基于語義的文獻資源發現服務體系構建
2018-09-19 01:55:22劉愛琴于賈燕
圖書館理論與實踐 2018年8期
劉愛琴,于賈燕,尚 珊
(山西大學經濟與管理學院)
當前互聯網上海量文獻資源的品質參差不齊,導致用戶無法及時有效地檢索目標信息,文獻資源發現服務體系服務效率低下,查準率較低,且無法實現對不同信息的統一訪問。[1]基于語義的文獻資源發現服務體系是借助人的智慧創建的依托于機器的智能化系統,提供人與機器之間信息通信的中介,可借助與客戶檢索文獻信息相關的語義知識地圖實現對知識的深度挖掘以及用戶與計算機間對數據信息的一致理解和認識。本研究致力于在語義的基礎上搭建將目標文獻資源以“與用戶檢索內容相匹配的數字資源的全文信息PDF匯編文檔”的形式,替代當前簡單的檢索目錄呈獻給用戶的文獻資源發現服務體系,進而根據用戶需求實現知識重組,促進知識創造的發展。
1 國內外研究成果
語義Web起源于英國,由國際W3C主席Tim Berners-Lee首次提出,即給出一種機器可理解的描述資源的方式,在保證查全率的基礎上大幅提升查準率。[2]當前,比較典型的語義數字資源服務系統有BRICKS、Fedora和JeromeDL。BRICKS是依托分布式開放結構的集成化整合文化知識服務資源建設的開源軟件系統;[3]Fedora是基于Web2.0靈活可擴展的、通用的數字對象管理系統;[4]JeromeDL是基于語義Web的高互操作性、高可用性、開源社會化語義數字資源服務系統。[5]上述三個語義數字資源服務系統各具特色,對語義技術有較強的支持作用,為數字信息領域提供了典型的研究范例,具有極強的參考價值。
中國學者劉健等為應對傳統數字文獻資源內容推薦服務過程中無法充分挖掘資源語義信息等問題,提出對用戶檢索關鍵詞實行語義擴展,并嘗試采用全新的語義相似度計算方法,借助本體推理規則,計算文獻資源內容相似度。[6]李佳南提出以用戶需求為核心出發點,在館藏資源特征分析的基礎上提出語義知識庫構建的方法,采用自底向上的構建思想構造層次化的館藏資源語義知識庫框架體系。[7]高俊峰提出一種基于語義標簽的數字文獻資源組織方法,力求為新技術標準下的數字圖書館知識服務工作的開展提供解決方案。[8]但令人遺憾的是,目前國內仍然沒有學者明確提出構建基于語義的文獻資源發現服務體系。
本研究嘗試搭建實現轉變關鍵詞為主題詞、對主題詞進行科學切分和重組,從而能夠根據用戶需求實現知識重組、促進知識創造的基于語義的文獻資源發現服務體系。該體系可以將匹配用戶檢索信息的相關數字資源以PDF文檔格式條理化、可視化的形式呈獻給用戶,實現全文信息呈現替代當前的檢索目錄可視化,進而借助形象化、具體化的描述提高信息的可理解性和可認知性的程度,提高數字資源的有效利用率,以達到減少用戶檢索獲取知識資源的時間與精力的目的。
2 基于語義的文獻資源發現服務體系機理分析
提供基于語義的文獻資源發現服務,更好地揭示數字文獻資源的語義特性,實現由關鍵詞到主題詞的轉變及主題詞的切分和重組,深度集成和統籌互聯網數字資源,反饋給用戶可視化的目標文獻資源全文信息。以語義Web技術為支撐,從用戶層、檢索層、語義分析層、預處理層、知識集成層五個層次挖掘并整合互聯網數字文獻資源(見圖1)。
(1)用戶在用戶層進行檢索查詢時制定的檢索策略會直接傳遞給檢索層。該層是實現用戶與機器直接信息交流的平臺,若用戶訪問一個信息內容實例,則把該內容以指定的中介格式(PDF文檔)反饋給用戶。同時,該層還負責以動態跟蹤的方式實時跟蹤所提供的知識服務,以主動推送的方式優化知識服務,進一步提升用戶滿意度。
(2)檢索層的檢索工具將用戶需求傳遞至推理機,提取需求特征后進行本體擴展,消除語義沖突和語義分歧等,并在服務器的基礎上完成數字資源語義沖突的智能化識別和處理。從而在已經建立的語義化信息或知識及相關算法的支持下,實現用戶需求的初步解讀。用戶需求數據庫通過推理機傳遞的經解讀分析后的數據信息了解用戶對知識服務的需求,從而進行整理和儲存。然后對用戶感興趣及習慣性的信息進行定期跟蹤查新,并通過用戶層及時將最新信息推送給用戶。
(3)用戶需求庫將解讀后的需求信息傳輸至語義分析層數據庫,在語義Web技術的基礎上,從索引庫、主題詞庫、文獻文檔三個維度對匹配用戶需求的相關文檔進行語義方面的逐層解析,進而篩選調用語義標準化后的數字資源,形成基于XML的檢索目錄。
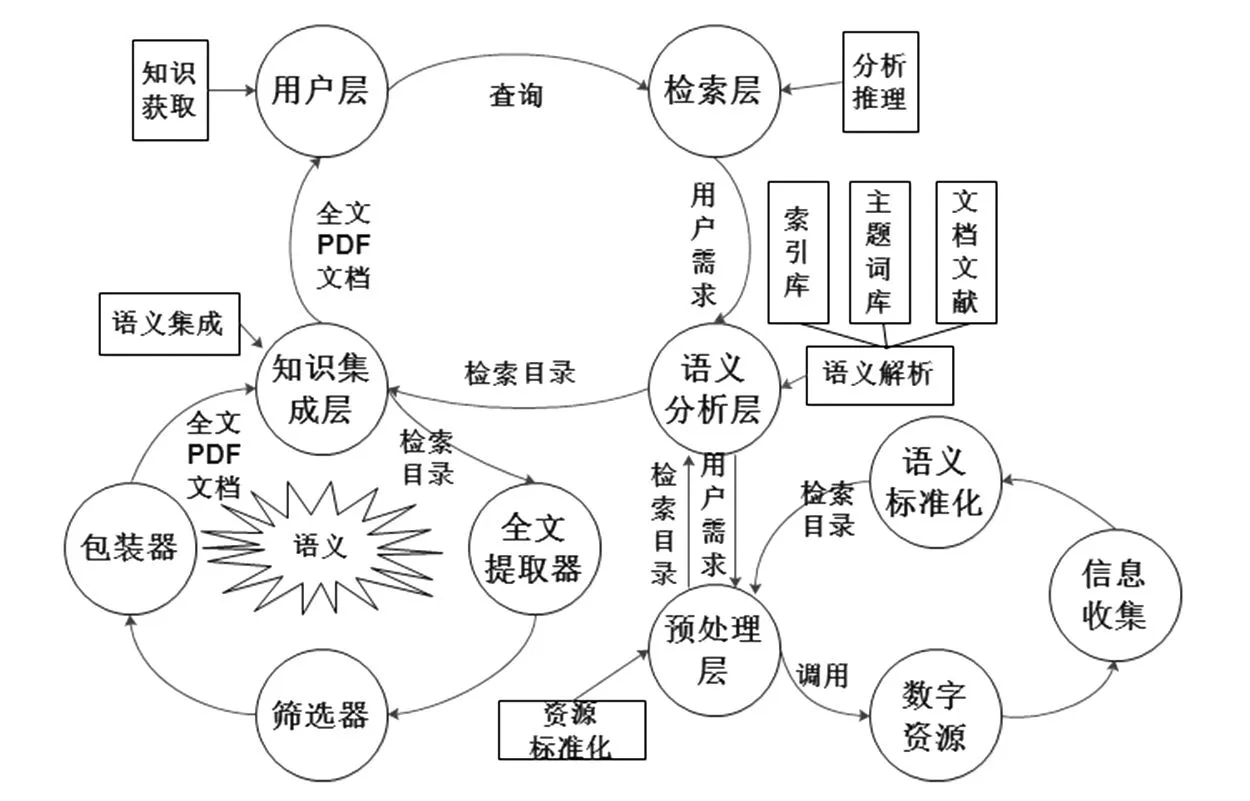
圖1 基于語義的文獻資源發現服務體系機理分析
(4)預處理層響應語義分析層的要求,收集為匹配用戶需求而篩選調用的文獻文檔,然后借助語義Web技術對其進行解析處理,具體過程如下。① 在數字資源尾部找到屬性標簽;② 轉入數字資源文檔根對象;③ 轉入數字資源文檔頁根對象;④ 轉入內容對象,解讀字體信息、位置信息和文本信息;⑤將所有內容對象的解碼流連接起來,組成文本內容流。該層基于語義技術通過突破描述異構、傳輸異構、兼容異構、功能異構以及過程異構等多種語義本體異構問題,將解析后形式各異的館藏數字資源用統一化、標準化、機器可理解的語言描述,為下一步的全文內容抽取奠定基礎。
(5)知識集成層由提取器、篩選器和包裝器三個模塊構成,對語義分析層形成的檢索目錄中的資源進行全文內容獲取,進而逐步實現推理解析、語義組別劃分和知識單元關聯匯總,基于數字信息資源聚類、分類和學習等算法研究,完成推理任務描述與分解技術研究,實現提取資源全文內容的生成、重用和演化,最終打包成包含匹配用戶需求的所有文獻文檔全文信息的PDF集成文檔呈現給客戶,實現基于語義的智能化文獻資源發現整合服務,更易于被用戶發現和瀏覽。
3 基于語義的文獻資源發現服務體系構建
實現高效準確的基于語義的文獻資源整合及知識推送服務的前提是基于語義標準化數字資源的篩選凝聚,在實現由關鍵詞到主題詞轉變的基礎上,系統才能高效滿足用戶的深層次知識需求,增進知識認知、推動知識解讀、促進知識整合、推進知識創作。基于此,本研究構建的基于語義的文獻資源發現服務體系由用戶層、檢索層、語義分析層、預處理層和知識集成層五個層次支撐并實現(見圖2)。
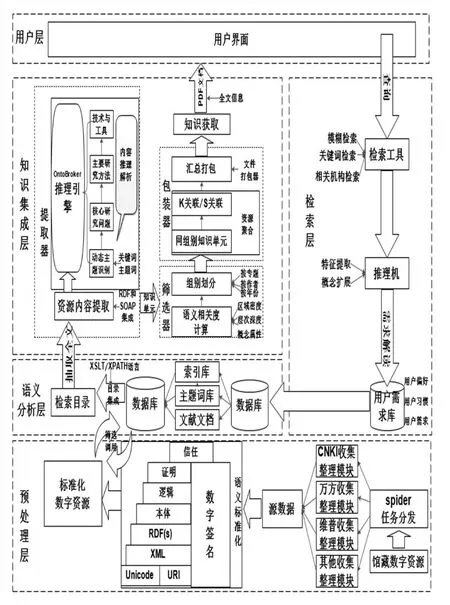
圖2 基于語義的文獻資源發現服務體系模型
(1)用戶層。該層與檢索層緊密相連,根據用戶的檢索需求,準確得到用戶目標信息,高效、可視化地反饋給用戶與檢索信息相匹配的文獻資源PDF整合文檔,這也是整個基于語義的文獻資源發現服務體系中最能直接體現其高速、高效、高水準知識服務的模塊。
(2)檢索層。該層主要發現、解析并整合用戶的檢索需求,具體流程如下。① 用戶在用戶界面上的檢索欄通過關鍵詞檢索、模糊檢索、相關機構檢索等檢索方式進行查詢檢索。基于語義的文獻資源發現服務體系在用戶層可實現動態自適應界面功能,并將用戶需求傳遞至檢索工具。② 推理機可實現將事實查詢和本體概念合并為一個查詢,經推理機借助領域本體規則,獲取用戶需求概念后依次進行特征描述、特征提取、概念擴展等處理,進而推理整合分析后,將用戶需求、用戶偏好、用戶特點等信息匯總至用戶需求庫。③ 系統自動將用戶需求庫匯總所得到的信息傳遞到語義分析層的特定數據庫進行匹配,進一步分析處理后調用語義標準化后的文獻文檔數據資源。
(3)語義分析層。該層基于語義Web技術首先從索引庫、主題詞庫、文獻文檔三個維度對需匹配用戶需求的相關文檔展開解析處理,并對書目進行層次劃分處理,分離屬性特征,概括并提取實體和屬性的語義關系,構建相應的數據庫,包含關鍵詞表、作者表、期刊表、引文表等。數據庫進而篩選調用預處理層語義標準化后的數字資源,將關系型數據庫中的數據換成RDF格式,以RDF有向圖的形式描述和表達各種關系;借助固定的、普遍的詞匯集實現概念規范,形成立體的組織模式;最終采用XSLT和XPATH(W3C協會提供)語言實現XML的目錄層集成,實現相關信息檢索目錄的可視化。
(4)預處理層。該層次的任務是回應語義分析層的需求,將數據庫所需篩選調用的文獻文檔預先進行標準化處理。① 收集并整合館藏數字資源,通過Spider實現任務分發,借助CNKI、萬方、維普和其他收集整理模塊形成源數據,包括結構化數據和非結構化數據。② 由于源數據存在格式不一致的問題,必須進行數據標準化處理,消除數字資源之間的異構特性。為簡化語義分析層的標準化步驟,省去不必要的麻煩,故在該層事先進行數據預處理。將出處各異、結構不同、格式不一、類型多樣的海量數字資源進行統一描述,確定各獨立資源節點、知識要素之間的語義關聯,保障其具有一致的標準,為計算機識別與知識細粒度化提供便利。
其中,語義標準化的具體過程如下。① URI、U-nicode在整個語義Web結構中處于最底層URI對Web上所有資源進行統一描述,保證唯一標識其中任意一個資源,借助鏈接實現資源的引用;Unicode為確保機器能有效地識別資源編碼而使用國際上的通用字符集。② XML為文檔提供結構化的語法,借助URI實現引用標識,達到資源存儲方式的統一。③ RDF(S)是一種借助數據模型提供簡單的語義資源描述框架,實現資源描述方式的一致化。④ 本體層通過提供確切的形式化語言,幫助準確定義術語及術語間的關系。⑤ 邏輯、證明和信任。邏輯層主要負責推理規則,證明層注重認證機制,信任層著重信任機制。⑥數字簽名的本質是一段數據加密塊,是實現Web信任的關鍵技術和基礎。
(5)知識集成層。該層是實現基于語義的文獻資源發現服務體系與其他知識服務不同的關鍵所在。分別通過提取器、篩選器和包裝器三部分對檢索目錄中的資源進行全文內容提取、語義組別劃分和知識單元關聯匯總,最終提供給用戶匹配其檢索內容的文獻資源PDF集成文檔。① 提取器借助由W3C協會提供的RDF和SOAP對檢索目錄中的資源實現全文內容提取。進而采用OntoBroker推理引擎對資源全文內容進行深度推理解析,動態識別資源主題,包括關鍵詞和主題詞,集成資源的核心研究問題、主要研究方法以及主要技術與工具。作為一個面向對象的邏輯推理系統,OntoBroker可以實現以數據庫現有知識為基礎提取新知識的功能。② 系統通過篩選器對提取器所得數據單元進行篩選整合,將推理擴展得到的內容在層次深度、區域密度、概念屬性三方面進行語義相似度計算,進而實現資源相關度計算,并按專題、年份、作者或其他因素進行語義組劃分,接著將相似文檔聚類成組。③ 通過包裝器,對同組別知識單元實現關聯,采用K關聯/S關聯等技術過程中通過補充關鍵詞、對摘要和題名進行切分詞處理等方式,實現對信息資源已有知識的發現與重組,進而形成全新的知識元,完成深度聚類和數據關聯。
區別于傳統的聚合方式,基于語義關聯的知識聚合主要從數字資源的概念關系、引證關系、等級關系、映射關系等層面進行語義分析,然后提取語義元數據與異構信息接口,解決異構數字資源之間的語義沖突,進而實現基于語義關聯的知識聚合。同時,突破篇名、作者、機構、內容知識單元、來源出版物和參考文獻等傳統題錄項之間的顯性關系構建,借助語義消歧、關系約簡及重構等方式綜合了題目、目錄、關鍵詞、數據、主題詞、內容等多種類型外部特征與語義元素之間的關聯方式,實現動態、多維的知識關聯。
最后,借助文件打包器對聚合的文檔進行匯總打包,實現智能、可視化知識獲取,將目標資源的全文信息以PDF文檔格式條理化、可視化地呈獻給用戶。取代先前簡單的檢索目錄,用戶即可獲得與其查詢內容相匹配的文獻數字資源的全文信息PDF匯編文檔,以期給用戶帶來更加智能化、便利化、柔性化的文獻資源發現服務。
4 總結與展望
針對當前數字文獻資源數據整體上不能實現互相關聯,只能實現局部范圍內組織的現狀,導致形成了大量分散、相互獨立的信息孤島。本研究專注探索如何借助語義Web技術對數字文獻資源進行統一描述、統一匯編等問題,為完成打造一個能夠實現語義功能的數字資源服務平臺的任務,搭建了一個基于語義的文獻資源發現服務體系。該體系核心是基于語義元數據的構建與關聯實現與檢索目標信息相匹配的數字文獻資源的全文內容PDF文檔匯編,替代當前簡單的檢索目錄。不可否認,語義Web的產生是搭建文獻資源發現服務體系的一個良好契機,提供了預處理層的語義級支持。在此基礎上,本系統匹配更加自動化、智能化的技術,如,高精度的知識篩選聚合技術、深層次的推理技術、高水平的可視化技術等,解決了傳統數字文獻資源服務推薦過程中存在的無法充分挖掘資源語義信息等問題,為用戶提供更加便利化、柔性化的知識服務。基于語義的文獻資源發現服務提升了數字文獻資源的篩選利用與整合匯編的效率,為知識匯總與獲取提供了有效的途徑,保障用戶能夠高效率地知識選擇、知識摘錄、知識利用、知識轉化、知識表達和知識創新。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
