大數據驅動金融市場監管研究
2018-06-11 08:45:53朱琳金耀輝
華東理工大學學報(社會科學版) 2018年6期
朱琳 金耀輝

[摘要]金融監管中的大數據應用在“互聯網+”時代面臨巨大的機遇與挑戰。本文提出應用共享與公開數據輔助政府決策的模型框架,以上海自貿區保稅區域P2P企業風險監測的實踐為例,分析數據采集、數據治理和人工智能在推進金融監管工作上的作用,提出五位一體監管理念,數據來源多樣化,數據治理引導數據資產化的發展建議。
[關 鍵 詞]大數據? 人工智能? 金融監管? 數據治理
[中圖分類號]C91;F830.9? ? [文獻標識碼]A? ? [文章編號]1008-7672(2018)06-0066-12
一、 大數據金融監管的背景
近年來,信息技術飛速發展,“大數據”成為當下最流行的概念之一,人們利用大數據的可用信息提升服務的質量。
大數據的出現可以具體解釋為以下兩點:其一,目前大多數活動都會生成低成本且有利用價值的數據;其二,數據驅動型決策是更好的決策,簡單、直接,使用大數據可以讓管理人員根據數據(證據)而不是直覺做出決定。隨著移動互聯網、物聯網、社交網絡等技術和應用的興起,全球范圍內數據量迅猛增長,大數據時代已經來臨。
Nature于2008年第一次推出Big Data專刊。Science在2011年2月推出專刊Dealing with Data,主要圍繞著科學研究中大數據的問題展開討論,說明了大數據對于科學研究的重要性。麥肯錫研究院(MGI)則于2011年6月發布名為《大數據:創新、競爭和生產力的下一個前沿領域》(Big data: the next frontier for innovation, competition, and productivity)的研究報告,對大數據的影響、關鍵技術和應用領域等都進行了詳盡的分析,并指出大數據將會是帶動未來生產力發展和創新以及消費需求增長的指向標。2012年3月美國奧巴馬政府發布了《大數據研究和發展倡議》(Big Data Research and Development Initiative),投資2億以上美元,正式啟動“大數據發展計劃”,計劃在科學研究、環境、生物醫學等領域利用大數據技術進行突破。該報告指出,大數據已進入膨脹期,并將在未來2-5年進入發展高峰期。2016年,國際商業機器公司(IBM)指出,每日的數據生成已達2.5艾字節(2.5 Exabytes),即當下各種新興技術活動都產生了大量相關的新鮮數據,同時,這些數據不僅是在不斷更新的,而且是龐大的。目前,“大數據”概念已開始根據5Vs模型進行定義,即容量(Volume),采集、存儲和計算的數據量都非常大;速度(Velocity),數據增長速度快,處理速度也快,時效性要求高;種類(Variety),種類和來源多樣化;價值(Value),從數據中提取有價值信息的過程,稱為大數據分析;真實性(Veracity),數據的準確性和可信賴度,即數據的質量。
金融行業對數據分析依賴性較強,各類金融監管主體會向其所主管領域的金融機構索取大量的數據用于監管。將數據應用于金融監管活動、運用數據在金融監管中做出決策并不是一個新生事物。金融業是一個典型的信息密集型產業部門,大量信息都以種類各異的數據形式被記錄、儲存和交換,比如銀行業,就有海量的儲戶個人信息、申請貸款的企業的經營信息數據、銀行自身的投資以及動態變化的各類資產負債數據等。對這些數據的分析成為商業銀行自身經營決策以及金融監管部門實施監管的基礎。長期以來,歐美國家大型跨國金融機構非常重視利用先進的信息技術和自身的數據資源拓展業務。
那么大數據又將會給金融領域帶來怎樣的影響?隨著云計算的出現以及數據挖掘等大數據技術的日益成熟,以歐美國家大型商業銀行為代表的傳統金融機構已率先走在了大數據實踐探索的前沿,如基于大數據分析實施更加精準的風險管理和市場營銷策略、為客戶提供更加個性化的金融服務等。伴隨互聯網金融的加速發展、利率市場化的快速推進、資本約束的日趨強化,金融市場呈現出業務廣、差異大、創新多的新特點與新趨勢,金融業面臨的風險在不斷加大,僅僅對金融監管機構管理模式進行改革已不能完全適應互聯網金融時代的監管需要,這就迫切要求建立“大數據金融監管平臺”來有效助力金融監管模式創新。依托大數據、智能化的監管一體化平臺與決策體系服務金融市場的發展,使金融監管的大數據應用真正轉變為金融業的效益優勢、效率優勢和競爭優勢。大數據將為金融監管提供新的平臺與模式,對金融監管的完善與發展具有一定的積極意義。
翟偉麗闡述了金融體系在大數據時代的重構問題,指明在大數據時代金融市場將真正融入實體經濟、居民的生活和工作當中。將大數據應用于金融市場將能夠促進資源的有效配置,降低成本,提高效率。由于參與者的行為得到了充分記錄,信用評價和征信體系變得更加有效,大數據的預測能力也將改變風險管理和決策的模式。綜合化、一體化的服務將加大數據金融服務的邊界,同時精細化和個性化服務程度的加深將使得大量貼身服務模式開始出現。王達根據大數據方法在美國宏觀審慎監管領域的應用,指出信息密集型的金融產業部門已經走在大數據浪潮的前沿;全球金融危機爆發后美國金融監管當局認識到彌合“數據缺口”的重要性。大數據的理念和技術為美國金融監管當局監測系統性風險提供了新方向,對加強系統性風險形成機制研究,進而更加有效地實施宏觀審慎監管具有非常重要的意義。Edward W. Sun等利用金融大數據來分析美國股票的價格動態, 研究了市場微觀結構對建構收益率波動模型的影響。Paolo Giudici描述了金融數據科學的概念,并提出“相關網絡”(correlation networks)數據科學模型,它可以在金融科技(Fintech)發展進程中發揮重要作用。在紐約大學理工學院(NYU-Poly)召開的大數據金融會議上,美國商品期貨交易委員會(CFTC)的代表斯科特·奧馬利亞( Scott OMalia)表示,CFTC曾考慮如何實現有效監管,主張讓監管機構主動出擊,對金融交易商的算法進行科學認證;在實踐中,利用算法采取的魯莽行為帶來更大的破壞,甚至超過傳統的操縱市場行為。勞倫斯伯克利國家實驗室擁有強大的超級計算能力和獨特的雄厚分析技術,能夠做到針對威脅穩定的交易行為采取實時監控傳統的停市機制只能在市場暴跌后采取措施,停止全部交易,而大數據實時監控能夠精細調控,將單個不規范的參與者清除,從而繼續向誠信的參與者開放市場。
二、 大數據金融監管涵義
在使用大數據的理念和方法下,實施監管的基本原理可以概括為:在可獲得的微觀金融數據的基礎上,使用數據挖掘、機器學習、數據可視化分析等大數據技術,對系統性風險進行量化;通過尋找和監測與系統性風險高度相關的指標這一方法,實現對系統性風險的預測和審慎監管。
首先,大數據為金融監管過程提供了新的信息分析手段。大數據大的體量且多維度的數據及對數據的科學性分析,使金融監管更直觀、準確。它在投資資格認定、打擊內幕交易、加強審查等多個領域具有應用意義。
其次,在大數據時代,金融監管有了新的風險管理手段,且這樣的監管更為精確。在傳統的金融監管過程中,金融監管部門通常為整個行業或某一個領域制定一個統一的監管規范,缺乏個性化監管的理念,不考慮被監管主體的差異性。而大數據的相關性分析,可以盡可能彌補此問題。
大數據不是要求事前對系統性風險的形成機制做理論假定,而是通過對盡可能獲得的金融數據而非抽樣樣本數據進行即時和動態分析,實現“讓數據說話”(Let data talk)。
在傳統的研究中,Crockett和 Borio等的早期研究將系統性風險分為時間維度(Time Dimension)和截面維度(Cross-sectional Dimension)。Bisias等提出美國財政部金融研究辦公室從監管、 研究和數據三個層面系統總結歸納了目前量化系統性風險的31種方法,并將其分為宏觀經濟度量法、微觀組織與網絡度量法、前瞻性風險度量法、壓力測試度量法、部門交叉度量法以及流動性與清償危機度量法6大類。
金融機構識別和金融產品識別系統是美國金融數據基礎設施建設的重要組成部分。這就要求人類的認知能力和計算機軟件處理海量數據的能力相結合。借助可視化分析技術,研究者能夠從類別龐雜、數量巨大的微觀數據中以圖片的直觀形式迅速、有效地獲得所需的信息,并通過互動界面對數據進行過濾、分割以及組合等操作,將這種信息轉化為可應用的知識(Actionable Knowledge),從而更好地為政策制定提供參考。但是Flood等指出,包括數據可視化分析方法在內的任何一種方法都不是完美的,研究者的認知和判斷始終在分析(系統性風險)過程中占據重要位置。
自2008年金融危機以來,全球金融體系發生了結構性調整。將大數據方法應用于金融監管,較好地契合了此發展。因此,以美國為代表的主要發達國家都非常重視對宏觀審慎監管的大數據方法的研究和探索,并旨在實現三個目標:第一,加強截面緯度的宏觀審慎監管。已有研究通常將系統性風險劃分為時間緯度和截面緯度,其中截面緯度指特定時期風險在金融體系中各金融機構之間的分布狀況和相互作用。第二,增強市場透明度,揭露監管盲區,提升對影子銀行體系的監管力度。第三,降低金融機構的數據成本和操作風險。
三、 政府對金融監管的政策指引
互聯網的興起不僅改變了人們的生活方式,也影響到行業的發展。金融行業逐步網絡化并深入發展,隨之而來的互聯網金融監管工作任務艱巨。從2015年開始,政府相關部門發布了一系列關于互聯網金融監管的指導意見。2015年7月,中國人民銀行、工業和信息化部、公安部、財政部、國家工商總局、國務院法制辦、中國銀行業監督管理委員會、中國證券監督管理委員會、中國保險監督管理委員會、國家互聯網信息辦公室聯合發布了《關于促進互聯網金融健康發展的指導意見》。
2016年2月4日,國務院發布的《國務院關于進一步做好防范和處置非法集資工作的意見》提出要充分利用互聯網、大數據等技術手段加強對非法集資行為的監管,包括事中事后的監管和事前的風險排查與預警,以控制這一問題發展的趨勢。
2016年3月5日,在第十二屆全國人民代表大會第四次會議上,國務院總理李克強在政府工作報告中提出要深化金融體制改革,“實現金融風險監管全覆蓋,整頓規范金融秩序,嚴厲打擊金融詐騙、非法集資和證券期貨領域的違法犯罪活動,堅決守住不發生系統性區域性風險的底線”。
2016年4月,在前述互聯網金融健康發展指導意見的基礎上,國務院在10月發布了《互聯網金融風險專項整治工作實施方案》,其中重點整治問題和工作要求第一條就是P2P網絡借貸和股權眾籌業務,規定了P2P網絡借貸平臺應該守住的法律底線和政策紅線。
2015年7月,國務院辦公廳印發的《關于運用大數據加強對市場主體服務和監管的若干意見》提出要運用大數據加強和改進市場監管。其中關鍵就是健全事中事后監管機制,要“構建大數據監管模型,進行關聯分析”,還要“對企業的商業軌跡進行整理和分析,全面、客觀地評估企業經營狀況和信用等級”,旨在利用大數據技術收集和追蹤企業的經營信息,并以此為依據掌握企業的情況,防范風險的發生。
2015年8月國務院印發《促進大數據發展行動綱要》指出大數據的發展和應用雖然已經有了一定的基礎,但政府在開放數據、頂層設計和規劃等方面還存在著不足,建設并不完善,潛力沒有發揮出來。綱要明確了大數據的發展形勢和重要意義,系統部署了大數據發展工作,明確指出了將數據共享列為下一步大數據發展的主要方向。
2017年1月國務院在發布的《“十三五”市場監管規劃》中也強調要加強大數據監管,提出要“充分運用大數據等新一代信息技術,增強大數據運用能力,實現‘互聯網+背景下的監管創新,降低監管成本,提高監管效率,增強市場監管的智慧化、精準化水平。”該規劃還強調了要建立風險預警機制,要“運用大數據資源科學研究制定市場監管政策和制度,對監管對象、市場和社會反應進行預測”。
四、 數據治理輔助決策框架
基于理論研究和實踐經驗,本文在政府機構已經擁有了一定共享數據基礎上,充分利用大數據技術輔助政府進行決策,提出如圖1所示的框架。該框架包括數據來源、數據治理、數據計算和交互展現四個部分,體現在以下三個方面:
一是數據來源的多樣,具有互聯網屬性。在國家對數據的重視之下,政府內部資料數據庫和業務數據庫的建設已經有了一定的成果,是十分重要的數據資產,但共享平臺能提供的信息維度仍存在不足。框架中選取互聯網數據和第三方數據作為數據來源的補充,充分整合全面、多樣的信息,作為政府決策的依據。
二是依托于先進技術的數據治理和數據計算能力。數據治理技術能夠對大量原始數據進行有效的存儲、清洗等工作,從中篩除無效信息、理清雜亂信息,提取出真正有價值的內容,用于進一步分析得出結論。此外,先進的算法能夠讓機器做出智能的判斷,代替耗時、主觀的人工勞動,提升政府工作的效率和準確性。
三是交互界面用于人機交流。一方面,政策制定者或者利益相關者可根據自己的不同需求向機器發出需求,通過合理的交互形式快速、有效地獲取自己需要的信息;另一方面,在智能系統運行的過程當中,人可以根據實際工作執行的情況不斷向系統提供反饋和修正,從而實現真正的機器智能學習。
下文以上海自貿區P2P企業風險評估的案例為范本,展示大數據技術和數據治理是如何依托框架服務于金融監管工作。
五、 上海自貿區P2P企業風險評估實踐
中國(上海)自由貿易試驗區(下文簡稱“自貿區”),是中國政府設立在上海的區域性自由貿易園區,位于浦東境內,2013年9月29日正式成立,是黨中央、國務院在新形勢下全面深化改革和擴大開放的戰略舉措。自貿區的主體部分是綜合保稅區片區,擴展區域還包括陸家嘴金融片區、金橋開發片區和張江高科技片區。
自貿區建設5年多來取得良好的發展,2017年4月,國務院下發《全面深化中國(上海)自由貿易試驗區改革開放方案》,提出其建設目標是到2020年成為領先的、國際高標準自由貿易園區。其中健全、便利的貿易監管服務體系,有效防控風險的金融服務體系、現代化的政府管理體系都是重點建設內容。
近年來,中國傳統金融業逐漸進入到了一個加速向互聯網模式轉型運營的階段,出現了多種多樣的互聯網金融創新模式,與傳統金融機構開展多元化合作與競爭。在互聯網金融興起的潮流和準入政策寬松的大環境下,P2P網絡貸款企業大量涌現,規模小而分散,業務模式層出不窮,各種企業魚龍混雜,給監管的轉變帶來了很大挑戰。
截止到2017年1月,國內P2P平臺共上線5881家,其中3514家出現問題,給投資者造成巨大損失的同時,也嚴重影響了國內互聯網金融的行業氛圍。在自貿區內各種高風險的市場主體行為中,網絡借貸P2P企業存在的風險尤為突出。
然而目前監管部門缺乏對問題平臺有效的監測工具。企業存在的風險和疑點往往就隱藏在平臺資料、交易數據、新聞報道、網民評論這些數據之中,而目前的監管部門只能依靠人工搜索這些互聯網數據,再結合現場勘查來發現互聯網金融犯罪的疑點,不僅耗時耗力,排查的企業數量和范圍也十分有限,難以真正實現大規模P2P企業風險監測的目的。如何節省人力成本,提高監管效率,成為P2P企業風險監管當下的難點。
P2P作為互聯網金融的一種新型模式,與之相關的企業工商信息、經營動態信息、產品信息、人員信息、政策輿情等各種數據分散在政府職能部門內部和企業官網、第三方平臺、各大新聞門戶、主流論壇等互聯網媒介中。為了準確判斷風險,需要將這些分散的數據采集、匯總、關聯形成大數據的生態環境,形成對企業多視角、多維度的描述,形成更清晰、更全面的企業標簽。本文以自貿區的金融監管項目為實例,介紹在共享平臺和公開數據的基礎上,如何利用大數據技術輔助金融監管、幫助政府決策,為大數據在“互聯網+政務”中的應用。
(一) 政府數據共享與服務平臺
為了實現各級政府管理部門間信息系統互聯互通、信息資源共享互換,自貿區啟動建設了信息共享和服務平臺項目。平臺架構如圖2所示。該平臺的核心是通過建立政府監管信息共享機制,打破部門間的信息壁壘,以建設“政府大數據中心和信息交換樞紐”為基礎,整合匯集監管信息傳遞、投資準入服務、部門條線管理和企業網上辦事等服務功能。
該平臺建立的目的是改變管理部門長期存在的各自為政、效率低下的現象,為更優質便捷的自貿區綜合監管與協同服務體系提供基礎性支撐。
(二) 共享數據與互聯網數據的融合
(1) 數據來源
通過對行業知識的分析,將P2P平臺出現問題的原因總結為兩方面:先天存在不足和后天發展出現問題。前者是在平臺創立之時就已經確定的因素,包括注冊資金不足、創始人信用不可靠、所處城市資源和發展空間不足等;后者是在平臺發展的過程中出現的問題,包括過度鼓吹利率而無法兌現、風險控制不過關造成大量逾期、缺乏投資者導致資金鏈斷裂、金錢利益誘發的違法犯罪等,與前者相比,這類因素具有動態、不確定性的特點。
在擁有政府共享平臺與服務數據的基礎上,為充分捕獲與P2P平臺風險相關的數據,補充共享平臺數據的欠缺和不足,需要通過互聯網數據采集的手段來擴充數據維度和內容。而互聯網上的信息紛繁復雜,在企業信息數據源的選擇上,需要做到全面和適當的信息抓取。將上述分析所得的風險原因對應到具體的平臺特征,可以分為靜態特征、動態指數、動態新聞、動態評論四類。
靜態特征,即平臺的先天因素,包括平臺的性質和類別、平臺標簽、上線時間、注冊資金、所在城市、投標保障、保障模式、擔保機構、人員信息等。動態指數,即平臺的業務和交易信息,包括平臺成交量、利率、歷史待還、資金凈流入、投資人數、借款人數、借款標數、平均借款期限、標的金額分布等。動態新聞,是平臺發展過程中相關的新聞報道,需要抓取的內容包括新聞出現時間、報道平臺、報道內容等信息,從中提取出報道的規模、報道平臺的特征、企業口碑情況(正面、負面報道的數量和比重)、涉及的主題和關鍵詞等。動態評論,即平臺發展過程中相關民眾主動在網上發布的評論信息,需要抓取的有評論內容、評論時間、評論來源等,從中提取出評論信息量、評論情感傾向、用戶畫像、輿情標簽等。
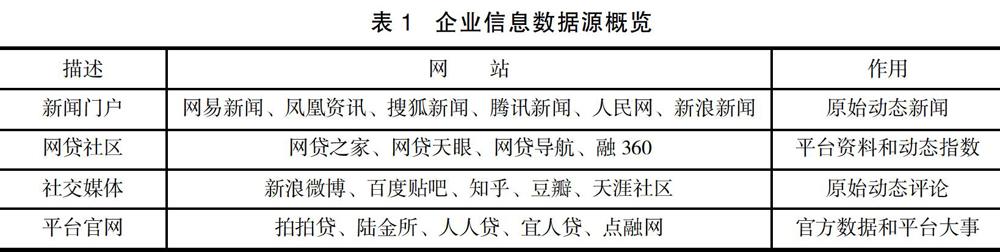
基于以上分析,選取一些國內公開網站作為數據源,包括主流新聞門戶和社交媒體、活躍的網貸社區和各大P2P平臺的官方網站,從盡可能多的維度來挖掘P2P平臺的風險信息,具體來源如表1所示。本文采集到的數據規模較大,僅企業備案網站就有1500多個,而社交媒體上的評論則達萬余條。
(2) 數據治理
由于獲取到的數據來源不同,結構和組織方式也不同,需要對這些數據進行適當的存儲、清洗和計算,才能夠進一步地用于使用和分析。數據治理中清洗、去重、降噪等處理工作是數據分析結果準確與否的關鍵環節,但是往往花費整個工作流程超過80%的時間和人力資源,且當原始數據質量較差時,這一時間還將延長。
本文涉及的數據具有兩個挑戰。一是非結構化數據多。從互聯網上采集到的企業輿情信息屬于非結構化數據,大量的信息點隱藏在大段的文字之中,需要先轉化為結構化數據,才能用于后續的數據處理。這里用文本分析技術,包括自然語義理解、監督式機器學習等,將埋藏在文本中的信息點提取出來進行重構。二是數據多源異構性。所采用的數據既有共享平臺中與企業相關的登記和關聯數據,也有從幾千個網站采集得到的互聯網數據。其中互聯網采集數據具有明顯的多源異構特征,每個網站采集下來的數據的內容、維度、表述方式均有異同。這就需要通過大數據治理系統利用機器學習和人工智能的方法,結合業務專家的參與,構建行業關鍵詞標簽庫,對大量網站采集得到的數據進行理解和關聯。
本文采用大數據治理系統來解決這個問題,其功能包括:利用Hadoop實現對大批量數據的快速存儲和計算,通過數據輪廓了解數據的基本情況,對無效信息進行數據清洗,基于大數據治理的4C原則即編目(Catalog)、關聯(Connection)、管護(Curation)和使用(Consume)對數據進行進一步的有效分析。
(三) 人工智能應用P2P企業識別和風險判斷
(1) P2P企業自動識別
采用機器學習模型,利用經過人工標注的P2P網站作為學習樣本,自動建立一套P2P網站內容的特征庫和語義集,自動識別網站內容與P2P業務的相關性,從而實現對這類企業的自動篩查。
(2) 企業知識圖譜
知識圖譜是一種知識表示的形式,用節點表示實體、用連接節點的邊表示實體之間的關聯,其中邊可以是有方向或無方向的。根據知識圖譜的相關技術,把基于P2P企業相關的所有信息繪制成以企業名稱為中心的知識圖譜,包含企業基本信息、企業對應的P2P平臺信息、企業法人/股東關聯等。引入知識圖譜的理論和技術,為P2P網貸企業構建知識圖譜,并利用該圖譜和其中的關聯關系作為企業風險防控的特征指標之一。
通過知識圖譜的方式,可以探索各企業之間的關聯和相似度,關聯度大的節點之間風險程度也互相聯系。平臺如果出現基本信息缺失的情況,即沒有與相應類別的節點關聯,或者和已知的問題平臺相似,都有可能存在大的風險。例如企業A已經被發現是高風險的P2P企業,這時候倘若通過圖譜發現企業B和企業A之間有相同的企業法人,或者是有十分相近的標簽和性質信息,此時企業B的風險程度也就成為了值得關注的對象。
(3) 輿情情感判斷
互聯網上存在著大量繁雜的信息,同樣是對于企業的評論,其內容質量和情感傾向都良莠不齊,如果要有效利用這些評論信息,必須采用人工智能的方法對它們進行判斷。
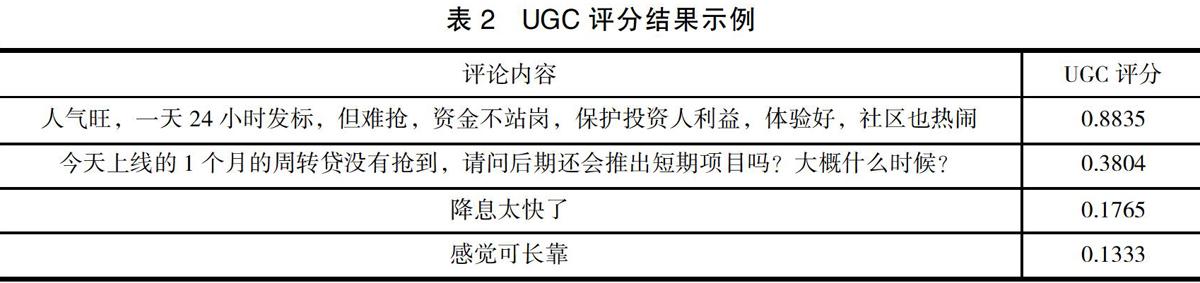
在新聞報道中,存在著大量重復和類似的報道。在網民評論中,也存在著很多信息含金量低的評論。本文使用了UGC(User Generated Content)算法,依據網民評論內容中的信息密度、情感傾向、用戶權重對其評論做出0-1之間的評分,得分越高的評論信息含金量越高。摘取了互聯網上一些評論實例,根據算法得到的評論如表2所示。可以看出,提及維度多的評論(同時提及人氣、搶標難度、資金情況、體驗、社區氛圍等)評分會較高,而內容單一籠統的評論評分則會較低。
情感分析(Sentiment Analysis)是輿情分析中關鍵的人工智能技術,是指挖掘文本所表達的情感傾向性和其背后的用戶態度。例如表2所示的評論中,“人氣旺,體驗好”就是表達了用戶對這一金融平臺肯定的態度。利用這一技術,通過對新聞報道和網民評論進行情感分析,可以獲悉媒體和公眾對P2P平臺所持態度偏向。負面的新聞是媒體在向民眾傳遞該平臺不可靠的信息,而公眾所表達的負面情感則是其他投資人的警示和借鑒,因此,情感分析技術得出的具有高負面情感度的平臺,往往意味著平臺的風險也要高于其他的平臺。本文訓練了一個半監督遞歸自編碼器模型用于情感分析,將所獲取的新聞和評論分為正面和負面兩類,從而得到各個平臺以天為粒度的正面以及負面新聞和評論數量,即動態新聞和動態評論中與正負情感有關的特征。結合評論評分和情感分析的結果,就能最大限度地利用互聯網上網民評論的信息,對有關企業的風險情況做出判斷。引起了大量有效負面的企業,理應作為監管中值得注意的目標。
(4) 基于深度學習進行風險指數量化
給定P2P平臺的特征集合,包括靜態特征集、動態指數特征集、動態新聞特征集、動態評論特征集,同時給定各個平臺的風險標簽,100表示平臺正常運營,0表示為問題平臺。平臺風險量化定義為,以特征集合為輸入并輸出風險量化評分,該評分介于0-100之間。
風險量化值應當滿足以下三點性質:
第一,選定某個合適閾值,量化值大于該值的應盡可能為正常平臺,小于則盡可能為問題平臺;
第二,正常平臺的量化值應盡可能高并接近100,而問題平臺則盡可能低并接近0;
第三,將所有平臺按量化值從高到底排列后,越靠前的平臺中存在的問題平臺應盡可能越少。
因此,P2P平臺風險量化本質上是一個有監督的二分類問題,以上提出的三點性質可以作為模型性能的評估標準。為了從多維異構的平臺特征中全面準確地融合出風險信息并進行評分,本文提出了基于深度學習的模型。
深度學習在近幾年的研究中得到了蓬勃的發展和廣泛的關注,隨著GPU性能的提升實現了進一步的普及,在自然語言處理、模式識別、語音識別和信息處理等領域表現尤為卓越。深度學習模擬人腦的思維模式,能夠通過深層網絡抽象出更為高層的概念并進行決策,而這正是監管者從紛繁復雜的數據海洋中概括有用信息所需要的能力。本文模型中采用多種深度學習模型組合成的神經網絡來處理不同形式(單個值或值序列)和不同類型(數值、類別值、文本)的輸入特征,進行全面精確的P2P平臺風險量化并生成評分和排名。數值特征可以直接輸入到模型中,類別值特征需要經過One-Hot處理轉換成0-1向量,文本特征則通過Word2Vec模型轉換成詞向量并輸入。
限于篇幅,對數據和模型不詳述。作為驗證,從互聯網采集了全國3050家平臺數據,時間跨度從2014年1月至2016年3月,所有采集的數據開放,同時開源了上述深度學習模型。從2015年11月至2016年4月的6次預測中,模型對問題平臺的預測始終保持較高的準確率,達到85%。
(四) 案例成果分析
(1) 企業篩查結果
本案例中涉及的企業數量有約40000家,其中金融相關企業有10000余家。經過建立風險模型、并對風險情況進行了指數鑒別,最終篩選出確定P2P的企業數量150家,其中高風險企業35家,另有疑似P2P的企業數量137家。
(2) 業務監管功能交互平臺
為了更加直觀便捷地展示自貿區P2P企業信息、便于工作人員搜索查詢企業資料從而進行業務監管工作,本文實現了業務監管功能交互平臺,在全面地展現監測和評估結果的同時,方便監管部門進行實時搜索查詢,進行高效監督和管理。
平臺涵蓋以下模塊:賬號驗證登陸模塊、搜索模塊、企業列表模塊、企業詳情模塊、風險預警模塊、監管交互模塊、行業概覽模塊和系統管理模塊。賬號登陸部分設置了權限管理,針對不同的用戶群實現頁面內容區別化呈現。搜索模塊有多個篩選維度可供查詢。企業向西部分可視化地采用圖形、圖表、圖譜等方式呈現了詳細信息和風險指數等。平臺在全面展示模型分析結果的同時,還提供多種互動交互功能,支持用戶對展示企業添加標簽、標注、評論、信息補充、模型分析結果反饋等。
除去展示功能外,平臺提供了人工反饋的入口。工作人員在使用該平臺的過程當中,可以將業務工作中的信息反饋輸入進去,例如添加標簽、修改完善風險信息等。基于人工智能技術,機器在得到反饋后能夠修正算法的準確性,從而真正實現輔助業務監管的智能化。
(3) 效益分析
本文通過充分利用共享和公開數據,加上大數據與人工智能技術予以輔助,給自貿區金融監管工作帶來了效益與參考價值。
給自貿區帶來的效益體現在以下幾點:
一是優化數據管理,實現數據資產化。通過搭建大數據治理系統,結合保稅區內部數據和通過各種渠道采集的外部數據,打通數據間的壁壘,實現數據關聯互通,消除信息孤島,并借助大數據治理系統優化數據管理模式和流程,實現保稅區數據資產化,進一步幫助政府部門做到管好數據、用好數據,擁有數據資產。
二是大幅度提高工作效率,實現業務智能化。利用內部數據和外部采集的大量數據構建保稅區企業信息庫,通過機器學習的技術學習P2P企業的特征,自動篩查出涉及P2P業務的企業,將以前人工排查的方式轉變為機器自動排查后將重點標注企業提交人工審查。機器代替人力完成最大量最繁瑣的初步審核階段,同時還提供了對審核結果風險程度的量化,減少了人的工作量,使得同樣時間內人工處理數量、質量同時上升一個檔次;從效率來講,不僅節省了時間和人力,而且提高了結果的準確性和一致性,讓部門的決策更實時、更快速、更有依據。
三是量化P2P企業風險,讓數據成為監管、上報和決策依據,實現監管科學化。通過對P2P企業風險量化評分以及對風險級別的評價,幫助監管部門針對不同風險級別的企業實施相應的監管措施,合理進行資源分配,提高監管效率,實現以數據為支撐的、科學的監管模式。
六、 大數據驅動金融監管發展的建議
運用大數據進行監管實踐具有十分重大的理論與現實意義。通過大數據進行監管打破了傳統的金融監管方法,為金融監管部門提供了新的視角;同時,大數據金融監管利用大數據5V特點,很大程度上提高了金融市場有效性。大數據金融監管對大數據相關領域有較強的借鑒意義。在此發展中,需要注意以下四個方面。
(一) 樹立五位一體監管理念
自十八大以來,黨中央提出了四個全面的戰略布局,強調以創新、協調、綠色、開放、共享的發展理念,深化政治體制改革、轉變政府職能、實現治理現代化,打造法治政府、創新政府、廉潔政府和服務型政府。互聯網在落實轉變政府職能、深化政務公開、推進放管服務改革和政務服務等方面發揮出日益重要的作用。合理有效的監管需要明確的監管理念作為指導。五位一體的監管理念是指監管需要有連接、整合、共享、聯動、參與五環節互通融合。具體是部門之間的有效連接,多源異構信息資源的合理整合,多元主體的信息資源的共享,流暢的跨部門的聯動,多方參與服務。
新一代的信息技術手段越是先進,越是要求提高環境整體的聯動性。不僅要求政府工作人員有較高的信息技術應用能力,同時還要有與之相適應的系統思維的理念,要求政府各部門之間打破條塊分割,實現部門間的協同工作和數據的自由流動,進行彼此無障礙的溝通,政府要在城市管理過程中更好發揮職能作用,共享和整合數據,完善信息技術、情景和人之間的交互,真正實現電子包容。
(二) 以流程為導向
《“互聯網+政務服務”技術體系建設指南》明確提出按照“堅持問題導向、加強頂層設計、推動資源整合、注重開放協同”的原則,以服務驅動和技術支撐為主線,圍繞“互聯網+政務服務”業務支撐體系、基礎平臺體系、關鍵保障技術、評價考核體系等進行。傳統的政府業務流程是圍繞“職能”與“計劃”來展開,對公眾的訴求缺乏了解和回應。需要變“職能導向”為“流程導向”。信息化的基礎管理中心在流程上,通過整合業務,形成職能間的有機聯系。以服務流程、支持流程、管理流程三個維度為支撐,降低協調成本,突出整體目標,實現整體效率最大化。服務流程是面向公眾的流程,主要為公眾提供公共產品和公共服務。支持流程位于政府內部且服務于服務流程,主要為政府內部提供產品、服務和信息。管理流程為服務流程和支持流程之間的橋梁,實現兩者最大程度的匹配。打破原有分工理論的束縛,注重整體流程最優的系統思想。以流程為導向最大限度地集成政府管理和服務功能,而后根據流程消除純粹的中間環節,實現內部的有效溝通,這不僅降低了管理費用和成本,而且提高了組織的運轉效率。
(三) 決策數據需多源化
目前正在大力推行的政府共享服務平臺為政府管理和決策科學化提供了堅實的基礎,但在數據源的完整性方面還存在一些不足。
共享平臺的數據具有稀疏性。組織內部的數據只涵蓋了管理中產生的數據,在實踐中有些維度的信息是缺失的,或者無法通過常規渠道獲取到。比如自貿區信息共享平臺只涵蓋了部分工商信息和一些部門信息,為了進行有效的風險預警,需要建立基于數據的預估模型,而數據的大量缺失和維度的不足會導致模型產生偏差因而性能降低。
共享平臺的數據具有局限性。比如本文中共享平臺數據來源主要是政府部門積累的企業登記信息和對企業實施監管的數據記錄,缺乏與企業實際經營業務、經營狀態、輿情評價相關的數據,在數據的維度上十分有限。企業登記信息和監管信息是企業資料的基礎,卻不能充分地反映企業在實際運營過程中的表現,而后者對于企業的評價和評估則是重要的依據。互聯網上有很多與P2P相關的網站平臺,涵蓋了與業務相關的大量信息,將這部分數據與共享數據融合補充,對金融監管工作會頗有益處。
共享平臺的數據具有滯后性。滯后性體現在數據是已經完成的工作成果,適用于事中事后的監管,難以起到快速及時的事前預警和風險預估的作用。在現實生活中,對企業風險信息反應最敏感的則是投資人,而這部分信息主要體現在互聯網上,體現在網民對企業的評論當中。
因此,除去共享平臺與服務數據之外,獲取互聯網的數據作為補充,尤其是民眾自發產生的數據,在金融監管的工作中十分必要。
(四) 運用數據治理,實現數據資產化
數據治理是對數據管理行使權力和控制的活動集合,包括規劃、監督和執行。數據治理功能需要體現在快速地完成數據清洗、去重、去噪等預處理;對數據中多張表進行關聯、融合;自動提取關鍵字段、降低數據維度;時空數據處理等。通過數據治理達到價值實現、運營合規和風險可控。經過利益相關人分析和溝通,建立統一的數據價值的理解,指導價值實現相關要素的定義、應用、調整,并持續開展對價值實現過程的評估、指導和監督,以滿足利益相關方對數據治理的收益和價值預期。建立符合法律、規范和行業準則的數據合規管理體系,并通過評價評估、數據審計和優化改進保證數據的合規,促進數據價值的實現,實現數據資產化。應建立、評估數據風險管理機制,確保數據風險不超過組織的風險偏好和風險容忍度,評估、指導和監督風險管理的實施。
數據資產化是指數據可管理、可度量、可運營。可管理包括形成資產目錄、標準化過程、全周期質量管理、可信安全管理。可度量包括資產數量、資產價值、資產成本、資產健康度的精準度量和分析。可運營包括資產監控和報告、成本評價和控制、質量提升流程和激勵機制。通過數據資產化,實現數據服務化和數據價值化。
政府作為擁有海量管理和服務數據方,對已有的數據和多來源數據需要進行數據治理,從而實現資產化過程,進而數據資源可成為第四類資產。
Research on Finance Supervision under Big Data—Based on Enterprise Risk Monitoring Practice in Shanghai Free Trade Area
ZHU Lin1,? JIN Yaohui2
(1. Social and Public Administration School of East China University of Science and Technology, Shanghai200237, China; 2. School of Electronic Information and Electrical Engineering,
Shanghai Jiaotong University, Shanghai? 200240, China)
Abstract:Application of big data in finance monitoring is faced with opportunity and challenge in the age of “Internet+” era. This research proposes a framework applying shared and open data to assist government strategy. Based on the practice of enterprise risk monitoring in Shanghai Free Trade Area, this paper also analyzes the role of data collection, data governance and artificial intelligence in promoting finance supervision, and proposes suggestions of “five-in-one” supervision guidance, multiple data source and data capitalization led by data governance.
Key words:big data; artificial intelligence; finance supervision; data governance
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
云南畫報(2020年9期)2020-10-27 02:03:26
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
