基于上下文語義信息的鐵路扣件狀態檢測*
2018-08-03 03:14:22李柏林羅建橋
傳感器與微系統 2018年8期
李 爽, 李柏林, 羅建橋, 歐 陽
(西南交通大學 機械工程學院,四川 成都 610031)
0 引 言
近年來,在車載軌道巡檢系統方面的研究取得了豐碩的成果[1~3],但一直未能很好地解決鐵路扣件的檢測問題。隨著計算機技術的發展,計算機視覺技術逐漸應用到鐵路扣件的自動檢測中[4,5]。目前,扣件自動檢測方法主要分為3類:1)基于扣件圖像全局特征的檢測方法;2)基于扣件圖像局部目標區域的檢測方法;3)基于“視覺詞包(bag-of-words,BOW)模型”的檢測方法。前兩類方法均由于底層特征與圖像內容之間存在語義鴻溝[6~9]制約了扣件狀態檢測算法的準確性。第三類方法首先利用局部特征向量定義圖像塊的不同語義概念(如扣件,軌枕等),即視覺單詞,再統計其出現頻率,生成圖像—單詞詞頻矩陣,將其作為圖像內容的表示,最后,使用機器學習算法來實現扣件圖像分類。文獻[10]在“視覺詞包模型”的基礎上,利用潛在狄利克雷分布 (latent Dirichlet allocation,LDA) 模型學習得到扣件圖像的潛在主題分布,進一步提高了扣件檢測性能。這類方法在將圖像表示成視覺單詞集合時,將每個局部特征映射為與其歐氏距離最近視覺單詞。但映射方法僅考慮了局部特征在特征域上的位置關系,并未考慮局部特征在空間域中是否與其周圍其他局部特征具有上下文約束關系。
針對傳統“視覺詞包模型”忽略視覺單詞在空間域中的上下文關系的缺點,本文提出了一種基于上下文語義信息的扣件檢測模型。在傳統“視覺詞包模型”的基礎上,引入吉布斯(Gibbs)隨機場來描述空間域中像素間的相關性。
在局部特征映射為視覺單詞時,將特征域中局部特征到視覺單詞的歐氏距離同空間域中局部特征間的上下文語義關系結合,提高了局部特征與視覺單詞間映射的準確性。實驗結果表明:結合了上下文語義信息的“視覺詞包模型”具有更高的分類性能。
1 吉布斯隨機場模型
對于二維網格S,由馬爾科夫隨機場的定義可知,隨機場在格點i處取得相應標記的概率只與其鄰域系統N(i)內的格點標記有關,而與鄰域系統外的格點狀態無關。可以表示為
p(wi|wS-i)=p(wi|wN(i))
(1)
根據Hamersley-Clifford定理[11],馬爾科夫隨機場的聯合概率分布與吉布斯隨機場的聯合概率分布等價,即
p(wi)=Z-1exp(-U(wi|β))
(2)
式中Z=∑exp(-U(wi|β))為正則化常數,U(wi|β)為能量方程,β為用來控制鄰域間相互作用的強度勢函數參數。
2 基于上下文語義信息的扣件檢測
在將底層特征向量映射為視覺單詞時,結合特征域和空間域對扣件圖像的分析結果,更準確地定義視覺單詞,并在此基礎上提高扣件檢測的精度。本文的模型框架如圖1所示。

圖1 本文扣件檢測模型框架
2.1 生成視覺單詞和視覺詞典
使用無監督的K-means算法將訓練圖像集上全體底層特征向量聚類為K個簇,每一個簇的中心視為一個視覺單詞,從而生成了一個容量為K的視覺單詞詞典。
2.2 生成圖像—單詞詞頻矩陣
本文設計了模擬視覺注意機制的單詞生成方法。通過引入吉布斯隨機場模型,在傳統單詞生成方法[12]中融入視覺單詞的上下文語義約束信息,提高了單詞生成單詞算法的準確性,消除歧義。
設S={∪si|i∈n}為從扣件圖像中提取的全體特征向量集合,采用歐氏距離將特征向量{s1,s2,…,sn}映射為其特征域中對應的視覺單詞wk,k=1,2,…,K。結合式(2)分析得到格點i與其鄰域中視覺單詞的上文下共生概率為
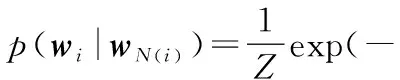
(3)
(4)
式中N為格點i的鄰域系統中所有特征向量的個數。將特征向量和視覺單詞在特征域中的位置關系與在空間域中的上下文語義關系結合,在式(3)、式(4)的基礎上定義了視覺單詞與特征向量的距離函數
(5)
式中p(wi=k|wN(i))為在已知si鄰域內視覺單詞wN(i)的條件下,si映射到第k類視覺單詞的先驗概率。算法具體流程如下:
1)初始化:設置閾值ε,采用歐氏距離將輸入圖像塊的特征向量S={sn}映射為初始的視覺單詞W={wk}。
2)按式(4)計算wi和wj的語義共生概率p(wi,wj)。
3)按式(3)計算視覺單詞的上下文語義共生概率。
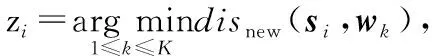
6)統計各幅圖像中視覺單詞的詞頻分布,生成圖像—單詞詞頻矩陣。
通過結合特征域和空間域,將圖像塊在空間域中的上下文語義共生性融入到傳統的單詞映射算法中。如當某一特征向量si的鄰域信息表明其屬于單詞wk的概率較高時,即使si在特征域內與wk的歐氏距離較大,上下文語義約束依然使其劃分到wk;反之亦然。改進后的算法在一定程度上解決了單詞的歧義現象,更準確地定義視覺單詞。
2.3 學習扣件圖像的主題分布
LDA中一幅圖像的生成步驟如下:
1)選擇θ~Dirichlet(α),其中θ是一個C×T的矩陣,行向量θi是第i幅圖像的主題分布向量;
2)對于每個圖像塊xi,從多項式分布θ抽樣主題tk,tk~Multi(θ),以概率p(wm|tk,β)選擇一個視覺單詞wm,β是一個K×V的矩陣,其元素βi,j=p(wi=1|tj=1)表示視覺單詞wi和主題tj同時出現的概率;
3)重復步驟(1)和步驟(2),進行圖像主題的選擇,通過主題產生對應的單詞,直到生成一幅完整的圖像。
LDA模型的學習過程是其生成模型的逆過程,采用吉布斯采樣可求解出模型中參數的近似值,從而獲得每幅圖像的主題分布。
2.4 算法整體流程
1)提取全體訓練圖像的底層特征向量S={∪si|i∈n},利用K-means聚類方法對S進行聚類,生成含K個視覺單詞的視覺詞典W;
2)計算每個特征向量si∈S到各個視覺單詞的歐氏距離dis(si,wk);
3)對于每個特征向量si,按式(5)更新其到每個視覺單詞的距離;
4)按更新后的距離disnew(si,wk),將特征向量映射到對應的視覺單詞,并統計得到圖像—單詞詞頻矩陣;
5)利用LDA模型學習扣件圖像的潛在主題分布;
6)構建支持向量機(support vector machine,SVM)分類器,對新的扣件圖像進行分類。
3 實驗與結果分析
3.1 實驗數據與配置
本文從采集的扣件圖像中選取共800幅作為實驗數據,其中正常、斷裂、丟失以及被遮擋的4類扣件圖像各200幅,均為120像素×180像素的灰度圖像。實驗計算機處理器為AMD Sempron X2 190 Processor 2.5 GHz,內存4.0 GB,在MATLAB 2014b環境下進行實驗。部分實驗樣本如圖2所示。

圖2 目標圖像狀態
3.2 實驗結果分析
1)詞典容量對分類性能的影響
改變視覺詞典容量的設置進行多次重復的實驗。圖3展示了在局部二值化模型(local binary pattern,LBP)、尺度不變特征變換(scale invariant feature transform,SIFT)以及方向梯度直方圖 (histogram of oriented gradient,HOG)3種不同的底層特征下,詞典容量的變化對正確率的影響。
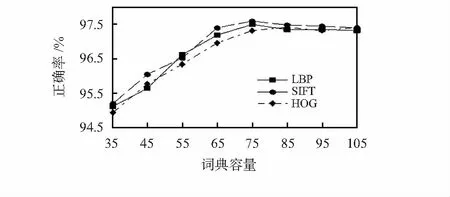
圖3 不同單詞數目時實驗正確率
觀察可知,隨著詞典容量的增加,不同底層特征下的測試結果正確率也在穩步提升。但當詞典容量大于某一特定值后,繼續增加視覺單詞數量,正確率不會繼續提高。這是因為過小的詞典容量造成了語義的丟失,而過大的詞典容量則會導致語義的冗余,進而影響測試結果的正確率。因此,在后續實驗中均選擇測試結果正確率相對較高的視覺詞典容量為75。
2)扣件檢測性能
將傳統“視覺詞包模型”方法[13]與本文方法進行比較,以衡量本文方法在扣件語義表達上的有效性;通過將本文方法與文獻[6]中的主成分分析方法、文獻[7]中的方向場(directional field,DF)方法以及文獻[8]中的LBP+SVM方法對比,以綜合評估本文方法的扣件檢測性能。
各種方法的實驗設置為:傳統“視覺詞包模型”與本文方法分別在LBP特征、SIFT特征和HOG特征的基礎上進行。對于本文方法,鄰域像素半徑設為2,鄰域像素個數設為8,主題數量T=40。上述參數設置均為優化值。文獻[6~8]中各方法的參數設置均與原文獻保持一致。實驗樣本采用本文創建的樣本庫。訓練集為每種狀態的扣件圖像各100幅,共400幅圖像,余下的作為測試集。訓練集與測試集的大小均為400。選擇LIBSVM[14]對扣件數據進行分類,實驗結果為10折交叉驗證(cross-validation)的平均值,并統計實驗結果的誤檢率和漏檢率。誤檢率=誤檢扣件數量/正常扣件總數量×100 %,漏檢率=漏檢扣件數量/失效扣件總數量×100 %,其中,丟失、斷裂、被遮擋的扣件均被視為失效扣件。檢測結果首先要求準確判斷出失效扣件,降低漏檢;其次是降低誤檢,減小浪費。各方法的檢測結果如表1所示。

表1 本文方法與其他方法的比較
實驗1和實驗2表明,在LBP特征下,本文方法顯著提高了傳統“視覺詞包模型”的扣件檢測性能:1)改進了視覺單詞的映射方式,既考慮了圖像塊的底層特征信息,又考慮了圖像塊的上下文約束信息,因此,能更準確地定義視覺單詞;2)提取了低維的主題分布,整合了語義信息,進一步降低了誤檢和漏檢。實驗3,4和實驗5,6這兩組實驗表明:在SIFT特征和HOG特征下,本文方法同樣能夠降低“視覺詞包模型”的漏檢率和誤檢率。
從實驗2,7,8,9中可以看出,文獻[6]的主成分方法和文獻[8]的LBP+SVM方法雖耗時較短,但誤檢率和漏檢率均較高。文獻[7]的方向場方法雖對失效扣件檢測效果較好,但誤檢率過高,且耗時較長。與現有方法相比,本文方法能更加有效地檢測扣件狀態。
4 結束語
通過引入吉布斯隨機場,將圖像塊在特征域的相似性同空間域的上下文語義信息結合起來,在一定程度上減小了底層特征與高層語義之間的“鴻溝”,提高了扣件檢測精度。在4類扣件數據集上的實驗獲得了較傳統“視覺詞包模型”更低的漏檢率和誤檢率,證明了本文模型的有效性和可行性。下一步的研究工作是如何綜合運用多種特征,更全面地挖掘扣件圖像的語義信息。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
