一種基于分子結構設計理論的聚類分析方法
2018-08-27 13:30:14張西寧唐春華
振動與沖擊 2018年15期
張西寧, 雷 威, 唐春華, 向 宙
(西安交通大學 機械工程學院 機械制造系統(tǒng)工程國家重點實驗室,西安 710049)
故障診斷的本質屬于模式識別,即當輸入矢量屬于不同類別時,對該矢量所屬類別做出正確的判斷,亦稱聚類[1]。故障診斷包括信號采集、特征提取和狀態(tài)識別三個環(huán)節(jié),其中信號采集是故障診斷的前提,特征提取是關鍵,而狀態(tài)識別則是故障診斷的核心[2]。
故障診斷的經(jīng)驗方法通常需要具有已知故障類別的信號樣本進行監(jiān)督訓練,然而,在實際故障診斷中很難得到不僅完備而且具有良好通用性的故障樣本[3]。無監(jiān)督聚類在沒有任何已知樣本學習的前提下,通過分析數(shù)據(jù)的內(nèi)在結構,根據(jù)樣本相似度或概率密度函數(shù)估計方法實現(xiàn)樣本的正確分類[4]。無監(jiān)督聚類因其實現(xiàn)不需要任何訓練樣本,廣泛應用于入侵檢測[5-7]、圖像處理[8-9]、數(shù)據(jù)挖掘[10]、故障診斷[11-14]等領域。
無監(jiān)督聚類方法可以被分為以下幾類:基于劃分的方法、基于層次的方法、基于網(wǎng)格的方法、基于密度的方法以及基于模型的方法[15]。常用的基于劃分的聚類方法有K-均值、K-中心點以及CLARA法(Clustering Large Applications)等;基于層次聚類方法的有BIRCH法(Balanced Iterative Reducing and Clustering using Hierarchies)、CURE(Clustering Using Representatives)法等;基于網(wǎng)格的方法有STING(Statistical Information Grid)、WaveCluster等;基于密度的方法有DBSCAN(Density-Based Spatial Clustering of Applications with Noise)、OPTIC(Ordering Point to Identify the Cluster Structure)等;基于模型的方法有競爭學習、SOM(Self-Organizing Map)等[16]。此外,主分量分析(Principal Component Analysis,PCA)也是一種能夠發(fā)現(xiàn)數(shù)據(jù)模式和結構的無監(jiān)督聚類方法[17]。
無監(jiān)督聚類算法多種多樣,每種方法都有其優(yōu)缺點。比如,基于模型的聚類方法SOM具有可視化、拓撲結構保持以及概率保持等優(yōu)點[18],被廣泛地應用于語音識別、模式聚類、組合優(yōu)化等眾多信號處理領域。但也存在著許多不足[19]:當樣本數(shù)據(jù)維數(shù)較高時,其從高維到低維的映射會出現(xiàn)較大的畸變;而且聚類結果容易受連接權向量的初始狀態(tài)的影響;“死神經(jīng)元”現(xiàn)象導致學習效率低,收斂時間長。楊松等[20]針對 SOM 網(wǎng)絡在分類中由于其初始權值的隨機性而導致的訓練次數(shù)過多且易陷入局部最小的問題,提出了利用遺傳算法改進網(wǎng)絡初始權值的設置。鄒瑜等[21]針對SOM在圖像分割中,隨著神經(jīng)元數(shù)量增加,網(wǎng)絡分割性能變差,且無法分割噪聲強度過大的圖像的問題,提出將有限脈沖響應(FIR)加入SOM,把每個神經(jīng)元作為FIR系統(tǒng),分割效果優(yōu)于基于SOM的方法。陶剛等[22]提出了一種改進的SOM聚類離散化算法,利用SOM實現(xiàn)初始聚類,以初始聚類中心為樣本,通過層次方法BIRCH進行二次聚類,有效地解決了大樣本,高維數(shù)據(jù)離散化問題。此外,大部分無監(jiān)督聚類方法在聚類過程中僅考慮類內(nèi)元素的關系而忽略了類間元素的關系,從而丟失掉了類間元素的相對位置以及距離信息[23]。
針對上述無監(jiān)督聚類算法中存在的問題,本文提出了一種基于分子結構設計理論的聚類分析方法。該方法將故障樣本空間看作分子系統(tǒng),將故障樣本看作分子系統(tǒng)中的原子,以故障樣本之間的差異度作為分子勢能的度量指標,在故障樣本間“相互作用勢”的影響下,以樣本間“勢能”最小為依據(jù),調(diào)整故障樣本在映射平面上的位置,從而獲得最佳的聚類效果。本文以滾動軸承和柴油機的故障數(shù)據(jù)為例進行聚類分析,并與SOM聚類方法進行對比,驗證所提方法的有效性。
1 分子結構設計理論
分子力學是模擬分子行為的一種計算方法,分子力學認為分子體系的勢能函數(shù)是分子體系中原子位置的函數(shù)[24]。這些原子在空間上過于靠近,便互相排斥;但又不能遠離,否則連接他們的化學鍵以及由這些鍵構成的鍵角等會發(fā)生變化,引起分子內(nèi)部應力的增加。分子力學從本質上說是能量最小值方法,即在粒子間相互作用勢的作用下,通過改變粒子分布的幾何位型,以能量最小為依據(jù),從而獲得體系的最佳結構[25]。
分子結構設計的流程如圖1所示,首先給出分子中各原子的初始坐標及其連接關系;其次按不同的聯(lián)接關系,選擇不同的勢能函數(shù)以及勢能場參數(shù);計算分子空間內(nèi)的總勢能,即原子間勢能的疊加;然后求出分子空間內(nèi)勢能場的最小值點;更新原子在分子空間的坐標,并進行循環(huán)迭代直到原子位置收斂。
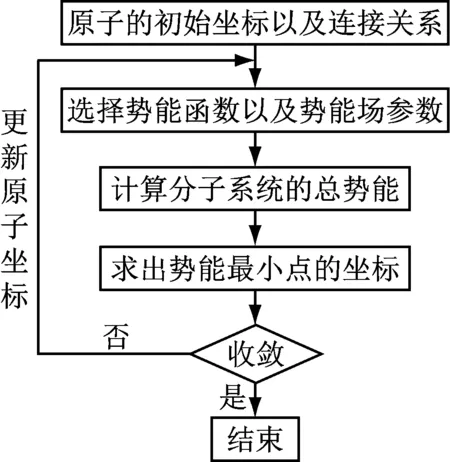
圖1 分子結構設計的流程
2 基于分子結構設計理論的聚類分析方法的原理
借鑒分子結構設計的思想,提出一種新的聚類分析方法。該方法由兩層網(wǎng)絡結構組成:第一層為輸入層,節(jié)點數(shù)目與數(shù)據(jù)樣本維數(shù)相同;第二層為決策層(決策平面),其形式可以是二維棋盤平面,也可以是三維空間結構。本文以二維棋盤平面為例進行說明,其結構示意圖如圖2所示。
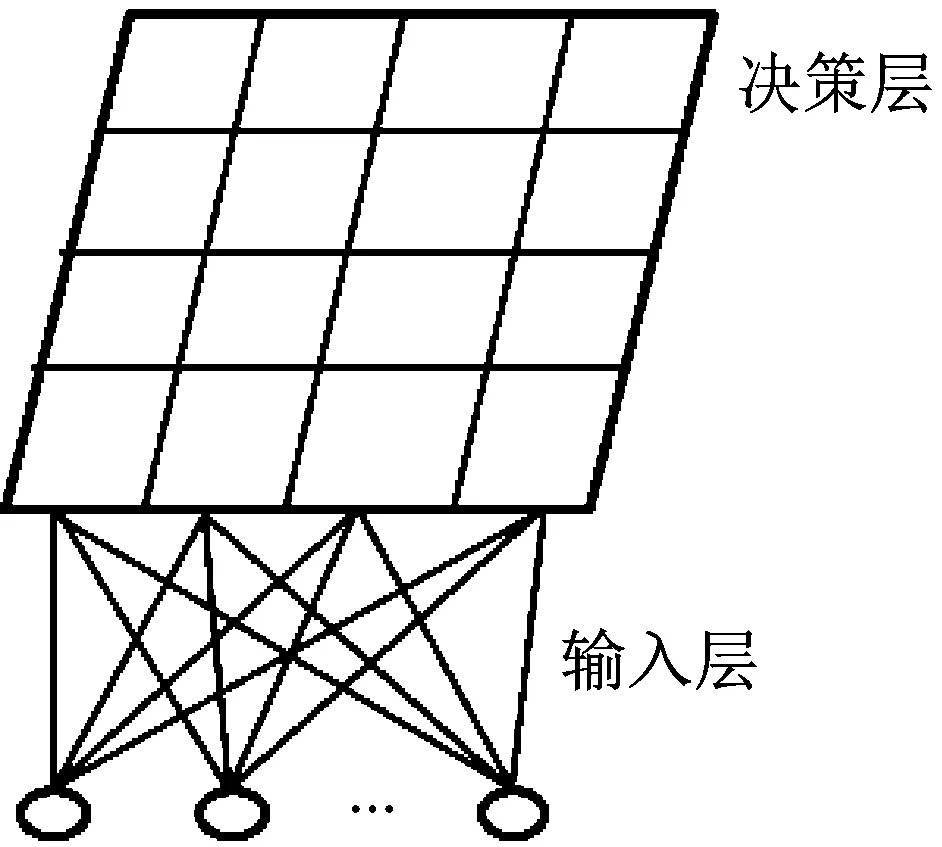
圖2 基于分子結構設計理論的聚類方法的結構圖
Fig.2 The structure of clustering method based on the theory of molecular structure design
以滾動軸承的故障模式聚類為例,假設共有N組,每組數(shù)據(jù)M維特征的故障特征集X={xn,n=1,2,3,…,N}。
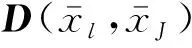
(1)
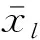
(2)
將滾動軸承振動數(shù)據(jù)樣本空間看作分子系統(tǒng),將每個故障樣本看作分子空間中的原子,以故障樣本之間的差異度作為原子間相互作用勢能的度量。
類似的,設樣本之間的勢能函數(shù)為
E=|s-d|a
(3)
式中:E為樣本間的勢能;s為故障樣本在決策平面上的歐氏距離;d為勢能場參數(shù),此處為樣本間的差異度;a用于控制樣本間勢能場隨距離增減的幅度。當a=1時,勢能函數(shù)為線性函數(shù),適用于樣本間差異比較明顯的情況;當a≥2時,勢能函數(shù)為非線性函數(shù),適用于樣本間差異不是很明顯的情況。其示意圖如圖3所示,示意圖中參數(shù)a設為2。從圖中曲線的趨勢可以看出當故障樣本在決策平面上的距離較小時,樣本間的勢能較大。隨著故障樣本在決策平面上的距離逐漸增大,樣本間的勢能逐漸減小;當故障樣本在決策平面上的距離達到一定程度時,樣本間的勢能將達到最小;然后隨著故障樣本在決策平面上距離的增大,樣本間的勢能同時也增大。參數(shù)d作為樣本間的差異度指標,從圖3中可以看到當d較小時,勢能函數(shù)的最小值點對應的樣本間距離較小;當d較大時,勢能函數(shù)的最小值點對應的樣本間距離較大。勢能函數(shù)的這些性質保證了相似的樣本會被放置在較近的位置,而不相似的樣本則會被放置在較遠的位置。
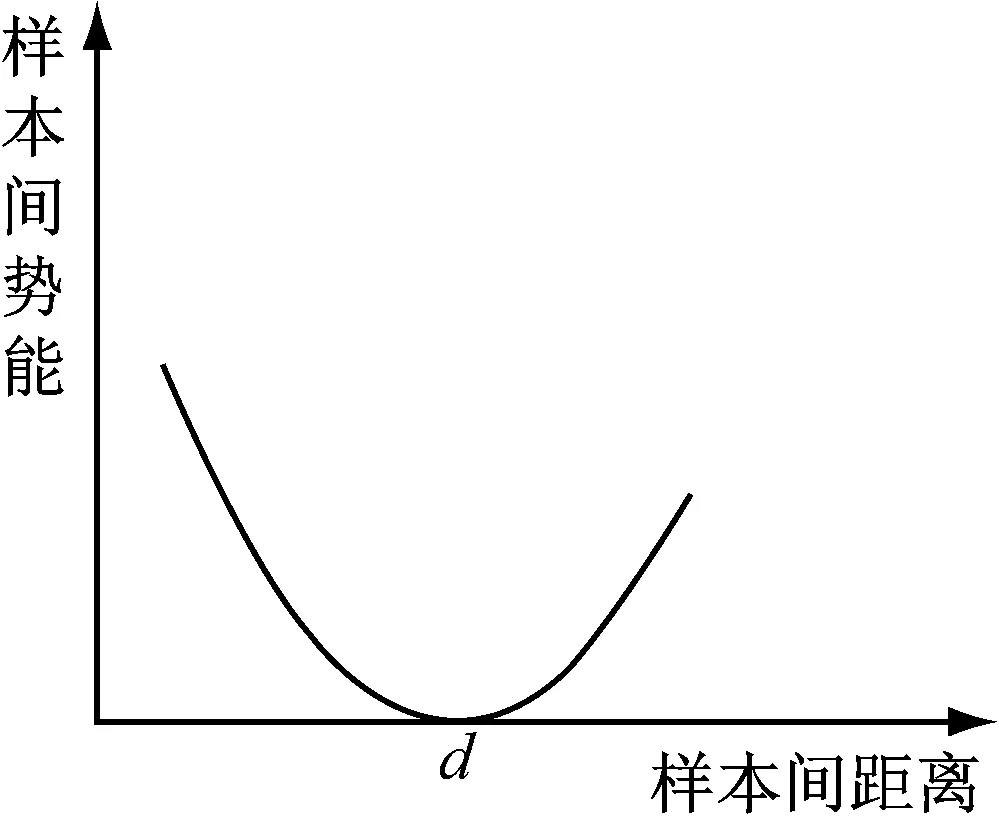
圖3 樣本間相互作用示意圖
本文方法的流程與圖2所示的分子結構設計流程相似。首先對每個故障樣本在決策平面的坐標進行初始化,在給定的勢能函數(shù)以及勢能場參數(shù)的情況下,計算某個故障樣本與其他所有故障樣本相互作用產(chǎn)生的勢能場,計算這些勢能場的矢量和,求出勢能場內(nèi)的最小值,此點即為在其他故障樣本的共同作用下與該故障樣本勢能最小點的位置,并以此位置更新該故障樣本在決策平面的坐標。類似的,計算其他樣本的勢能最小點的位置,并以此更新該故障樣本的坐標。在將所有故障樣本的坐標更新完成之后,重新計算上述過程,直到故障樣本在決策平面的坐標收斂。
收斂準則可以描述為
(4)
式中:P,P′分別為算法中樣本點在上次迭代和本次迭代的坐標;MapX為決策平面的邊長;m的值建議選為1/MapX,本文中取m=0.1。
在故障樣本的坐標收斂后,相似的樣本被放置到比較近的位置,差異較大的故障樣本則被放置到較遠的位置,完成故障樣本的聚類。假設有N組,每組數(shù)據(jù)M維特征的滾動軸承振動信號故障特征集,本文方法的具體步驟如下:
步驟1將N組故障樣本按照式(2)進行標準化,然后按照式(1)計算樣本之間的差異度,并初始化N組樣本在決策平面上的坐標;
步驟2按照式(3)選擇勢能函數(shù),設置勢能場參數(shù)a;
步驟3①第1組故障樣本與其他樣本相互作用產(chǎn)生的勢能場為
E1=E1,2+E1,3+…+E1,n+…+E1,N
(5)
式中:E1,n=|S1,n-D1,n|a,S1,n為樣本1和樣本n在決策平面上的歐氏距離
(6)
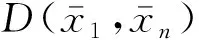
②求出當勢能E1取最小值的坐標,并以此坐標更新第1組故障樣本在決策平面上的坐標;
③重復①、②更新所有故障樣本在決策平面上的坐標;
步驟4對比故障樣本更新前后的坐標,如果坐標不再變化,結束算法;否則,重復步驟3直到所有樣本點收斂。
如前面分析,在SOM聚類過程中網(wǎng)絡連接權值的初始狀態(tài)對網(wǎng)絡的收斂性能有較大的影響。本文方法雖然需要對故障樣本的初始位置進行初始化,但是無論故障樣本的初始位置如何,由于故障樣本之間的差異度確定,在多次迭代后樣本的相對位置固定,因此減少了初始狀態(tài)對聚類結果的影響。并且勢能函數(shù)保證了相似的樣本會被放置在較近的位置,而不相似的樣本則會被放置在較遠的位置,降低映射過程中的畸變。本文方法不僅考慮類內(nèi)元素的關系而且考慮了類間元素的關系,因此能夠保留原始樣本不同模式間的相對位置以及距離信息。
3 滾動軸承振動測試實驗
本次實驗使用實驗臺如圖4所示。該滾動軸承實驗臺由直流電機、滾動軸承安裝架、加載裝置和滾動軸承等部分構成。實驗軸承選用了四種狀態(tài)的6308深溝球軸承,分別是正常、內(nèi)圈剝落、外圈剝落和滾動體剝落。實驗時軸承內(nèi)圈轉速為1 200 r/min,傳感器為IMI的601A11加速度傳感器,數(shù)采卡為UA300系列數(shù)據(jù)采集卡。采樣頻率10 kHz,采樣時間持續(xù)10 s。

圖4 滾動軸承實驗臺
每種狀態(tài)采集8組數(shù)據(jù),共有32組數(shù)據(jù)。本文提取了滾動軸承振動信號的均方幅值、峰值、平均幅值、峰值指標、峭度指標、K因子、脈沖指標、波形指標等8個時域參數(shù)。
首先使用SOM聚類方法對軸承故障數(shù)據(jù)進行聚類。將特征向量進行歸一化作為SOM神經(jīng)網(wǎng)絡的輸入,輸入層神經(jīng)元數(shù)目為8,輸出層神經(jīng)元數(shù)目為100。SOM神經(jīng)網(wǎng)絡使用Mexihat函數(shù)調(diào)整側向抑制的鄰域,更新權值學習率的函數(shù)采用式(7)
(7)
式中:α0為初始的學習率;α為當前步的學習率;t為當前迭代的步數(shù);T為設定的總的迭代步數(shù)。
SOM對軸承數(shù)據(jù)特征的聚類結果如圖5所示,圖中四種顏色分別表示四種類型的軸承故障。從圖中可以看到四種類型的故障基本能夠被區(qū)分開,但是其中屬于同一種故障模式的樣本在圖中的距離較遠,比如點25和點28;而不屬于同一種故障模式的樣本在圖中的距離較近,如點5和點25。第25組樣本與第28組樣本都屬于滾動體剝落,其歐式距離為0.078 4。第5組樣本與第25組樣本屬于不同的故障模式,其歐氏距離為0.344 0。在原樣本空間,第5組樣本與第25組樣本距離較遠,第25組樣本與第28組樣本距離較近。但是在經(jīng)過SOM映射到二維平面,樣本間的位置關系出現(xiàn)了畸變。
本文方法設置決策平面大小為10×10,勢能函數(shù)選為線性函數(shù)E=|s-d|。使用本文方法的聚類結果如圖6所示,圖中橢圓圖形是為了方便觀察而加上的。從圖中可以看到四種類型的故障樣本被很好的區(qū)分開,而且同種故障模式的樣本在映射到?jīng)Q策平面后,其在平面內(nèi)的距離較近;不同種故障模式的樣本在映射到?jīng)Q策平面后,其在平面內(nèi)的距離較遠。說明本文方法有效的降低了故障樣本從高維到低維映射時產(chǎn)生的畸變。
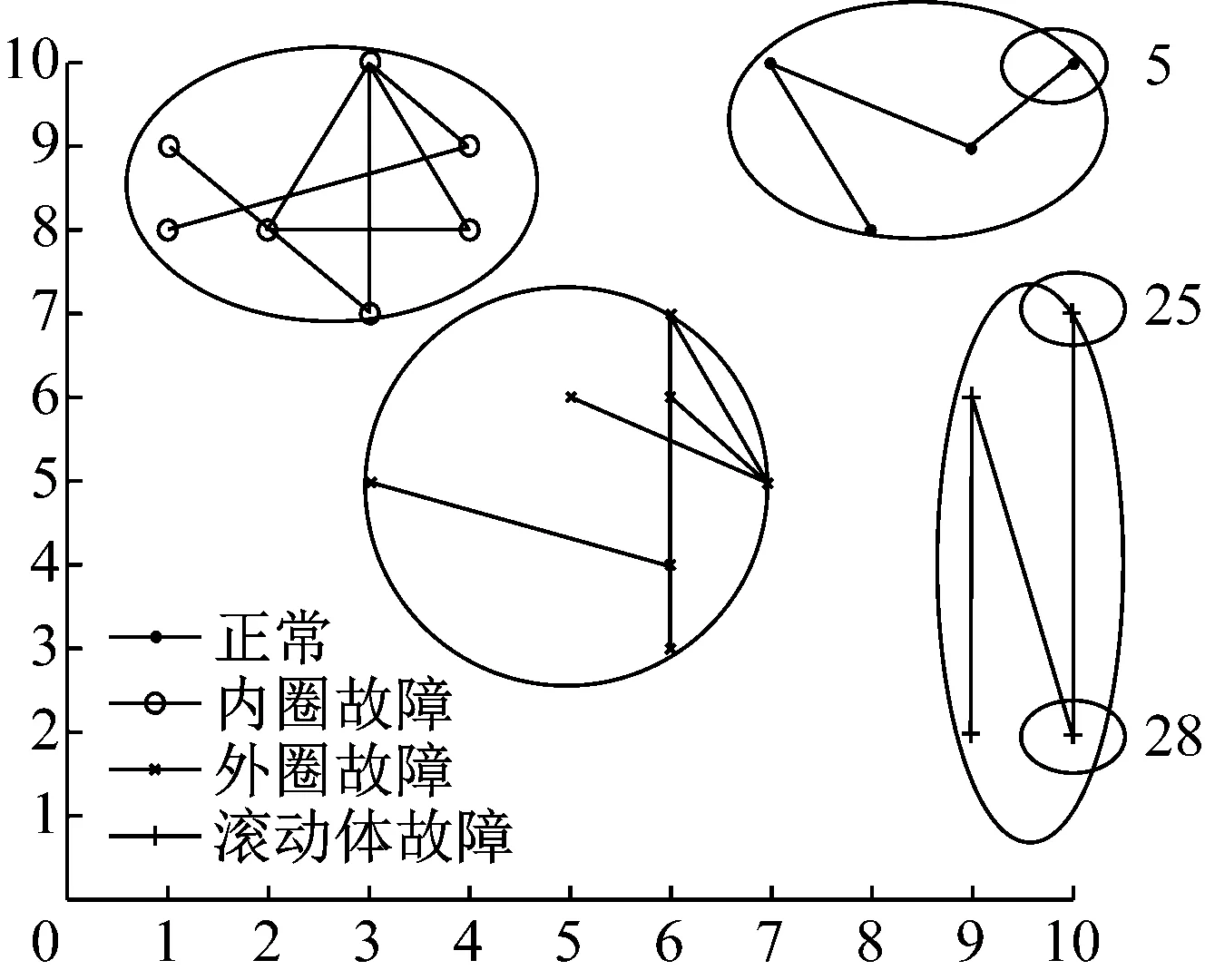
圖5 SOM對軸承數(shù)據(jù)的聚類結果
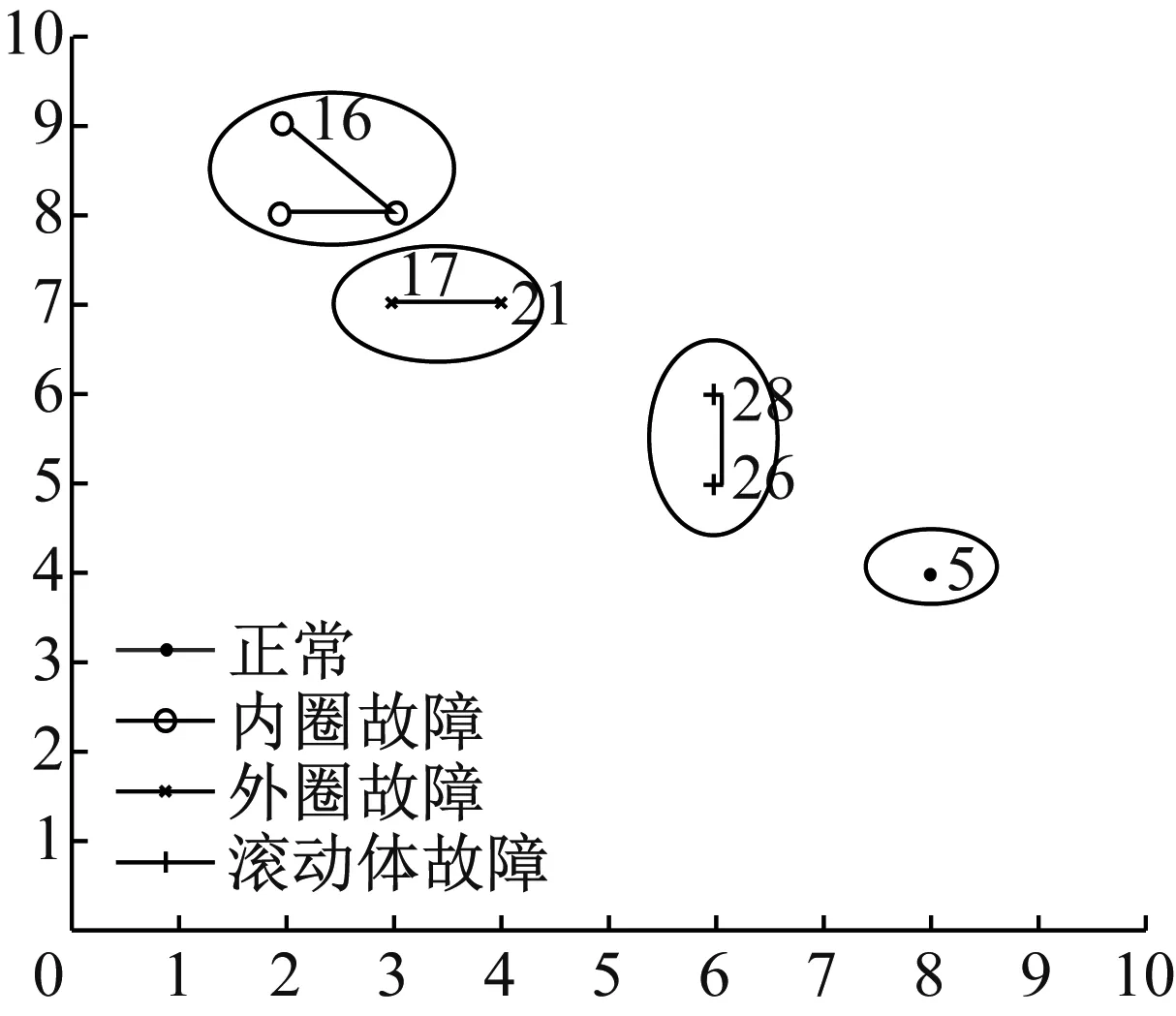
圖6 本文方法對軸承數(shù)據(jù)的聚類結果
Fig.6 The proposed method clustering of the rolling bearing data
評價聚類結果優(yōu)劣的過程稱為聚類有效性分析,過程中所使用的指標稱為聚類有效性指標。一個好的聚類方法應盡可能反映數(shù)據(jù)的內(nèi)在結構,使類內(nèi)樣本盡可能相似,類間樣本差異盡可能大[26]。DB(Davies-Bouldin)指標是基于樣本的類內(nèi)散度與各聚類中心間距的測度。
(8)
式中:DWi為聚類Ci的所有樣本到其聚類中心的平均距離;DCij為聚類Ci和聚類Cj中心之間的距離;k為k個聚類。由式(8)可以看出,DB指標的數(shù)值越小,表示聚類效果越好。計算得SOM聚類有效性指標DB值為0.690 6,本文方法的聚類有效性指標DB值為0.351 9。本文方法的DB值比SOM方法的DB值減小了49.04%。
由于SOM聚類方法需要對輸出層各權向量賦隨機數(shù)進行初始化,在隨后的迭代過程中,是通過調(diào)節(jié)權值來使神經(jīng)元與輸入向量更加匹配,所以故障樣本所激活的神經(jīng)元的位置是不可預知。因此權值向量初始化的不同將會導致最終聚類結果的不同。在本文方法中,通過計算樣本之間的相互影響調(diào)節(jié)樣本的位置,從而使故障樣本在決策平面的位置坐標收斂,因此故障樣本總能在決策平面收斂到相對固定的位置。本文方法的這些特點保證了算法輸出結果的確定性,即多次訓練后不同故障模式在決策平面的最終的相對位置是固定的。圖7是多次運行的某次聚類結果,對比圖6和圖7發(fā)現(xiàn),將圖7向右旋轉90°之后,兩圖中各故障模式之間的相對位置相同。
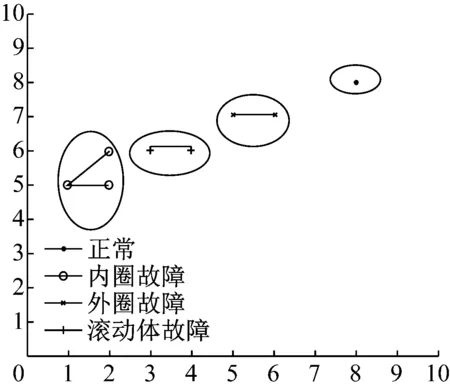
圖7 本文方法對軸承數(shù)據(jù)的特征的聚類結果
Fig.7 The proposed method clustering of the rolling bearing data
4 柴油機振動測試實驗
柴油機振動測試實驗的實驗數(shù)據(jù)來源于新加坡國立大學小波近似和信息處理中心[27]。柴油機為ISUZU C240型四沖程四缸柴油機。交流發(fā)電機和電力負載箱與柴油機相連為其提供載荷,信號采集使用B&K的4393型加速度傳感器和2635型電荷放大器。采樣頻率為20 kHz,采樣過程由安裝在發(fā)電機軸末端的編碼器觸發(fā)。實驗過程中柴油機轉速1 800 r/min,所加載荷為最大載荷的40%。在第四缸模擬了四種運行狀態(tài):缸套和活塞環(huán)磨損造成的漏氣;噴油嘴阻塞造成的噴油壓力過大,噴射壓力為160 kg/cm2;針閥和噴嘴磨損造成的噴油壓力過小,噴射壓力為80 kg/cm2;噴油壓力正常,噴射壓力為120 kg/cm2。
實驗分析數(shù)據(jù)為柴油機一個工作循環(huán)周期0.067 s的振動信號。每種狀態(tài)的數(shù)據(jù)采集30組,共有120組數(shù)據(jù)。提取8維數(shù)據(jù)特征作為本文方法的輸入,決策平面大小為11×11,勢能函數(shù)選為線性函數(shù)E=|s-d|。使用本文方法對柴油機四種狀態(tài)的振動信號的聚類結果如圖8所示,圖中橢圓圖形是為了方便觀察而加上的。其聚類有效性指標DB值為0.150 6。從圖中可以看到四種狀態(tài)的信號被很好的區(qū)分開,并且同種狀態(tài)的樣本在決策平面上的位置較近,不同狀態(tài)的樣本在決策平面上被放置到了較遠的位置。不僅如此,本文方法在映射的同時還能保持故障樣本在原樣本空間的距離關系。由勢能函數(shù)E=|s-d|可知,當樣本間的相似性度量d較小時,勢能函數(shù)的最小值點在距離較近的位置;當樣本不相似時,即相似性度量d較大時,勢能函數(shù)的最小值點在距離較遠的位置。該方法在確定樣本在決策平面上的位置時,不僅考慮了相似樣本間相互關系,而且考慮了不相似故障樣本間的相互關系,因此該方法能夠保留不同類型故障樣本間的距離信息。
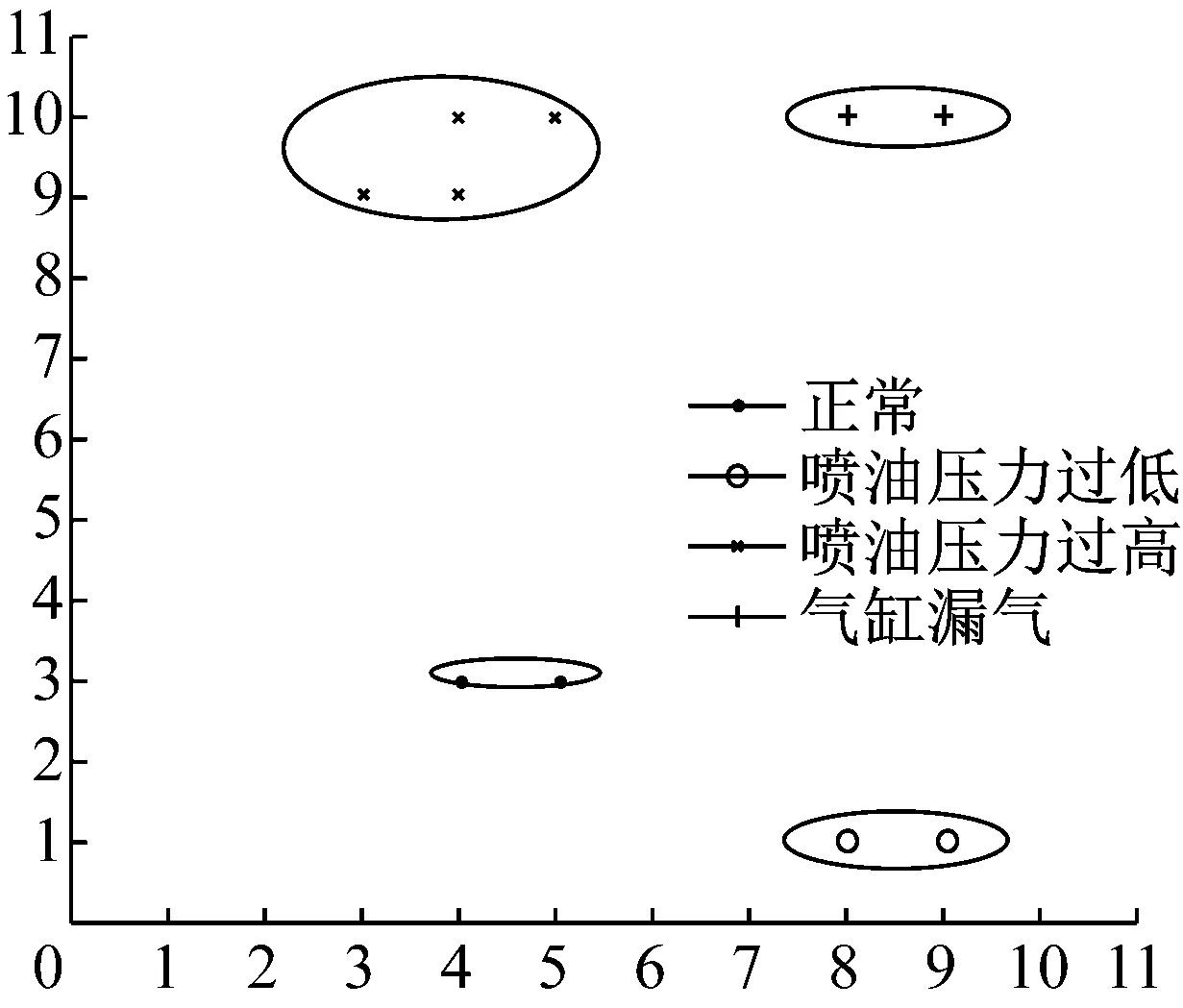
圖8 本文方法對柴油機振動信號聚類結果
圖9所示為使用PCA對柴油機四種類型狀態(tài)振動信號的特征降至2維。其聚類有效性指標DB值為0.158 2。將PCA應用于聚類分析時,其在力保數(shù)據(jù)信息丟失最小的原則下,將數(shù)據(jù)從高維變量空間映射到低維變量空間[28]。對比圖8和圖9可以發(fā)現(xiàn),兩張圖中不同故障類間的相對位置是相同的。說明本文方法在聚類時不僅能夠將相似的樣本聚集到一起,而且能夠保留不同樣本間的相對位置信息。
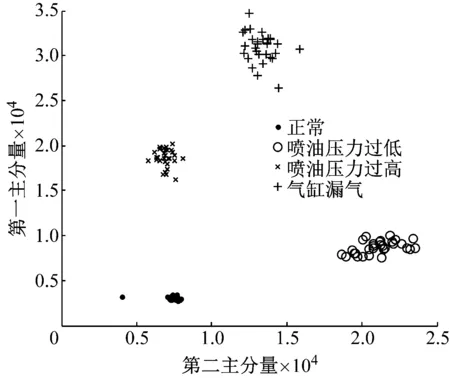
圖9 主分量分析聚類結果
5 結 論
本文分析了無監(jiān)督聚類算法存在的一些問題,針對這些問題,提出了一種基于分子結構設計理論的聚類分析方法,并給出了其原理和算法。將本文提出的方法應用于滾動軸承振動數(shù)據(jù)的聚類中,相比于使用SOM聚類算法,本文方法將聚類有效性指標DB值降低49.04%。將本文方法應用于柴油機振動數(shù)據(jù)的聚類中,實驗結果表明聚類效果良好,本文方法能夠有效地應用于故障模式的聚類,并得到結論如下:
(1) 本文方法有效的降低了故障樣本從高維到低維映射時產(chǎn)生的畸變。
(2) 本文方法不需要事先設置聚類數(shù)等初始參數(shù),避免了初始參數(shù)的設置對聚類結果的影響。
(3) 本文方法在聚類過程中,對相似數(shù)據(jù)聚類的同時,保留不同樣本間的相對位置和距離信息。
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
兒童故事畫報(2019年5期)2019-05-26 14:26:14
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
