的天氣信息絕對比當地的房價更重要。在算法的驅動下,每個人都有了自己的頭條,這一點得以實現。整個信息世界大一統的秩序被打破。
但是,也正因為如此,算法型推薦模式站在了風口浪尖上。人民日報曾連續三天撰文從內容生產、信息推薦和社會創新等角度對于某算法型信息推薦平臺進行了全方位立體式的批判。公允地說,這些批判在現實狀況下不無道理。比如,在現在的算法還不足夠“聰明”的情況下,用機器智能去完全替代人的“把關”,這樣的資訊“守門人”是否可以完全信賴?再比如,算法性信息推薦更多地建立在對于人們的直接興趣和“無意注意”的信息需求的挖掘上,它的直接后果是對于人們必需的那些非直接興趣和需要“有意注意”所關注的信息的忽略所導致的“信息繭房”問題,等等。更為重要的是,不管是算法對于傳媒業的重塑,還是算法對于各類信息的跨界整合,這無一不使人思考:技術不僅能夠賦能與賦權,而且它自身就構成為一種權力的行使和對于傳統權力模式的替代。在始自上世紀90年代初的中國媒介市場化的進程中,“編輯終審權”是作為一條紅線不容市場侵犯的,而今卻在算法分發的大趨勢中毀于無形。那么,真的是“得算法者得天下”嗎?算法本身又代表了什么?這些已經成為未來社會和傳媒發展中亟待研究和認識的重大課題。
一、推薦算法的技術機制與邏輯自洽
推薦算法的產生所引發的是一場內容分發領域的革命,認識和把握它的實踐范式,探究其內在的機制與局限,找到它未來健康可持續發展路徑是當下學術研究領域的當務之急。
(一)算法:定義與作為“行動者”的演進
在數學和計算機科學中,算法是指如何解決一類問題的明確規則。算法的概念已經存在了幾個世紀。隨著計算機的發展和人類社會的數據化,大數據運用、個性化、自動化成為社會發展的主要趨勢,算法也因此得到廣泛應用和發展。算法重要性的凸顯離不開兩個關鍵要素:數據和算力。互聯網的發展尤其是移動互聯網的爆發,積累了大量的數據,尤其是人們的行為數據。物聯網的發展也擴展了數據的數量和類型。龐大的數據量和計算的復雜度決定了對算力資源的需求。計算芯片的快速迭代和云計算的發展起到了非常關鍵的作用。在信息社會,算法在政治、經濟和文化領域發揮著重要作用,日益影響我們的日常生活。
算法在媒體領域同樣扮演著非常重要的角色。在媒介使用方面,人們查找和獲取的信息都經過算法的篩選。這其中最具代表性的是主打“算法分發”的今日頭條。算法分發是指在沒有人工編輯干預的情況下,通過算法抓取內容,并且依據用戶的行為數據,為用戶建模,再將用戶可能喜歡或需要的內容推送給他。算法還介入新聞生產領域,機器人寫作的生產方式日益被互聯網公司和新聞機構采用。騰訊的“Dream Writer”、今日頭條的“張小明”、新華社的“快筆小新”等受到業界和學界廣泛關注。
從行動者網絡理論(Actor Network Theory)的觀點來看,算法作為一種技術,和人一樣都是“行動者(actor)”,他們共同構成了相互依存的網絡世界。*姜紅、魯曼:《重塑 “媒介”:行動者網絡中的新聞 “算法”》,《新聞記者》2017年第4期。算法處于動態變化之中,需要不斷調整和完善以適應用戶的需求,Google的搜索算法每年調整500-600次。人對算法提供的內容作出反饋,產生新的行為數據,繼而影響之后算法的決策。因此,算法呈現的媒介內容是人和算法不斷互動,彼此調整的結果。從這個意義層面上,可以認為算法和人共同建構了媒介現實。在信息爆炸的時代,算法分擔了人們對外界信息進行認知和決策的壓力,也成為了李普曼所說的“擬態環境”的建構者。
(二)推薦算法的類型和運作機制
推薦算法在人們日常的媒介使用中有著廣泛的應用。從電子商務、社交網站、視頻網站到新聞資訊,都使用了不同形式的推薦算法。個性化推薦本質就是信息篩選,可以說是解決“信息過載”有效方法。“算法分發”這個概念,其實體現了互聯網時代從“人找信息”到“信息找人”的轉變。
1.推薦算法的主要類型
目前主流的推薦算法有:基于內容的推薦算法、協同過濾推薦算法和混合的推薦算法等。其中協同過濾是應用最廣的一種。顧名思義,協同推薦就是大家一起產生的推薦。其中又包括基于用戶的協同過濾和基于內容的協同過濾。基于用戶的協同過濾是指在用戶行為中尋找特定的模式,建立相似用戶之間的連接。比如要向A用戶推薦一本書,就找一個和他相似的B用戶,然后將B用戶喜歡的書推薦給A用戶。基于內容的協同過濾是向用戶推薦與他過去喜歡的物品相似的物品。因此,協同過濾是基于用戶歷史行為數據進行推薦。基于內容的推薦算法則僅取決于物品或用戶的描述,不包括以往的行為數據。混合的推薦算法則結合了以上兩種方式,來借助兩種方法的優勢。

表1 常用的推薦算法及其優缺點
注:所謂“冷啟動”在這里是指某款app或某項服務的使用者是一位缺乏相關數據的“新用戶”,難以判斷他的屬性、狀態和需求,因此滿足其需要的相應推送就難以啟動。
2.推薦算法的運作機制
推薦算法需要獲取用戶數據,以及預測給定的用戶組對哪些內容感興趣。用戶的數據涵蓋多個方面:用戶的人口統計學數據(如年齡、職業等)、用戶的環境特征(如時間、地理位置、網絡情況、天氣情況等)以及用戶的行為數據。行為數據一般包括兩種,即顯性行為和隱性行為。顯性行為明確表達了用戶的偏好,例如轉發、保存、評論等;隱性行為不能直接明確用戶的喜惡,但數據量更大,例如點擊和頁面停留時間等。在用戶剛開始進入時,數據積累較少,這時候就需要依靠對內容的分析來將與用戶感興趣的內容相似的內容推薦給用戶。在一定程度上,推薦算法是在挖掘和建立人與人之間、信息與信息之間以及人與信息之間的關聯,將來還要進一步拓展到人與物、物與信息之間的關聯。
二、推薦算法對用戶信息需求的滿足機制
(一)信息需求模型
信息需求,顧名思義,就是對信息的需求,其需求主體是用戶。在信息科學中,信息需求通常被解釋為:1.用戶的使用頻率,偏好信息檢索滿意度實證研究,是作為需求評價來研究*Kunz, W., Rittel, H. W., & Schwuchow, W.Methods of Analysis and Evaluation of Information Needs:a Critical Review,Verlag Dokumentation,1977.; 2.用戶的一個需求輸入到信息系統中使其啟動或工作,系統輸出一個基于事實的反應*Mai, J. E. Looking for Information: A Survey of Research on Information Seeking, Needs, and Behavior,Emerald Group Publishing,2016.。但是對信息流產品來說,信息需求是偏向人類而不是偏向技術的,“是指人們在從事各種社會活動的過程中,為解決不同的問題所產生的對信息的需求”*鐘守真:《信息資源管理概論》,南開大學出版社2000年版,第134頁。。
美國信息技術專家科亨 (Kochen) 把用戶的信息需求狀態劃分為客觀狀態、認識狀態和表達狀態。*徐嬌揚:《論用戶信息需求的表達》,《圖書館論壇》2009年第1期。他認為,信息需求的客觀狀態由用戶所進行的職業或活動,以及其所處的社會環境和知識結構等客觀因素決定,不以用戶的主觀意志為轉移;而信息需求的認識狀態則指用戶能夠清楚認識到自己已有的對客觀信息的需求,雖然由于主客觀原因,存在著用戶可能只能認識一部分或者全都無法認識,甚至于錯誤認知的情況;信息需求的表達狀態是指用戶通過信息活動,如信息瀏覽、信息傳播、信息訂閱等,特別是與信息服務系統的交往和互動,明確、清晰地表達出自己的需求。

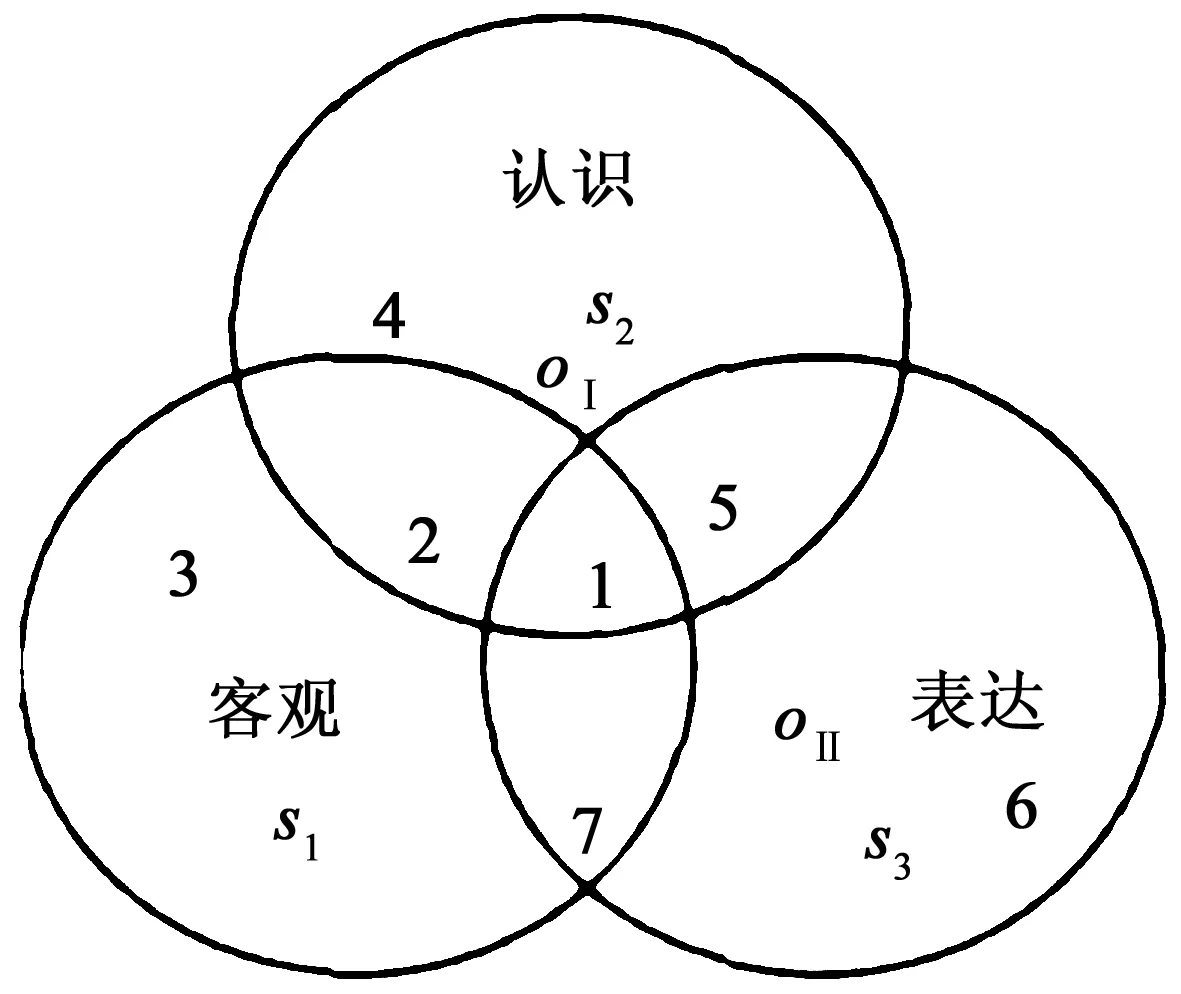
圖1 用戶信息需求的狀態描述
(二)用戶需求的滿足機制
信息流產品中,不論是有著何種需求的用戶,他們對于信息服務或者說推薦算法的基本要求都是相似的,他們始終渴望著這些產品可以及時反饋自己的需求,并且能夠充分、全面地滿足它,甚至在某些情況下可以為自己開發出潛在的或者全新的需求,真正實現他們對于信息流產品的個性化、精準性、及時性和充分性的終極需要。事實上,對于推薦算法來說,要實現這些目標,就是推動信息需求模型中的客觀狀態(S1)和認識狀態(S2)向表達狀態(S3)移動,其核心任務就是完成精細的用戶畫像,其中包括用戶基本的社會人口統計學信息、社交信息、行為信息以及其生活工作的環境信息等多個維度,具體來說推薦算法對用戶信息的滿足體現在以下幾個方面:
1.利用集體的結構性智慧
集體的結構性智慧是Web2.0的核心價值觀,其中最具代表性的案例就是維基百科。其含義通常是指:為了創造新的想法,將一群人的行為、偏好或思想按照某種規則組合在一起。在互聯網時代之前,人們為了從彼此沒有關系的一大群人之中搜集和分析數據,經常采用調查問卷或者普查的方法。而到了Web2.0時代,依托于互聯網,可以更大范圍地從人群的行為數據中搜集信息,發現人群的集中趨勢(共性)及其變化。
推薦算法中常用的協同過濾就是利用集體的結構性智慧的典型方法。這種方法認為,海量的人群中,一些群體是相似的,用戶可能會喜歡和他相似的人喜歡的信息,也可能會討厭和他相似的人所討厭的信息。這種方式類似于營銷中的市場細分。人群具有很多特征,如年齡、地域、職業、興趣等,根據人群不同維度,可以將人群細分到一個合理的層次。這個層次的人群既不要太多,也不要太少,因為太多了沒有個性化,太少了又沒有統計意義。舉例來說,如果A喜歡科技類、軍事類資訊,B喜歡科技類、軍事類、生活類資訊,統計發現A和B相似度高,那么算法就會認為A在很大程度上也會喜歡生活類資訊,就可以把生活類資訊推薦給A。這種方法具有推薦新信息的能力,往往會給用戶帶來“意外之喜”,這樣未被認識和表達的需求就能夠在集體的結構性智慧中得到滿足。
2.挖掘用戶的社會屬性
信息流產品經常面臨冷啟動的問題,即在用戶剛開始使用產品時,行為數據積累較少,向用戶推薦信息的難度較大。社會化推薦方法應運而生。這種方法主要依據用戶之間的社會關系構建社會化網絡,將新用戶和網絡中原有用戶關聯起來,依據原有用戶的興趣模型對新用戶推薦信息。一般認為,個體的興趣和偏好往往受到社會關系中其他成員的影響,社會成員之間也會進行互相推薦。因此,一個人感興趣的信息,往往他身邊的朋友也會感興趣。以今日頭條為例,用戶最開始注冊賬號時,今日頭條會建議用戶用微博帳號注冊登錄,這樣就可以得到用戶的微博信息,包括用戶資料、關注關系、發布的微博等等,這些數據都可以成為算法對用戶進行信息推薦的依據。
研究顯示,與家庭成員相比, 朋友會對人的行為和發展產生更深遠的影響,朋友間的信任關系對提高推薦系統的性能有非常重要的作用。*Sinha, R. R., & Swearingen, K.“Comparing Recommendations Made by Online Systems and Friends”,in DELOS Workshop:Personalisation and Recommender Systems in Digital Libraries,Vol. 106(2001,June).因此,將社交關系融入推薦系統之中可以為用戶提供更精確的信息,使信息推薦更符合人類生活的社會化特征,以此主要來解決模型中被認識卻未被表達的信息需求。
3.挖掘信息間的關聯
目前,推薦算法是解決信息超載問題最有效的工具之一。*Li, L., Zheng, L., Yang, F., & Li, T.“Modeling and Broadening Temporal User Interest in Personalized News Recommendation”,in Expert Systems with Applications,41(7),2014,pp.3168-3177.推薦算法作為一種有效的信息過濾技術,除了通過獲取用戶的興趣偏好信息從而有針對地向用戶推薦可能感興趣的內容外,還有效建立了信息與信息之間的二元關聯規則。關聯即指兩個不相交的非空集合中,如果X→Y,就說X→Y是一條關聯規則,可以分為時間關聯和空間關聯兩種。這種關聯主要是通過收集用戶在一次記錄中,如一次搜索行為、一條內容信息等,兩類項目同時出現的次數、頻率甚至是周期,來挖掘產品與產品之間的相似度與關聯度,從而做出推薦。通過這種方式,推薦算法可以對用戶認識有誤、表達亦有誤的需求加以修正,進一步挖掘用戶的潛在需求,提高了用戶對于信息產品的認知,可以幫助其做出更好的信息選擇。例如“搜索了防脫發產品的20-30歲年齡段用戶可能會需要咖啡”就是一條關聯規則,基于這條規則,將兩種產品進行關聯式推薦可能會更加符合用戶的購買需求。
通過挖掘信息間的關聯規則,推薦算法也可以計算并根據產品間的相似度和用戶對該產品的已有評分,來預測用戶對未被評分的新產品的喜好程度并做出推薦,這對沒有任何行為的新用戶以及沒有形成聚類的新產品來說,可以有效解決冷啟動問題。
4.追蹤和預測用戶行為
如今,基于算法的精準化推送已經成為信息流產品分發的重要形式,“基于個人喜好的推送”應運而生。在新媒體技術的條件下,各種互聯網平臺都設置和增加了推送功能。經常網上購物的人已經習慣了收到系統為他們做出的個性化推薦,視頻網站會推薦你可能會喜歡看的視頻,而音樂軟件會通過我們的聽歌風格來預測我們想要聽什么歌曲從而生成專屬的音樂流。所有這些推薦都來自于推薦算法進行計算分析的結果。
推薦算法實現了從“人找信息”到“信息找人”的轉變。它立足于用戶個體的特殊性,通過用戶的信息行為偏好、搜索歷史、社交網絡賬號、 IP 地址等興趣圖譜和信息消費習慣,形成了用戶專屬的信息模型,并通過深度數據挖掘,智能計算用戶興趣意圖并預測行為,為其推薦個性化關聯產品。它根據對用戶行為的追蹤和預測,以同類信息聚合發送的方式自動為其生成符合需求的信息,可以在海量的數據中幫助用戶快速找到其可能需要的內容并進行精準推薦,有利于節省用戶時間,很大程度上減少了信息過載帶來的困擾。這種追蹤和預測也能夠幫助用戶喚醒他們表達出來但是沒有意識到的需求。
三、推薦算法的進一步發展:技術迭代的重點與走向
在如何更好滿足用戶信息需求上,推薦算法的最終目的是增強面向個體的推薦效果,讓“信息找人”更加精準,使用戶的客觀信息需求被盡可能完整認知并正確表達出來,實現用戶需求的客觀狀態、認識狀態和表達狀態的親密耦合。但就推薦算法的發展狀況來看,仍面臨著很多的挑戰,例如相關數據的稀缺、分割和冷啟動問題成為制約推薦算法精準到達的技術及社會性的障礙,推薦算法在信息推送時面臨著多樣性和精確性的兩難挑戰,其對于用戶信息認知框架的閉環影響和其本身的權力如何與社會傳統權力之間的妥協問題等等。
在信息超載問題日益嚴重的今天,運用智能技術幫助用戶識別、理解信息正日漸成為一種不可阻擋的趨勢,但現階段的推薦算法還遠遠未精準到可以完全滿足用戶認知和行為需求的程度。作為一個發展前景廣闊的研究領域,推薦算法的未來發展必須依靠自身技術、市場模式、信息生產監管制度三者共同進步,才能重新展現面向個體的多樣性和精確性,更好地把握用戶的信息需求,實現精準推薦。對于算法的生產者和內容的提供者來說,可以通過產品創新、內容優化、在技術層面提供隱私服務等“自我組織”的方式適應市場,同時在道德層面上為用戶提供更大的透明度、更多的自主性,加大對用戶隱私的保護。但是由于市場機制可能會帶來“透明度困境”,因此政府的干預和調節也必不可少。但對于現階段推薦算法來說,最重要的是自身技術的進化,體現在以下幾個方面:
(一)構建基于多層聚類和多維數據交叉分析的個性化推薦算法
聚類是將具有相似屬性的數據聚集,使具備一定相似性的數據實例組織成一些相似組,推薦算法只有在這些相似度高的用戶分組基礎之上才能完成高效的物品推薦。*Gong, S. “A Collaborative Filtering Recommendation Algorithm Based on User Clustering and Item Clustering”,in JSW, 5(7), 2010,pp.745-752.聚類方式出于不同的維度可做不同劃分,一般將其分為用戶聚類和項目聚類等。用戶聚類是指根據用戶對某產品的中心相似度找到目標用戶的相似用戶群,對其行為做出預測與分析;而項目聚類則指尋求對幾個產品(項目)進行聚類,尋求產品對象之間的相似性,對產品間的相似性及可能的用戶群進行分析。*翁小蘭、莊永龍:《基于項目特征聚類的協同過濾推薦算法》,《計算機應用與軟件》2009年第7期。
傳統推薦算法在實際應用場景中往往存在單層次信息獲取導致數據稀疏和精確性缺失的問題。因此,在對用戶行為進行分析時,將用戶聚類和項目聚類相結合進行立體式的過濾推薦,可以有效提高推薦的準確性。這是因為用戶與用戶以及用戶和行為選擇之間并不是孤立存在的,而是處于一種“交疊關系”*劉建國、周濤、汪秉宏:《個性化推薦系統的研究進展》,《自然科學進展》2009年第1期。,身處某一場景的每個用戶都同時存在于其他數個場景之中,其身份和行為也在不斷變化。只有將用戶在信息流產品中分散的行為數據收集、整合起來,在考慮到時間、空間、任務等因素的同時,基于多層聚類和多維數據進行交叉分析,尋找用戶行為以及項目類屬之間的中心相似度,才能為用戶推送更加精準和個性化的信息。
(二)建構基于多層語義的混合推薦算法
對于傳統推薦算法在多樣性和精準性上的失衡導致推薦結果過于集中或精確性低等問題,還可以利用語義網絡中的語義推理技術,通過推理物品間的語義關系、文本中上下文間的關系等建立新的聯系,從而增強推薦能力。*黃震華、張佳雯、張波、喻劍、向陽、黃德雙:《語義推薦算法研究綜述》,《電子學報》2016年第9期。算法可以通過收集標有語義注釋物品的反饋信息,包括對某物品“本意(物品生產商提供的物品描述信息)”“表意(在使用中被用戶所表達和認知的含義)”“相關意(二者間的相關邏輯)”的反饋以及基于關聯規則的候選物品的挖掘,獲取用戶與物品、物品與物品之間較深層次的關系,來表示用戶對物品的偏好程度和物品之間的關聯程度。現階段的推薦算法已經可以做到初級關聯的識別,例如在搜索某音樂時,現有的推薦算法可以向用戶提供該首樂曲以及該樂曲作者的其他作品、同風格的作品等,而在下一階段的算法學習中,算法將會對該音樂進行多層語義的標簽分析,諸如該音樂的文體起源、衍生形式、典型樂器等,同時對用戶獲取其他音樂的行為進行多維度分析,以推測該用戶搜索某歌曲是為了滿足何種需求、獲取何種信息,從而更有針對性地提供推薦服務。
(三)形成基于人機交互的“自適應”改進機制
目前的推薦算法系統與用戶之間更多體現為一種單向互動。而用戶在信息流產品中的認知和行為需求是一個不斷變化的過程,未來的推薦算法應該意識到用戶對系統的實時反饋的重要性,設計一種合理的人機交互策略,在用戶提供反饋的過程中不斷做出修正和更改。*黃震華、張佳雯、張波、喻劍、向陽、黃德雙:《語義推薦算法研究綜述》,《電子學報》2016年第9期。推薦算法應為用戶建立動態興趣模型,同時提高推薦系統的實時性,在對用戶需求進行及時記錄和調整的同時,讓用戶參與到推薦結果的反饋中去,根據反饋進行自適應改進。
(四)數據凈化,去除無意義噪音
在傳統推薦算法對用戶信息進行追蹤和記錄時,不可避免地存在大量噪音和無意義數據,這些噪音會對精準推薦帶來極大干擾。未來的推薦算法應該在技術上采取加入控制參數等方法對用戶信息進行選擇性的記錄,以去除用戶無意義或失誤性的信息行為,從而提高推薦結果的準確度。
四、結語
在信息流產品中,推薦算法正在打造其獨特的需求滿足機制以實現自身的發展和完善。用戶的需求是多層且易變的,如何更為精準地把握和預測,將是推薦算法需要繼續解決的問題。就如同人們擔憂,在未來機器是不是會取代人的價值,人們對于算法的擔憂也是一直存在的,我們不能忽略推薦算法本身所帶來的倫理道德等問題,但是,我們更應該清楚,技術和人類的發展不是相克的,而是一種協同共生關系。人們需要意識到算法的存在,了解其運作的方式,以更好地把握它、利用它,而不是被技術主導。未來社會的發展,不僅要建立在技術進步的基礎上,而更應該是以技術與人類的相互理解為前提,實現人類智慧與機器智慧的互動。
最后特別想引用蘋果公司的CEO庫克在烏鎮中國互聯網大會上所說的一句話:“很多人都在談AI,我并不擔心機器人會像人一樣思考,我擔心的是人像機器一樣思考!”*https://baijiahao.baidu.com/s?id=1585741143201033766&wfr=spider&for=pc.這句堪稱振聾發聵的警世格言非常值得正在人工智能+領域行進中的人們好好記取。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
