深度學(xué)習(xí)下智能寫稿輔助服務(wù)的設(shè)計與實(shí)踐
2018-08-21 03:56:54任海平
傳媒論壇 2018年4期
任海平
(浙江日報報業(yè)集團(tuán)產(chǎn)品研發(fā)中心,浙江 杭州 310039)
一、引言
隨著媒體大數(shù)據(jù)時代的到來,媒體用戶獲取信息的渠道變得越來越豐富,也越來越便利,而日益快速增長的新聞資源不僅給新聞出版行業(yè)發(fā)展帶來巨大的機(jī)遇,更帶來了前所未有的挑戰(zhàn)。這些挑戰(zhàn)是多層次、多方面的,本文聚焦其中的技術(shù)挑戰(zhàn)——如何高效利用海量新聞資源提升新聞制作水平,立足浙報集團(tuán)媒體出版特色,利用深度學(xué)習(xí)的模型設(shè)計并實(shí)現(xiàn)智能寫稿輔助服務(wù)平臺。
要實(shí)現(xiàn)高質(zhì)量的智能寫稿輔助功能,關(guān)鍵技術(shù)難點(diǎn)是如何快速有效地從海量新聞文本中把與當(dāng)前撰寫稿件相關(guān)的新聞資料匯聚起來,形成有價值的創(chuàng)作素材。由于這種匯聚要求在語義上是高度相關(guān)的,因此簡單利用關(guān)鍵詞搜索不僅費(fèi)時費(fèi)力,也無法取得匯聚的良好效果。利用機(jī)器學(xué)習(xí)的方法,實(shí)現(xiàn)新聞文本資源的自動聚類是一個較好的解決方案。傳統(tǒng)面向文本聚類的機(jī)器學(xué)習(xí)方法主要包括:基于決策樹、基于概率圖模型和基于向量空間等各類方法。然而,這些方法都屬于淺層模型,無法利用不斷增長的文本數(shù)據(jù)來提高聚類效果,甚至?xí)陆怠R虼耍疚牟捎蒙疃葘W(xué)習(xí)的模型,實(shí)現(xiàn)新聞文本資源的高質(zhì)量聚類。具體而言,我們利用深度學(xué)習(xí)模型對文本進(jìn)行層層特征提取并降維,最終獲得較為精練的文本特征代碼,使得在語義上相關(guān)度較高的文本代碼,在語義空間中的距離也是相近的,從而實(shí)現(xiàn)相關(guān)資料的匯聚。
在內(nèi)容創(chuàng)作過程中,利用訓(xùn)練好的深度模型,系統(tǒng)可以動態(tài)提取當(dāng)前稿件內(nèi)容(甚至只是一個標(biāo)題),生成語義代碼,并快速從海量媒資庫中捕捉到與當(dāng)前最為相關(guān)的文本素材,第一時間推送至寫稿平臺,供內(nèi)容創(chuàng)作者參考使用,這便是本文闡述的智能寫稿輔助服務(wù)。由此項(xiàng)技術(shù)衍生出“主題延展”“稿件背景”“自動摘要”甚至機(jī)器寫作等場景應(yīng)用,讓內(nèi)容創(chuàng)作者真正享受到人工智能時代的紅利。
二、基于深度學(xué)習(xí)的文本聚類模型
寫稿的智能內(nèi)容輔助的關(guān)鍵技術(shù)難點(diǎn)在于如何根據(jù)寫稿人當(dāng)前錄入的部分內(nèi)容,在語義空間中生成相應(yīng)的語義代碼(向量),并快速在媒質(zhì)庫中獲取和該語義代碼距離最為接近的相關(guān)文本資料。因此,這在機(jī)器學(xué)習(xí)領(lǐng)域中是一個典型的文本聚類問題,即利用高效的算法實(shí)現(xiàn)針對在人看來語義相近的文本在虛擬語義空間中也是距離相近的。
為此首先我們要對文本進(jìn)行建模,目前最為常用的建模方式是“文檔-詞”矩陣(簡稱“D-T”矩陣):A=(aik),其中aik是矩陣中的元素,目前大多采用TF-IDF權(quán)重法。在此基礎(chǔ)上,本文利用深度學(xué)習(xí)模型從“D-T”矩陣中生成高質(zhì)量的語義特征代碼,利用這種代碼,可以高效地獲得和寫稿內(nèi)容相關(guān)文本資料。在闡述新方法之前,我們首先回顧一下傳統(tǒng)文本聚類的主要方法。
(一)傳統(tǒng)文本聚類的主要方法
為實(shí)現(xiàn)有效的文本聚類,機(jī)器學(xué)習(xí)領(lǐng)域已經(jīng)做了長期的探索,并取得長足進(jìn)展。從技術(shù)實(shí)現(xiàn)路線劃分,傳統(tǒng)文本聚類算法大致分為以下三種:
1.基于決策樹的模型
決策樹(Decision Tree)是一種利用樹狀結(jié)構(gòu)來描述一個決定和其產(chǎn)生結(jié)果的模型,并且在樹的結(jié)構(gòu)中,賦予每個結(jié)果一定的可能性。其中主要典型算法包括:ID5、C4.5、QUEST、PUBLIC等。決策樹的優(yōu)勢在于邏輯和規(guī)則的可解釋性,對于非大量的強(qiáng)數(shù)據(jù)集,結(jié)合領(lǐng)域?qū)<业慕?jīng)驗(yàn),決策樹可以取得較好的效果。
2.基于概率圖的模型
概率圖模型是文本挖掘中應(yīng)用最為廣泛的一種模型,它的基本假設(shè)是不同的文本擁有不同詞的聯(lián)合概率分布,換句話說,不同詞的概率組合將產(chǎn)生不同類型的文本,其中典型模型包括:樸素貝葉斯分類器(Na?ve Bayes Classifier),pLSA(Probabilistic Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)等。該類算法模型,能夠發(fā)展各種更加復(fù)雜的模型,并在新聞文本語義分析中做出很大的貢獻(xiàn)。
3.基于向量空間的模型
基于向量空間的模型立足“D-T”矩陣,每一行代表一個文檔,它在向量空間中為一個向量,每一個分量代表詞的權(quán)重。該類模型通過各種向量空間的變換來估算兩篇文本的相似度,其中典型模型包括:支持向量機(jī)(Support Vector Machine,SVM)、k個最鄰近(k-Nearest Neighbor,kNN)算法和支持向量聚類(Support Vector Clustering,SVC)模型等。
這三類算法模型均屬于淺層模型,其主要局限性體現(xiàn)在,它們無法充分利用不斷增長的文本大數(shù)據(jù)來提升其性能(甚至?xí)陆担瑫r無法實(shí)現(xiàn)多層次隱含語義的高效分析。因此,本文采用深度學(xué)習(xí)的方法實(shí)現(xiàn)高效語義代碼的提取并聚類。
(二)基于深度學(xué)習(xí)的文本聚類模型
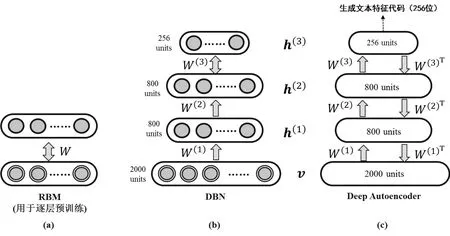
圖1
為充分利用媒資庫中海量的新聞文本數(shù)據(jù),提升聚類的效果,本文采用了深度學(xué)習(xí)模型,生成蘊(yùn)含有效語義的文本代碼的基礎(chǔ)上,實(shí)現(xiàn)高質(zhì)量文本聚類。目前深度學(xué)習(xí)比較主流的模型有CNNs(Convolutional Neural Networks)、DGMs(Deep Generative Models) 和 RNNs(Recurrent Neural Networks)。由于文本聚類是非監(jiān)督學(xué)習(xí),因此我們采用屬于DGMs中DBNs(Deep Belief Networks, DBNs),如圖1(b)所示。
圖1是基于DBN的文本聚類模型示意圖,(a)是RBM,用于逐層預(yù)訓(xùn)練;(b)是DBN,為本文主模型[2000,800, 800, 256];(c)是在DBN精調(diào)過程中,展開的Deep Autoencoder。
DBNs是一種混合多層概率圖模型,它可以利用RBMs(Restricted Boltzmann Machines)實(shí)現(xiàn)層層預(yù)訓(xùn)練(pre-training)來獲得多層次特征的提取。而RBM是一種基于能量的模型,預(yù)訓(xùn)練的詳細(xì)過程可詳見Hinton的成果。
要提取文本的語義特征,并生成代碼,首先要利用首層RBM對文本進(jìn)行采樣和建模。首先,我們利用傳統(tǒng)方法獲得文本“D-T”矩陣。由于每篇文本的長度不同,因此我們采用的方式是復(fù)制Softmax模型進(jìn)行首層采樣和預(yù)訓(xùn)練,具體采樣公式如下:

公式(1)(2)
其中vik,為第i篇文本的第k個分量,h(1)為第1隱藏層,{W(1),a(1),b(1),}為第1層RBM的參數(shù),g(x)=1/(1+exp(-x))為Logistic函數(shù)。在此基礎(chǔ)上,利用多層RBM分別對{h(1),h(2),h(3),}進(jìn)行訓(xùn)練,并在h(3)上獲得文本的特征代碼。此時的特征代碼還不是最優(yōu)化的,需要將DBN展開成為一個稱之為Deep Autoencoder的深度編碼器,并利用反向傳播(Backprogation)機(jī)制,獲得最優(yōu)化的代碼,如圖1(c)所示。這里反向出傳播的目標(biāo)函數(shù)選擇交叉熵的偏差(cross-entropy error)函數(shù):

公式(3)
其中,vi(input)為第篇文本,vi(output)為第i篇文本通過層層采樣后的輸出,M為文本的數(shù)目。
深度編碼器對DBN的參數(shù)做進(jìn)一步優(yōu)化之后,我們可以在深度模型的頂層h(3)獲得文本較高質(zhì)量的特征代碼,我們將該特征代碼存入媒資庫的每篇文稿的記錄中,并在智能寫稿輔助服務(wù)中,用于語義相關(guān)性的聚類和搜索。
三、智能寫稿輔助服務(wù)的設(shè)計
在確立了上述理論和技術(shù)模型后,接下來就是如何將其應(yīng)用于媒體內(nèi)容采編環(huán)節(jié),賦予更多的智能。為此,我們選擇了智能寫稿輔助服務(wù)作為切入點(diǎn)。在傳統(tǒng)的寫稿功能設(shè)計中往往只實(shí)現(xiàn)了一些常規(guī)性功能,如:發(fā)稿單欄設(shè)置、內(nèi)容編輯、文字修飾、字行統(tǒng)計、文章關(guān)聯(lián)、檢索等,這些功能只對成文方面提供了一定幫助。隨著媒體對內(nèi)容創(chuàng)作的數(shù)量、質(zhì)量、效率以及非同質(zhì)化要求越來越高,這些傳統(tǒng)功能早已無法滿足新的需求。創(chuàng)作者們渴望通過新技術(shù)手段來提升內(nèi)容策劃、內(nèi)容組織、背景資料查找以及關(guān)聯(lián)信息挖掘能力,為內(nèi)容“編碼”,實(shí)現(xiàn)知識增量,快速形成精品原創(chuàng)。
(一)數(shù)據(jù)源采集
要形成有效的智能寫稿輔助服務(wù),首先要構(gòu)建一套海量的、存放高質(zhì)量語義特征代碼的媒資庫,這也是內(nèi)容基礎(chǔ)。目前能為媒體所用的數(shù)據(jù)源非常廣泛,就以浙報集團(tuán)“媒立方”項(xiàng)目而言,數(shù)據(jù)的采集分為了資源圈與分析圈,覆蓋了新聞、資訊、交互性內(nèi)容范疇,包括但不局限于集團(tuán)采編資源、歷史媒資數(shù)據(jù)、全網(wǎng)重點(diǎn)新聞(如:媒體網(wǎng)站、政府門戶、微博、微信、論壇、新聞爆料、數(shù)字報、APP)以及民眾互動數(shù)據(jù)等,如圖2。
(二)數(shù)據(jù)源處理
接下來就是對這些采集數(shù)據(jù)的清洗處理,包括脫敏(保留隱私性)、清理(保留有效數(shù)據(jù))、加標(biāo)簽(分類)等前序工作,形成初始數(shù)據(jù)源(圖2-[S1])。若計算資源充足,還可對初始數(shù)據(jù)源按信息階段(信息發(fā)現(xiàn)、信息跟蹤、信息挖掘、信息推薦、信息評估)和信息性質(zhì)(速度、廣度、準(zhǔn)度、深度、流行度)兩大需求方向進(jìn)行二次結(jié)構(gòu)化預(yù)處理,形成初始數(shù)據(jù)源(圖2-[S2])。最后,利用深度學(xué)習(xí)模型,將預(yù)處理結(jié)果數(shù)據(jù)進(jìn)行特征代碼計算、提取、存儲,形成真正可利用的優(yōu)質(zhì)信息,供智能寫稿服務(wù)使用。
(三)功能應(yīng)用
根據(jù)實(shí)際應(yīng)用需要,我們設(shè)計了兩類智能寫稿輔助服務(wù):主題延展和背景資料,并在浙報集團(tuán)“媒立方”項(xiàng)目的融合寫稿編輯器中應(yīng)用,并取得了非常好的效果。
1.主題延展的實(shí)現(xiàn)與效果
主題延展可動態(tài)獲取當(dāng)前稿件相似主題、相似內(nèi)容在其他媒體的報道文章。對于該場景設(shè)計,需要將智能輔助服務(wù)掛鉤內(nèi)容編輯的全過程,隨著創(chuàng)作內(nèi)容篇幅的越來越長,其文章主題也逐漸清晰,當(dāng)完成整段內(nèi)容輸入,系統(tǒng)即可觸發(fā)機(jī)器深度學(xué)習(xí)算法服務(wù),對當(dāng)前已輸入內(nèi)容進(jìn)行分析并抽取語義特征代碼。與此同時,該服務(wù)與后臺媒資庫海量語義特征碼進(jìn)行匹配,當(dāng)超過預(yù)設(shè)的匹配值后,系統(tǒng)便可獲取相似度最高的文章推送至用戶端。
對于相似主題文章的展示,我們在設(shè)計上應(yīng)包括:標(biāo)題、摘要、來源、發(fā)布時間,具體控制如表1所示。

表1 各要素設(shè)計說明
在“媒立方”項(xiàng)目融合編輯器設(shè)計中,我們?yōu)榫庉嬈鞯挠覀?cè)欄專門設(shè)計了智能輔助頁簽欄,可別小看這幾個頁簽,已經(jīng)成為記者編輯在內(nèi)容采編過程中不可或缺的助手。一旦創(chuàng)作者開始內(nèi)容寫作,“主題延展”服務(wù)便根據(jù)編輯器中的內(nèi)容進(jìn)行智能分析,并實(shí)時地將匹配到的信息推送至編輯窗右側(cè)頁簽內(nèi),設(shè)計界面如圖3:

圖3:主題延展界面展示
(1)查閱結(jié)果:“主題延展”結(jié)果內(nèi)容以瀑布流式顯示,并分布在稿件編輯器右側(cè),用戶點(diǎn)擊任意一篇內(nèi)容即可打開查閱原文。對于長標(biāo)題,只需將鼠標(biāo)放置標(biāo)題位置,便會彈出浮動信息窗,完整顯示標(biāo)題內(nèi)容。當(dāng)結(jié)果文章數(shù)過多并超出本頁,可單點(diǎn)擊“展開更多”進(jìn)行全量查閱。

圖2:數(shù)據(jù)源采集與處理框架
(2)內(nèi)容選取:內(nèi)容選用方式在設(shè)計上要突出方便、快速,因此在本設(shè)計中,我們約定了鼠標(biāo)拖拽方式,通過鼠標(biāo)拖動即可將所選文章內(nèi)容、圖片、音視頻,插入至編輯器正文光標(biāo)位置。
(3)主題延展內(nèi)容更新:每次觸發(fā)“主題延展”功能,均會對當(dāng)前正文內(nèi)容進(jìn)行一次深度學(xué)習(xí),并同步更新“主題延展”結(jié)果內(nèi)容清單。內(nèi)容更新的觸發(fā)機(jī)制有很多種,可以在內(nèi)容增刪改查時觸發(fā),亦可在換行、換段以及保存時觸發(fā),為了最大程度避免影響寫作體驗(yàn),同時又能達(dá)到主題延展效果,最終我們選定了“回車換行”作為主要觸發(fā)機(jī)制。
2.稿件背景的實(shí)現(xiàn)與效果
“稿件背景”是從當(dāng)前稿件內(nèi)容中抽取人名、地名、機(jī)構(gòu)名等關(guān)鍵詞,加以解釋,或列舉這些關(guān)鍵詞在歷史重要媒體報道中的描述,為內(nèi)容創(chuàng)作者提供稿件背景資料。同理,在該場景設(shè)計中,用戶在內(nèi)容創(chuàng)作到達(dá)一定篇幅后,系統(tǒng)會根據(jù)已輸入內(nèi)容觸發(fā)機(jī)器深度學(xué)習(xí)服務(wù),確立人名、地名、機(jī)構(gòu)名等關(guān)鍵詞以及語義特征代碼,并與媒資庫海量語義特征碼進(jìn)行匹配,獲取相似度最高的文章推送給用戶端,為內(nèi)容創(chuàng)作者提供文章相關(guān)的高價值信息。對于稿件背景結(jié)果的展示,在設(shè)計上包括:標(biāo)題、摘要、來源、發(fā)布時間,展示控制與“主題延展”相同。但不同的是,稿件背景的核心匹配目標(biāo)是文章關(guān)鍵詞,如:人名、地名、機(jī)構(gòu)名以及其他關(guān)鍵詞,通過不同組合的關(guān)鍵詞選擇,將會產(chǎn)生不同的背景資料呈現(xiàn)結(jié)果。
在“媒立方”項(xiàng)目融合編輯器設(shè)計中,我們同樣為編輯器的右側(cè)欄專門設(shè)計了“稿件背景”智能輔助頁簽。在內(nèi)容創(chuàng)作過程中,系統(tǒng)會自動從當(dāng)前稿件中抽取人名、地名、機(jī)構(gòu)名等關(guān)鍵詞,并列舉這些關(guān)鍵詞在各類媒體報道中的詳細(xì)描述,為內(nèi)容創(chuàng)作者提供文章相關(guān)背景信息。例如:一篇稿件中引用了某一句詩歌、典故,通過背景資料就可以快速定位到這句詩歌、典故的完整原創(chuàng)內(nèi)容。設(shè)計界面如下:

圖4:稿件背景界面展示
“稿件背景”以瀑布流方式顯示關(guān)鍵詞所定位的原文內(nèi)容,用戶可在稿件編輯器右側(cè)“稿件背景”欄點(diǎn)擊查閱。各類關(guān)鍵詞間以“and”搜索關(guān)系約束,且同一類關(guān)鍵詞約束為單選,不同類關(guān)鍵詞允許多選。內(nèi)容選用方式、內(nèi)容更新與“主題延展”功能設(shè)計一致。
四、結(jié)束語
本文詳細(xì)闡述了基于深度學(xué)習(xí)的智能寫稿輔助服務(wù)的關(guān)鍵技術(shù)和設(shè)計方案,其出發(fā)點(diǎn)是讓機(jī)器(服務(wù)器計算資源)充分進(jìn)入內(nèi)容信息源領(lǐng)域,幫助我們完成第一道最費(fèi)時費(fèi)力的數(shù)據(jù)收集和結(jié)構(gòu)化處理工作,讓海量的內(nèi)容資源庫成為真正有價值的知識庫。當(dāng)然對算法模型的優(yōu)化與實(shí)踐還需要一個過程,可以預(yù)見,在不久的將來,通過人工智能深度學(xué)習(xí),必然會帶來包含內(nèi)容生產(chǎn)要素在內(nèi)的衍生變化,甚至引發(fā)傳統(tǒng)信息流生產(chǎn)方式的顛覆。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
