基于情感分析的商品評價模型構建研究
2018-05-17 06:49:20陳曉玲許鈞儒
銅陵學院學報 2018年6期
陳曉玲 褚 漢 許鈞儒
(安徽財經大學,安徽 蚌埠 233030)
一、引言
隨著網上購物行為的增多,商品評論數量也越來越多,評論數據的可讀性與豐富性,使得評論往往成為消費者決定是否購買的標尺。由于評論數據量過于巨大,討論的主題涉及商品的各個屬性,想從大量的商品評論中整理出有用信息,是非常困難的。筆者采用情感分析方法,將海量評論中所蘊含的信息挖掘整理出來——建立基于情感分析的商品評價模型,對特定商品進行評價。
情感分析是2001年在分析股票的留言板上首次出現,作者認為,股票的走勢會受到投資者的情感影響,而投資者的情感則可以通過股票留言板中的留言來提取。次年,Turney和Pang[1]分別提出了有監督學習和無監督學習的情感分類研究。
Pang(2002)認為,對文檔進行分類時不必對整個文檔進行研究,應該將文本分類技術用于文檔中含有主觀情緒的部分。Abbasi(2008)對提取特征的過程進行了改進,開發了熵加權遺傳算法,通過對阿拉伯語與英語的語法句法特征分析,提取特征集,有效提高了學習的準確度,數據的準確識別達到了95%[2],這些屬于有監督的機器學習。
無監督學習,也稱基于詞典的規則匹配,通過對特定語言的語法結構進行分析,制定規則和詞典,對語句進行分析。pak(2010)等人對國外流行的推特上的內容進行情感分析表明,利用這種社交平臺監控國民輿情具有可操作性,并且發現越來越多的人喜歡在這種平臺表達自己情感[3]。
國內關于情感分析的研究較晚。朱嫣嵐(2006)認為,詞作為文章的基礎單元,首先要對詞的正負面做研究,進而研究出詞義傾向模型。其核心思想在于相同極性的詞會經常在一起出現,或者是可以相互替換[4]。張子瓊等人在2010年對當時情感分析的狀況進行了一個總結,論述了商品評論挖掘的經濟價值,對于股票、電影和一些電子商品的商品評論中含有的褒貶義情感與商品的銷量成正相關[5]。
隨著電子商務的蓬勃發展,消費者迫切需要科學有效的商品評價數據指導消費。如何利用網上海量評論數據,有效地分析得出真實、準確的評價信息,成為信息科學、統計學等領域的研究熱點。本文以情感分析理論為基礎,側重分析基于情感分析的商品評價模型的構建,以便對電子商務產品進行評價。
二、基于情感分析的商品評價模型構建
基于情感分析的評價,其評價指標源于大量的評論數據,數據的獲取和處理是構建模型的基礎。
1.數據的獲取
利用python對電商評論數據進行抓取,需要在發鏈接請求時附帶上完善的header信息即可,如圖1所示。

圖1 請求信息
2.數據的清洗
由于刷單行為越演越烈,數據清洗成為構建商品評價模型的重要一環。數據清洗基于二個規則,第一,每個買家每天最多在一件商品下評論一次,這是為了杜絕同一賬號在同一商品下多次刷評論的行為,也是為了刪除爬取過程中的重復數據。第二,從評價內容的角度,利用余弦定理,從評價內容中找出相似的文本向量,剔除極度相似的評論。
3.指標體系的建立
本文以手機為例,討論指標體系的構建。
(1)主題模型
利用LDA(Latent Dirichlet Allocation)主題模型,我們可以從經過清洗的大量數據文本中找出潛在主題——即消費者所關心的商品屬性,通過人為的判定這些主題的類別,來確定出商品的評價指標體系。
LDA模型對詞語和文章的關系有著這么一種認識,即每一篇文章或者每一段文字都是由一個或者多個主題構成,每一個主題又是由特定的詞組合而成。LDA的聯合概率公式為:
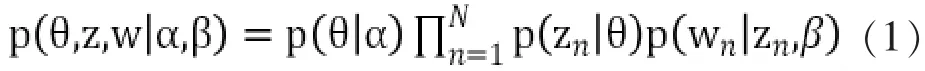
每一篇文章首先從主題分布θ中挑選出一個主題 z(p(θ|α)),同時 z對應著一個詞分布 p(zn|θ),從詞分布中挑選出N詞語,再重新回到主題分布中挑選主題,循環K次就是一篇文章的詞分布。α,β是主題分布與詞分布的先驗分布(狄里克雷分布)的參數。計算后驗概率為

似然函數:
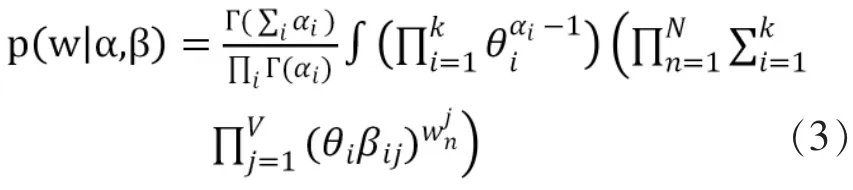
該式中含有的參數α,β是無法直接求解的,只能使用計算機進行大量的樣本抽取,對后驗分布進行估計。
(2)指標體系
利用主題模型,從大量評論中挑出消費者最關注的商品屬性,構成評價指標體系。

表1 指標體系表
4.情感單元的抽取
情感單元包含兩部分信息,情感的主體和情感。情感單元的抽取目的是將雜亂的評論變為規范的問卷式數據,一段評論可能包含多個情感單元,筆者只抽取每段評論中與最終評價指標息息相關的情感單元。
情感單元中的情感主體利用一些篩選規則即可以很快判定情感。從可實現性與高效的角度,筆者將每一條規則定為四個部分[關鍵詞、聯合詞1、聯合詞2、互斥詞]。 例如[(容量),(電),(…),(內存、存儲、空間)],這樣一條簡單的規則,已經可以將電池容量這個主體抽取出來了,經過反復測試,筆者建立了90余條規則用于抽取情感主體。
情感單元中的情感抽取則是根據三部分決定的,情感詞(褒貶義詞)、程度詞和轉意詞,如表2所示:

表2 詞性標注
每一個褒貶義詞都有自己的褒貶義得分,褒義詞正分,貶義詞負分,程度詞0.8至2分,轉意詞-1分,每一句計算公式為:

最終的情感分還需要進行規范:

最終的抽取結果如表3所示:

表3 評論情感單元提取表
5.情感詞典的擴充
盡管與前幾年相比,大學新生的英語水平有了明顯提高,但仍有相當一部分學生的英語水平并不足以滿足ESP課程的要求。如果學習者沒有一定的英語基礎,ESP教學因增加了專業內容,且教學目標并不僅僅是對語言技能的訓練,從而將加重這些學生的學習負擔,他們會喪失英語學習的興趣。因而,現階段在我國高校大面積推廣ESP取代EGP顯然過于冒進。一個普遍接受的做法是在學習者通過大學英語四級考試以后再開展ESP教學,這樣教學效果將大大提高。目前,可以在學生入學英語水平普遍較高的院校進行試點ESP取代EGP,以為下一步改革積累經驗。
情感詞典是幫助確定情感強弱與翻轉的詞典,本文使用的基礎詞典是hownet情感詞典。“這部手機好”和“這部手機很好“這兩句話都是褒義,但是“很”這個程度詞就讓后一句的褒義要大于前一句。由于,Hownet詞典沒有基于特定方向,像發燙、黑屏、卡機、自動關機這類過于專業化的詞匯沒有出現在詞典中,需要根據研究方向進行擴充和修改詞典。筆者將利用Apriori和word2vec模型對評論進行處理,找出和研究主體相關的詞,再人工篩選出合適的詞加入詞典。利用非監督的機器學習找出行業相關的詞,再人工篩選,能夠有效提高詞典的擴充效率與準確率。
6.評論的有效度模型
在商品的評價中,貼合消費者思維模式的評論是高質量的評論,筆者希望評論的質量越高對模型最終結果影響越大,因此,在建立商品評價模型前,就需要先建立評論的有效度模型。
在爬取的評論數據中,除了有每一條評論的文本內容,還含有一些其他信息,比如買家的昵稱、等級、評論的點贊數量、回復數量和評價時間,這些信息可以代表問卷質量,表4為評論的附帶信息。
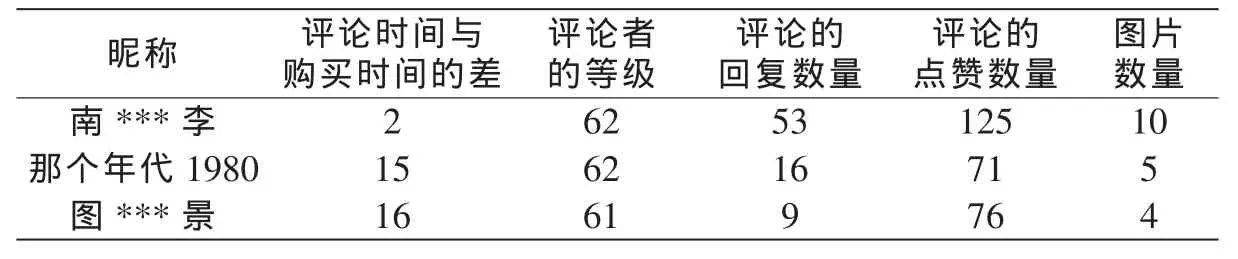
表4 買家相關信息
指標都是效益型指標,我們利用熵值法確定權重,熵值法的核心公式:
計算第i個評論第j項指標的占比
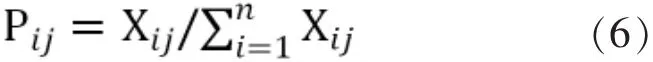
計算評論的第j項指標熵
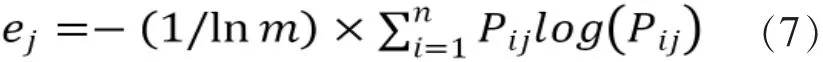

7.商品評價模型
在選取評價模型時考慮了共性和個性兩個要求:共性,評價模型將海量評論的信息總結出規律,同時又盡可能的保留更多的信息。個性,商品的同一屬性可能不同的人的評價是不一樣的,所以希望在最終評價時可以針對不同類型的客戶,給予不同的評價結果。
模糊關系矩陣R可以解決共性問題,不僅從評論中提取出有效的信息,最終的信息是根據評論信息計算該商品屬性對于非常滿意、滿意、一般、不太滿意和非常不滿意五個消費者態度的隸屬度,這樣的隸屬度矩陣富含更多的信息。
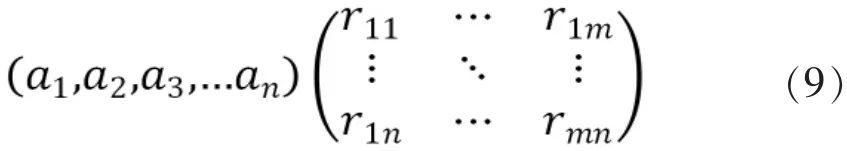
權數與關系矩陣分別代表了個性與共性,筆者很難斷定兩者的重要性,所以筆者更傾向選擇算子值得注意的是模糊關系矩陣的構造不同于一般的計算公式,矩陣的計算與前文評論的有效度是密不可分的:
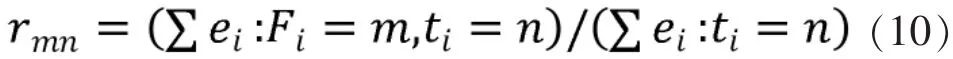
每條評論有以下幾個指標,見表5

表5 隸屬度指標
評價模型的構建邏輯見圖2。
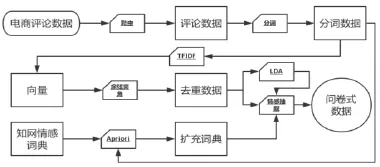
圖2 評價模型構建邏輯
三、結論
筆者通過爬蟲技術從電商網站獲取評論數據,利用情感分析技術將不規則的評論數據轉變成規范的問卷樣式,再利用模糊數學方法建立商品評價模型,整個流程省時省力。評論數據作為評價模型的源數據,包含了非常重要的消費者體驗信息,模型評價結果貼合消費者感受。研究表明,利用評價結果幫助消費者挑選商品是可行的,當擁有大量手機的模糊矩陣后,就可以在更大范圍內幫助不同消費者挑選商品。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
