基于改進i-vector的說話人感知訓練方法研究
2018-05-30 01:26:56梁玉龍邱澤宇
計算機工程 2018年5期
梁玉龍,屈 丹,邱澤宇
(解放軍信息工程大學 信息系統工程學院,鄭州 450002)
0 概述
近年來,在連續語音識別應用中存在一個難以忽視的問題,即由訓練數據與測試數據間的說話人不匹配導致的系統性能下降。雖然基于深度神經網絡(Deep Neural Network,DNN)[1-5]的語音識別系統極大地提升了語音識別的性能,但在該類系統中仍然存在一個隱含假設:訓練數據和測試數據服從相同的概率分布,該假設在實際中很難滿足,主要原因是訓練階段難以獲得與測試環境相匹配的數據,或匹配數據較少,通常不能對應用場景進行全覆蓋,使得訓練和測試的條件仍存在不匹配的問題。
可以使用說話人自適應技術解決模型和測試間說話人不匹配的問題,對此,許多研究機構已經做了大量關于DNN自適應方面的研究。這些方法中,文獻[6-12]中基于辨識向量(i-vector)的說話人感知訓練方法備受青睞,其基本思想是將i-vector和原始輸入特征拼接后對DNN模型進行訓練,該方法操作簡單且容易與其他自適應方法兼容。上述文獻主要關注純凈語音條件下的基于i-vector的說話人感知訓練方法,文獻[13-15]則研究噪聲條件下基于i-vector的自適應方法,研究結果顯示基于i-vector的說話人感知訓練方法同樣適用于噪聲條件。
雖然學者們針對基于i-vector的說話人感知訓練做了大量研究,但由于在獲取i-vector的過程中常使用MFCC作為特征,MFCC雖然具有較好的表征能力和一定的魯棒性,但其低層特征表征能力有限,且在惡劣環境中的魯棒性欠佳,導致用其提取的i-vector表征能力受到影響。一些研究機構試圖應用其他魯棒性更強的特征代替MFCC特征來獲取性能更優的i-vector,其中優先考慮的是瓶頸(bottleneck)特征[16],該特征的表征能力和魯棒性均優于MFCC,因此,其受到各研究機構的普遍青睞,但由于在提取bottleneck特征時,在DNN結構中引入了bottleneck層,該策略降低了DNN的幀分類準確率,使得系統的識別性能受到一定的影響。
針對上述問題,本文提出一種基于改進i-vector的說話人感知訓練方法,其主要特點是在獲取i-vector的過程中替換掉傳統特征MFCC。首先,訓練一個與說話人無關的DNN模型;然后,應用奇異值矩陣分解(Singular Value Matrix Decomposition,SVMD)算法對DNN某一隱層的權值矩陣進行分解,用分解后的矩陣代替原始權值矩陣,并應用該網絡提取低維特征;最后,應用該特征完成i-vector提取器的訓練與i-vector的提取,進行說話人感知訓練。
1 基于i-vector的說話人感知訓練方法
將說話人信息輸入到DNN后,DNN能自動利用說話人信息對網絡參數進行調整,該方法稱為說話人感知訓練[17]。
1.1 訓練方法原理
說話人感知訓練方法即從句子中估計說話人信息,然后將這些信息輸入到網絡中,通過DNN訓練算法自動理解如何利用這些說話人信息完成模型參數的調整。圖1所示為說話人感知訓練過程示意圖,DNN的輸入包括聲學特征和說話人信息2個部分,其余部分與DNN模型相同。

圖1 基于i-vector的說話人感知訓練過程
當輸入特征不包含說話人信息時,第一個隱層的激勵為:
v1=f(z1)=f(W1v0+b1)
(1)
其中,v0表示輸入聲學特征向量,W1表示權值矩陣,b1表示偏置向量,z1表示輸入聲學特征向量的線性變換。當加入說話人信息后,式(1)變為:
(2)
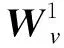
說話人感知訓練的優點是其暗含、高效的自適應過程。由式(2)可以看出,說話人感知訓練算法無需單獨的自適應步驟,其自適應過程可以理解為對偏置項做的變換,該過程使得模型對不同的說話人都適用。如果能夠可靠地將說話人信息估計出來,則說話人感知訓練將在DNN自適應框架中具有優勢。
1.2 i-vector原理
i-vector技術在說話人識別及說話人確認中作為說話人信息矢量被廣泛應用,該技術之所以有如此廣泛的應用,原因主要有以下2點:1) i-vector表示了說話人特征中最重要的信息,且其值是低維的;2) i-vector不僅可以用于GMM模型的自適應,也可以用于DNN模型的自適應。因此,i-vector可以作為說話人自適應的一個理想工具。下文介紹i-vector的計算推導過程[17]。
i-vector提取首先需要訓練一個通用背景模型(Universal Background Model,UBM),UBM是一個由K個對角協方差高斯組成的高斯混合模型,用來描述整個數據空間的分布,該模型可以表示為:
(3)

(4)
其中,μk(s)表示第s個說話人從UBM自適應得到的屬于第k個高斯分布的均值。進一步假設自適應后的說話人均值s與均值μk存在如下關系:
μk(s)=μk+Tkw(s),1≤k≤K
(5)
其中,Tk表示全變換空間矩陣,其包含M個基矢量,這些基矢量組成了高斯均值向量空間的一個子空間,該子空間包含整個均值向量空間最核心的部分,w(s)表示第s個說話人的i-vector。
i-vector是一個隱含變量,如果假設i-vector滿足均值為0、方差為單位方差的高斯分布,且每一幀都屬于某一固定的高斯分量,同時全變換空間矩陣T是已知的,則可以估計后驗概率分布如下:
(6)
(7)
零階與一階統計量分別為:
(8)
(9)
其中,γtk(s)是第s個說話人的第t幀特征序列屬于第k個高斯分量的后驗概率。i-vector可以看作是變量W在最大后驗概率(MAP)下的點估計:
(10)
由式(10)可以看出,i-vector就是后驗分布的均值。
由于{Tk|1≤k≤K}是未知的,因此需要使用期望最大化(Expectation Maximization,EM)算法從特定說話人的聲學特征{xt(s)}中,根據最大似然(Maximum Likelihood,ML)準則來進行估計。其中,EM算法的E(Expectation)步驟的輔助函數為:
(11)
式(11)等價于:
(12)
將式(12)對Tk求導后可以得到EM算法的M(Maximization)步驟:
(13)
其中,式(14)與式(15)通過E步驟得到。
(14)
(15)
2 基于改進i-vector的說話人感知訓練方法
2.1 改進的i-vector提取方法
傳統的i-vector提取方法用MFCC作為輸入特征,為使i-vector的魯棒性更強,一些研究機構利用bottleneck特征代替MFCC特征,實現i-vector提取器的訓練與i-vector的提取。但在提取bottleneck特征時,設置的DNN網絡bottleneck層節點數遠小于其他隱層節點數,導致系統的幀分類準確率受到影響,為此,本文提出應用基于SVD的低維特征提取方法得到低維特征,用其代替MFCC特征完成i-vector提取器的訓練與i-vector的提取。
目前研究DNN模型的矩陣分解方法主要關注神經網絡的參數減少,如文獻[18]提出的思想。這些方法分解DNN模型的權值,利用低秩分解或SVD減少神經網絡無用參數的數量,但其重構的神經網絡在識別精度上沒有太大變化。基于SVD的低維特征提取方案如圖2所示,該方法使用SVD對某一隱層的權值矩陣進行分解(該權值矩陣不包括偏移向量),將分解后得到的基矩陣代替原始矩陣,然后應用新的網絡提取低維特征。

圖2 基于SVD的低維特征提取方法示意圖
采用基于SVD的低維特征提取方法的原因有2點:
1)因為無法直接對隱層的線性輸出進行變換,所以需要使用間接方法,在計算DNN隱層的線性輸出時,層與層間的權值矩陣作用于每一幀特征,因此,可以將權值矩陣看作是一種具有一定的整體分布特性的廣義映射函數。
2)同一層的權值矩陣與偏置向量沒有整體性聯系,很難對偏移向量和權值矩陣同時進行操作,因此,在該特征層不設置偏移向量。
用SVD算法對權值矩陣進行分解的過程表示為:
(16)
其中,A為帶分解矩陣,U為一個m×m的U矩陣,矩陣U為一個m×n的對角矩陣且其對角線上的元素非負,VT為V的轉置,S的對角線元素是矩陣A的奇異值,奇異值按降序排列,在這種情況下,對角矩陣S由A唯一確定。此時可以保存k個奇異值和A的近似矩陣Um×kNk×n。
2.2 訓練方法步驟
獲取改進的i-vector后,將得到的改進i-vector與原始輸入特征進行拼接,得到新的包含說話人信息的輸入特征后,利用該特征對模型進行訓練與識別。基于改進i-vector的說話人感知訓練方法過程如圖3所示。

圖3 基于改進i-vector的說話人感知訓練示意圖
該訓練方法的主要步驟如下:
1)訓練數據模型SI-DNN;
2)應用SVD對最后一層隱層權值矩陣進行分解,并用該結果代替原始權值矩陣;
3)應用網絡提取新的低維特征;
4)應用低維特征進行i-vector的提取;
5)應用改進的i-vector進行說話人感知訓練。
3 實驗結果與分析
3.1 語料庫簡介
為驗證本文所提特征的識別性能,采用如下2種語料庫進行測試:
1)WSJ語料庫,國際通用的英文語料庫,數據由麥克風在安靜環境下錄制得來。訓練集包含WSJ 0和WSJ 1兩部分,共81.3 h。其中,WSJ 0包含84個說話人,共7 138句,總時長為15.1 h,WSJ 1包含200個說話人,共30 278句,總時長為66.2 h。測試集包括Eval 92和Dev 93兩部分。本文使用Dev 93作為測試集,該部分包含10個說話人,共503句,總時長為65 min。
2)Vystadial 2013 Czech data(Vystadial_cz),開源的捷克語語料庫,總時長約15 h,主要由3類數據組成:Call Friend電話服務語音數據、Repeat After Me語音數據和Public Transport Info口語對話系統語音數據。其中,訓練數據集共22 567句,126 333個詞語,總時長為15.25 h;測試集共2 000句,11 204個詞語,總時長為1.22 h。
3.2 實驗工具與評價指標
3.2.1 實驗工具
實驗使用的工具包括2個:開源工具包Kaldi和PDNN+Kaldi。Kaldi工具包主要實現數據準備、特征提取、語言模型和聲學模型的訓練與解碼。PDNN工具包主要實現DNN的搭建與訓練。
3.2.2 評價指標
連續語音識別的結果一般為詞序列,采用動態規劃算法將識別結果與正確的標注序列對齊后進行比較,其中產生的錯誤類型分為3類:插入錯誤,刪除錯誤,替代錯誤。插入錯誤是由于在2個相鄰的標注間插入其他詞所引起,刪除錯誤是由于在識別結果中找不到與某個標注對應的詞所引起,替代錯誤是由于識別得到的詞與對應的標注不相符所引起。
假設某個測試集中標注的總個數為N,插入錯誤個數為I,刪除錯誤個數為D,代替錯誤個數為R,則詞錯誤率(WER)的定義如下:
(17)
該評測指標越低,表明系統的識別性能越好。
3.3 基線系統
本文采用的基線系統為基于i-vector的說話人感知訓練模型,將其命名為DNN+i-vector模型,由于實驗中需要比較基于SVD提取的低維特征與bottleneck特征的性能,且這2個模型的訓練都基于GMM-HMM模型,因此本節將給出這3個模型的具體參數設置。
1)GMM-HMM+LDA+MLLT+SAT模型。輸入特征為13維的MFCC特征,訓練三音子GMM聲學模型。首先,經過線性區分性分析(Linear Discriminant Analysis,LDA)將9幀拼接的特征降到40維;然后,采用特征空間最大似然線性回歸(feature-space Maximum Likelihood Leaner Regression,fMLLR)進行特征歸一化;最后,進行說話人自適應訓練(Speaker Adaption Training,SAT)。對于WSJ語料庫和Vystadial_cz語料庫,采用的高斯混元數均為9 000。
2)DNN-HMM/DNN-HMM+i-vector模型。采用DNN對聚類后的三音子狀態的似然度進行建模。以WSJ語料庫的DNN模型為例,該模型包括6個隱層,每個隱層包含1 024個節點,激活函數為Sigmoid函數。輸入層包含11幀40維fbank特征,DNN的輸入節點為440個,輸出層節點數為GMM-HMM+LDA+MLLT+SAT模型中綁定后的三音子狀態數,有3 415個節點。用后向傳播(Back Propogation,BP)算法對DNN進行訓練,以DNN計算得到的預估計概率分布與實際概率分布間的交叉熵作為目標函數。在BP算法中,隨機梯度下降法的mini-batch大小為256。BP過程所用的綁定狀態標注由GMM-HMM+LDA+MLLT+SAT模型對訓練集進行強制對齊得到。使用受限玻爾茲曼機(Restricted Boltzmann Machines,RBMs)對DNN參數初始化。最終的網絡結構參數設置為“440-1024-1024-1024-1024-1024-1024-3415”。與WSJ語料庫參數設置相似,Vystadial_cz語料庫的網絡結構參數設置為:“440-1024-1024-1024-1024-2125”。對于DNN+i-vector模型,只有輸入需要拼接100維的i-vector,因此,其輸入變為540,其余設置相同。
3)BNF+GMM-HMM+LDA+MLLT模型。首先,采用DNN模型進行BNF提取,然后將BNF輸入到GMM-HMM+LDA+MLLT模型中,該模型由上述第一個模型GMM-HMM+LDA+MLLT+SAT中省略最后SAT訓練所得。對于BNF提取網絡而言,輸入特征與DNN模型的輸入特征相同。經過多次實驗表明,對于WSJ語料庫,相應的bottleneck DNN的網絡結構參數設置為“440-1024-1024-1024-1024-40-1024-3415”時性能最佳,對于Vystadial_cz語料庫,bottleneck DNN設置為“440-1024-1024-40-1024-2125”時bottleneck特征的性能最佳。2個語料庫使用的聲學模型均為GMM-HMM+LDA+MLLT。
DNN訓練的學習速率初始值為0.08,當相鄰2輪訓練的誤差小于0.2%時,學習速率減半,當減半后相鄰2輪的誤差再次小于0.2%時訓練停止(如果一直大于0.2%,則最多進行8次學習)。沖量值設為0.5,mini-batch尺寸設為256。基線系統詞錯誤率如表1所示。

表1 基線系統詞錯誤率 %
3.4 基于SVD的低維特征提取
基于SVD的低維特征提取步驟為:首先,初始化一個與說話人無關的DNN模型(SI-DNN);然后,對DNN基線系統某一層的權值矩陣應用SVD算法做矩陣分解;最后,用分解后的基矩陣替換原始權值矩陣。
應用該特征重新訓練GMM-HMM+LDA+MLLT聲學模型并解碼。其中,影響識別性能的因素主要有2個:1)對DNN的哪一層權值矩陣進行分解;2)對權值矩陣分解多少維效果更優。根據這2個因素,本文分別做實驗進行驗證。實驗結果如表2和表3所示。

表2 WSJ語料庫DNN-SVD 詞錯誤率結果

表3 Vystadial_cz語料庫DNN-SVD詞錯誤率結果
表2中“SVD-1”表示最后一層隱層的權值矩陣,“SVD-2”表示倒數第2層隱層的權值矩陣,詞錯誤率表示由DNN+矩陣分解+GMM-HMM+LDA+MLLT組成的語音識別系統的詞錯誤率。從表2的結果中可以看出,對于WSJ語料庫,當使用SVD對最后一個隱層的權值矩陣做分解并取分解維數為40時,效果最好。由表3的結果可以看出,對于Vystadial_cz語料庫,當使用SVD對最后一層隱層的權值矩陣做分解并取分解維數為30時,效果最好。
由上述結果可知,基于矩陣分解的方法克服了幀分類準確率下降的問題,與基線系統BNF+GMM-HMM+LDA+MLLT相比,其WSJ語料庫的識別性能提升了1.52%,Vystadial_cz語料庫的識別性能提升了9.11%。由于矩陣分解的算法解決了低資源情況下的數據不充分訓練問題,因此其在數據量較小的Vystadial_cz語料庫上的識別性能提升得更高,在數據量相對充足的WSJ語料庫上性能提升不明顯。
DNN通過每層的非線性變換將輸入特征變得越來越抽象,魯棒性也越來越強,因此,理論上由最后一層得到的特征表征能力會優于由倒數第2層得到的特征,在WSJ與Vystadial_cz語料庫中的實驗結果也證明了這一點。本文分析認為,分解尺寸的大小應該與數據量的多少有關,超出或少于某個范圍,會導致特征表征稀疏或特征表示不充分,進而導致系統的識別性能下降。
3.5 基于改進i-vector的說話人自適應方法
基于改進i-vector的說話人自適應方法步驟為:首先,將SVD-BN特征代替原MFCC特征進行i-vector提取器的訓練與i-vector的提取,得到改進后的i-vector;然后,將改進的i-vector代替原始i-vector,與DNN的輸入特征進行拼接后送入DNN進行訓練與識別。該方法所用模型的其余參數設置與基線DNN+i-vector模型相同。實驗結果如表4所示。

表4 基于改進i-vector的說話人感知訓練識別結果 %
由表1、表4可以看出,在Vystadial_cz語料庫中,相對DNN-HMM語音識別系統,本文方法識別性能提升了1.62%,相對原始基于i-vector的方法,本文方法識別性能提升了1.52%。在WSJ語料庫的實驗中,上述性能分別提升了3.9%和1.48%。實驗結果表明,改進的i-vector在提取時應用了基于SVD分解得到的低維特征,該特征克服了幀分類準確率下降的問題,因此,其魯棒性與表征能力更優,使得到的i-vector包含更有用的說話人信息,最終使得整個識別系統的性能得到提升。
4 結束語
傳統的i-vector提取方法主要應用MFCC作為輸入特征。由于MFCC的魯棒性與表征能力均較差,因此本文提出一種基于改進i-vector的說話人自適應方法,該方法在一定程度上克服了幀分類準確率下降的問題,由其提取的特征表現出了較好的魯棒性。實驗結果表明,相比原有基于i-vector的方法,該方法的系統識別性能較高。下一步將考慮應用更優的算法以獲取更有效的特征表征,使系統更魯棒、識別率更高。
[1] HINTON G,DENG L,YU D,et al.Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups[J].IEEE Signal Processing Magazine,2012,29(6):82-97.
[2] DAHL G E,YU D,DENG L,et al.Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J].IEEE Transactions on Audio Speech and Language Processing,2012,20(1):30-42.
[3] 李傳朋,秦品樂,張晉京.基于深度卷積神經網絡的圖像去噪研究[J].計算機工程,2017,43(3):253-260.
[4] 梁玉龍,屈 丹,李 真,等.基于卷積神經網絡的維吾爾語語音識別[J].信息工程大學學報,2017,18(1):44-50.
[5] 秦楚雄,張連海.低資源語音識別中融合多流特征的卷積神經網絡聲學建模方法[J].計算機應用,2016,36(9):2609-2615.
[6] LIAO H.Speaker adaptation of context dependent deep neural networks[C]//Proceedings of 2013 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2013:7947-7951.
[7] SEIDE F,LI G,CHEN X,et al.Feature engineering in context-dependent deep neural networks for conversational speech transcription[C]//Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding.Washington D.C.,USA:IEEE Press,2011:24-29.
[8] YAO K,YU D,SEIDE F,et al.Adaptation of context-dependent deep neural networks for automatic speech recognition[C]//Proceedings of 2012 IEEE Workshop on Spoken Language Technology.Washington D.C.,USA:IEEE Press,2012:366-369.
[9] HAMID O A,JIANG H.Rapid and effective speaker adaptation of convolutional neural network based models for speech recognition[EB/OL].[2017-04-25].http://www.isca-speech.org/archive/archive_papers/interspeech_2013/i13_1248.pdf.
[10] SELTZER M,YU D,WANG Y.An investigation of deep neural networks for noise robust speech recognition[C]//Proceedings of 2013 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2013:7398-7402.
[11] YOSHIOKA T,RAGNI A,GALES M J.Investigation of unsupervised adaptation of DNN acoustic models with filterbank input[C]//Proceedings of 2014 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2014:6344-6348.
[12] DELCROIX M,KINOSHITA K,HORI T,et al.Context adaptive deep neural networks for fast acoustic model adaptation[C]//Proceedings of 2015 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2015:5270-5274.
[13] KARANASOU P,WANG Y,GALES M J F,et al.Adaptation of deep neural network acoustic models using factorized i-vectors[EB/OL].[2017-04-20].http://www.isca-speech.org/archive/archive_papers/interspeech_2014/i14_2180.pdf.
[14] SENIOR A,MORENO I L.Improving DNN speaker independence with i-vector inputs[C]//Proceedings of 2014 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2014:225-229.
[15] ROUVIER M,FAVRE B.Speaker adaptation of DNN-based ASR with i-vectors:does it actually adapt models to speakers?[EB/OL].[2017-04-20].http://pageperso.lif.univ-mrs.fr/~benoit.favre/papers/favre_interspeech 2014a.pdf.
[16] YU C,OGAWA A,DELCROIX M,et al.Robust i-vector extraction for neural network adaptation in noisy environment[EB/OL].[2017-04-15].http://www.isca-speech.org/archive/interspeech_2015/papers/i15_2854.pdf.
[17] SAON G,SOLTAU H,NAHAMOO D,et al.Speaker adaptation of neural network acoustic models using i-vectors[C]//Proceedings of 2013 IEEE Workshop on Automatic Speech Recognition and Understanding.Washington D.C.,USA:IEEE Press,2013:55-59.
[18] XUE S F,HAMID O A,JIANG H,et al.Fast adaptation of deep neural network based on discriminant codes for speech recognition[J].IEEE/ACM Transactions on Audio,Speech and Language Processing,2014,22(12):1713-1725.
猜你喜歡
甘肅教育(2020年18期)2020-10-28 09:07:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國體育教練員(2018年2期)2018-07-23 02:49:20
中國體育教練員(2018年2期)2018-07-23 02:49:12
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
運動(2016年7期)2016-12-01 06:34:36
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
