改進GWO優化SVM的語音情感識別研究
2018-08-20 03:43:04RYADChellali
計算機工程與應用 2018年16期
陳 闖,RYAD Chellali,邢 尹
CHEN Chuang1,RYAD Chellali1,XING Yin2
1.南京工業大學 電氣工程與控制科學學院,南京 211816
2.桂林理工大學 測繪地理信息學院,廣西 桂林 541004
1.College of Electrical Engineering and Control Science,Nanjing Tech University,Nanjing 211816,China
2.College of Geomatics and Geoinformation,Guilin University of Technology,Guilin,Guangxi 541004,China
1 引言
語音是人類交流的重要方式。語音信號中不僅傳遞了說話人的語義內容,也承載著說話人的情感狀態。如何有效識別語音信號中的情感類型是近年來人工智能領域的一個研究熱點。語音情感識別技術已經成功應用于輔助測謊[1]、遠程教學[2]、臨床醫學[3]等領域。
目前常用的語音情感識別方法主要有支持向量機(Support Vector Machine,SVM)、人工神經網絡(Artificial Neural Network,ANN)、隱馬爾可夫模型(Hidden Markov Model,HMM)、混合高斯分布模型(Gaussian Mixture Model,GMM)等[4]。SVM是機器學習領域的一個熱點算法,在解決非線性、小樣本以及高維模式識別中體現出特有的優勢,但其分類性能受其內部參數影響很大[5]。為此,許多學者提出將布谷鳥搜索算法[6](Cuckoo Search,CS)、差分進化算法[7](Differential Evolution,DE)、粒子群算法[8](Particle Swarm Optimization,PSO)等運用于SVM的參數尋優上,但這些優化算法對于提升SVM的性能仍比較有限。2014年,由Mirjalili等人[9]提出的灰狼算法(Grey Wolf Optimizer,GWO)在尋找最優解方面具備簡單、高效的特點而備受關注。為了進一步提升GWO的尋優性能,各種改進的GWO算法也應運而生。文獻[10]提出將極值優化算法融入GWO,增加了算法獲得全局最優解的概率;文獻[11]利用佳點集理論初始化種群,并對當前種群中最優個體使用Powell算法進行局部搜索,提升了算法的尋優性能,加快了收斂速度;文獻[12]提出采用反向學習改進GWO,并將算法并行化;文獻[13]提出采用非線性調整策略對GWO進行改進,平衡了種群全局搜索能力和局部搜索能力。
在前人研究的基礎上,本文提出在基本GWO算法中嵌入選擇算子和改進收斂因子,以此探索改進的灰狼算法(Improved Grey Wolf Optimizer,IGWO)的尋優性能。通過對10個基準測試函數的仿真實驗,驗證了IGWO算法尋優性能優于基本GWO算法。利用IGWO算法來對SVM參數進行優化,并采用優化后的參數建立了IGWO-SVM的語音情感分類模型。實驗結果表明,IGWO-SVM模型在對語音情感的識別上體現出了優越性。
2 改進灰狼算法
2.1 基本灰狼算法
灰狼算法是一種模擬灰狼群體狩獵活動的智能算法。灰狼群中包含社會等級最高的α狼,其次分別為β、δ和ω狼。群體捕食時,由α狼帶領,β和δ狼協助,ω狼追隨,完成對獵物的包圍、獵捕和攻擊等行為。
灰狼群在狩獵中,首先對獵物進行包圍,該過程的數學描述為:
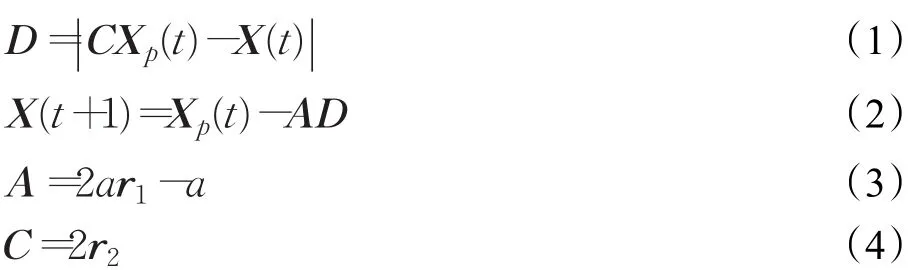
其中,Xp表示獵物的位置;X(t)表示第t代時灰狼個體的位置;A和C為系數向量;r1和r2為[0,1]的隨機數;a為收斂因子,a=2-2t/T,T為最大迭代次數。
其次,灰狼群進行獵捕。該過程由α、β和δ狼來引導,更新灰狼個體位置,數學描述為:
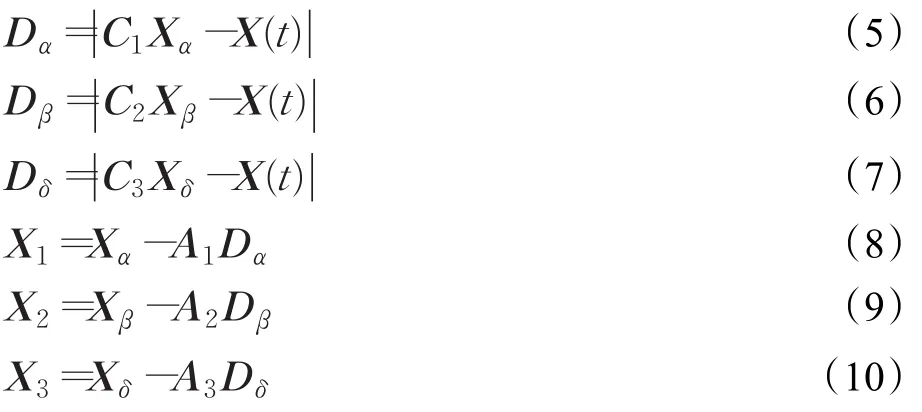

最后,灰狼群進行攻擊,完成捕獲獵物這一目標,即GWO算法獲得的最優解。攻擊行為主要依據式(3)中a值由2遞減到0來實現。當時,灰狼群對獵物集中攻擊,對應于局部搜索;當時,灰狼散去,進行全局搜索。
2.2 嵌入選擇算子
Haupt等人[14]認為,多樣性較好的初始種群對提高群體智能算法的尋優性能具有積極意義。基本灰狼算法以隨機方式生成初始種群,初始種群雖然具備一定的種群多樣性,但種群水平未必較好,影響算法的收斂速度和精度。在隨機生成初始種群之后,嵌入選擇算子[15],將有利于提升基本GWO的尋優性能,具體操作如下:
(1)隨機生成初始灰狼種群,并計算每個個體適應度值。
(2)根據適應度值,由小到大排列,分為前、中、后三段。
(3)每段按照1.0、0.8和0.6的比例隨機選擇個體。
(4)對于損失的個體,以前段的個體進行補充,插入步驟(3)所選擇的個體之后,形成新種群。
上述的選擇算子采取優者多選、劣者少選的策略,提升了初始種群整體水平,同時兼顧了種群多樣性,操作簡單。
2.3 非線性收斂因子
群體智能優化算法一般面臨著全局搜索與局部搜索能力平衡的問題。為了解決GWO在兩者之間的平衡問題,文獻[13]提出了一種改進的收斂因子a,具體公式如下:

其中,e為自然對數的底數;t為當前迭代次數;T為最大迭代次數。初始階段a衰減程度降低,以便算法全局尋優;后期提升a的衰減程度,對應于算法精確局部尋優。但在實際使用中發現,a不同的衰減程度對應于不同的GWO搜索性能。為此,本文提出一種改進的非線性收斂因子如下:

其中,p為衰減階數,在[0,10]之間取整數,p越大對應收斂因子a衰減越劇烈,如圖1所示。
2.4IGWO算法實施步驟
(1)給定種群規模N,最大迭代次數T,初始化a、A和C等參數。
(2)根據2.2節中的選擇算子確定新種群。
(3)根據式(13)計算a,更新A和C。
(4)根據式(5)~(11)更新個體位置。

圖1 收斂因子對比圖
(5)如果達到最大迭代次數,則輸出最優個體位置和最優值;否則,返回步驟2。
3 改進灰狼算法優化支持向量機模型
3.1 支持向量機
支持向量機是一種基于統計理論的分類算法,在模式識別和數據挖掘領域有著廣泛應用[16]。對于非線性可分樣本,它的基本思想是引入核函數將輸入特征樣本映射到高維空間中,然后尋求此空間中的超平面使得樣本線性可分。對于非線性可分的SVM優化問題可描述為:

式中,w為權系數向量;b為分類閾值;C(C>0)為懲罰因子,用來平衡分類誤差與推廣性能;ξi(ξi≥0)為松弛變量,用來衡量對應樣本xi相對于理想條件下的偏差;L為訓練樣本個數;為類別標號。假設低維輸入空間到高維特征空間的映射函數為Φ,應用核函數變換等式 (xi,xj)→K(xi,xj)=Φ(xi)?Φ(xj),得到最終的分類超平面函數為:

式中,ai為拉格朗日因子;K(xi,x)為核函數。目前常用的幾種核函數有多項式核函數、RBF核函數、S型核函數。本文采用RBF核函數,對應公式如下:
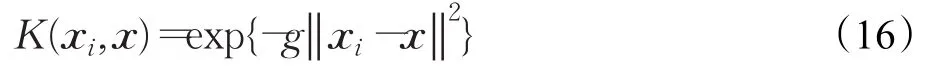
3.2IGWO-SVM分類模型建立步驟
(1)初始化灰狼種群,每個個體位置由C和g組成。
(2)SVM依照個體位置中的C和g,對訓練集進行學習,以測試集SVM分類錯誤率作為個體適應度函數。
(3)采用IGWO算法對灰狼群個體位置進行更新。進化過程結束時,返回最優個體位置,即C和g值。
(4)采用優化后的C和g建立SVM分類模型。
4 實驗結果及分析
4.1IGWO算法性能分析實驗
為了驗證本文提出的兩種改進策略的有效性,選取10個基準測試函數,見表1。表1列出了這10個函數的基本信息,包括3個單峰基準測試函數(F1~F3),3個多峰基準測試函數(F4~F6)和4個固定維度多峰基準測試函數(F7~F10)。為公平起見,所有算法的種群規模統一設置為30,最大迭代次數為500。
為了消除隨機性對結果的影響,取30次運行結果的平均值作為最終結果。考慮到篇幅限制,選取Sphere、Schwefel’s Problem 2.22和Ackley函數考察不同衰減階數對算法的影響,如圖2所示。
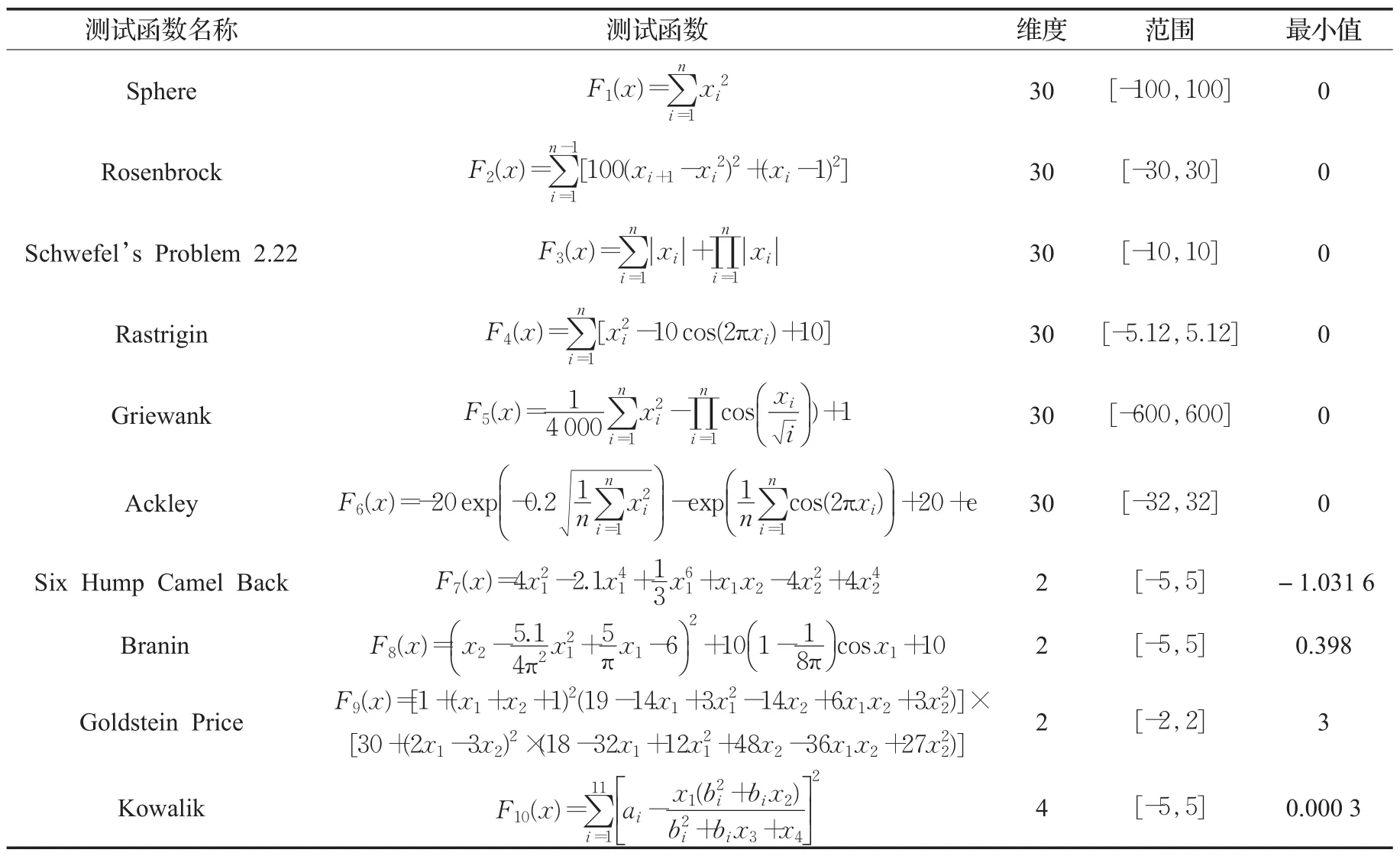
表1 10個基準測試函數

圖2 Sphere、Schwefel’s Problem 2.22和Ackley函數的不同衰減階數尋優收斂曲線

表2 對10個基準測試函數的測試結果
從圖2中可以看出,采用非線性收斂策略提升了GWO的尋優精度,且隨著衰減階數p的增大而增高,當p增大到4時,尋優精度穩定,說明p=4是一個較佳的衰減階數。
為了說明IGWO的優越性,GWO、IGWO1、IGWO2和IGWO對10個基準測試函數的測試結果見表2。其中,IGWO1表示嵌入選擇算子的改進GWO,IGWO2表示引入非線性收斂因子(p=4)的改進GWO,IGWO表示兩種改進策略混合的改進GWO。
從表2中可以看出,對于單峰基準測試函數F1~F3,IGWO1和IGWO2在函數F1和F3上均表現良好;引入選擇算子和非線性收斂因子的IGWO綜合了IGWO1和IGWO2的優點,在函數F1和F3上將性能發揮至最大,尋優結果更接近目標函數最優值,且穩定性更好。對于多峰基準測試函數F4~F6,IGWO和IGWO2在函數F4上都尋找到了目標函數的最優值0,且標準差為0;對于函數F5和F6,IGWO都好于另外3種算法。對于固定維度多峰基準測試函數F7~F10,3種算法對于函數F7~F9的尋優效果相當;對于函數F10,IGWO2表現最好,更接近目標函數最優值。綜上,IGWO在大多數函數上不僅提升了搜索精度,且尋優結果更加穩定。
為了直觀地反映各算法的尋優性能,圖3示例性地給出了各算法對于Sphere、Rastrigin和Ackley函數的尋優收斂曲線。
從圖3中可以看出,IGWO1和IGWO2均提升了基本GWO的尋優性能,尤其是嵌入選擇算子和引入非線性收斂因子的IGWO具有更高的收斂精度和更快的收斂速度。
4.2 語音情感識別實驗

圖3 Sphere、Rastrigin和Ackley函數的尋優收斂曲線
本文的實驗樣本來源于柏林情感語音庫[17]。該語音庫在語音情感識別領域應用廣泛,許多語音情感識別研究成果均在此語音庫上進行驗證。本文選取其中生氣、開心、平靜、傷心和害怕5種常見情感,經過人耳的辨別試聽,最終保留了400條語音樣本,具體為生氣126條,開心68條,平靜78條,害怕66條,訓練樣本和測試樣本以1∶1比例隨機分配。實驗中,選取短時能量、基音頻率、共振峰和梅爾頻率倒譜系數(Mel Frequency Cepstral Coefficient,MFCC)這4類語音情感特征構建實驗數據,具體為短時能量、基音頻率、第一二三共振峰、0~12階MFCC及其一階差分的最大值、最小值、均值和方差。具體計算方法詳見參考文獻[18]。將提取的語音情感特征按照式(17)進行歸一化處理:

其中,x表示原始語音情感特征;xmin和xmax分別表示特征的最小值和最大值。
為了驗證IGWO-SVM模型對于語音情感分類的優越性,分別采用布谷鳥搜索算法(CS)、差分進化算法(DE)、粒子群算法(PSO)、灰狼算法(GWO)和改進灰狼算法(IGWO)對SVM參數進行尋優。語音情感實驗中,采用十折交叉驗證技術,即將原始數據集隨機分成10等份,其中9份用于SVM訓練,剩下的1份用于驗證。統一設置所有優化算法的種群規模為30,最大迭代次數為200,此參數設置均保證了各尋優算法達到收斂狀態。其中CS被宿主發現概率為0.25;DE交叉概率因子為0.8;PSO加速因子均為1.5。SVM參數尋優范圍設置為C∈[0.01,100],g∈[0.01,100]。各算法對SVM參數的尋優結果見表3。
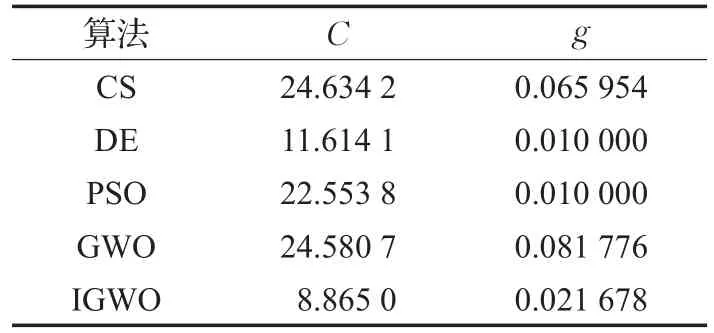
表3SVM參數尋優結果
將表3中的C和g分別作為SVM參數,對訓練集進行學習,分別建立CS-SVM、DE-SVM、PSO-SVM、GWO-SVM和IGWO-SVM語音情感分類模型。
IGWO-SVM模型的5種情感識別結果,如圖4所示。其中橫坐標表示測試集樣本的樣本序號,縱坐標類別標簽1~5依次對應生氣、開心、平靜、傷心和害怕情感。統計5種模型的語音情感識別結果,見表4。從表4中可以看出,IGWO-SVM和CS-SVM模型的語音情感平均識別率最高,均為93.50%(187/200)。由表3可知,IGWO的參數尋優結果C=8.8650,小于CS的參數尋優結果C=24.6342,減少了SVM過學習的可能性。因此,采用IGWO對于SVM的優化是有效的,可以提升語音情感的識別率。

圖4IGWO-SVM模型的語音情感識別結果
5 結束語
本文首先介紹了GWO的基本原理,并針對GWO在尋優過程中易陷入局部最優的缺點,提出嵌入選擇算子和引入非線性收斂因子來提升GWO的尋優性能。通過對10個基準測試函數的仿真實驗,驗證了IGWO的優越性。采用IGWO對SVM的懲罰因子和核函數參數進行優化,并構建了IGWO-SVM的語音情感分類模型。相比于CS、DE、PSO和GWO優化的SVM模型,IGWOSVM模型有效提升了語音情感識別率。針對實驗結果中傷心情感識別率偏低的情況,下一步將從特征提取角度提取短時能量、基音頻率和共振峰的衍生參數,探討對傷心情感識別的影響。

表4 不同模型的語音情感分類結果
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年6期)2016-08-21 13:49:38
