基于時(shí)空采樣的卷積長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)模型及其應(yīng)用研究
2018-06-28 02:23:22閉世蘭
機(jī)電信息 2018年18期
閉世蘭
(中南民族大學(xué)生物醫(yī)學(xué)工程學(xué)院,湖北武漢430074)
0 引言
近年來,基于機(jī)器學(xué)習(xí)的方法作用于人體動(dòng)作識(shí)別取得了卓越的成效,其中以計(jì)算機(jī)模擬生物體神經(jīng)系統(tǒng)視覺感知機(jī)制的深度學(xué)習(xí)法最為有效。然而,人體動(dòng)作在空域和時(shí)域上呈現(xiàn)不可分割性,但現(xiàn)有的動(dòng)作識(shí)別方法主要采用純粹提取單域信息或時(shí)空信息分離處理的技術(shù)來實(shí)現(xiàn)人體動(dòng)作識(shí)別,從而導(dǎo)致識(shí)別性能仍然不太理想。
眾所周知,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在視覺皮層的多級(jí)處理的啟發(fā)下可以自動(dòng)學(xué)習(xí)特征,模擬視頻空間相關(guān)性效果最好。
Ji Shuiwang等人將傳統(tǒng)的CNN擴(kuò)展到3D-CNN以捕捉視頻中的空間時(shí)間特征[1],但識(shí)別精度不理想且增加了學(xué)習(xí)的復(fù)雜性。
研究者為了提取視頻的時(shí)域特性,提出將循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)[2]及長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)LSTM[3]應(yīng)用于動(dòng)作識(shí)別,V.Veeriah等人在研究中提出微分式循環(huán)神經(jīng)網(wǎng)絡(luò)dRNN模型[4],使用密集取樣的HOG3D特征,并證實(shí)了循環(huán)神經(jīng)網(wǎng)絡(luò)的記憶能力,然而LSTM忽略了幀中局部像素之間的空間相關(guān)性。
為了同時(shí)利用CNN與LSTM的優(yōu)勢(shì),研究者考慮將RNN或LSTM模型與CNN結(jié)合,生成CNNRNN(CNNLSTM)模型,它的基本架構(gòu)是CNN序列特征作為輸入引入到LSTM模型中。
M.Baccouche等人在科研中使用3D-ConvNet+LSTM、3DCNN+Voting兩種組合方式,取得了較高的準(zhǔn)確性[5]。
雖然這些模型可以解決動(dòng)作識(shí)別的問題,但是在模型的兩個(gè)不同階段,它們分別考慮了空間性和時(shí)間性,然而空間性和時(shí)間性是生物體運(yùn)動(dòng)識(shí)別不可分割的特性。
為了揭示動(dòng)作識(shí)別的本質(zhì)特征,專注于時(shí)空信息相關(guān)性,必須將時(shí)間相關(guān)的LSTM網(wǎng)絡(luò)融合到二維CNN中,實(shí)現(xiàn)空間和時(shí)間不可分割的功能,Shi Xingjian等人將完全連接的LSTM擴(kuò)展到卷積LSTM[6]。
1 ConvLSTM
為解決RNN梯度消失和記憶衰減的問題,S.Schuster和J.Schmidhuber等人引入了長(zhǎng)短時(shí)記憶結(jié)構(gòu)(LSTM)[3],模型具有聯(lián)想和記憶功能,能較好地獲取視頻序列空間信息在時(shí)間上流動(dòng)的結(jié)構(gòu)特征,在處理時(shí)序數(shù)據(jù)問題上成效非凡,但是由于LSTM的內(nèi)部接近于全連接的方式,這就帶來嚴(yán)重的信息冗余問題,且LSTM將輸入數(shù)據(jù)視為向量,即使它們具有空間結(jié)構(gòu),忽略幀中局部像素之間的空間相關(guān)性,違背了視頻的本質(zhì)。為了解決這個(gè)問題,Shi Xingjian等人提出將FC-LSTM的思想擴(kuò)展到卷積結(jié)構(gòu)中,用卷積運(yùn)算替換FC-LSTM的input-to-state和state-to-state的點(diǎn)乘運(yùn)算,最終形成LSTM融合CNN的一種卷積LSTM模型(ConvLSTM[6]單元)。ConvLSTM是對(duì)LSTM結(jié)構(gòu)的改進(jìn),其信息處理過程展示如圖1所示,由輸入門、遺忘門、輸出門、記憶單元、隱藏門組成,這些門運(yùn)算過程如式(1)~(5)所示。
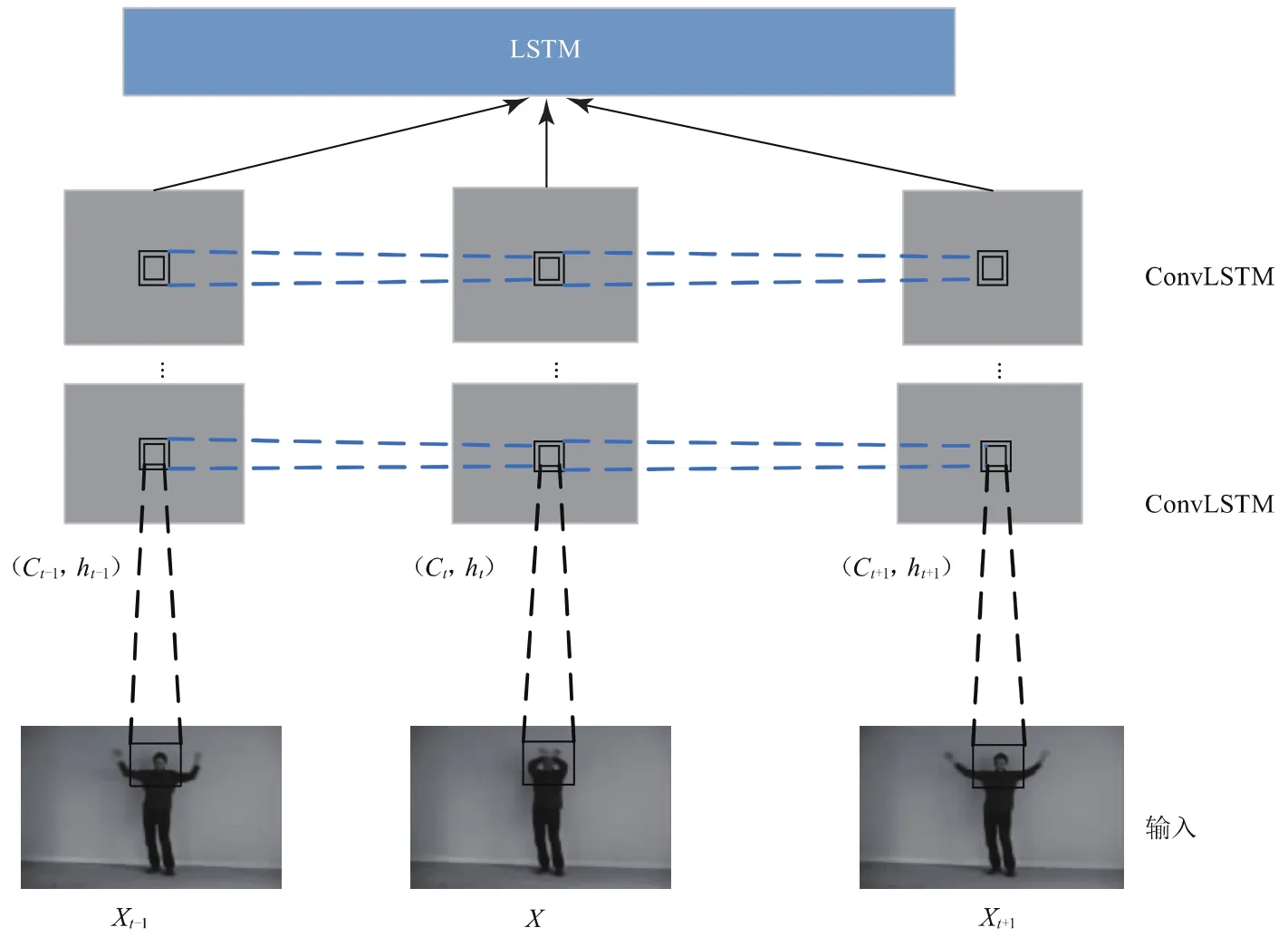
圖1 卷積LSTM信息處理過程

以上公式中,*表示卷積運(yùn)算;·表示點(diǎn)乘運(yùn)算;xt代表t時(shí)刻的輸入圖像;it代表t時(shí)刻的輸入門輸出信息;Ct-1代表t-1時(shí)刻記憶單元的信息;whi是輸入門到遺忘門的權(quán)值矩陣,其余矩陣依此類推。
值得注意的是,這里的xt、it、ft、Ot、Ct、ht都是三維的變量,第一維是時(shí)間信息,后兩維代表行和列的空間信息。
該模型結(jié)構(gòu)既充分發(fā)揮了空間卷積神經(jīng)網(wǎng)絡(luò)的特性,模擬視覺系統(tǒng)感受野,較好地感知視頻中人體動(dòng)作結(jié)構(gòu)特征,提取圖像中的空間局部相關(guān)性,又能發(fā)揮LSTM模型在長(zhǎng)時(shí)間序列處理問題上的聯(lián)想和記憶功能,提取視頻的時(shí)空特征,獲取動(dòng)作在時(shí)間上流動(dòng)的特征,是一個(gè)既有空間深度,又有時(shí)間深度的“雙重”深度學(xué)習(xí)網(wǎng)絡(luò)。
2 狀態(tài)微分ConvLSTM
雖然卷積長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)模型能提取時(shí)間和空間上的特征,對(duì)任何復(fù)雜動(dòng)力學(xué)的時(shí)間序列數(shù)據(jù)進(jìn)行建模,但不幸的是該模型對(duì)輸入視頻序列隱藏狀態(tài)的動(dòng)態(tài)演化不敏感,不具備精準(zhǔn)分類的能力。
為解決這個(gè)問題,本文在ConvLSTM的基礎(chǔ)上,提出一個(gè)具有時(shí)間狀態(tài)微分的卷積長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)模型——狀態(tài)微分ConvLSTM模型(簡(jiǎn)稱d_ConvLSTM),該模型強(qiáng)調(diào)視頻幀間運(yùn)動(dòng)引起的信息增益,這些信息增益的變化是通過狀態(tài)導(dǎo)數(shù)量化的。
狀態(tài)微分是對(duì)記憶單元Ct進(jìn)行求導(dǎo),其值越大表明在相同時(shí)間上信息的變化量越大,因此模型對(duì)輸入序列的時(shí)空結(jié)構(gòu)變化很敏感,其結(jié)構(gòu)內(nèi)的門運(yùn)算過程見公式(6)~(10),變量信息、各門關(guān)系與ConvLSTM相同。

上式中,是記憶單元Ct的n階導(dǎo)數(shù),狀態(tài)微分也是時(shí)間采樣的一種形式,體現(xiàn)了狀態(tài)Ct在時(shí)間上的變化程度,其一階導(dǎo)數(shù)、二階導(dǎo)數(shù)見公式(11)~(12),較高階的導(dǎo)數(shù)可用類似方式求出。為了不放大包含在輸入序列中的不必要噪聲,本文的離散模型不對(duì)輸入序列進(jìn)行求導(dǎo)。
3 網(wǎng)絡(luò)架構(gòu)
在搭建網(wǎng)絡(luò)模型中,需要考慮的是卷積核大小、網(wǎng)絡(luò)層數(shù)、過擬合等問題。
回顧近年來提出的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)框架:從LeNet-5網(wǎng)絡(luò)架構(gòu)到AlexNet架構(gòu),再到Googlenet[7]網(wǎng)絡(luò)與VGG網(wǎng)絡(luò),最后擴(kuò)展到NIN[8]網(wǎng)絡(luò)與darknet-19[9]網(wǎng)絡(luò)架構(gòu)。隨著模型架構(gòu)的改進(jìn),發(fā)現(xiàn)伴隨著卷積核的減少,卷積層數(shù)的增加,模型在識(shí)別問題上表現(xiàn)的性能越來越出色。
因此本文判定結(jié)合這些網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)點(diǎn)所搭建的框架也具有從圖像提取特征映射的能力,本文模仿Darknet-19的網(wǎng)絡(luò)結(jié)構(gòu),并對(duì)其進(jìn)行擴(kuò)展和簡(jiǎn)化,通過將其卷積層替換成新模型ConvLSTM單元。在深度方向,本文的模型使用了15個(gè)ConvLSTM層、6個(gè)池化層,并采取在每層ConvLSTM卷積后增加批量標(biāo)準(zhǔn)化防止網(wǎng)絡(luò)過擬合。此外,施加在權(quán)重上的正則項(xiàng)使用L2正則規(guī)范化等初始化方式防止過擬合。
本文的模型框架是ConvLSTM層與池化層堆疊而成的,然后送入LSTM單元,LSTM融合視頻序列的所有幀信息,然后將特征向量傳送到softmax分類器,為每一個(gè)視頻生成一個(gè)標(biāo)簽。訓(xùn)練采用批量隨機(jī)梯度下降法(SGD)迭代160次,批量處理大小為10個(gè)樣本,網(wǎng)絡(luò)的學(xué)習(xí)率初始化為0.1,momentum為0.9,權(quán)重衰減為0.000 5。
4 實(shí)驗(yàn)結(jié)果與分析
KTH數(shù)據(jù)庫(kù)是評(píng)估動(dòng)作識(shí)別算法的基準(zhǔn)[10],數(shù)據(jù)庫(kù)包含六類動(dòng)作四種場(chǎng)景,由25個(gè)人組成共599個(gè)灰度視頻。
本文使用其中的20組作為訓(xùn)練集,5組作為測(cè)試集,在網(wǎng)絡(luò)訓(xùn)練之前,首先將圖片進(jìn)行線性插值、減去均值、除方差等預(yù)處理。
4.1 基于時(shí)間深度的效果
深度ConvLSTM是一種“雙深”結(jié)構(gòu),提取時(shí)空特征以識(shí)別人體動(dòng)作。為了證明網(wǎng)絡(luò)模型的有效性,本文進(jìn)行了一些探索性實(shí)驗(yàn),選用不同的時(shí)間深度T進(jìn)行不同場(chǎng)景(d1、d2、d3、d4)的測(cè)試,用于評(píng)估時(shí)間深度對(duì)動(dòng)作識(shí)別的影響,實(shí)驗(yàn)效果如表1所示,識(shí)別率(ARRs)是判別網(wǎng)絡(luò)性能的標(biāo)準(zhǔn)。

表1 KTH數(shù)據(jù)庫(kù)在不同場(chǎng)景不同幀長(zhǎng)下的識(shí)別率
實(shí)驗(yàn)證明在時(shí)間深度T<10時(shí),識(shí)別精度隨著深度(或幀長(zhǎng))增加而增加,當(dāng)T>10時(shí),精度卻呈現(xiàn)微弱的下降。這是因?yàn)闀r(shí)間深度越深包含的運(yùn)動(dòng)信息越多,越有助于行動(dòng)識(shí)別,當(dāng)深度值接近動(dòng)作的循環(huán)周期時(shí),識(shí)別率最高。
然而,當(dāng)時(shí)間深度大于10時(shí)識(shí)別率并不能顯著提高,與此同時(shí)深度的增加特征提取的計(jì)算量也成倍的增加,計(jì)算負(fù)載越重。
4.2 基于時(shí)間采樣的效果
考慮到傳統(tǒng)的網(wǎng)絡(luò)結(jié)構(gòu)中采樣能有效地提高識(shí)別精度,加速模型收斂,融合上下文信息。本文的網(wǎng)絡(luò)結(jié)構(gòu)中,在對(duì)視頻系列的時(shí)間維度進(jìn)行簡(jiǎn)單的特征提取基礎(chǔ)上,提出了狀態(tài)微分采樣、三維池化、幀間采樣三種時(shí)間采樣方式,并在4.2.1~4.2.3章節(jié)中對(duì)這三種方式進(jìn)行實(shí)驗(yàn)分析。為了便于理解,利用ConvLSTM模型搭建的框架結(jié)構(gòu)稱為對(duì)比試驗(yàn)中的原始結(jié)構(gòu)。
4.2.1 狀態(tài)微分
首先對(duì)狀態(tài)微分進(jìn)行實(shí)驗(yàn),微分結(jié)構(gòu)d_ConvLSTM替換原始框架結(jié)構(gòu)中的ConvLSTM層,其他框架結(jié)構(gòu)不改變,實(shí)驗(yàn)比較狀態(tài)微分與原始結(jié)構(gòu)在KTH數(shù)據(jù)庫(kù)不同實(shí)驗(yàn)幀長(zhǎng)中的識(shí)別效果,實(shí)驗(yàn)結(jié)果如表2所示。
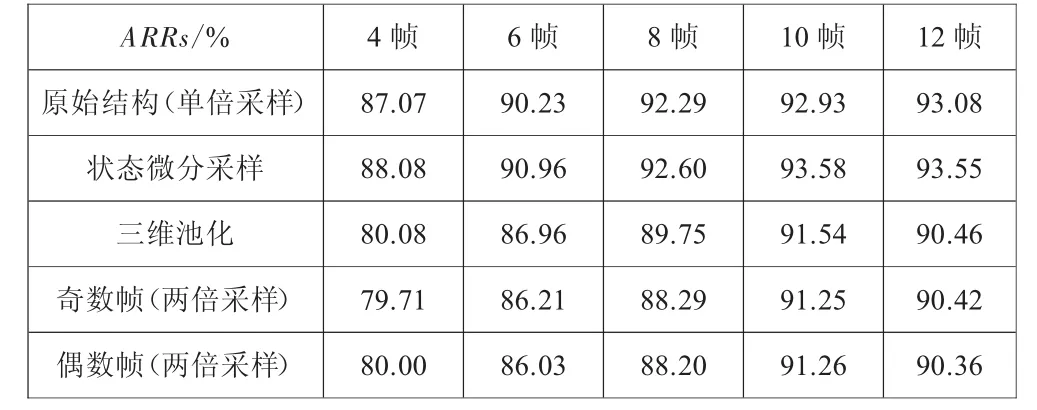
表2 三種時(shí)間采樣方式與原始結(jié)構(gòu)的對(duì)比
在實(shí)驗(yàn)結(jié)果表2中,注意到d_ConvLSTM模型相比ConvLSTM模型在不同長(zhǎng)度的輸入序列下動(dòng)作識(shí)別效果好,每個(gè)長(zhǎng)度的平均識(shí)別率都增長(zhǎng)了0.5至1個(gè)百分點(diǎn)。實(shí)驗(yàn)證明狀態(tài)導(dǎo)數(shù)確實(shí)對(duì)輸入的變化量敏感,從而捕獲細(xì)小的變化,提高識(shí)別率。
4.2.2 三維池化
在本文的框架中,使用了六層池化層,但是時(shí)空融合在哪一層的效果最好呢?為此,本文進(jìn)行了探究實(shí)驗(yàn),文章首先選取以10幀圖片作為參照標(biāo)準(zhǔn),在每一層都單獨(dú)做三維時(shí)間池化,實(shí)驗(yàn)得出第一層池化精確度91.54%,第二層池化精確度91.87%,第三層池化精確度91.75%,第四層池化精確度92.17%,第五層池化精確度91.34%,第六層池化精確度91.38%。不難發(fā)現(xiàn),當(dāng)本文的框架選取第四層做三維池化時(shí),實(shí)驗(yàn)精度最高。
第二個(gè)實(shí)驗(yàn)里,我們選取第一層池化層做三維池化,比較不同時(shí)間深度T下,三維池化與非池化的動(dòng)作識(shí)別差異,結(jié)果見表2,三維池化的平均結(jié)果略低于非池化的平均結(jié)果,這是因?yàn)樵跁r(shí)間軸上發(fā)生了池化,而時(shí)間采樣相當(dāng)于一個(gè)模糊濾波器,導(dǎo)致了信息模糊化,運(yùn)動(dòng)特征區(qū)分性不明顯,造成識(shí)別精度較低。
4.2.3 幀間采樣
KTH實(shí)驗(yàn)數(shù)據(jù)采用等間隔的單倍幀間采樣法,當(dāng)增加間隔的步長(zhǎng),相當(dāng)于變相地增加了數(shù)據(jù)樣本的距離,使得序列在時(shí)間上跳躍性大,幀間信息差別明顯,拉大動(dòng)作的類內(nèi)差距。
本文第一組實(shí)驗(yàn)中先討論不同的幀間采樣方式對(duì)動(dòng)作識(shí)別的影響,考慮到當(dāng)輸入序列小于8幀時(shí)若選取4倍的采樣間隔,實(shí)驗(yàn)毫無意義,因此,本文只考慮兩倍的采樣間隔。兩倍幀間采樣有奇采樣與偶采樣的兩種不同的采樣方式,兩種采樣方式的實(shí)驗(yàn)結(jié)果見表2。
通過實(shí)驗(yàn)可知奇采樣與偶采樣兩種兩倍幀間采樣方式對(duì)于不同幀長(zhǎng)下的實(shí)驗(yàn)結(jié)果影響并不明顯,但是兩倍幀間采樣的平均識(shí)別率低于單倍幀間采樣,因此,本文可以得出結(jié)論:識(shí)別精度與采樣方式無關(guān),而與采樣步長(zhǎng)相關(guān)。
4.3 對(duì)比實(shí)驗(yàn)結(jié)果
為了評(píng)估本文方法的有效性,將本文的方法與傳統(tǒng)的LSTM和最先進(jìn)的非LSTM方法進(jìn)行比較,對(duì)比結(jié)果如表3所示,本文的方法的識(shí)別性能要優(yōu)于其他方法。

表3 在KTH數(shù)據(jù)集上比較ConvLSTM模型與其他模型算法
5 結(jié)語
本文針對(duì)視頻圖像的識(shí)別,采用卷積LSTM模型在時(shí)域空域方向提取特征,實(shí)現(xiàn)動(dòng)作識(shí)別。實(shí)驗(yàn)結(jié)果證明:本文提出的基于卷積神經(jīng)網(wǎng)絡(luò)模型算法在學(xué)習(xí)時(shí)空特征動(dòng)作識(shí)別過程中更優(yōu)于傳統(tǒng)的單獨(dú)學(xué)習(xí)空間、時(shí)間特征,也優(yōu)于CNN+LSTM的結(jié)構(gòu),識(shí)別精度獲得了較大的提升,微分形式的采樣更有利于特征的提取。
[1]JI S W,XU W,YANG M,et al.3D Convolutional Neural Networks for Human Action Recognition [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,35(1):221-231.
[2]SCHUSTER M,PALIWAL K K.Bidirectional Recurrent Neural Networks [J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[3] HOCHREITER S,SCHMIDHUBER J.Long Short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[4]VEERIAH V,ZHUANG N F,QI G J.Differential Recurrent Neural Networks for Action Recognition[C]//proceedings of the IEEE International Conference on Computer Vision,2015:4041-4049.
[5]BACCOUCHE M,MAMALET F,WOLF C,et al.Sequential deep learning for human action recognition[C]//proceedings oftheInternationalConferenceonHumanBehavior Unterstanding,2011:29-39.
[6]SHI X J,CHEN Z R,WANG H,et al.Convolutional LSTM Network:A Machine Learning Approach for Precipitation Nowcasting [C]//Advances in Neural Information Processing Systems 28(NIPS),2015:802-810.
[7]SZEGEDY C,LIU W,JIA Y Q,et al.Goingdeeperwith convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2015:1-9.
[8]LIN M,CHEN Q,YAN S C.Network in Network[C]//International Conference on Learning Representations(ICLR),2014.
[9] REDMON J,FARHADI A.YOLO9000:Better,Faster,Stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017:6517-6525.
[10]SCHULDT C,LAPTEV I,CAPUTO B.Recognizing Human Actions:A Local SVM Approach[C]//Proceedings of the 17thInternational Conference on Pattern Recognition(ICPR),2004:32-36.
[11]GRUSHIN A,MONNER D D,REGGIA J A,et al.Robust human action recognition via long short-term memory[C]//International Joint Conference on Neural Networks,2014:1-8.
[12]SCHINDLER K,GOOL L V.Action snippets:How many frames does human action recognition require?[C]//IEEE Conference on Computer Vision and Pattern Recognition,2008:1-8.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
