基于主成分回歸的區域物流發展預測模型構建與實證分析
——以泰安市為例
2018-04-19 01:50:11高愛霞滿廣富姚興華
山東工會論壇 2018年2期
高愛霞,滿廣富,姚興華
(1.山東財經大學東方學院,山東 泰安 271000;2.山東農業大學,山東 泰安 271018)
《2017-2022年中國物流市場研究及投資前景預測報告》表明,我國物流業發展盡管起步晚,但發展迅猛,表現為速度快、規模大、第三方物流和第四方物流蓬勃發展,涌現出一批具有較強競爭力和成長能力的物流公司[1]。物流業作為國民經濟的動脈系統和基礎性產業,其發展程度已成為衡量一個國家或地區現代化程度的重要標志之一。據中國市場報告網發布的《2015-2020年中國物流行業現狀調研分析及發展趨勢研究報告》顯示,2020年我國物流行業市場規模將接近360萬億元[2]。構建區域物流發展預測模型對區域物流業發展具有十分重要的意義,通過模型預測未來年份物流發展狀況,為政府及相關部門制定物流發展政策、科學進行物流業管理提供決策依據,為物流企業把握物流市場狀況和變化、發展物流業務提供決策參考。
一、相關文獻研究
物流發展預測方法眾多,主要有定性和定量兩類。定性分析主要對物流業發展趨勢以及物流業發展轉折點進行預測,定量分析則是根據必要的統計資料,對物流業發展的未來狀態進行定量測算。近年來物流業發展預測定量研究方法發展快速,國內外專家采用多種定量研究方法對物流業發展進行預測。
Cullinane KPB等[3]采用BOX-JENKINS模型也稱為自回歸積分滑動平均模型,來預測海貨運指數。M.Hakan Satman等[4]采用BP神經網絡與灰色模型來對物流量進行預測。賈海成等[5]運用多元回歸分析和灰色預測相結合的方法對江蘇省物流業發展進行了預測研究。田麗等[6]采用基于支持向量機和神經網絡(SVM-BP)相結合的組合模型,以我國1990-2001年的樣本數據作為測試集,構建預測模型進行研究。楊蕾等[7]采用隨機時間序列模型對我國2004-2010年的全社會貨運總量月度數據進行建模,進而對物流發展狀況進行了預測。王小麗[8]采用灰色GM(1,1)模型和多元線性回歸模型的多因素灰色預測模型,對河南省2002-2011年物流業發展相關數據進行預測研究。楊晶晶等[9]運用灰色關聯度和灰色系統模型,對江蘇省2000-2010年的物流業相關指標數據進行分析,對江蘇省物流發展進行了動態預測。郭旭文[10]采用計量經濟分析方法對1995-2011年的中國物流業發展進行了預測和實證研究。劉力軍等[11]采用GDP的物流量預測與灰色關聯分析相結合的方法,對石家莊市物流產業2004-2012年的數據進行建模分析和預測研究,進而提出了石家莊市物流業發展的措施。耿立艷等[12]將LSSVM與動態加速系數優化(DACPSO)算法相結合,提出LSSVM-DACPSO的物流預測模型,并以我國1991-2011年物流業發展相關數據為樣本,進行了實例分析。萬玉龍等[13]分別采用線性、對數和乘冪等多種回歸模型,以2005-2015年數據為依據,對淮安市清江浦區域的物流業發展進行預測研究。汪洪帆[14]采用BP神經網絡,以杭州市2000-2015年物流業相關數據,對杭州城市圈物流需求量進行了預測分析。孫遜[15]構建 GA-SVM 物流需求預測模型,以成都市物流業1996-2010年的相關數據作為樣本數據,對成都市物流業發展進行了預測分析。以上研究大多采用優異的方法模型對物流業發展預測方面進行了深入的研究。本文將采用主成分和回歸分析相結合的方法,構建區域物流發展預測模型,并以泰安市物流業發展為實例進行分析,為區域物流業的發展和預測提供決策借鑒。
二、主成分回歸預測模型分析法思想
主成分分析法(PCA)是利用降維的思想,在損失很少信息的前提下把多個指標轉化為幾個綜合指標,進而提取出有用的信息,去除了冗余的信息,從而達到降維的目的[16]。該方法在面對變量較多的復雜問題時,能夠在保證原始信息不丟失的前提下,簡化模型的結構,避免因原始變量之間信息的重疊而降低模型的精度。主成分回歸的原理則是用主成分分析提取的主成分與因變量回歸建模,由于主成分間具有不相關性,并且能較好地反映原來眾多相關性指標的綜合信息,因此,用主成分作為新的自變量進行回歸分析,使得回歸方程及參數估計更加可靠。其步驟為:①原始數據歸一標準化;②計算出標準化后數據矩陣的協方差矩陣;③根據協方差矩陣計算出對應的特征值以及其對應的特征向量,并得到主成分貢獻率和累計方差貢獻率,選取前m個主成分;④采用普通最小二乘法,做前m個主成分F1,F2,…,FP對因變量Y的多元線性回歸,得到回歸模型。⑤由于每個主成分F1,F2,w,Fm均是自變量X1,X2,…Xp的線性組合,因此,經轉化可得最終多元線性回歸模型。
多元線性回歸模型的一般形式為:
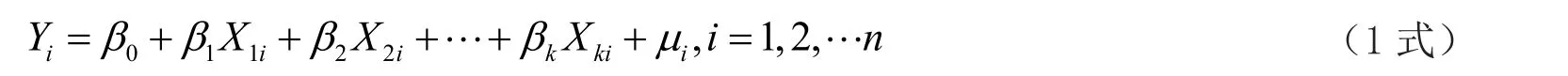
它的非隨機表達式為:
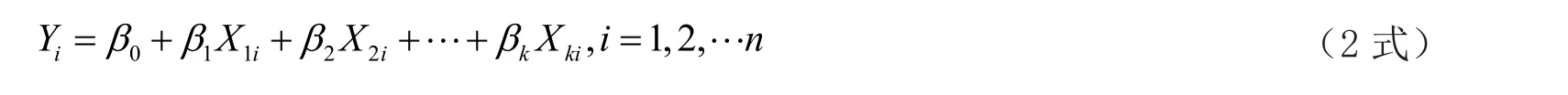
βj也被稱為偏回歸系數。
多元線性回歸模型計算式為:
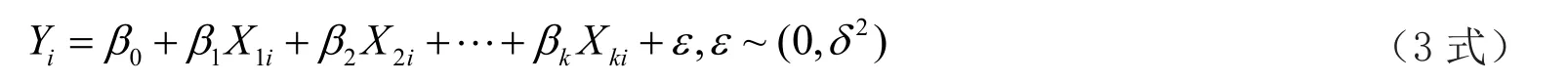
多元性回歸模型的參數估計,同一元線性回歸方程一樣,也是在要求誤差平方和為最小的前提下,用最小二乘法或最大似然估計法求解參數。
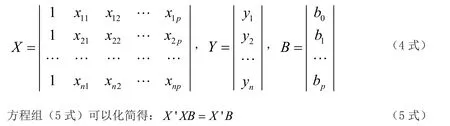
可得最大似然估計值:

該式即為P元線性回歸方程。
三、基于多元回歸法的物流發展預測模型構建分析——以泰安市為例
(一)指標選取
物流業的發展受很多因素的影響,包括經濟因素和非經濟因素。其中經濟因素是影響物流發展的主要因素,包括區域經濟發展規模、區域產業結構、商業活躍程度、進出口貿易、區域交通運輸狀況、固定資產投資、電子商務的發展等;非經濟因素包括宏觀經濟政策和管理體制、物流服務水平、物流信息化水平、交通樞紐和節點城市多式聯運設施建設不斷完善,以及物流園區服務功能的不斷提升等。通過閱讀大量文獻,借鑒國內外學者的文獻,并深入訪談政府部門、專家學者、物流行業協會及物流企業管理者,根據影響物流業發展的因素,按照科學性、全面性、相關性、可操作性、數據的可獲得性的原則,選取與物流發展規模相關性較高的指標如下:
1.貨運周轉量和貨運量。在大量的文獻分析基礎上發現,大部分學者對區域物流發展進行研究時,都采用貨運量作為物流發展狀況的衡量指標。貨運量和貨運周轉量這兩個指標只能反映出物流作業量的一部分,因為物流不僅包括貨物運輸,還包括裝卸、流通加工、存儲、包裝、配送、信息處理等多個環節,但是由于運輸貫穿整個物流活動的始終,而貨物周轉量指標相對于貨運量指標,它不僅包括了運輸對象的數量,還包括了運輸距離的因素,因而能夠全面地反映運輸生產成果。所以本研究選取貨運周轉量作為物流發展規模的量化指標。
2.區域經濟發展規模。物流業是經濟發展必不可少的支撐行業,而地區的經濟發展規模大小又決定著物流需求規模的大小。有研究表明,經濟規模與物流需求具有很強的相關性。如葉柏青等(2016年)研究提出,經濟發展水平與物流業的發展狀況之間有密切的關系;姜維軍等(2016年)研究發現,物流產業的發展同經濟發展水平的提升之間存在著較強的相關性;李紅梅等(2016年)研究發現,區域物流與區域經濟有明顯的動態協同關系。區域經濟發展規模一般用 GDP和人均 GDP 來表示。
3.產業結構。物流的需求規模、層次、結構與區域產業結構密切相關,隨著科技和信息水平的發展,我國的產業結構逐漸由農業主導向服務主導轉變。這里的產業結構主要包括第一產業總值、第二產業總值、第三產業總值三個指標。
4.社會消費品零售總額。社會消費品零售總額反映了商業活躍程度,商業是通過買賣方式,使貨物得以流通的一類經濟活動。一個地區的商業主要包括餐飲、超市、購物中心、各種商店等,一個地區商業活躍度必將影響該地區的物流需求,因此區域的商業活躍程度通常用社會消費品零售總額來衡量。
5.進出口貿易總值。進出口貿易是指兩個不同的國家之間進行的商品、技術和勞務的交換活動。這種貿易由進口和出口兩個部分組成。對于沿海城市,進出口貿易對物流需求影響較大。因此,用地區進出口貿易總額來衡量該地區的物流需求水平。
6.等級公路通車里程。一個地區基礎設施發展情況對物流效率有直接影響。交通基礎設施包括:鐵路、公路、港口、機場等的建設情況,與物流有關的信息系統的建設情況等。我們可以用鐵路、公路的長度,港口、機場的數量以及各交通運輸工具的營運里程,來衡量該地區的物流發展狀況。這里選用等級公路通車里程作為衡量指標。
7.固定資產投資。固定資產投資具有永久性,包括對物流產業的投資和其他產業的投資。其他產業的投資會對經濟的發展具有后向效應,即本年度增加固定資產投資額會影響以后年度經濟的運行情況,從而間接影響物流,對物流產業的投資會直接影響物流的發展,所以固定資產投資也是影響物流的重要影響指標。
8.郵電業務總量。電子商務和互聯網的發展,加快了物流與電商的結合,互聯網時代,就是無線服務時代,線上是無線端的訂單,線下就是物流端的遞送。一方面是從電商向物流端,一方面是從物流向電商端,這種發展也正在快速地推進。可以采用互聯網上網人數來衡量互聯網發展對物流需求的影響,所以郵電業務總量是反映和影響物流的重要影響指標。
(二)數據搜集
通過查找山東省統計年鑒和泰安市統計信息網[17-18],搜集2005-2015年物流業發展數據,見表1所示。這里要說明的是,交通運輸部2014年修訂了公路、水運運輸量統計試行方案,統計口徑發生變化。2013年泰安市貨運量為12068萬噸,貨運周轉量為17214百萬噸公里。由于2014年統計口徑發生變化,2014年泰安市貨運量為6253萬噸,貨運周轉量為13969百萬噸公里;2015年泰安市貨運量為6150萬噸,貨運周轉量為14064百萬噸公里。為便于分析,本研究根據最新統計口徑以及每年的貨運量及貨運周轉量的增長率重新進行推算,以排除統計口徑變化對數據的影響。

表1 2005-2015年物流業發展相關影響因素的歷史數據
(三)泰安市物流發展預測的主成分回歸模型構建分析
1.指標的標準化處理
為便于研究,選取貨物周轉量為因變量,記為y,選取影響貨物周轉量的10個重要因素為自變量,分別用x1-x10表示,其中x1代表貨運量,x2代表地區生產總值,x3代表第一產業總值,x4代表第二產業總值,x5代表第三產業總值,x6代表社會消費品零售總額,x7代表等級公路通車里程,x8代表進出口貿易總值,x9代表郵電業務總量,x10代表固定資產投資。
在做主成分分析之前,為了消除各個變量之間量綱的影響,首先對變量進行標準化處理,即每一變量值與其平均值之差除以該變量的標準差,歸一化處理后數據見表2。
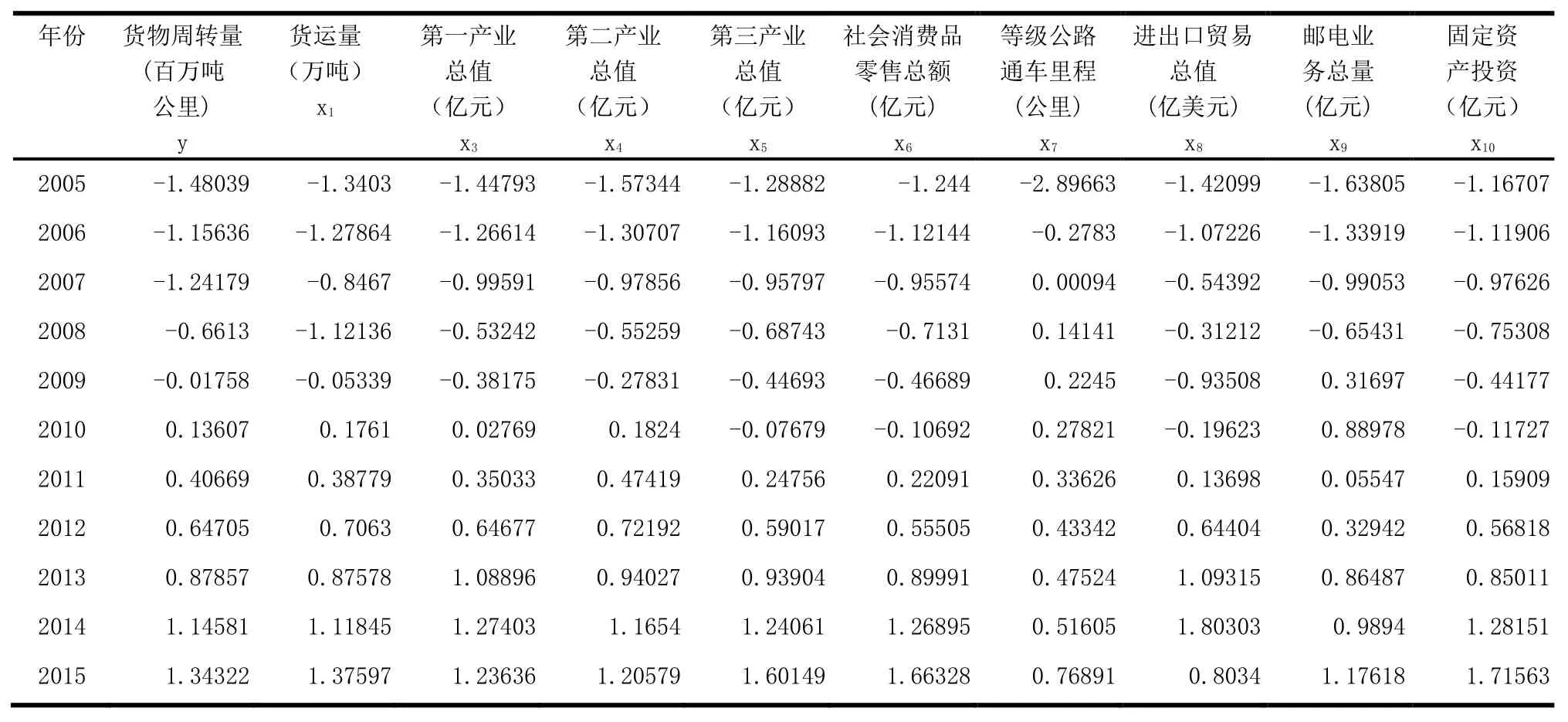
表2 2005-2015年物流業發展相關影響因素的歸一化處理數據
2.普通線性回歸分析
首先用SPSS軟件做因變量y與自變量x1-x10的普通線性回歸,輸出相關結果見表3所示。

表3 模型匯總
由表3可知,回歸模型擬合優度達到99.4%,說明99.4%的預測可以用這個模型來預測。由表4方差分析顯示,線性回歸方程整體顯著性稍差(F=43.642,Sig.=0.023)。經多重共線性診斷表明自變量存在共線性,所以,不能直接采用多元線性回歸,采用主成分分析做多重共線性處理。由于主成分間具有不相關性,并且能較好地反映原來眾多相關性指標的綜合信息,因此,用主成分作為新的自變量進行回歸分析,使得回歸方程及參數估計更加可靠。

表4 Anova
3.主成分分析
利用統計軟件SPSS對表2數據進行主成分分析,在SPSS 軟件中,我們通過因子分析方法來進行主成分分析,統計顯示,KMO值為0.75,大于0.6,說明適合進行主成分分析。輸出相關結果見表5、表6所示。
從表5可看出,變量相關陣中有一個較大的特征值為9.112,這個特征值對總方差的貢獻率達到了91.119%。這說明從原始數據中提取了一個主成分,這一個主成分就解釋了原始數據大部分信息。
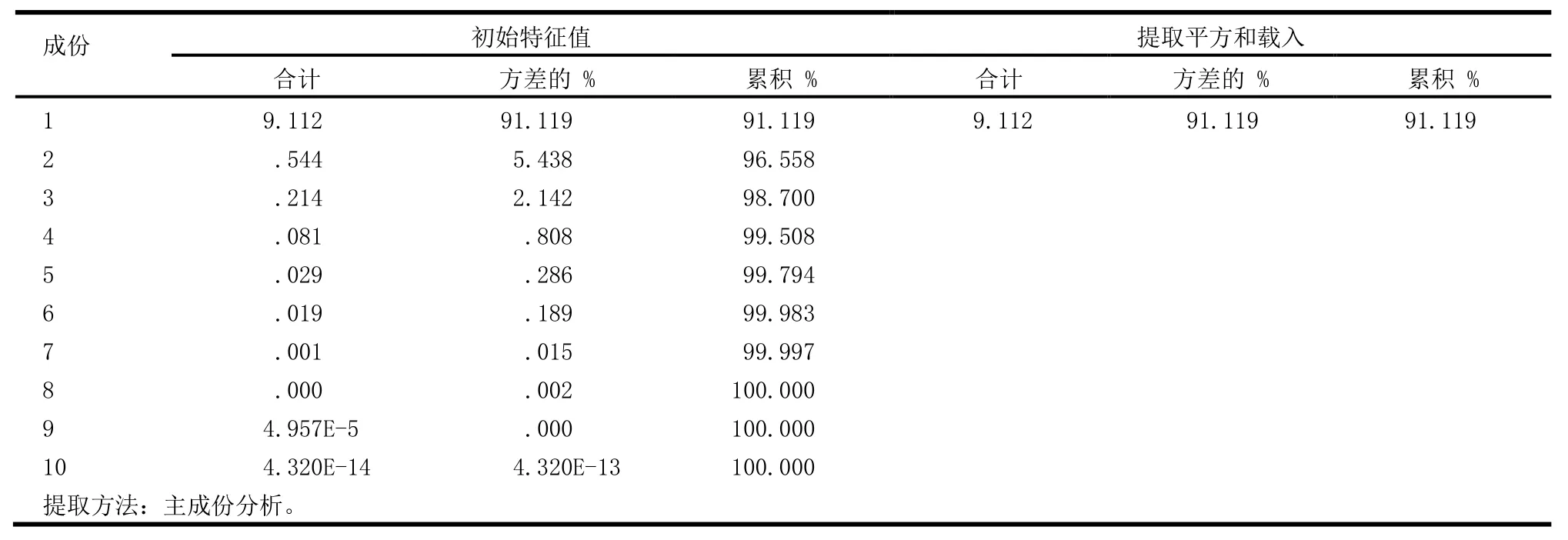
表5 解釋的總方差
成分矩陣如表6。由此可看出,主成分對10個變量的解釋分別為97.9%, 99.8%, 99.5%, 99.4%,
99.0%,98.5%,72.8%,93.0%,93.5%,97.5%。表6中顯示出了這個主成分與原始變量的關系,由表6(初始因子載荷陣)和表5特征向量,得出主因子線性組合表達式為:


表6 成份矩陣
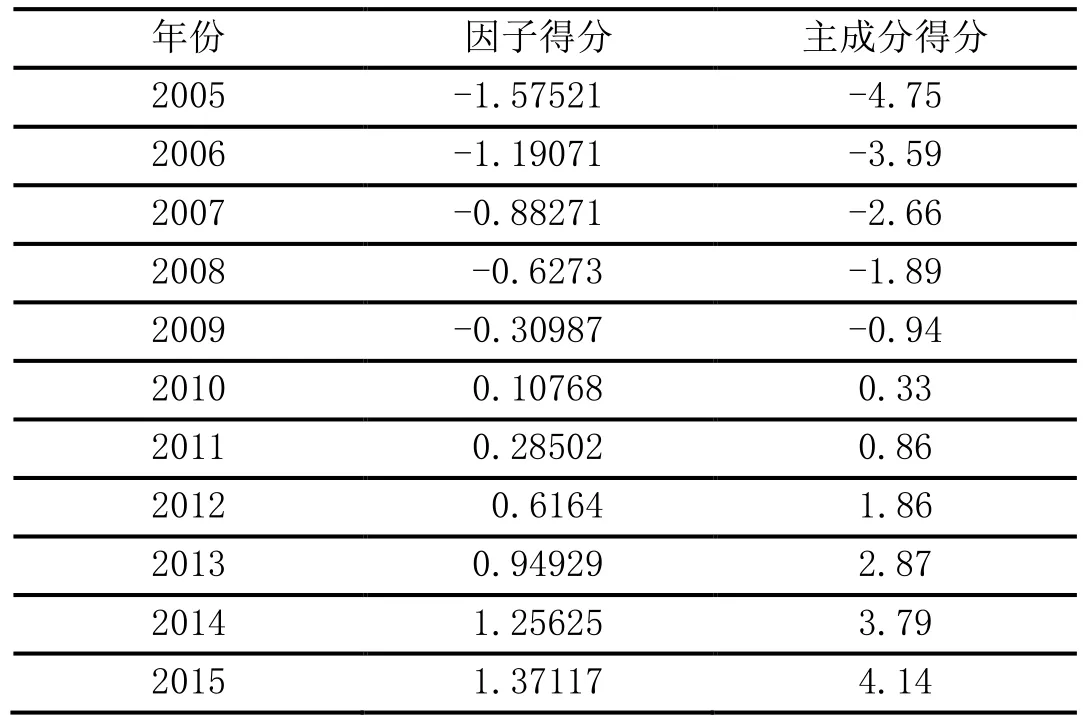
表7 因子得分及主成分得分
其中X1*-X10*表示為標準化變量,這是因為在進行主成分分析時是以標準化變量進行分析的,是從相關陣出發分析的。
由于主成分互不相關,可以用提取的主成分代替自變量進行回歸分析,因此需要計算主成分得分來代替自變量X1*-X10*。在SPSS中,由因子分析提取時是用主成分法提取的,根據初始因子與主成分的關系,未旋轉的初始因子等于主成分除以特征根的平方根,因此主成分得分等于因子得分乘以特征根的平方根,因此可以由因子得分計算主成分得分。根據F1等于第一因子得分乘以第一特征根的平方根,計算主成分得分,見表7。
4.主成分回歸模型構建
用標準化的因變量與主成分得分做回歸,對因變量y做標準化,然后對因變量y和主成分得分F1進行回歸分析,相關輸出結果見表8、表9和表10。

表8 模型匯總

表9 Anova

表10 系數
表8顯示,R=0.987,回歸模型擬合優度達到98.7%,說明98.7%的預測可以用這個模型來預測。由表9方差分析顯示,線性回歸方程非常顯著可信(F=339.11,Sig.=0.000 〈0.005),通過顯著性檢驗,也沒有多重共線性,回歸系數合理。由表10得y*=0.327F1,將(8式)帶入,可得標準化y*關于標準化自變量的回歸方程:
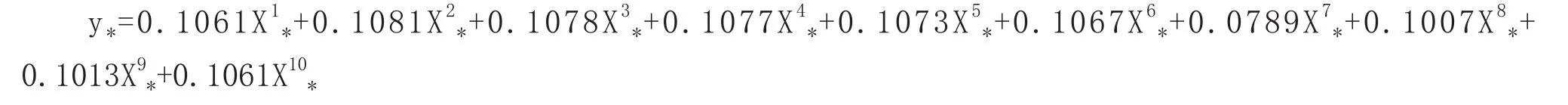
還原為原始變量:

整理得最終回歸模型結果:
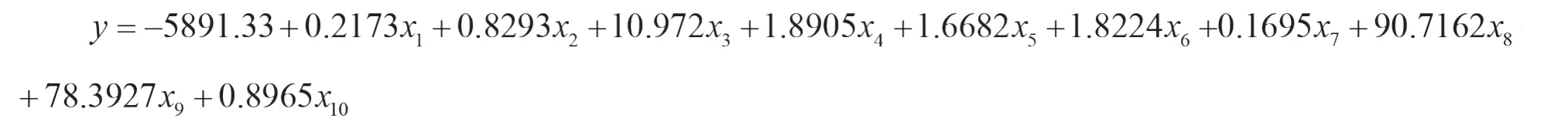
四、結論
隨著經濟的快速發展,泰安市物流業呈現出快速增長態勢。本文選取貨物周轉量為因變量,影響貨物周轉量等10個重要因素為自變量,建立了衡量物流業發展的指標體系。采用主成分回歸方法,首先消除量綱影響,對數據進行了歸一化標準處理,初步回歸發現,指標之間存在一定的線性關系。為此對標準化數據進行主成分分析,提取了一個主成分,解釋了原始數據91.119%的信息,該主成分對10個變量的解釋分別為97.9%, 99.8%, 99.5%, 99.4%, 99.0%,98.5%,72.8%,93.0%,93.5%,97.5%。接著對因變量y做標準化,然后對因變量y和主成分得分F1進行回歸分析,得出回歸模型擬合優度達到98.7%,方差分析顯示,線性回歸方程非常顯著可信(F=339.11,Sig.=0.000〈0.005),通過顯著性檢驗,也沒有多重共線性,回歸系數合理。通過主成分回歸的分析方法構建了主成分回歸模型,明確了影響物流發展的主要經濟因素包括貨運量、區域經濟發展規模、產業結構、社會消費品零售總額、等級公路通車里程、進出口貿易總值、郵電業務總量、固定資產投資等及其對物流發展規模的影響程度,可以為物流發展規模預測提供借鑒意義,同時也能為物流發展政策及決策的制定和實施提供一定的參考。
參考文獻:
[1]2017-2022年中國物流市場研究及投資前景預測報告[M/CD].智研咨詢集團.2017-06.
[2]高愛霞,滿廣富.基于VRIO模型的中小物流企業競爭力評價研究及提升對策[J].山東財經大學學報,2016(6).
[3] Cullinane KPB, Mason KJ,Cape M.A Comparison of Models for Forecasting the Baltic Freight Index:Box-Jenkins Revisited[J].Maritime Economics&Logistics, 1999,1(2).
[4]M.Hakan Satman,Erkin Diyarbakirlioglu.Reducing errors—in—variables bias in linear regression using compact genetic algorithms[J].Journal of Statistical Computation and Simulation,2015,5(3).
[5]賈海成,秦菲菲.區域物流需求預測研究——以江蘇省為例[J].中國物流與采購,2012(3).
[6]田麗,曹安照,王蒙,周明龍,王靜.基于SVM和神經網絡組合預測模型物流需求預測[J].重慶工商大學學報(自然科學版),2012(9).
[7]楊蕾,張苗苗,時間序列模型在物流需求預測中的應用[J].商業時代,2013年(13).
[8]王小麗.基于多因素灰色模型的物流需求量預測[J].統計與決策,2013(14).
[9]楊晶晶,張兆同.基于灰色系統的江蘇省物流需求預測[J].物流工程與管理,2013(1).
[10]郭旭文.基于滯后模型展開的物流發展預測[J].物流技術,2014,33(6).
[11]劉力軍,侯維磊.基于物流量預測及產業關聯分析的石家莊物流業發展研究[J].物流技術,2015,34(24).
[12]耿立艷,郭斌.基于 LSSVM-DACPSO 模型的物流需求預測[J].統計與決策,2015(14).
[13]萬玉龍,胡田田,章艷華.基于多種回歸模型的區域物流需求預測實證分析[J].物流科技,2017,(10).
[14]汪洪帆.基于BP神經網絡的杭州城市圈物流需求預測[J].現代商貿工業,2017(29).
[15]孫遜.基于 GA-SVM 的物流園區物流需求預測及分析[J].中國市場, 2017,(15).
[16]李勇.多元回歸模型在物流需求分析中的應用[J].湖南城市學院學報(自然科學版),2016(1).
[17]山東省統計局.山東省2006-2016年國民經濟和社會發展統計公報[DB/OL].山東統計信息網.http://www.stats-sd.gov.cn/.2016-02-08.
[18]泰安市統計局.泰安市2006-2016年國民經濟和社會發展統計公報[DB/OL].泰安市統計信息網.http://www.tatj.gov.cn.2016-03-30.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
物流技術與應用(2019年8期)2019-09-04 03:29:56
汽車觀察(2018年12期)2018-12-26 01:05:44
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
現代企業(2015年2期)2015-02-28 18:45:09
