基于大數(shù)據(jù)分析的農(nóng)產(chǎn)品質(zhì)量控制研究
2018-08-01 07:53:36孫建召
江蘇農(nóng)業(yè)科學(xué) 2018年13期
孫建召
(河南經(jīng)貿(mào)職業(yè)學(xué)院計(jì)算機(jī)工程學(xué)院,河南鄭州 450018)
我國(guó)為農(nóng)業(yè)與人口大國(guó),近年來(lái),隨著我國(guó)經(jīng)濟(jì)迅猛發(fā)展,人們物質(zhì)及生活水平逐漸提高,對(duì)農(nóng)產(chǎn)品質(zhì)量的要求越來(lái)越高[1]。農(nóng)產(chǎn)品出口為我國(guó)外匯收入的關(guān)鍵部分[2],當(dāng)前國(guó)外對(duì)農(nóng)產(chǎn)品進(jìn)口出臺(tái)貿(mào)易保護(hù)政策,且我國(guó)少部分出口農(nóng)產(chǎn)品質(zhì)量標(biāo)準(zhǔn)低,被進(jìn)口國(guó)退貨的事件時(shí)有發(fā)生[3]。面對(duì)國(guó)內(nèi)外環(huán)境,農(nóng)產(chǎn)品作為食品的源頭,其質(zhì)量直接影響著國(guó)家發(fā)展,須研究一種有效的農(nóng)產(chǎn)品質(zhì)量控制方法,保證市場(chǎng)農(nóng)產(chǎn)品質(zhì)量。
當(dāng)前,我國(guó)政府對(duì)農(nóng)產(chǎn)品質(zhì)量控制非常關(guān)注,出臺(tái)了相應(yīng)的法律法規(guī),為農(nóng)產(chǎn)品質(zhì)量控制分析與應(yīng)用提供了重要保障[4]。在此基礎(chǔ)上,很多學(xué)者對(duì)農(nóng)產(chǎn)品質(zhì)量控制進(jìn)行了系統(tǒng)研究,但當(dāng)前農(nóng)產(chǎn)品質(zhì)量控制方法大多通過抽樣實(shí)現(xiàn)農(nóng)產(chǎn)品質(zhì)量控制,結(jié)果并不可靠,為此,提出一種新的基于大數(shù)據(jù)分析的農(nóng)產(chǎn)品質(zhì)量控制方法,不但控制精度和穩(wěn)定性高,而且具有很高的參考價(jià)值。
1 基于大數(shù)據(jù)分析的農(nóng)產(chǎn)品質(zhì)量控制方法
1.1 建立大數(shù)據(jù)分析體系框架
建立大數(shù)據(jù)分析背景下農(nóng)產(chǎn)品質(zhì)量控制體系框架(圖1)。依據(jù)農(nóng)業(yè)信息化基礎(chǔ)設(shè)施建立體系,通過模塊化開發(fā)平臺(tái)為農(nóng)產(chǎn)品質(zhì)量控制體系提供開發(fā)環(huán)境,利用網(wǎng)絡(luò)提供質(zhì)量控制服務(wù),主要包括用戶訪問層、業(yè)務(wù)服務(wù)層、數(shù)據(jù)平臺(tái)層、基礎(chǔ)數(shù)據(jù)層和虛擬資源層。
1.2 關(guān)鍵技術(shù)
1.2.1 數(shù)據(jù)采集技術(shù) 為實(shí)現(xiàn)農(nóng)產(chǎn)品質(zhì)量控制,須對(duì)其生產(chǎn)銷售過程中的重要參數(shù)進(jìn)行采集,即基礎(chǔ)數(shù)據(jù)庫(kù)層。無(wú)線傳感網(wǎng)絡(luò)能夠?qū)崟r(shí)采集數(shù)據(jù),選用基于ZigBee的無(wú)線傳感網(wǎng)絡(luò)對(duì)數(shù)據(jù)進(jìn)行采集。ZigBee整體性能高[5],基于ZigBee的無(wú)線傳感網(wǎng)絡(luò)將CC2430作為核心,主要用于數(shù)據(jù)交換[6]。CC2430為TI(Texas Instruments)企業(yè)生產(chǎn)的芯片,其內(nèi)置增強(qiáng)型8051控制器與2.8 GHz擴(kuò)頻射頻收發(fā)器,外圍電路簡(jiǎn)單,是一種高性能芯片[7]。ZigBee模塊除CC2430芯片外,還有天線、傳感器等,實(shí)質(zhì)上就是一個(gè)節(jié)點(diǎn),能夠和其他節(jié)點(diǎn)通信。

ZigBee網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)即ZigBee節(jié)點(diǎn)的組網(wǎng)結(jié)構(gòu),主要有星型、樹型與網(wǎng)狀等3種結(jié)構(gòu)[8],用于實(shí)際應(yīng)用環(huán)境中,選擇合理的ZigBee網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)。
本節(jié)農(nóng)產(chǎn)品質(zhì)量控制體系選用網(wǎng)狀拓?fù)浣Y(jié)構(gòu)。在ZigBee模塊中,網(wǎng)狀拓?fù)浣Y(jié)構(gòu)有網(wǎng)絡(luò)協(xié)調(diào)器、路由器和終端設(shè)備等3種通信設(shè)備(圖2)。選用的網(wǎng)狀拓?fù)浣Y(jié)構(gòu)自組織與自愈能力強(qiáng),可以很好地適應(yīng)農(nóng)產(chǎn)品大數(shù)據(jù)分析需求。

網(wǎng)狀拓?fù)浣Y(jié)構(gòu)的ZigBee網(wǎng)絡(luò)能夠有效地采集農(nóng)產(chǎn)品數(shù)據(jù),利用中繼方式[9]把采集數(shù)據(jù)發(fā)送至遠(yuǎn)程數(shù)據(jù)中心。遠(yuǎn)程數(shù)據(jù)中心將接收的數(shù)據(jù)保存至數(shù)據(jù)庫(kù),通過業(yè)務(wù)服務(wù)層與數(shù)據(jù)平臺(tái)層進(jìn)行大數(shù)據(jù)分析,再保存至Web存儲(chǔ)器及相應(yīng)服務(wù)器。
1.2.2 農(nóng)產(chǎn)品質(zhì)量監(jiān)控 主要對(duì)生產(chǎn)階段、收購(gòu)階段、加工階段、銷售階段的農(nóng)產(chǎn)品質(zhì)量進(jìn)行監(jiān)控。將生產(chǎn)階段、加工階段的農(nóng)產(chǎn)品看作主要研究目標(biāo),開展有針對(duì)性的質(zhì)量控制監(jiān)控研究。研究關(guān)鍵為基于大數(shù)據(jù)分析的農(nóng)產(chǎn)品質(zhì)量控制,將大數(shù)據(jù)分析應(yīng)用于農(nóng)產(chǎn)品質(zhì)量控制中,而本節(jié)提出的質(zhì)量監(jiān)控方法為大數(shù)據(jù)分析的基礎(chǔ)。農(nóng)產(chǎn)品質(zhì)量監(jiān)控過程如圖3所示。

通過檢測(cè)歷史異常數(shù)據(jù)和數(shù)據(jù)分布異常對(duì)農(nóng)產(chǎn)品數(shù)據(jù)進(jìn)行分析,實(shí)現(xiàn)對(duì)農(nóng)產(chǎn)品質(zhì)量監(jiān)控。
在對(duì)農(nóng)產(chǎn)品質(zhì)量進(jìn)行監(jiān)控時(shí),隨著時(shí)間的推移,會(huì)形成大規(guī)模監(jiān)測(cè)數(shù)據(jù)集合。對(duì)農(nóng)產(chǎn)品數(shù)據(jù)進(jìn)行研究,獲取數(shù)據(jù)的變化規(guī)律與比較數(shù)據(jù)庫(kù)當(dāng)前數(shù)據(jù)改變規(guī)律,得到監(jiān)控農(nóng)產(chǎn)品數(shù)據(jù)改變趨勢(shì),從而發(fā)現(xiàn)可能出現(xiàn)的農(nóng)產(chǎn)品質(zhì)量異常情況。
(1)
式中:δab為決定農(nóng)產(chǎn)品質(zhì)量控制過程中檢測(cè)數(shù)據(jù)歷史異常趨勢(shì)系數(shù),該值的正負(fù)情況表示異常狀況個(gè)數(shù)在使用者設(shè)定的m個(gè)時(shí)間區(qū)間中的遞增或遞減趨勢(shì);a為m個(gè)時(shí)間區(qū)間中發(fā)生異常狀況的總個(gè)數(shù);ab為第b個(gè)時(shí)間區(qū)間中出現(xiàn)質(zhì)量異常的個(gè)數(shù),這里:
(2)
對(duì)于時(shí)間區(qū)間而言,可依據(jù)農(nóng)產(chǎn)品的種類、特性等因素進(jìn)行設(shè)定[10],通常為幾天,有時(shí)為幾個(gè)月。
在分析過程中,農(nóng)產(chǎn)品質(zhì)量控制人員根據(jù)實(shí)際狀況對(duì)趨勢(shì)系數(shù)δab的閾值ξ進(jìn)行設(shè)定,若δab>ξ,表明農(nóng)產(chǎn)品質(zhì)量控制要素在質(zhì)量安全上發(fā)生異常,并按照事先設(shè)定的危險(xiǎn)等級(jí)進(jìn)行報(bào)警。
根據(jù)異常趨勢(shì)系數(shù)δab能夠掌握被監(jiān)控農(nóng)產(chǎn)品質(zhì)量控制點(diǎn)在某一時(shí)期內(nèi)數(shù)值的改變情況,是一種依據(jù)時(shí)間序列的質(zhì)量控制方法。
數(shù)據(jù)分布異常主要針對(duì)不同區(qū)域中的相同要素進(jìn)行分析和比較,從而獲取各區(qū)域間不同農(nóng)產(chǎn)品質(zhì)量監(jiān)測(cè)方法。
農(nóng)產(chǎn)品監(jiān)測(cè)數(shù)據(jù)歷史數(shù)據(jù)庫(kù)中包含了所有質(zhì)量數(shù)據(jù)異常的信息,對(duì)歷史數(shù)據(jù)庫(kù)中異常數(shù)據(jù)在不同區(qū)域的分布狀態(tài)進(jìn)行分析,有助于質(zhì)量監(jiān)測(cè)人員發(fā)現(xiàn)各區(qū)域已經(jīng)存在及潛在的農(nóng)產(chǎn)品質(zhì)量問題。
詳細(xì)過程如下:
針對(duì)須監(jiān)控的農(nóng)產(chǎn)品區(qū)域,首先將其分為k個(gè)子區(qū)域,用q描述區(qū)域向量,通過k個(gè)子區(qū)域構(gòu)成1個(gè)集合,也就是q=(q1,q2,…,qk)。用L描述相應(yīng)子區(qū)域出現(xiàn)異常的農(nóng)產(chǎn)品數(shù)據(jù)集合,也就是L=(L1,L2,…,Lk)。假設(shè)R是從數(shù)據(jù)庫(kù)中采集的該區(qū)域完成檢測(cè)的質(zhì)量控制要素個(gè)數(shù),也就是R=(R1,R2,…,Rk),則有:
(3)
區(qū)域i中的農(nóng)產(chǎn)品質(zhì)量數(shù)據(jù)異常情況通過均值可描述成ui,u=(u1,u2,…,uk),ε表示常數(shù),負(fù)責(zé)對(duì)u進(jìn)行標(biāo)準(zhǔn)化處理,使其處于(1,10)范圍內(nèi)[11]。
農(nóng)產(chǎn)品質(zhì)量監(jiān)測(cè)按照實(shí)際情況對(duì)閾值S進(jìn)行設(shè)置,S=(S1,S2,…,Sk),在ui>Si的情況下,認(rèn)為qi區(qū)域有質(zhì)量異常農(nóng)產(chǎn)品數(shù)據(jù),用戶須按情況發(fā)出報(bào)警信息。
針對(duì)上述區(qū)域,農(nóng)產(chǎn)品異常狀態(tài)數(shù)據(jù)量均值u可通過下式計(jì)算:
(4)
(5)

1.3 農(nóng)產(chǎn)品溯源及召回
1.3.1 射頻識(shí)別(radio frequency identification,簡(jiǎn)稱RFID)硬件設(shè)計(jì) 通過射頻識(shí)別對(duì)出現(xiàn)質(zhì)量問題的農(nóng)產(chǎn)品進(jìn)行溯源和召回,射頻識(shí)別系統(tǒng)結(jié)構(gòu)如圖4所示。

射頻識(shí)別系統(tǒng)主要包括電子標(biāo)簽、讀寫器和計(jì)算機(jī)通信網(wǎng)絡(luò)。
電子標(biāo)簽主要用于保存農(nóng)產(chǎn)品相關(guān)信息,一般被置于農(nóng)產(chǎn)品上,其保存的信息可利用讀寫器通過非接觸形式讀寫[12]。讀寫器為能夠通過射頻技術(shù)實(shí)現(xiàn)電子標(biāo)簽信息讀寫操作的裝置。讀寫器讀出標(biāo)簽信息后,利用PC機(jī)和網(wǎng)絡(luò)系統(tǒng)對(duì)信息進(jìn)行傳輸。在射頻識(shí)別系統(tǒng)中,計(jì)算機(jī)通信網(wǎng)絡(luò)主要負(fù)責(zé)完成對(duì)農(nóng)產(chǎn)品質(zhì)量數(shù)據(jù)的管理,實(shí)現(xiàn)通信功能。讀寫器能夠經(jīng)標(biāo)準(zhǔn)接口和PC機(jī)通信網(wǎng)絡(luò)相連[13],從而達(dá)到通信與數(shù)據(jù)傳輸?shù)哪康摹?/p>
1.3.2 軟件設(shè)計(jì) 當(dāng)農(nóng)產(chǎn)品出現(xiàn)質(zhì)量問題時(shí),先根據(jù)出現(xiàn)質(zhì)量問題的成品批次,從下到上逐步找到出現(xiàn)問題的原料批次,即溯源;再根據(jù)這些出現(xiàn)質(zhì)量問題的原料批次,由上到下逐步找出含此批次的成品,即跟蹤;最后將它們一并召回。依據(jù)批次的農(nóng)產(chǎn)品召回示意如圖5所示。

上面主要闡述了依據(jù)批次的農(nóng)產(chǎn)品溯源與召回原理,下面對(duì)其優(yōu)化模型進(jìn)行介紹。先對(duì)各層次批次集合進(jìn)行定義,主要包括原料C個(gè)批次、部件P個(gè)批次、半成品G個(gè)批次以及成品V個(gè)批次,且可依次分成D、N、H、Z個(gè)類別,依次對(duì)原料層次YL、部件層次BJ、半成品層次HP以及成品層次CP的批次集合進(jìn)行描述,公式描述如下:
YL=(YL1,…,YLc,…,YLC);
(6)
BJ=(BJ1,…,BJp,…,BJP);
(7)
HP=(HP1,…,HPg,…,HPG);
8)
CP=(CP1,…,CPv,…,CPV)。
(9)
各層中任意一個(gè)批次的屬性可描述為:
YLc=(IYLc,CYLc,NYLc);
(10)
BJp=(IBJp,CBJp,NBJp);
(11)
HPg=(IHPg,CHPg,NHPg);
(12)
CPv=(ICPv,CCPv,NCPv)。
(13)
在各層中,各批次農(nóng)場(chǎng)品均存在電子標(biāo)簽、類別以及數(shù)目等3大屬性。對(duì)于原料批次YLc的屬性,IYLc表示其電子標(biāo)簽,為此批次在整個(gè)系統(tǒng)中的唯一標(biāo)志;CYLc表示它的類別,且CYLc∈{1,…,d,…,D};NYLc表示它的數(shù)量。同理,可實(shí)現(xiàn)部件、半成品以及成品各批次屬性的定義,其批次電子標(biāo)簽屬性依次是IBJ、IHP、ICP,類別屬性依次是CBJ、CHP、CCP,數(shù)目屬性依次是NBJ、NHP、NCP。
分解、組合和包裝比例只受批次類別屬性的影響,存在下述關(guān)系:
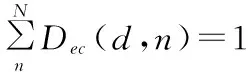
(14)

15)

(16)
式中:Dec(d,n)用于描述分解比例,也就是原材料類別d分解至部件類別n的比例;Gro(n,h)用于描述組合比例,也就是半成品類別h中,部件類別n占用的比例;Pac(h,z)用于描述包裝比例,也就是成品類別z中,半成品類別h占用的比例。
用X(c,p)描述原料至部件的批次布爾變量,BJp中含YLc的元素時(shí),則X(c,p)為1,否則X(c,p),為0;用K(p,g)描述部件至半成品的批次布爾變量,若HPg中含有BJp元素,則K(p,g)為1,否則K(p,g)為0;用Y(g,v)描述半成品至成品的批次布爾變量,若CPv中存在HPg元素,則Y(g,v)為1,否則Y(g,v)為0;用W(c,v)描述原料至成品的批次布爾變量,若CPv中含有YLc元素,則W(c,v)為1,否則W(c,v)為0。通過布爾運(yùn)算可得:

(17)
一旦原料批次YLc出現(xiàn)質(zhì)量不達(dá)標(biāo)問題,對(duì)全部含有YLc的成品批次均召回。通過下式求出平均召回規(guī)模:
(18)
在生產(chǎn)和加工的過程中,受加工器械、工作場(chǎng)景以及人員水平的制約[14],考慮到經(jīng)濟(jì)效益,須將部件與半成品批次的數(shù)量控制在某一范圍。設(shè)類別為n的部件批次的最大與最小允許數(shù)量依次為ξmax(n)與ξmin(n),類別為h的半成品批次的最大與最小允許數(shù)量依次為ξmax(h)與ξmin(h)。由此可得部件與半成品的批次數(shù)量的限制條件[15],即:
ξmin(CYLc)≤NYLc≤ξmax(CYLc);
(19)
ξmin(CHPg)≤NCHPg≤ξmax(CHPg)。
(20)
將公式(18)作為目標(biāo)函數(shù),將公式(19)與(20)作為目標(biāo)函數(shù)的約束條件,構(gòu)建農(nóng)產(chǎn)品召回優(yōu)化模型,公式描述如下:
(21)
利用粒子群法對(duì)模型進(jìn)行尋優(yōu)處理,通過優(yōu)化模型達(dá)到農(nóng)產(chǎn)品的最小召回目標(biāo),從而實(shí)現(xiàn)農(nóng)產(chǎn)品質(zhì)量控制。
2 結(jié)果與分析
2.1 樣品采集及制備
為了驗(yàn)證本方法的有效性,將統(tǒng)計(jì)學(xué)方法和數(shù)據(jù)挖掘方法作為對(duì)比進(jìn)行測(cè)試。依次采用3種方法對(duì)3個(gè)不同種植基地的農(nóng)產(chǎn)品質(zhì)量進(jìn)行控制。試驗(yàn)樣品采用抽樣方式,針對(duì)個(gè)體較大的樣品,采樣量為2個(gè)。針對(duì)個(gè)體較小的樣品,采樣量為0.5 kg。
把抽取的樣品混合在一起,通過四分法進(jìn)行縮分處理。針對(duì)個(gè)體較小的樣品,去除不可食部分,保留可食部分;針對(duì)個(gè)體較大的樣品,將其切為小塊;針對(duì)不均勻樣品,在其任意部位取小片;針對(duì)谷類和豆類樣品,通過圓錐四分法完成縮分。
把縮分后樣品攪碎并混勻,通過四分法取樣,將濕樣勻漿添加至聚乙烯瓶中,在-18 ℃左右環(huán)境下儲(chǔ)存,干貨類攪勻后添加至瓶中,在常溫下通風(fēng)儲(chǔ)存。
2.2 召回試驗(yàn)
以農(nóng)藥殘留為標(biāo)準(zhǔn),將有農(nóng)藥殘留農(nóng)產(chǎn)品召回,不同濃度農(nóng)藥殘留對(duì)召回率的要求以及3種方法召回率比較結(jié)果如表1所示。

表1 不同添加濃度要求召回率及3種方法召回率比較
由表1可知,本研究方法召回率一直處于要求召回率范圍內(nèi),且在農(nóng)藥殘留濃度相同的情況下,本研究方法召回率高于統(tǒng)計(jì)學(xué)方法和數(shù)據(jù)挖掘方法。統(tǒng)計(jì)學(xué)方法和數(shù)據(jù)挖掘方法召回率大部分未處于要求召回率范圍內(nèi),召回率低,說(shuō)明本研究方法質(zhì)量控制效果更佳。
2.3 農(nóng)產(chǎn)品質(zhì)量控制性能評(píng)價(jià)
農(nóng)產(chǎn)品質(zhì)量控制性能評(píng)價(jià)包括計(jì)算工作評(píng)價(jià)值與技術(shù)評(píng)定2部分,本研究通過穩(wěn)健Z比分?jǐn)?shù)對(duì)農(nóng)產(chǎn)品質(zhì)量控制性能進(jìn)行衡量,其可通過下式求出:
Zbf=(x-X)÷0.752×3IQR。
(22)
式中:x表示試驗(yàn)結(jié)果;X表示試驗(yàn)結(jié)果中值;IQR表示上四分位數(shù)和下四分位數(shù)差值。
在穩(wěn)健Z比分?jǐn)?shù)低于2的情況下,認(rèn)為相應(yīng)農(nóng)產(chǎn)品質(zhì)量控制方法性能高,控制穩(wěn)定;在穩(wěn)健Z比分?jǐn)?shù)在(2,3)范圍內(nèi)的情況下,認(rèn)為相應(yīng)農(nóng)產(chǎn)品質(zhì)量控制方法穩(wěn)定性一般;在穩(wěn)健Z比分?jǐn)?shù)高于3的情況下,認(rèn)為相應(yīng)農(nóng)產(chǎn)品質(zhì)量控制方法非常不穩(wěn)定。由表2可知,本研究方法質(zhì)量控制穩(wěn)定性高,而統(tǒng)計(jì)學(xué)方法和數(shù)據(jù)挖掘方法的穩(wěn)定性均一般,控制精度時(shí)高時(shí)低,實(shí)用性較差。
農(nóng)產(chǎn)品質(zhì)量控制精度為影響農(nóng)產(chǎn)品質(zhì)量控制方法性能的關(guān)鍵指標(biāo),對(duì)3種方法的農(nóng)產(chǎn)品質(zhì)量控制精度進(jìn)行進(jìn)一步測(cè)試。

表2 3種方法質(zhì)量控制性能比較
通過重復(fù)性限和再現(xiàn)性限對(duì)農(nóng)產(chǎn)品質(zhì)量控制精度進(jìn)行衡量。在正態(tài)分布的情況下,重復(fù)性限公式為:
(23)
再現(xiàn)性限公式為:
(24)
式中:δζ表示重復(fù)性標(biāo)準(zhǔn)差;δs表示再現(xiàn)性標(biāo)準(zhǔn)差。
將本研究方法、統(tǒng)計(jì)學(xué)方法和數(shù)據(jù)挖掘方法檢測(cè)結(jié)果極差的絕對(duì)值和重復(fù)性限相比,若極差絕對(duì)值低于重復(fù)性限,則認(rèn)為通過質(zhì)量檢測(cè);否則未通過質(zhì)量檢測(cè)。再現(xiàn)性試驗(yàn)和重復(fù)性相同。按照上述過程對(duì)不同方法對(duì)農(nóng)產(chǎn)品質(zhì)量控制精度進(jìn)行測(cè)試,取平均值。經(jīng)測(cè)試發(fā)現(xiàn),本研究方法控制精度為96.23%,統(tǒng)計(jì)學(xué)方法控制精度為78.36%,數(shù)據(jù)挖掘方法控制精度為69.85%,本研究方法控制精度最高。
3 結(jié)論
提出了一種新的基于大數(shù)據(jù)分析的農(nóng)產(chǎn)品質(zhì)量控制方法,建立大數(shù)據(jù)分析背景下農(nóng)產(chǎn)品質(zhì)量控制體系框架,通過基于ZigBee的無(wú)線傳感網(wǎng)絡(luò)對(duì)數(shù)據(jù)進(jìn)行采集。通過檢測(cè)歷史異常數(shù)據(jù)和數(shù)據(jù)分布異常對(duì)農(nóng)產(chǎn)品數(shù)據(jù)進(jìn)行分析,實(shí)現(xiàn)農(nóng)產(chǎn)品質(zhì)量監(jiān)控,利用RFID射頻識(shí)別對(duì)出現(xiàn)質(zhì)量問題的農(nóng)產(chǎn)品進(jìn)行溯源和召回,從而實(shí)現(xiàn)農(nóng)產(chǎn)品質(zhì)量控制。經(jīng)試驗(yàn)驗(yàn)證,本研究所提方法能夠有效控制農(nóng)產(chǎn)品質(zhì)量,控制精度和穩(wěn)定性高。
猜你喜歡
中學(xué)生數(shù)理化·八年級(jí)物理人教版(2021年12期)2021-12-31 03:23:08
中學(xué)生數(shù)理化·中考版(2020年10期)2020-11-27 01:59:48
中國(guó)生殖健康(2019年2期)2019-08-23 08:12:08
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
產(chǎn)品可靠性報(bào)告(2017年7期)2017-09-05 09:49:12
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56

- 江蘇農(nóng)業(yè)科學(xué)的其它文章
- 我國(guó)農(nóng)業(yè)化肥施用強(qiáng)度的變動(dòng)趨勢(shì)與影響因素
——基于省級(jí)面板數(shù)據(jù)的實(shí)證分析 - 基于微分博弈的“農(nóng)超對(duì)接”質(zhì)量安全投入問題
- 我國(guó)新型農(nóng)村金融機(jī)構(gòu)風(fēng)險(xiǎn)指標(biāo)體系實(shí)證分析
- 精準(zhǔn)扶貧背景下深度貧困地區(qū)“一戶一策”扶貧模式
——以新疆喀什地區(qū)克什拉克村為例 - 農(nóng)田土中外源Ti(Ⅳ)對(duì)Cd脅迫下油葵生長(zhǎng)的影響
- 竹蓀間作對(duì)橡膠園土壤微生物區(qū)系與群落功能多樣性的影響