軟件定義網絡中一種兩步式多級流表構建算法
2018-10-11 12:32:08邱智亮孫士勇潘偉濤王偉娜張之義
西安電子科技大學學報 2018年5期
鄭 凌,邱智亮,孫士勇,潘偉濤,王偉娜,張之義
(1. 西安電子科技大學 綜合業務網理論及關鍵技術國家重點實驗室,陜西 西安 710071;2. 中國電子科技集團公司第五十四研究所 通信網信息傳輸與分發技術重點實驗室,河北 石家莊 050081)
軟件定義網絡(Software-Defined Network,SDN)[1]是一種新興的網絡技術,它將傳統網絡的控制面和數據面相分離,并通過開放的軟件定義應用程序接口(Application Program Interface,API)實現網絡功能的靈活重構,構建動態、開放、可控的網絡環境,極大地改善了網絡的擴展能力和靈活性.OpenFlow[2]是SDN最重要的南向接口標準,其主要思想是在數據平面上采用基于流表(Flow Table)的轉發機制,并提供了數據面和控制面的標準接口.如今,隨著網絡新型業務的快速發展,流表匹配域不斷增加、流表規模爆炸性增長,流表的存儲與查找已逐漸成為OpenFlow交換機的性能瓶頸.并且自OpenFlow 1.1版本起提出了多級流表的概念,多級流表的劃分與構建仍然是一個開放性問題.此外,隨著 40/ 100 Gbit/s 以太網標準的出現,不斷增長的轉發速率需求對交換機的轉發性能和硬件設計提出了新的挑戰.因此,針對高速環境下OpenFlow的多級流表研究在近年來得到了廣泛關注[3-4].
文獻[5]提出了一種哈希表和三態內容尋址存儲器(Ternary Content Addressable Memory,TCAM)相結合的多級流表實現方式,但是該方法依賴于流表中匹配域的類型,只能實現TCAM與哈希表互相交替的流水結構.文獻[6]針對數據平面轉發提出了可重構匹配流表(Reconfigurable Match Table,RMT)模型,該模型實現了一個可重新配置的流表,支持任意的數據位寬和深度,具備了協議無關和可編程的靈活性.但是這種思想在硬件實現時需要消耗大量的靜態隨機存取存儲器(Static Random Access Memory,SRAM)和TCAM資源,不具備實際工程的可實現性.文獻[7]提出了一種SDN流表化簡機制(Flow Table Reducation Scheme,FTRS),該算法針對IP表項進行前綴聚合,能夠在不影響網絡功能的前提下,減少流表項的條數,從而壓縮流表的存儲空間.但是這種方法僅能應用于IP查找,難以適應OpenFlow的多字段匹配需求.考慮到OpenFlow匹配域的特征,文獻[8]提出了一種啟發式流表空間優化算法(Heuristic Storage space Optimization algorithm for Flow Table,H-SOFT),該算法分析了OpenFlow流表結構定義字段之間的共存和沖突關系,通過分級消除流表中的互斥字段從而降低流表的存儲空間.文獻[9]提出了一種OpenFlow多級流表結構及其映射算法,將單一流表映射到多級流表中進行高效存儲和查找.但是該方法難以對流表中的匹配域進行均勻的拆分,導致流表空間壓縮性能不夠理想,且硬件開銷較大.文獻[10]提出了一種平衡時空的自適應多級流表構建方法,該方法根據每個匹配域的重復率對流表進行分級,并且在一片TCAM中為每一級流表分配一定的空間用于存儲流表項.但是該方法僅使用了一片TCAM進行多級流表的存儲,因而不能進行流水操作,帶來了較大的時延,無法實現硬件交換機端口的線速處理.
針對OpenFlow流表面臨的這些問題,文中提出了一種兩步式多級流表構建方法,通過流表匹配域的流類別拆分和正交分解兩個步驟實現多級OpenFlow流表的構建,能夠實現流表存儲空間的有效壓縮,同時保證了多級流表查找的硬件可實現性和流水線處理速度,支持 100 Gbit/s 線速處理.
1 OpenFlow多級流表結構
1.1 OpenFlow流表
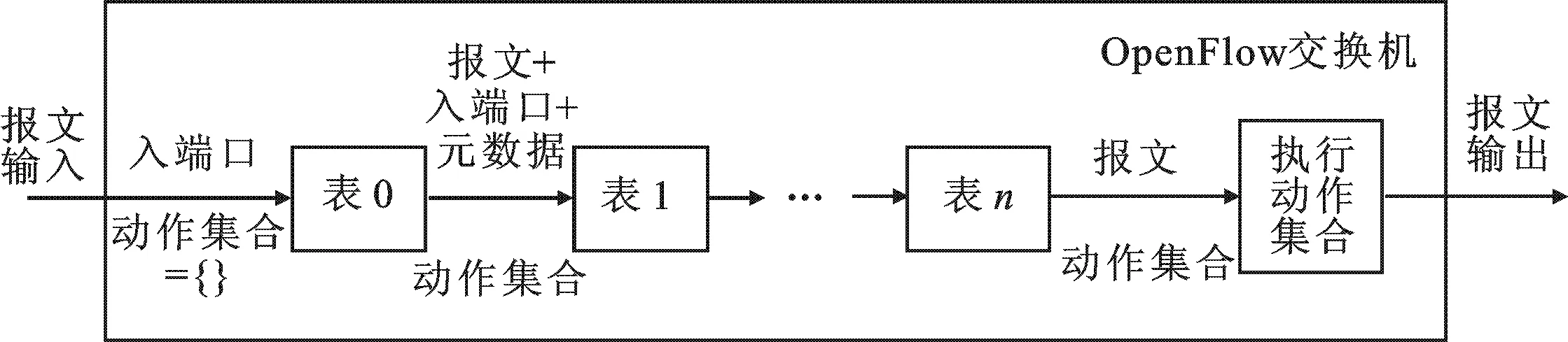
圖1 多級流表工作流程
最初的OpenFlow 1.0版本將轉發規則存放在一張單級流表中,但當網絡規則變的很復雜時,這種單流表結構不僅會造成流表資源的浪費,而且還限制了應用層業務規則的制定.因此,在OpenFlow 1.1版本中提出了基于流水線工作方式的多級流表概念,多級流表的工作流程如圖1所示.分組進入交換機后,將從流表0開始依次匹配,流表項將以優先級從高到低的順序與數據包進行匹配,當數據包成功匹配到一條流表項后,根據流表項中的指令進行相應操作(例如跳轉至后續的某一流表繼續處理,增加或者修改該數據包對應的動作集合,更新元數據等).當數據包已經處于最后一個流表時,其對應的動作集合(Action Set)中的所有動作指令將被執行(例如轉發至某一端口、修改數據包某一字段、丟棄數據包等).
1.2 符號描述
流表T,是包含多個流表項e的集合,每條流表項可以包含多個匹配域(Match Field).用符號f表示流表中的匹配域,如OpenFlow協議定義的IP源地址(IPSRC),IP目地地址(IPDST),以太網源地址(ETHSRC)等字段都稱為匹配域.設流表T共有n條流表項,每條流表項由d個匹配域{f1,f2,…,fd}構成,令si表示匹配域fi的位寬(例如,IPV4SRC的位寬為 32 bit,ETHDST的位寬為 48 bit),則單級流表T的總存儲空間為
(1)
如果將流表T分解為K個子流表{H1,H2, …,HK},則對于第k個子流表,其中 1≤k≤K,設其包含了Nk條表項,每條流表項包含了Mk個匹配域,令sk,j表示第k個子流表的第j個匹配域所占用的存儲空間,則K個子流表所占用的總存儲空間為
(2)
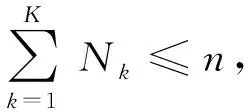
(3)
由式(3)可知,分級之后的流表存儲空間小于分級之前的,因此,通過流表分級的方式能夠減少流表存儲空間,提高流表資源的利用率.使用流表空間壓縮率作為指標衡量流表分級算法的性能.定義流表空間壓縮率p為將單流表劃分為多級流表之后節省的流表空間的比率,則
(4)
設已知交換機可接受的查找處理時延為D,系統的時鐘頻率為fCLK,則最大流表級數K=DfCLK.
流表分級問題從而轉化為如下的最優化問題: 已知交換機中,原始單級流表T,交換機可接受的最大流表級數K為DfCLK,求多級流表的集合H= {H1,H2…,HK},使得
H=argminp(H1,H2,…,HK) .
(5)
2 兩步式多級流表構建算法
2.1 基本思想
雖然OpenFlow標準給出了13個必選的匹配域,但是在實際的應用場景中,用戶通常并不需要同時用到全部的13個匹配域對流進行匹配.在特定應用中,只需要關注某些特定的字段.例如,在橋接路由器中,橋接分組只關注二層字段的匹配; 路由分組只關心IP地址的匹配; 而訪問控制列表(Access Control List, ACL)采用五元組對輸入分組進行過濾.由此可見,可以根據不同的數據流處理邏輯的功能,將一張包含所有匹配項的流表,劃分成多個相互獨立,且具備不同數據流處理功能的邏輯流表.例如,將橋接轉發,路由轉發,以及ACL各維護一張表,這樣能夠優化流表中通配符所占用的空間,節約流表所需的存儲空間.
此外,由于SDN對業務流的細粒度分類需求,通過匹配域的正交組合而產生的流表項會導致流表中存在很多重復的內容,也會使得流表的規模顯著增加.例如,在服務質量保證(Quality of Service,QoS)中,需要根據輸入分組的源IP地址以及目的IP地址得出分組要入隊的隊列號,從而實現對不同數據流的區分服務.假設源IP地址包含了M種匹配,目的IP地址包含了N種匹配,則在單級流表中就需要M×N條表項.這種正交組合會導致流表項數爆炸性增長.而如果把單流表的流表項通過匹配域的正交分解形成多個流表,可以壓縮各匹配域中的重復值,也能夠在很大程度上節省流表的物理存儲空間.例如,將源IP地址,目的IP地址分別存儲在2個流表中以流水線的方式進行查找,查找得到的中間結果使用元數據(metadata)進行傳遞,則只需要存儲M+N條表項,從而降低存儲流表所需的空間.綜上所述,可以通過流類別拆分和匹配域間正交分解兩個步驟來實現多級流表的構建.
2.2 算法流程
2.2.1 流類別向量拆分
定義流類別向量α=(b1,b2,…,bd),對于某一條流表項e= {f1,f2,…,fd},若其匹配域fi不為通配符“*”,則將bi置1;反之,則將bi置0.例如,單流表T的所有匹配域為{ETHDST,IPV4SRC,IPV4DST,TCP/UDPSRC,TCP/UDPDST,IPPROTO},橋接轉發只關注目的MAC地址,可將橋接轉發規則表示為α1= (1,0,0,0,0,0).路由轉發需要關注源IP和目的IP地址,因此,路由轉發規則可以表示為α2= (0,1,1,0,0,0).而ACL表利用五元組對輸入分組進行過濾,則ACL規則可以表示為α3= (0,1,1,1,1,1).
根據流類別向量的不同,可將單級流表T拆分為多級流表.為了衡量拆分某個流類別向量后能夠壓縮的流表空間,定義分級收益C(αi)為
(6)
其中,ni為流類別向量αi所對應的規則數.每次迭代時,優先選取分級收益最高的流類別向量作為新的一級子流表.在子流表存儲時,需要根據該子流表對應的查找算法,選取合適硬件存儲器進行存儲,具體描述如下.
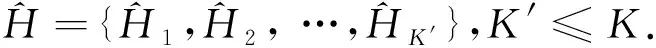
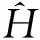
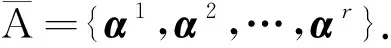

2.2.2 匹配域間正交分解
通過分解流表項中匹配域間的正交組合關系,壓縮匹配域中的重復表項,進一步對流表進行分級.主要思想是統計出流表中每個匹配域fi的重復率,其定義為整個流表中匹配域fi中包含內容重復的次數,記為R(fi).每次迭代時,以貪心的方式選取重復率最高的匹配域提取出來作為一級子流表進行壓縮存儲,從而實現對流表規模的進一步壓縮.直到流表級數達到最大流表級數約束K,或者全部匹配域均已提取完畢時,算法停止,具體描述如下.
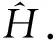
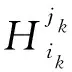
(6) 繼續遍歷集合S,直到集合S中所有元素遍歷完畢或者多級流表H的級數等于K.
通過正交分解進行流表分級時,流表項中各個字段之間的組合關系也隨之消失.為了保證子流表分級前后數據包匹配結果的一致性,需要通過metadata傳遞查找的中間結果,最后根據各級流表查找得出的元數據集合查找動作表,得出最終的action.而metadata只需在action表中存儲前級表項查找得到的序號即可,因此,metadata的存儲開銷非常小.
3 性能仿真
3.1 軟件仿真
由于OpenFlow還沒有廣泛部署于實際網絡中,所以外界難以獲取實際OpenFlow網絡中的流表信息.文中的實驗數據來源于ISN國家重點實驗室研發的高性能同軸電纜寬帶接入(HIgh-performance Network Over Coax,HINOC)[11]網絡中的流分類規則集,并結合OpenFlow 1.3版本的必選匹配域加以擴充,生成不同規模的流表測試集,包括從INPORT到UDPDST的13個匹配域,能夠在一定程度上反映實際OpenFlow網絡中的流表情況.文中實驗數據均是在該實驗條件下得出的.
首先分析文中提出算法的流表存儲空間壓縮性能,其中流表壓縮率指標的定義由式(4)給出.不同流表級數N以及不同的流表規模下的仿真結果如圖2所示.可以看出,相對于單級流表結構,文中方法分級之后能夠節省60%以上的流表空間.在相同的表項數量下,流表劃分的級數越多,流表的空間壓縮率越高.這是因為隨著流表級數增加,流表中不關注的字段表項以及字段內重復的表項被壓縮的越多,從而節省更多的存儲空間.但是,為了實現流水線方式的查找,多級流表需要存儲在相互獨立的硬件存儲器中,因此,更多的流表級數會消耗更多的硬件資源,同時更長的流水線也會增加控制邏輯的復雜度.因此,在實際應用中,要視實際的硬件資源情況來確定流表的級數.此外,從圖中可以看出,在流表級數相同的情況下,隨著流表規模的增大,流表壓縮率的變化較為平緩.這表明在測試集中,文中提出的算法的流表空間壓縮性能對于流表規模變化不敏感,具有較高的穩定性.
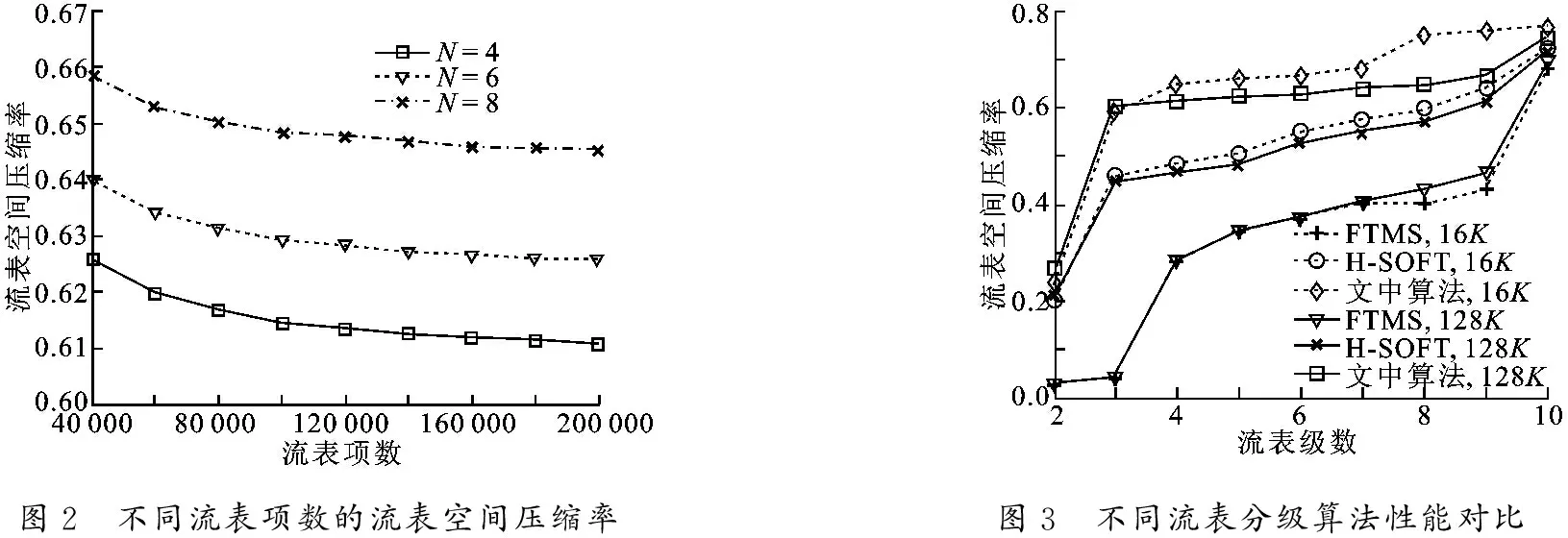
圖2 不同流表項數的流表空間壓縮率圖3 不同流表分級算法性能對比
接下來分析不同流表分級算法之間的流表空間壓縮率性能對比,對比方法包括FTMS[9]算法以及H-SOFT[8]算法,流表規模設置為16K以及128K條表項,仿真結果如圖3所示.從圖中可以看出,各方法的流表壓縮率隨著流表級數的增加而增加.當流表級數較小時 (K=2,3),FTMS算法的流表壓縮性能較差.這是由于這種方法每次分級時只提取出一個匹配域作為一級流表進行壓縮存儲,這種方式無法實現多個匹配域的均勻拆分,導致在流表級數較低時性能會受到嚴重影響.H-SOFT算法是一種啟發式的流表分級算法,該算法首先對流表的匹配域進行分析,刪除表項中的互斥字段從而節省空間.從圖3中可以看出,在不同的流表級數和流表規模下,文中算法均具有較好的流表壓縮性能.當流表級數N=8,流表規模為128K條表項時,相對于FTMS算法,文中算法性能提高了51.5%; 相對于H-SOFT算法,文中算法性能提高了21.4%.當流表級數繼續增大時 (N=10),幾乎所有字段都被拆分出來作為一級單獨的流表,此時各種算法性能較為接近.
3.2 FPGA實現
在現場可編程門陣列(Field Programmable Gate Array,FPGA)平臺上驗證了該多級流表構建與查找算法,實驗環境為Xilinx Virtex 7 xc7vx690t,ISE 14.6以及Modelsim 10.4.FPGA多級流表模塊設計如圖4所示,主要包括幀解析模塊,流表管理模塊,分組處理模塊以及多級流表模塊.當一個分組到達時,分組頭部進入幀解析模塊中提取待匹配的字段信息,而分組數據傳送至分組處理模塊中進行緩存.分組頭部字段提取出之后進入多級流表模塊,以流水線的方式依次匹配各個子流表.多級流表模塊包括TCAM、SRAM和FPGA片內隨機存取存儲器(Random Access Memory,RAM).FPGA片內RAM根據查找算法的不同,分為精確匹配模塊、前綴匹配模塊和范圍匹配模塊.精確匹配模塊使用哈希表查找,前綴匹配模塊使用比特向量(Bit Vector,BV)[12]算法進行查找,范圍匹配算法使用范圍比特向量編碼(Range Bit Vector Encoding,RBVE)[13]算法進行查找.多級流表匹配結束后得到的匹配結果通過指令碼傳遞到分組處理模塊中,分組處理模塊從輸出緩存中提取出分組數據并執行相應的操作.流表管理模塊負責表項的配置,更新和管理.仿真的輸入數據為64字節的以太網最短幀突發,仿真結果顯示在一定的流水線時延之后,查找結果能夠連續輸出,與輸入數據的速率相同,說明文中方法能夠實現流表的線速查找.ISE綜合工具顯示該設計的最高時鐘頻率能夠達到197MHz.在具體硬件實現中,只需系統時鐘在150MHz以上,即可滿足150MPPS(Million Packets Per Second)的分組處理能力,實現 100 Gbit/s 的線速處理.
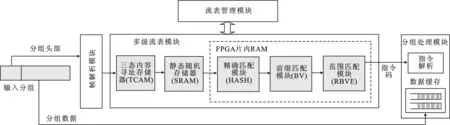
圖4 多級流表模塊的FPGA實現
4 結 束 語
針對SDN中多級流表的分級和查找問題,提出了一種兩步式多級流表構建方法.通過對流表進行流類別拆分和字段間正交分解兩個步驟將單級流表構建為多級流表,在保證硬件可實現性的前提下,充分利用了流水操作提高了數據吞吐量.軟件仿真與FPGA驗證的結果表明,該方法能夠實現流表存儲空間的有效壓縮,并且能夠滿足 100 Gbit/s 的線速查找要求.
