圖書館大數據知識服務情境化推薦系統研究
2018-09-19 01:55:20劉海鷗孫晶晶張亞明
圖書館理論與實踐 2018年8期
劉海鷗,陳 晶,孫晶晶,張亞明△
(燕山大學 a.互聯網+與產業發展研究中心;b.經濟管理學院)
1 引言
隨著大數據時代到來,圖書館知識服務面臨兩個日益凸顯的矛盾,其一是知識爆炸性增長與用戶選擇能力局限性之間的矛盾,其二是信息量極度豐富和用戶感興趣信息局限性之間的矛盾。圖書館大數據知識服務的個性化推薦技術是解決該問題的一個有效工具。圖書館大數據知識服務的個性化推薦是將讀者興趣、知識領域等關聯信息加工為能夠生動描述讀者偏好的知識元,由此來支持數字圖書館各種推薦服務,最終為用戶提供滿足其個性化需求的知識資源。面對海量的知識資源,用戶的需求并非一成不變,會隨著其所處的環境與場景(情境)而發生變化。有研究表明,[1,2]用戶這種情境的變化對其個性化需求會造成不同程度的影響。但目前大多數圖書館對情境因素的感知能力不足,因此難以為圖書館用戶提供與其情境最為匹配的精準個性化服務。
為解決個性化推薦系統存在的“情境缺位”問題,國外學者Mallat等[3]在其構建的個性化推薦系統中對用戶的情境信息進行了定義,可根據用戶當時所處的情境來進行個性化推薦;Adomavicius等[4]在研究過程中引入了用戶的購買時間,將其作為情境變量來構建集成用戶情境的協同過濾推薦模型;Anand等[5]在研究中討論了如何在推薦系統中對情境進行模擬的問題,基于此提出了融合用戶情境信息的推薦方法;Bao等[6]通過研究提出了一種無監督方法,由此來對移動用戶的個性化情境進行實時模擬;Sen[7]、Karatzoglou[8]、Rendle 等[9]也各自在其推薦系統中融入了用戶情境信息,由此提出情境感知推薦方法、融合情境的多元推薦方法以及基于情境分解機的推薦方法。
在圖書館個性化服務推薦研究領域,我國學者郭順利、李秀霞[10]探討了圖書館用戶信息需求的情境敏感性以及推薦即時性特點,基于此提出了圖書館用戶信息需求模型,并通過實驗驗證了情境要素對提升圖書館個性化推薦質量的關鍵作用;畢達天、晁亞男[11]在數字圖書館用戶興趣建模過程中,從用戶情境偏好的角度出發,探討了數字圖書館資源情境對用戶接受推薦結果的重要影響;李靜云[12]構建了用戶情境感知的圖書館知識推薦系統,以此來提高圖書館知識推薦的針對性與準確性;張文萍等[13]進一步分析了影響數字圖書館個性化知識服務的多個情境因素,基于此探討每個情境維度對知識服務個性化推薦的影響;周玲元[14]探討了移動環境下的情境感知計算流程,基于此構建了圖書館聯盟情境感知推薦系統;曾子明、陳貝貝[15]從智慧圖書館建設的角度出發,提出構建智慧圖書館情境感知的個性化服務推薦系統,通過深層次融合情境信息為廣大用戶提供與其情境更為匹配的智慧信息資源,從而實現精準個性化服務;胡慕海等[16]通過研究提出了基于信息熵的用戶情境敏感性度量方法,由此對用戶進行相似性計算,該方法在一定程度上提高了圖書館知識推薦精度,有利于為用戶提供滿足其個性化知識資源。
綜上所述,國內外學者已對融合情境信息的協同過濾(Collaborative Filtering,CF)推薦進行了一定的研究,也有部分研究在圖書館個性化推薦系統中引入了讀者的情境信息。但是當前大多數研究主要通過用戶靜態信息與評分項目進行推薦,對圖書館用戶的位置情境、時間情境、業務關聯情境等挖掘不夠深入,圖書館推薦服務中的情境信息共享、情境興趣建模以及情境感知的個性化服務機制等問題仍需要進一步研究。[17]此外,圖書館用戶的行為數據與情境信息在大數據環境下呈指數式爆炸性增長,這極大增加了從海量數據中挖掘用戶情境興趣與相關知識的難度,且項目評分的稀疏性問題也愈加突出。鑒于此,本研究在傳統推薦算法中引入圖書館用戶的情境信息,提出面向圖書館大數據知識服務的情境化推薦系統,采用大數據MapReduce處理技術實現協同過濾算法的并行分布式推薦,最后給出推薦結果。
2 圖書館大數據知識服務情境化推薦系統設計
在借鑒分布式架構、用戶個性化興趣建模以及CF推薦技術的基礎上,本研究提出面向圖書館大數據知識服務的情境化推薦系統架構(見圖1)。
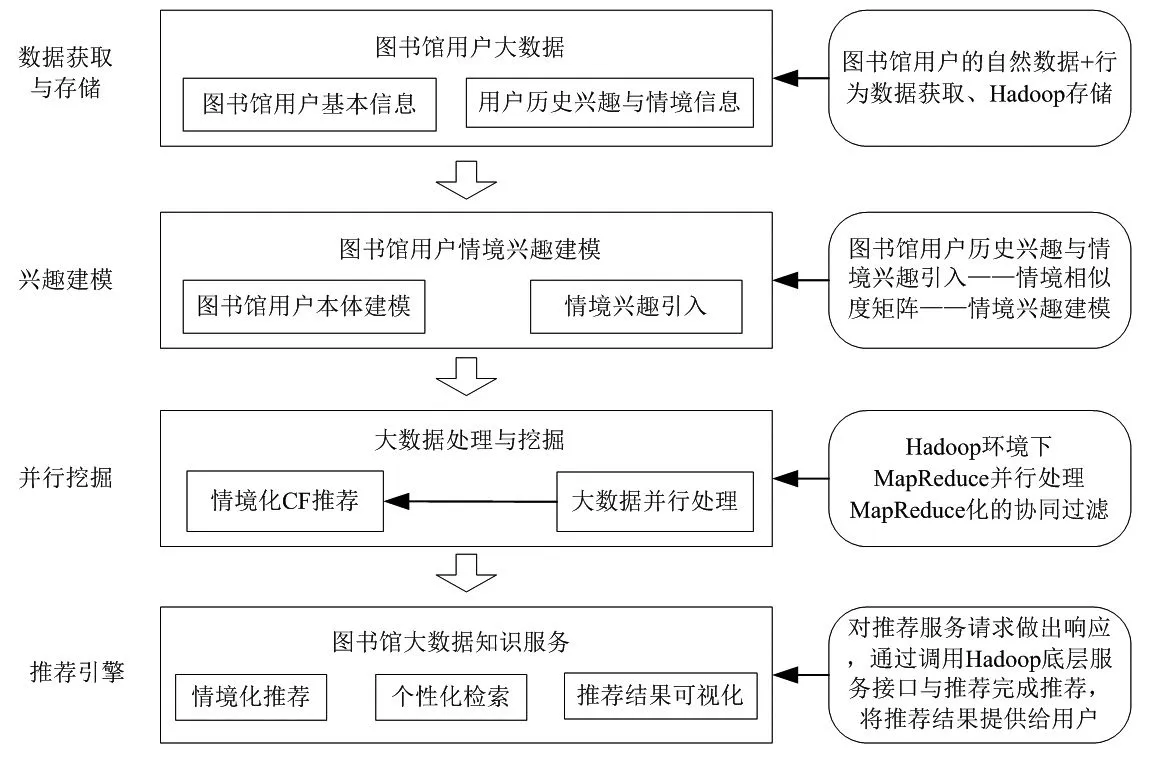
圖1 面向圖書館大數據知識服務的情境化推薦系統架構
從圖1可以看出,圖書館情境化服務推薦系統部署在Hadoop分布式環境下,對推薦系統而言,隨著圖書館用戶服務請求規模的不斷增加,其面臨的大數據處理壓力也逐漸增大。此時,Hadoop分布式處理的計算優勢就得以充分發揮,它可以將圖書館用戶服務請求部署到Hadoop集群進行處理,通過橫向擴展Hadoop節點數量,增加集群并行計算性能,以此緩解推薦系統面臨的大數據處理壓力。具體來講,面向圖書館大數據知識服務情境化推薦系統包括如下模塊。
(1)圖書館用戶大數據獲取與存儲模塊。數據獲取模塊的主要目的是提取圖書館用戶相關數據,同時將其存儲到Hadoop相應的存儲模塊中。鑒于面向圖書館大數據知識服務的情境化推薦系統需對用戶的即時興趣迅速作出回應,因此對數據存儲層的響應時間提出了較高要求。Hadoop中的HBase分布式存儲面對海量數據具有快速的服務響應能力,因此可通過橫向擴充集群節點來實現圖書館用戶大數據的存儲。
(2)情境興趣建模模塊。圖書館大數據知識服務情境化推薦系統的核心模塊為情境興趣建模,即如何融合圖書館用戶的情境信息進行情境興趣建模,并基于此緩解數據稀疏性導致的推薦性能下降問題。
(3)并行推薦模塊。大數據環境下,協同過濾的挖掘速度與推薦系統的運行效率遇到了極大挑戰。本研究引入MapReduce大數據處理工具對傳統的協同過濾推薦方法進行改進,以此提高圖書館用戶大數據的并行挖掘精度以及推薦系統的運行效率。
(4)情境化服務推薦引擎模塊。本研究構建的圖書館推薦系統的推薦引擎主要對系統前端接收的圖書館情境化服務請求做出回應,推薦系統服務接口再使用情境化推薦方法進行推薦,最終將計算出的推薦結果提供給用戶。
3 大數據的獲取與存儲
大數據技術的出現促使圖書館數字資源間的協同與互聯達到前所未有的深度和廣度,尤其是移動閱讀終端的多樣化和普及化為我們帶來了多領域、立體化、全方位的圖書館大數據。對圖書館而言,可實現其情境化推薦服務的大數據資源主要包括:用戶基本數據、用戶行為數據、圖書館知識資源數據以及用戶情境數據(見表1)。

表1 圖書館大數據資源類別劃分
表1中的用戶個人信息主要體現圖書館用戶的性別、年齡、專業等,此類信息可通過系統的注冊信息獲取,行為數據以及知識資源數據可通過Cloudera提供的Flume系統進行采集。其中,Flume是一個開源的分布式海量日志收集系統,該系統將定期分布式存儲用戶的訪問日志,以供后續的跟蹤和分析使用。用戶情境信息是本研究重點關注的要素,主要包括時間信息、地理位置信息以及環境信息,其中,時間信息和位置信息也可合稱為時空情境。時空情境既包括絕對時空信息(可確切且可量化的時空信息,如,東經12.3度,北緯45.6度、樣本閱覽室101、圖書館入口以及確切的年月日等),還包括相對時空信息(模糊描述時間與位置的時空信息,如,圖書館一樓、圖書館大門200米處、暑假期間等)。時空數據主要可根據定位技術獲取,如GPS、北斗、RFID、無線網絡基站、WiFi、傳感器等。環境信息主要客觀描述用戶所處的自然條件,如,用戶周圍的溫度、濕度、光線、噪聲、天氣狀況等,這些數據可以通過傳感器、用戶手持的智能終端設備直接獲取。
此外,Hadoop的持久化分布式文件系統(Hadoop Distributed File System,HDFS)解決了圖書館大數據的存儲問題。HDFS特別適于存儲數據查詢要求不高的圖書館信息,如,圖書情報學界近年來重大新聞信息、行業發展動態信息等。對于分布式存儲的高級應用,HBase具有類似關系型數據庫的服務功能,其列式存儲也非常適用于大規模本體數據的存儲、查詢以及實時更改。圖書館大數據的HDFS存儲機制具體如圖2所示。
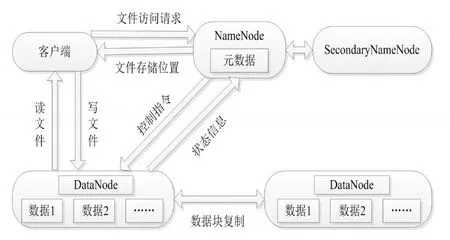
圖2 圖書館大數據知識服務的HDFS存儲機制
4 用戶情境興趣建模
用戶情境興趣建模是大數據知識服務情境化推薦的核心部分,本節對其進行細致描述。
在情境化推薦系統中,根據圖書館用戶所處的地理位置、環境溫度、服務時間等不同類型的情境,本研究使用向量計算公式將其標記為Context={C1,L,Ci,L,C}n。其中Ci表示某一情境屬性的向量,可以體現圖書館用戶當前的時間信息、位置信息、活動狀態等。如在C={c1,L,ci,L,c}n這一情境實例,ci體現的是情境屬性Ci的具體屬性值:若Ci為位置情境,則ci可表示東經12.3度、圖書館101、圖書館入口等。Contextx和Contexty則表示兩種不同的情境,其相似度本研究記為Sim(Contextx,Context)y,Simk(Contextx,Context)y則表示情境Contextx和Contexty在k類情境背景下比較的相似程度。鑒于圖書館用戶是在一定情境下對項目進行評分,且該情境信息將對用戶評分產生影響,因此本研究在評分過程中引入了圖書館用戶的情境信息,由此來對傳統CF的用戶—項目評分矩陣進行擴展,形成用戶—項目—情境評分矩陣,也就是將情境信息ContextK融入到原先圖書館用戶的每一個項目評分中去,實現融合情境興趣的圖書館個性化推薦。具體而言,就是建立“用戶—項目—情境評分”的三維量空間模型:{User,Item,Context},三個維度用戶、項目、情境評分分別由各自的屬性值構成。
首先,獲取用戶—項目評分矩陣及評分時用戶所處的情境。在建立圖書館用戶情境化推薦模型時,先建立傳統的用戶評分矩陣 ,該矩陣反映了用戶User對項目Item的評分情況,如公式(1)所示:
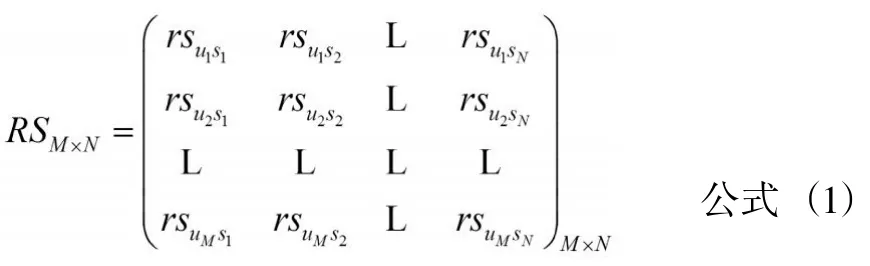
其中,用戶ui對項目sj的評分使用表示,用戶ui的平均評分使用表示,用戶uj的平均評分使用表示。
然后,根據用戶在不同情境下對相同項目的不同評分,采用Pearson相關系數度量公式計算同一用戶的不同情境相似度,具體如公式(2)所示。
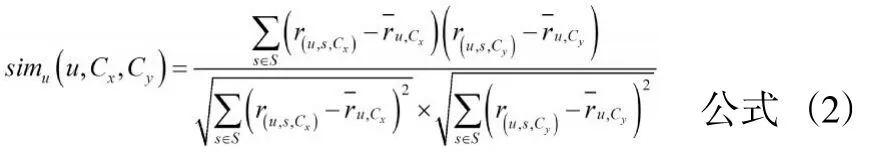
公式(2)中,S表示目標用戶u在情境Cx和情境Cy都有評分值的項目集合;表示用戶項目在情境下的評分值;則表示平均評分值。
最后,計算與目標用戶u的近似情境集合。大數據知識服務環境下,由于圖書館用戶在不同情境下共同評分的知識服務資源項目很少,這樣就很難獲得與目標用戶u相近的情境集合。為解決這一問題,本文采用余弦相似性公式對情境Cx和情境Cy的余弦相似度進行計算,具體如公式(3)所示:

通過公式(3),可以得出與目標用戶u當前情境最接近的近似情境集合,然后進行情境化協同過濾推薦,最后給出Top-N的推薦結果。
5 大數據的并行處理與推薦
由于本研究提出的情境化推薦面向的是海量數據,僅通過單機運行的協同過濾推薦方法難以進行有效的圖書館大數據知識挖掘。鑒于此,引入了大數據并行處理技術,利用Hadoop分布式環境下部署本文構建的圖書館情境化推薦系統,通過MapReduce對CF推薦方法進行并行處理,從而改進海量數據環境下CF推薦系統的挖掘性能與可擴展性。
圖書館情境化推薦的大數據并行處理與挖掘過程主要包括兩個環節:第一步使用MapReduce大數據處理方法計算用戶—項目評分矩陣的相似度;第二步通過相似度對未評分項目進行評分預測。在計算圖書館用戶—項目評分矩陣相似度時,本文輸入的鍵值對以〈null,(User,Item,Score)〉 的形式表示,輸出的鍵值采用〈(Item1,Item2),Sim〉表示。該階段的并行計算可通過兩個MapReduce任務來實現,第一次MapReduce主要匯總圖書館用戶對項目的評分信息,然后進行排名;其中的Map函數將輸入的圖書館用戶信息與項目打分信息轉換為相對應的鍵值對,Reduce函數則合并具有相同用戶的打分項目,具體過程如表2和表3所示。第二次MapReduce致力于計算項目間的相似度,將圖書館用戶和各項目間(User and Item)的鍵值對轉換成項目和項目間(Item and Item)的鍵值對,具體是采用Map函數獲得各Item間同一User的評分,利用Reduce函數計算項目之間的相似程度。通過兩次MapReduce處理后,可得出相似度的計算結果以及各Item的相似度列表。最后,根據MapReduce計算得出的圖書館用戶的推薦評分相似列表,使用Map函數進行CF推薦,并通過Reduce函數輸出推薦結果,具體計算過程如表4和表5所示。
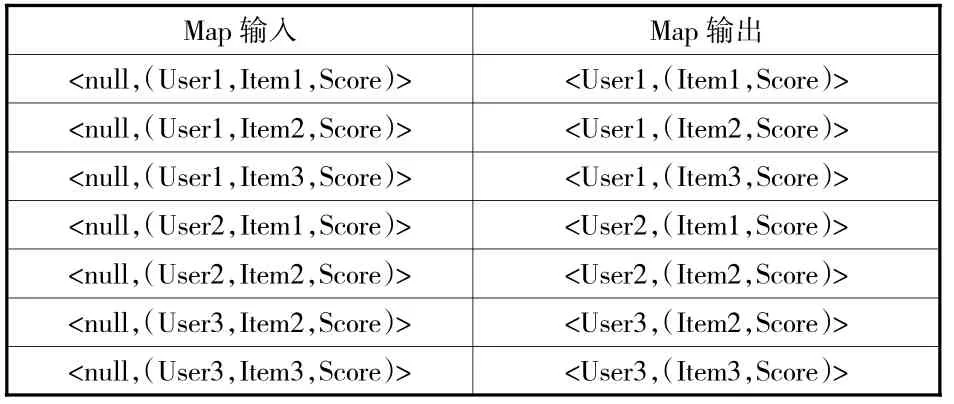
表2 第一次MapReduce的Map階段
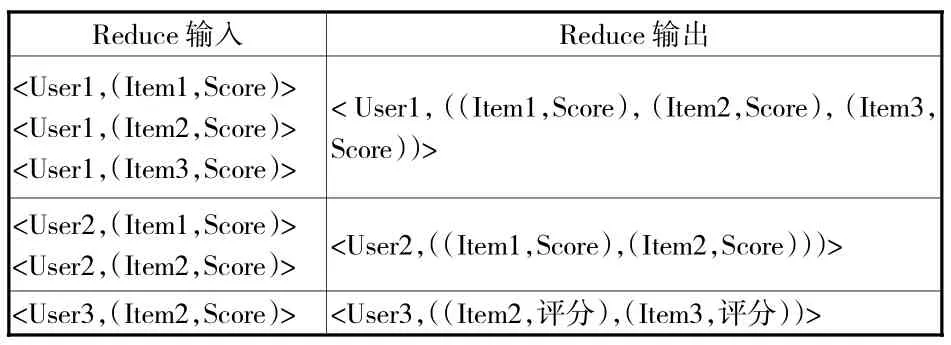
表3 第一次MapReduce的Reduce階段

表4 Map函數的CF推薦階段

表5 Reduce函數的推薦結果輸出階段
具體而言,首先將第三部分獲得的圖書館用戶行為、相關圖書評分等大數據知識服務信息引入推薦系統,在進行第四部分的情境興趣建模時,引入時間或者其他情境要素的評分權重,由此可以獲得Top-N的推薦結果。在大數據的處理與挖掘過程中,原始輸入的參數為(Reder,Book,Score),通過 MapReduce將獲得以Reder為Key值、(Book,Score)為 Value值的輸入,然后利用情境相似度公式獲得用戶u對圖書項目b的興趣度Pref;以此類推,可獲得u所有的圖書項目歷史瀏覽信息 ((Book1Pref1),(Book2Pref2),L (BooknPrefn)),采用Map輸出相似度計算得出的鍵值對,通過函數Reduce匯總并輸出以Book為 Ket值,以{(book1n1),(book2n),L (booknnn)} 為 Value值的鍵值對,最終得到用戶u的圖書相似度矩陣和Top-N的推薦結果。
6 并行推薦效果的檢驗方法
本研究實驗評價標準主要包括兩個方面:首先測試基于Hadoop的大數據并行挖掘有無提升模型計算的性能;其次是測試情境化推薦對數據稀疏性導致推薦精度下降的緩解情況。
作為并行計算測試的評價指標,加速比主要用來對比單機與并行計算兩種不同環境下特定算法運行所耗費的時長,其計算方法為單機運行時間與并行運行時間兩者之間的比值:S=T(1)/T(N)。其中,T(1)為算法在單機環境下的運行時間,T(N)為多機并行處理的時間,兩者的比值結果即為加速比。此外,為了對比Hadoop環境下不同數目節點對并行計算結果的影響,還引入了相對加速比指標:S相對=T(單DataNode)/T(多DataNode)。其中,S相對表示相對加速比,T(單DataNode)表示單機運行的時間,T(多DataNode)表示多DataNode集群運行的時間。
在推薦性能測試方面,使用最為常見的平均絕對偏差MAE、用戶覆蓋率Coverage以及P(u)@N。MAE表明預測評分與實際評分間的偏差程度,MAE越小,表明算法給出的推薦結果約接近于實際情況,兩者誤差也就越小。MAE的計算公式為:MAE=/N。其中,{P1,P2,…,PN},為算法預測得出的用戶評分集合,{q1,q2,…,qn}為實際用戶評分集合。覆蓋率指標主要衡量對數據集的覆蓋范圍,本文采用Coverage表示,計算公式為其中,測試實驗執行次數使用n表示,算法計算得出的用戶預測評級使用pi表示。而P(u)@N則表示推薦列表中與目標用戶u當前情境相符合的用戶需求項目數與N的比值,計算公式為:P(u)@N=(relevent items intop nitemsforu)/N。
猜你喜歡
福建中學數學(2023年5期)2024-01-25 17:41:36
中學生數理化·中考版(2022年10期)2022-11-10 09:37:46
小太陽畫報(2018年1期)2018-05-14 17:19:25
護士進修雜志(2017年3期)2017-02-14 07:19:35
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
小學生作文(中高年級適用)(2016年3期)2016-11-11 06:30:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
