采用弧映射的雙層對象分布算法
2018-06-21 08:23:06聶世強伍衛國崔金華薛尚山劉釗華
西安交通大學學報 2018年6期
關鍵詞:一致性
聶世強,伍衛國,崔金華,薛尚山,劉釗華
(西安交通大學電子與信息工程學院,710049,西安)
對象存儲系統由于可擴展和易管理等特點,已經發展成為主流存儲系統架構。常見的對象存儲系統有Red Hat公司的Ceph存儲系統[1]、Facebook的Cassandra存儲系統[2]等。對象存儲系統中對象是讀寫的基本單位。客戶端調用對象分布算法將對象分布到對象存儲設備(OSD)。高效簡潔的對象分布算法可以均衡I/O負載、自適應系統的變化、提高數據可靠性[3]。
對象分布算法是對象存儲系統的核心組件,針對對象分布問題已有很多研究。為了解決對象分布的均勻性問題,提出一致性哈希算法[4]、層次化一致性哈希算法[5]、雙模對象分布算法[6]、Crush算法[7]、分層對象分布算法[8]、隨機切片算法[9]等。為了提高存儲I/O性能和降低數據熱點問題,Xu等提出了EDP算法以保證去重存儲系統中均勻讀[10];Jouini等提出了適用于文檔存儲的副本放置算法[11];Gao等提出了根據數據的訪問頻率分布對象算法[12];Shen等提出了一種應用于BCube網絡拓撲結構的提高數據修復速率的對象分布算法[13];Qin等提出了對象分布算法分別針對糾刪碼存儲中降級讀和寫性能進行優化[14],以上提及的對象分布算法雖然各具特色,但是在對象存儲系統的應用中受到諸多約束,不具有普適性。本文利用存儲系統批量擴容和刪除的特點,設計了弧映射雙層對象分布(TMHR)算法。將同一批次的多個存儲節點劃分為子集群,對象分布過程中,TMHR算法首先采用可擴展的子集群哈希(SHFC)算法選擇存放對象的子集群,其次采用隨機置換算法在目標子集群內計算存放對象的存儲節點。該算法可以在較短時間內計算任意對象的目標OSD節點,保證對象均勻分布,遷移較少的對象以適應OSD節點的動態變化。
1 問題定義
設存儲系統以子集群為單位進行擴容和刪除,擴容、刪除的第i個子集群用Ci表示,其權值用wi表示,wi是子集群Ci內節點容量、性能等特征的量化,根據具體需求賦予權值不同的含義。如以存儲容量為量化標準,則1 TB的存儲節點和500 GB的存儲節點的權值之比為2∶1。Ci擁有的存儲節點數為mi。初始時存儲系統僅包括子集群C0,所有子集群用子集群集合C表示,所有子集群數用k表示。對象數為y(y≥1),每個對象擁有唯一的識別符,對象數理論上無限,且對象數遠遠大于節點數。
2 TMHR算法
利用存儲系統批量擴容、刪除的特性,TMHR算法采用雙層映射模式,存儲節點按照加入系統的批次被分為多個子集群,相同的子集群內節點性能、容量相似。客戶端讀寫對象時只需要從存儲系統獲取當前子集群和節點的描述信息,客戶端在本地完成對象和其存儲節點映射關系的計算,即在子集群間采用SHFC算法以權值為概率選取目標子集群,在目標子集群內采用隨機置換算法等概率選擇目標節點。
2.1 子集群間SHFC算法
基于動態區間映射算法和隨機切片算法兩者都將對象存儲在以區間為單位的邏輯單元中,兩種算法的時間復雜度與區間數均正相關。系統擴容過程中兩種算法都會產生大量小區間,雖然隨機切片算法提出了4種減小區間碎片化的策略,但是區間數仍然較大,極大地影響了系統I/O性能。為了解決系統擴容造成的區間碎片化問題,SHFC算法將對象和子集群的哈希值映射在半徑為R的環形空間,根據子集群的權值將整個環形空間分為相應比例的弧,每個子集群負責存儲映射在弧上的對象,并將最大相鄰弧合并策略應用于系統的擴容、刪除過程。
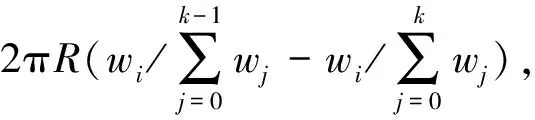
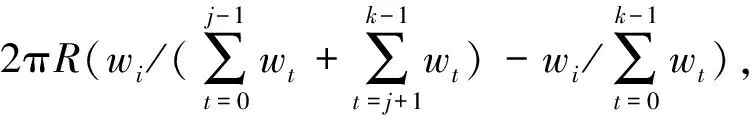
當映射在子集群Ci上的弧序列需要重映射部分弧到子集群Cj時,設需要遷移的弧長為L,設子集群Ci上的弧序列為{a1,a2,…,ae},則最大相鄰弧合并策略會盡可能的從子集群Ci的弧序列中找到多個弧au(1≤u≤e)之和的長度接近L。當需要對存在的弧切割時,切割滿足如下條件的弧,該弧切割后可以與目標子集群Cj的弧合并,同時該弧是所有滿足條件的弧中最長的弧。
存儲系統擴容、刪除子集群后,SHFC算法不需要重新分割整個環形區間,而是更新發生變化的弧和子集群之間的映射關系,這種策略使重映射的弧長度最短,從而使需要遷移的對象最少。
2.2 子集群內隨機置換算法
子集群內的對象分布采用隨機置換算法降低計算時間開銷。隨機置換算法實現了對副本機制的支持,保證同一對象的多個副本均勻分布在OSD節點上。計算對象x的第r個副本存放節點的函數為
f(x,r,m)=(hash(x)+rp)modm
(1)
式中:x是對象的標識符;r是小于m的副本數;p和m都是質數,且滿足p>m。m默認等于子集群Ci(0≤i≤k-1)的節點數mi,但是如果子集群Ci的節點數mi并非質數,則m取大于mi的最小質數。式(1)對序列{0,1,…,m-1}進行隨機置換生成等概率的新序列,對象x的第t(0≤t≤r-1)個副本存放在新序列的第t位。若新序列的第t位序號大于節點數mi,則順次選擇下一位。存儲系統的擴容和刪除等都是批量操作,很少或者幾乎不會出現單個存儲節點加入、刪除的情況,單個存儲節點故障失效后很快會被替換,子集群內的節點數是維持不變的,因此不需要考慮子集群內的節點變化情況。
3 算法理論分析
3.1 公平性和自適應性分析
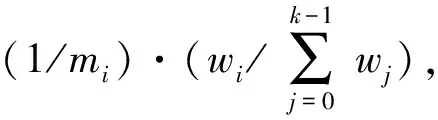
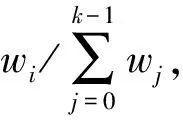
以下證明隨機置換算法滿足公平性。第2.2節中隨機置換算法的核心思想可以用式(1)表示,式(1)可以分解為如下3個運算操作
d=hash(x)modm
(2)
h=rpmodm
(3)
l=(d+h)modm
(4)
式(2)表示以對象x為種子生成隨機數,取模映射在{0,1,…,m-1}整數范圍內,其值為d。式(3)表示以對象的副本為特征值對序列{0,1,…,m-1}隨機置換,文獻[15]指出,如果gcd(b,c)=1,bp≡gmodc并且p是解,那么p一定是唯一解,因此可以得出對象x的副本數r和h存在一一映射關系。式(4)表示將置換后的整數序列循環右移了d位得到l。綜上可得,式(1)以對象x和副本數r為特征值,將序列{0,1,…,m-1}等概率隨機置換生成新序列。若m與子集群Ci的節點數mi相等,則任意節點被選中的概率是1/mi,若m是大于mi的最小質數,重復依次選擇下一位,則任意節點被選中的概率是(1/m)·(m/mi)=1/mi,因此隨機置換算法滿足公平性。
3.2 復雜度分析
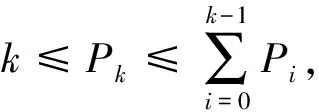

4 實驗對比分析
在計算時間、均勻性、公平性和自適應性4個方面比較TMHR算法、一致性哈希算法和隨機切片算法,實驗的操作系統為ubuntu 14.04 LTS系統,采用python語言實現3種算法。
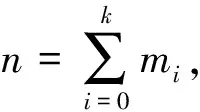
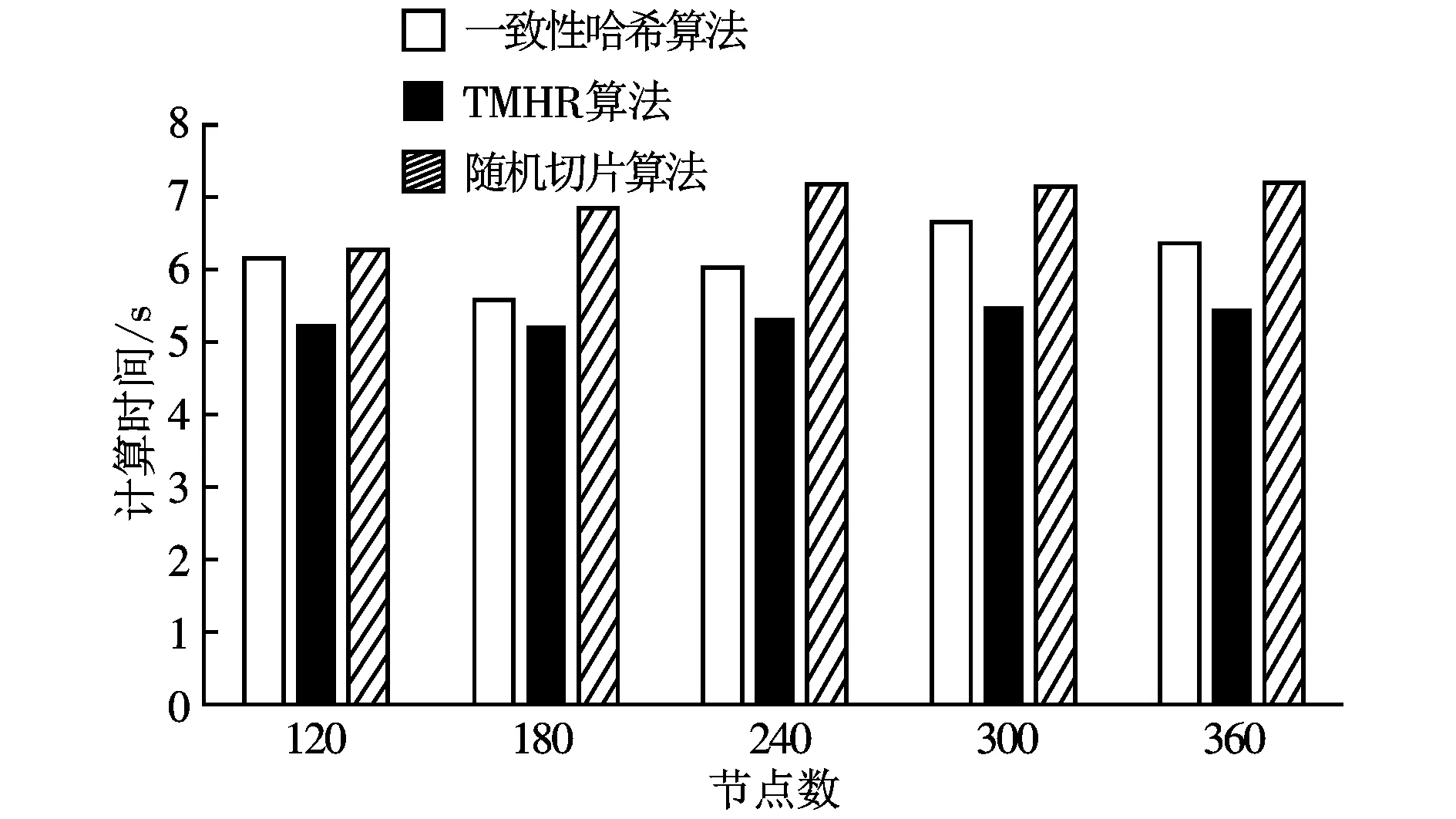
圖1 對象分布時間開銷的比較
圖2給出了將15萬個對象分布到由25個節點組成的存儲系統后的對象分布情況,25個節點共分為5個子集群,每個子集群包括5個節點,子集群與子集群之間的OSD節點是異構的,5個子集群的權值比為1∶2∶3∶4∶5,從圖2可以看出,對象在0~4號子集群內是均勻分布的,子集群間呈現比例分布,也就是說異構環境中對象的分布會隨加入OSD節點特性的變化而變化,因此本文算法是完全適應于異構環境的。
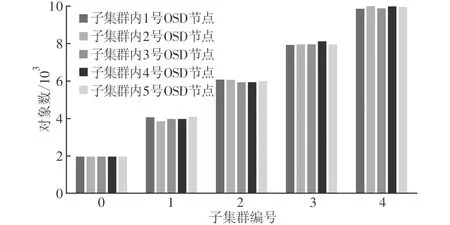
圖2 不同權值OSD組成的子集群間對象數比較
圖3給出了由120~360個節點組成的存儲系統中3種算法分別分布100萬個對象的均勻性比較。從圖3可以看到,TMHR算法和隨機切片算法的方差比一致性哈希算法的方差小,即這兩種算法對象分布的更加均勻,有效保證了存儲節點的負載均衡。TMHR算法和隨機切片算法都可以通過理論證明節點分配的對象數和其權值成正比,并且TMHR算法將對象進行雙層映射細粒度分布,比隨機切片算法分布更加均勻。一致性哈希算法只是將節點、對象隨機分布到環形空間,當數據量較大時對象才能均勻分布,因此其公平性相對較差。

圖3 對象分布算法的公平性比較
實驗模擬比較一致性哈希算法、TMHR算法在存儲系統批量擴容、刪除后對象的遷移量,對象遷移量越少表示算法自適應性越好。圖4、5給出了180個節點組成的存儲系統擴容、刪除后每個節點的對象遷移量。存儲系統中每5個節點為1個子集群。圖4是模擬存儲系統的61~120號節點失效后剩余節點的對象遷移量。存儲系統中預先已分布了100萬個對象,因此理論上可以計算得到在節點刪除前每個節點存儲的對象數為106/180≈5 555個。在節點刪除后,每個節點存儲的對象數為106/120≈8 333個,則被刪除的節點平均遷移2 778個對象到剩余的節點。從圖4可以看出,TMHR算法在1~60號節點和121~180號節點的變化量在2 800左右,實際遷移量和理論值相近,而一致性哈希算法在1~60號節點和121~180號節點的變化量在5 000~6 700左右波動,遷移量較大。此外,61~120號節點的遷移量表示在節點刪除前節點的對象數,可以看出在刪除前TMHR算法的對象分布相對均勻,每個節點都大致分布了5 500個對象,和理論值5 555大致相等,而一致性哈希算法每個節點分布的對象數波動較大,公平性較差。
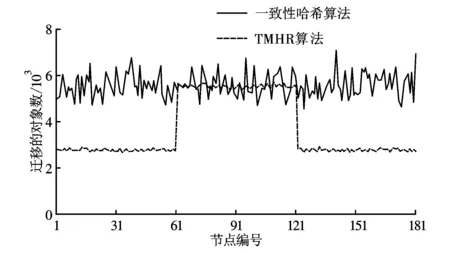
圖4 61~120節點失效后的數據遷移量比較
如圖5所示是模擬180個節點組成的存儲系統加入60個節點后1~180號節點的對象遷移量。系統擴容前每個節點分配的對象數為106/180≈5 555個。在節點增加后,每個節點存儲的對象數為106/240≈4 166個,因此擴容后每個節點都要遷移5 555-4 166=1 389個對象到新加入節點。從圖5可以看出,TMHR算法中每個節點的對象遷移量和理論值相近,且每個節點遷移量也大致相等,而一致性哈希算法對象遷移量波動較大。
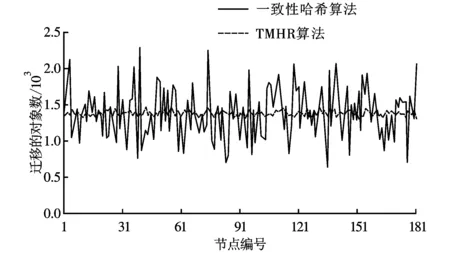
圖5 節點增加后的數據遷移量比較
通過模擬實驗,從圖1~5可以得出如下結論:與一致性哈希算法和隨機切片算法相比,TMHR算法在對象分布時間上分別縮短了20%和28%,較快的對象分布有利于客戶端快速讀寫對象,提高系統性能;實驗結果表明,TMHR算法可以使對象分布的更加均勻,保證系統負載均衡;當系統擴容、刪除后,可以遷移較少的對象以保證對象均勻分布。
5 結 論
大數據時代下,對象分布算法對于對象存儲系統的性能影響更加顯著。目前,大部分對象分布算法無法在公平性、自適應性、高效性和簡潔性取得一定的平衡,很難應用于EB級混合異構存儲系統中。本文提出了一種高效簡潔的TMHR對象分布算法,算法支持權值和副本機制,在具有較低的時間復雜度的前提下,兼顧了算法的公平性、高效性、簡潔性和自適應性。實驗模擬結果表明,與一致性哈希算法和隨機切片算法相比,TMHR算法在對象分布時間上分別縮短了20%和28%,數據的分布也更加接近于理論情況,對象遷移量方面更加接近理論最優值。異構存儲系統中對象分布數量與OSD節點的權值成正比,因此TMHR算法更加適用于異構對象存儲系統。
參考文獻:
[1] WEIL S A,BRANDT S A,MILLER E L,et al. Ceph: a scalable,high-performance distributed file system [C]//Proceedings of the 7th Symposium on Operating Systems Design and Implementation. New York,USA: ACM,2006: 307-320.
[2] LAKSHMAN A,MALIK P. Cassandra: a decentralized structured storage system [J]. ACM SIGOPS Operating Systems Review,2010,44(2): 35-40.
[3] FACTOR M,METH K,NAOR D,et al. Object storage: the future building block for storage systems [C]//Proceedings of the 2005 IEEE International Symposium on Mass Storage Systems and Technology. Piscataway,NJ,USA: IEEE,2005: 119-123.
[4] KARGER D,LEHMAN E,LEIGHTON T,et al. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the world wide web [C]//Proceedings of the 29th ACM Symposium on Theory of Computing. New York,USA: ACM,1997: 654-663.
[5] ZHOU J,XIE W,GU Q,et al. Hierarchical consistent hashing for heterogeneous object-based storage [C]//Proceedings of the 14th IEEE International Symposium on Parallel and Distributed Processing with Applications. Piscataway,NJ,USA: IEEE,2016: 1597-1604.
[6] XIE W,ZHOU J,NOBLE J,et al. Two-mode data distribution scheme for heterogeneous storage in data centers [C]//Proceedings of the 2015 IEEE International Conference on Big Data. Piscataway,NJ,USA: IEEE,2015: 327-332.
[7] WEIL S A,BRANDT S A,MILLER E L,et al. CRUSH: controlled,scalable,decentralized placement of replicated data [C]//Proceedings of the 2006 ACM/IEEE Conference on Super-Computing. Piscataway,NJ,USA: IEEE,2006: 31.
[8] 陳濤,肖儂,劉芳. 對象存儲系統中一種高效的分層對象布局算法 [J]. 計算機研究與發展,2012,49(4): 887-899.
CHEN Tao,XIAO Nong,LIU Fang. An efficient hierarchical object placement algorithm for object storage systems [J]. Journal of Computer Research and Development,2012,49(4): 887-899.
[9] MIRANDA A,EFFERT S,KANG Y,et al. Random slicing: efficient and scalable data placement for large-scale storage systems [J]. ACM Transactions on Storage,2014,10(3): 1-35.
[10] XU M,ZHU Y,LEE P P C,et al. Even data placement for load balance in reliable distributed deduplication storage systems [C]//Proceedings of the 23th IEEE International Symposium on Quality of Service. Piscataway,NJ,USA: IEEE,2016: 349-358.
[11] JOUINI K. Distorted replicas: intelligent replication schemes to boost I/O throughput in document-stores [C]// Proceedings of the 2017 IEEE/ACS International Conference on Computer Systems and Applications. Piscataway,NJ,USA: IEEE,2017: 25-32.
[12] GAO Y,LI K,JIN Y. Compact,popularity-aware and adaptive hybrid data placement schemes for heterogeneous cloud storage [J]. IEEE Access,2017,5(99): 1306-1318.
[13] SHEN Z,LEE P P C,SHU J,et al. Encoding-aware data placement for efficient degraded reads in XOR-coded storage systems [C]// Proceedings of the 35th IEEE Symposium on Reliable Distributed Systems. Piscataway,NJ,USA: IEEE,2016: 239-248.
[14] QIN Y,AI X,CHEN L,et al. Data placement strategy in data center distributed storage systems [C]// Proceedings of the 2016 IEEE International Conference on Communication Systems. Piscataway,NJ,USA: IEEE,2017: 1-6.
[15] STINSON D R. Combinatorial designs: constructions and analysis [M]. Berlin,Germany: Springer-Verlag,2003: 56-57.
猜你喜歡
遼寧教育(2022年19期)2022-11-18 07:20:42
公民與法治(2022年5期)2022-07-29 00:47:28
汽車實用技術(2022年9期)2022-05-20 05:51:26
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
裝備制造技術(2020年11期)2021-01-26 00:39:12
中國公共安全(2017年11期)2017-02-06 05:28:08
電測與儀表(2016年7期)2016-04-12 00:22:18
燕山大學學報(2015年4期)2015-12-25 02:19:49
