論OT語法的初始狀態(tài)
2018-10-12 03:45:52秦川
外語學刊 2018年2期
秦 川
(香港浸會大學,香港999077)
提 要:優(yōu)選論研究界對一語習得的初始語法有3種觀點:(1)初始排序為M>>F;(2)初始排序為F>>M;(3)初始階段制約條件無排序,其中以前兩種觀點間的交鋒最為激烈。本文分別從理論可學性和實證性的角度回顧和剖析各家觀點,確認M>>F的主張,并指出對M>>F排序最有力的證明來自于實證觀測到的兒童語言。為了從超音段習得的角度檢驗M>>F的假說,基于前人研究,本文探討兒童對漢語普通話聲調的習得,結果同樣印證M>>F的觀點。最后,本文進一步討論關于M>>F排序本身的相關問題,并指出未來研究的方向。
1 引言
優(yōu)選論(Optimality Theory,簡稱 OT)(Prince,Smolensky 1993/2004)已被廣泛應用于語言習得研究。一方面,OT被用來解釋兒童語言習得的各類現(xiàn)象;另一方面,各種驗證OT語法可學性的習得推演算法(learning algorithms)也相繼問世。無論研究的側重點是什么,OT中習得的實質始終是個體語法系統(tǒng)的演變。既然是演變,自然會有如下問題:一語習得中語法演變的起點是什么?本文將圍繞這一問題展開。
2 習得中的初始排序
OT語法包含一系列制約條件,制約條件來源于普遍語法,不同語言間的區(qū)別在于制約條件的不同排序,因此學習者的一大任務就是構建起符合目標語的制約條件排序。具體而言,當學習者接觸到的顯性形式(即實際觀察到的成人語言形式)與自身語法生成的形式不符時,制約條件會被重新排序,這就是OT的錯誤驅動(error?driven)學習。
對于重新排序的形式,影響力較大的是Tesar和 Smolensky(2000)制約條件降級的主張,Boers?ma和Hayes(2001)則認為升級與降級同樣重要。升級也好,降級也罷,我們都要明確重新排序的起點和終點。在一語習得中,終點通常是成人語法排序,可作為起點的兒童語法初始排序就沒那么明確。但出于3方面的原因,我們有必要弄清初始排序:
第一,從語法設計來看,合理的語法體系必須是可學的。OT要成為可學的語法①,必須讓兒童僅靠顯性形式就能在有限時間內從初始狀態(tài)達到目標排序。若假定了一個錯誤的初始狀態(tài),目標排序可能永遠也無法達到。因此,初始排序是OT理論體系里的重要一環(huán)。
第二,OT根植于普遍語法,初始排序對不同語言背景的兒童都是一樣的。在Chomsky(1986:3)看來,普遍語法正是語言機制(language faculty)的初始狀態(tài)。換言之,兒童的初始語法最接近普遍語法的預設值。若能弄清OT語法的初始排序,我們對普遍語法本質的認識將更進一步。
第三,就習得研究而言,只有弄清兒童的初始語法,才能完整地把握兒童語言發(fā)展的軌跡。
由于OT語法表現(xiàn)為標記性制約條件(簡稱M制約條件)和忠實性制約條件(簡稱F制約條件)的相對排列,因此學界對初始排序有過3種主張:(1)兩類制約條件無排序(unranked);(2)M 制約條件高于F制約條件(M >>F);(3)F制約條件高于M制約條件(F>>M)。本文將回顧和剖析這些主張,并指出M>>F的初始排序最能準確反映兒童語言發(fā)展的規(guī)律。
3 早期的可學性模型:M與F無排序
針對OT語法的可學性問題,Tesar和Smolen?sky(1993)提出制約降級算法(Constraint Demotion Algorithm)。根據(jù)他們的觀點,在初始階段所有制約條件都位于同一層級(stratum),隨著兒童開始接觸目標語的顯性形式,顯性形式所違反的制約條件會被逐步降級,直至達到目標語的排序為止。其降級過程可演示如下②:
第一階段:{C1, C2, C3}
第二階段:{C1} >> {C2, C3}
第三階段:{C1} >> {C2} >> {C3}
在以上過程中,被降級的制約條件會形成新的層級,其結果是符合語法的形式在總體上逐漸減少:第一階段的語法會因所有制約條件位于同一層級而接受多個互為平手的表層形式;在第二階段,語法只青睞不違反C1的表層形式;制約條件在第三階段達到完全排序,這時只有一個候選項能勝出。針對無排序的初始階段,Tesar和Smolensky(1993)認為,語言習得應遵循母集原則(Superset Principle):初期語法是后期語法的母集,即初期涵蓋后期的可接受形式。但Tesar和Smolensky并未明確說明習得為何要遵循母集原則,母集原則也僅能視為對所提出算法的一種描述。另外,若初始語法是完全無排序的,各種表層形式應有均等的機會出現(xiàn)在兒童語言中,兒童語言應是隨機的,無規(guī)律的。但恰恰相反,兒童語言及其發(fā)展路徑呈現(xiàn)顯著的規(guī)律性(詳見4.2節(jié)),這顯然是無排序初始階段無法解釋的。
4 支持M>>F的觀點
4.1 M >>F:可學性角度
Tesar和Smolensy(2000)對之前提出的制約降級算法進行修正,認為習得應始于M>>F的排序③。該排序可接受的表層形式最少,是局限性最強的子集(subset)語法。促使Tesar和Smolen?sky做出這一修正的是語言學習中的子集問題(subset problem):當學習者處于母集語法時,僅靠顯性形式無法學到子集語法。這是因為母集包含子集語法可接受的所有形式,符合子集語法的顯性形式同樣也符合母集語法,因此不會產生可驅動學習的錯誤,學習者自然不會改變當前的母集語法(Kager et al.2004:42)。
但根據(jù)OT的基礎豐富性原則(Richness of the Base),子集語法又是必須要掌握的。OT可以允許數(shù)量無限的輸入項,但這些輸入項往往只有一小部分能在表層形式中被忠實體現(xiàn),這就需要子集語法對可能出現(xiàn)的輸出項加以限制。事實上,子集語法也確實存在于人們的語法知識中,McCarthy(2002:205)就給出一個例子。盡管英語中并沒有顯性形式能直接表明由“塞音+鼻音”組成的詞首輔音叢(如[kn])是不可接受的,但英語母語者通常知道這類輔音叢是不合語法的。另一些語言卻可以接受“塞音+鼻音”輔音叢,如德語中就存在[kni]“膝蓋”。在此英語顯然需要一個M>>F的子集語法,德語則是F>>M的母集語法,見表1④。
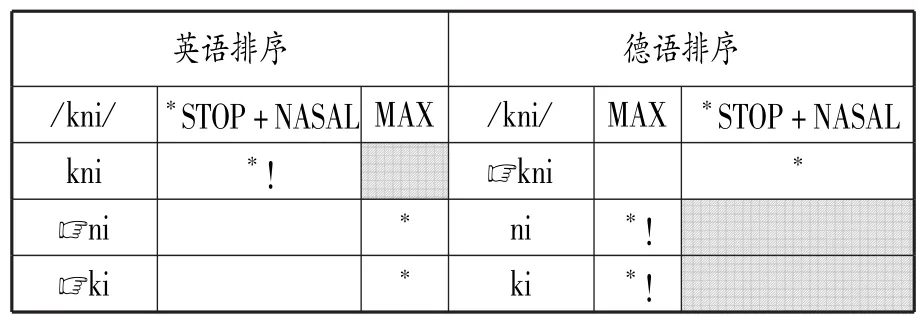
表1 底層形式/kni/在英語及德語中的OT評估表
一方面,兒童須要習得子集語法;另一方面,僅靠顯性形式無法從母集語法達到子集語法,而在自然的習得環(huán)境中,兒童很難通過大量的反面證據(jù)來獲知怎樣的形式不被允許。要解決這一難題,Smo?lensky(1996b),Tesar和 Smolensy(2000)提出的方案是預設一個M>>F的初始狀態(tài),使習得始于子集語法。在M>>F的排序下,語法僅能接受非標記的形式,當學習者接觸到標記的顯性形式時,M制約條件會被降級,直至達到目標語的F>>M狀態(tài);若學習者接觸的都是非標記的顯性形式,制約條件排序會維持在最初的M>>F狀態(tài)。這樣一來,無論是子集語法還是母集語法都將是可學的。
M >>F的初始排序正與 Berwick(1985:37)提出的子集原則(Subset Principle)相一致:當學習者接觸到的語料同時符合母集和子集語法時,要盡量選擇子集語法。Prince和 Tesar(2004:263)指出,M>>F不僅出現(xiàn)在初始語法中,還是貫穿于習得全過程的一種傾向,是學習者遵循子集原則的結果。無論在哪一習得階段學習者都應把F制約條件盡量維持在排序底端,初始階段自然也不例外。
須要指出的是,基于可學性的M>>F主張實質上是一種虛擬假設,目的是為了方便語法運算。該假設正確與否,還有賴于實證的檢驗。
4.2 M >>F:實證性角度
通過實證研究,學者發(fā)現(xiàn)兒童語言中M>>F的例證。 Levelt和 van de Vijver(2004:209)觀測不同音節(jié)類型在荷蘭兒童語言中的出現(xiàn)順序,總結如下:
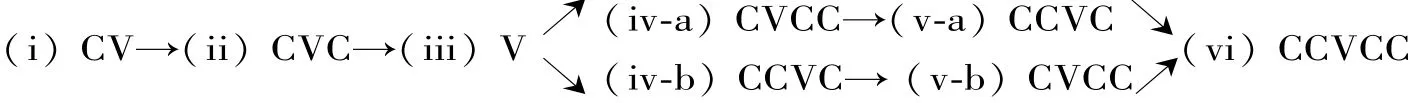
圖1 荷蘭兒童的音節(jié)習得順序⑤
Levelt和 van de Vijver(同上)認為,這一習得順序可用以下制約條件解釋:
ONSET:音節(jié)必須有首音。
NOCODA:音節(jié)不能有尾音。
?COMPLEXONSET:音節(jié)不能有復雜首音。
?COMPLEXCODA:音節(jié)不能有復雜尾音。
FAITH:輸出項與輸入項一致⑥。
在圖1中,階段(i)的CV標記性最低,當上述M 制約條件(即 ONSET,NOCODA,?COMPLEXON?SET,?COMPLEXCODA)都位于 FAITH 之上時,CV是唯一被允許的音節(jié)。隨后的習得可用M制約條件的降級來解釋,每當有新的音節(jié)類型出現(xiàn),一個M制約條件就會被降級。當兒童達到階段(vi)時,荷蘭語中所有的音節(jié)類型都已出現(xiàn),兒童也達到荷蘭語的目標排序:{FAITH >>ONSET,NOCODA,?COMPLEXONSET,?COMPLEXCODA}。 這一由非標記到標記的音節(jié)出現(xiàn)順序也驗證M>>F的初始排序。兒童對復雜音節(jié)結構的簡化在Fik?kert(1994)和 Gnanadesikan(2004)的研究中均有記錄,這些研究都表明NOCODA,?COMPLEXON?SET和?COMPLEXCODA等M制約條件在兒童語法中的高排序。
M>>F排序在兒童對語音配列的習得中也有體現(xiàn)。 根據(jù) Fikkert(1994:57 -59),習得早期的兒童傾向于用塞音作為音節(jié)首音。Kager等(2004:37)認為,這種傾向可用首音響度制約條件(Gna?nadesikan 2004:81)來解釋,如下所示:
μ/a >> μ/e,o >> μ/i,u >> μ/r,l >> μ/m,n >> μ/v,z >> μ/f,s >> μ/b,d >> μ/p,t
上述的“μ/a”表示音段 a應為莫拉(Mora),而以上的排序可理解為響度最高的a最應該為莫拉,而響度最低的p和t最不適合成為莫拉。換言之,當非莫拉位置(如首音)需要某個音段來填充時,塞音p和t將是標記性最低的選擇。兒童用塞音來取代其他的發(fā)音方式,表明首音響度制約條件的排序高于要求底層特征不變的F制約條件IDENT.
Davidson等(2004)通過兒童對語言的感知實證為M>>F提供依據(jù)。Davidson等的感知實驗采用轉頭范式(Headturn Preference Procedure)⑦,其理論假設為:嬰兒會聽到由3個刺激(stimulus)組成的一組錄音{X,Y,XY},其中 XY可被認為是由底層形式X和Y組成的表層形式;若XY越符合嬰兒當前的語法,他們對XY的注意時間會越長。Davidson等對比4、5個月大的嬰兒對以下兩組不同刺激的反應:
組別 1:{on...pa...ompa}
組別 2:{on...pa...onpa}
組別1的ompa產生發(fā)音部位同化;而組別2中onpa忠實保留on和pa的發(fā)音部位。ompa中的同化現(xiàn)象可歸結于M制約條件MNASALPL:鼻音應與隨后相鄰的輔音發(fā)音部位相同。當MNASALPL排序高于F制約條件時,ompa和諧度更高;反之,onpa更合語法。結果顯示大多數(shù)嬰兒對組別1的注意時間更長,這也支持M>>F的初始排序。由于實驗中的嬰兒尚未具備語言產出能力,這一階段的兒童語法也許更能揭示語法的最初狀態(tài)。
4.3 M>>F:產出與感知的不對稱性
兒童語言的一大特點是其在產出(produc?tion)與感知(perception)上的不對稱性——兒童無法精確地產出目標語言形式,卻可以精確地感知語言(Menn, Matthei 1992)。 Smolensky(1996a)指出,只需將初始排序設定為M>>F便可解釋這一不對稱性。
Smolensky(1996a)認為,精確的感知和不精確的產出都源于同一套語法,他們之間的區(qū)別在于語法評估中競爭候選項的不同。在產出語法中,已知某一輸入項,評估裝置會選出最和諧的候選輸出項;在感知語法中,已知某一輸出項,評估裝置需要從眾多候選輸入項中選出最合語法的一個⑧。當處于M>>F排序時,在產出語法中勝出的是標記性最低的候選輸出項。在感知語法中,由于M制約條件只負責評估輸出項,而輸出項已經給出,無論候選輸入項是什么,M制約條件早已被已知的輸出項違反。因此,篩選最優(yōu)輸入項的任務就落在F制約條件上,最忠實于輸出項的候選輸入項將會勝出。
以表2為例,盡管在M>>F排序的作用下,兒童產出的表層形式[ta]偏離目標語形式[tat],但當兒童聽到目標形式[tat]時,感知語法總能忠實地將[tat]理解為正確的底層形式/tat/。
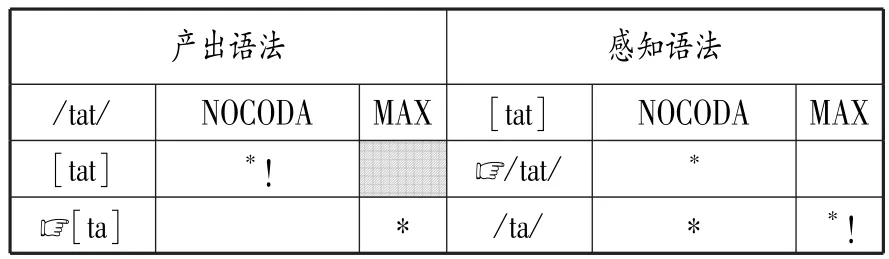
表2 兒童對/tat/及[tat]的產出和感知
5 支持F>>M的觀點
5.1 F>>M:從底層形式習得出發(fā)
Hale 和 Reiss(1998)質疑 Smolensky(1996a)的算法(見4.3),并提出 F>>M 的初始排序。 Hale和Reiss指出,當語言中存在中和(neutralization)時,Smolensky的算法無法將表層形式引導向正確的底層形式。在中和現(xiàn)象中,存在于底層的音位對立會在表層消失,如德語的尾音清化現(xiàn)象:/rat/→[rat]“建議”;/rad/→[rat]“車輪”。 由于“建議”和“車輪”兩詞在表層均為[rat],根據(jù)Smolensky的觀點,聽者會將兩詞同時理解為/rat/,而無法將“車輪”一詞理解為其底層形式/rad/。
Hale和Reiss認為,Smolensky僅能為表層形式匹配一個底層形式,假若聽者能將表層形式與一組底層形式集合相匹配(如將[rat]同時匹配/rat/和/rad/),中和問題將迎刃而解。 為此,Hale和Reiss為語言感知提出以下算法:
(1)當聽到某一表層形式Φ,聽者會為Φ設立一組底層形式集合Ψ,首先確定的集合成員為Φ本身,即Ψ={Φ}。
(2)根據(jù)制約條件排序由高到低逐條進行計算;
(3)當遇到關于某一特征G的F制約條件時,集合Ψ會被“鎖定”:不許再有就G而言與現(xiàn)有成員不同的新成員加入。
(4)當遇到某一M制約條件MX時,集合Ψ會被“擴大”:若現(xiàn)有集合成員沒有違反MX,在Ψ中加入一個新成員,新成員與現(xiàn)有成員的唯一不同是違反Mx.
(5)當余下的M制約條件不高于任何F制約條件時,計算完成。現(xiàn)有集合Ψ即為Φ的所有可能底層形式。
當F>>M時,底層形式集合會在擴大前被F制約條件鎖定;當M>>F時,集合會在鎖定前被M制約條件擴大。在德語中,要求阻塞尾音清化的M制約條件NOVOICEDOBSCODA排序高于IDENT,當聽到[rat]時,除/rat/本身,集合中還會加入違反NOVOICEDOBSCODA的底層形式/rad/;英語的排序是IDENT>>NOVOICEDOBSCODA,底層形式集合在被NOVOICEDOBSCODA擴大前就已被IDENT鎖定,聽者自然不會把[rat]理解為/rad/。
Hale和Reiss進一步指出,若以上算法是解決中和問題的最佳途徑,初始排序必須為F>>M.在M>>F的初始語法下,此算法將無法為學習者構建起正確的底層詞庫,表3以德語為例對此進行說明。
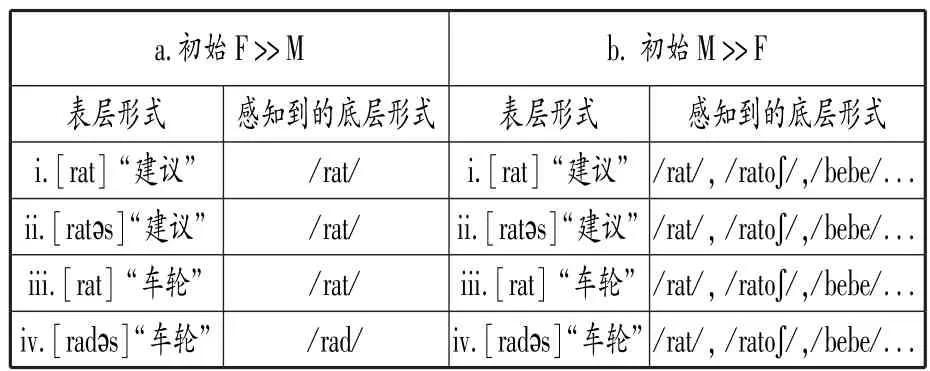
表3 兩種不同語法下學習者對德語的感知
[??s]為單數(shù)屬格后綴,當其出現(xiàn)時,原本中和的/rad/在[rad?s]中忠實呈現(xiàn)(見表3?a?iv)。 如表3?b所示,當M>>F時,在感知語法中首先起效的是M制約條件,所有違反M制約條件的輸入項都將被加入底層形式集合,處于排序底端的F制約條件再也無法鎖定已被無限擴大的底層形式集合。因此,聽者會把一個表層形式與眾多不相關的底層形式(如/rat/,/rato?/,/bebe/)相匹配,而這顯然與事實不符,在此情況下底層詞庫也無法被習得。當初始排序為 F >> M 時,除了表3?a?iii中的[rat]無法被正確理解為/rad/外,其余的表層形式均被正確感知。Hale 和 Reiss 認 為, 解 決 表3?a?iii的 關 鍵 在 于 后 綴[??s],通過[rad?s]與[rat]之間的交替,學習者最終確定表3?a?iii與表3?a?iv共享同一底層詞干 /rad /。
事實上,表3的例子并未顯示出Hale和Reiss的算法有什么高明之處。在F>>M的初始排序下,該算法只能將表示“車輪”的[rat]理解為/rat/本身而不是由/rat/和/rad/組成的集合。 要依靠交替現(xiàn)象,學習者才能把[rat]和/rad/聯(lián)系起來。根據(jù) Smolensky (1996a)的算法,除[rad?s]會被理解為/rad/外,表3?a中其余的表層形式均會被感知為/rat/,這實際上與Hale和Reiss的算法無異。通過替換現(xiàn)象,Smolensky同樣能為“車輪”一詞構建起底層形式/rad/。
即便在德語的NOVOICEDOBSCODA>>IDENT排序下,Hale和Reiss的算法也存在問題。誠然,表示“車輪”的[rat]會與正確的底層形式/rad/聯(lián)系起來,但聽者是否同樣會將原本就應為/rat/的[rat](表“建議”)誤解為/rad/呢? 若如此,Hale和Reiss無非是在解決舊問題的同時又帶來新問題。這一誤解問題在其他場合會被放大,如依照表1中的英文排序?STOP+NASAL>>MAX,當英語母語者聽到表層形式[ni]時,根據(jù)Hale和Reiss的算法,[ni]將會被理解為底層形式/kni/,但在現(xiàn)實中這幾乎不可能發(fā)生。此外,在F>>M的初始排序下,Hale和Reiss(1998)將兒童產出的非標記語言完全歸結于語言運用(perfor?mance)(Chomsky 1965:4),這樣的處理多少有些絕對化,弱化語法的解釋作用。Fikkert和de Hoop(2009:319)也指出,基于語言運用的解釋既不適用于句法領域,也無法說明兒童語言的系統(tǒng)性。
5.2 F >>M:從兒童語言出發(fā)
Fikkert和Levelt(2008)在荷蘭兒童的語言習得中發(fā)現(xiàn)“忠實→非忠實→忠實”的U形發(fā)展過程,認為M>>F初始排序無法解釋U形發(fā)展。
在兒童早期產出的語言中,同一單詞內的輔音往往發(fā)音部位相同,如成人形式[bed]在兒童形式中變?yōu)椋踕?t],其中[d]和[t]皆為舌尖音。在Fikkert和Levelt看來,該階段的兒童尚未對輔音的發(fā)音部位特征進行賦值,整個單詞中唯一賦值的是元音的發(fā)音部位⑨,兒童會將元音的賦值應用于整個詞,因而產生諸如[d?t]的形式([e],[?],[d],[t]皆為舌尖音)。 因此[bed]變?yōu)椋踕?t]的過程可理解為整個詞忠實于元音的發(fā)音部位。
在下一階段,輔音發(fā)音部位開始被賦值,部位不同的輔音也逐漸出現(xiàn)在同一個詞中(如[plk])。然而,在上一階段忠實于成人形式的發(fā)音在這一階段卻開始偏離,如荷蘭語單詞koek(餅干)在初始階段發(fā)成[kuk](3個音段皆為舌根音),在本階段卻變?yōu)椋踭ouk]。Fikkert和Levelt認為這是忠實性的倒退,并且是M>>F的初始排序無法解釋的,因為M制約條件的降級應使兒童越發(fā)忠實于成人形式。Fikkert和Levelt指出導致忠實性倒退的是禁止詞首舌根音的 M制約條件?[DORSAL,而?[DORSAL源自兒童對目標語詞匯頻率的總結:在兒向語言(child directed speech)里詞首舌根音的比例遠低于舌尖音和唇音,兒童會將這一分布趨勢加以概括并形成?[DORSAL。?[DORSAL進入語法后會位于F制約條件之上,從而使koek被實現(xiàn)為[touk]。
根據(jù)Fikkert和Levelt的分析,U形發(fā)展反映的是F>>M的初始語法,M>>F只是由詞匯學習引發(fā)的一個中間狀態(tài)。然而,他們的分析存在問題。首先,初始階段的語言并非完全忠實于元音的發(fā)音部位。 根據(jù) Fikkert和 Levelt(2008:253, 264)提供的數(shù)據(jù),首階段的兒童同樣會產出與元音發(fā)音部位不同的輔音,如有的詞以“舌根輔音+舌尖元音+舌根輔音”的組合形式存在(如[klk]);另一些詞出現(xiàn)輔音之間部位不同的情況,如“唇輔音+舌尖元音+舌尖輔音”。
這些反例對Fikkert和Levelt的觀點形成質疑:整個單詞是否真的忠實于元音的賦值?如將這些反例理解為兒童忠實于原音段(包括元音和輔音)的發(fā)音部位賦值,F(xiàn)ikkert和Levelt又憑何認為其他詞(如[d?t])中的輔音未賦值呢?若無法解釋這些反例,初始階段的語言很難被視作忠實性的反映。其次,依照Fikkert和Levelt的分析,首階段的忠實性其實是對元音發(fā)音部位的忠實(而非輔音)。然而階段二中的[touk]和成人形式[kuk]的元音皆為舌根音,并未發(fā)生忠實性倒退,而成人與兒童間的輔音差異([k]和[t])也不屬于這一倒退范疇。另外,?[DORSAL這樣的M制約條件本身也值得懷疑,它們僅來源于兒童對某一階段接觸到的詞匯的概括,既沒有類型學事實依據(jù),也缺乏生理基礎。隨著兒童接觸的詞匯進一步增多,這類制約條件會被降級,抑或從語法中消失?Fikkert和Levelt未給出進一步解釋。
6 比較分析
在數(shù)量和論證角度上,支持M>>F初始排序的觀點始終是主流,而通過對Hale和Reiss(1998),F(xiàn)ikkert和Levelt(2008)的分析不難發(fā)現(xiàn),F(xiàn) >>M 的觀點并不可取。因此,本文進一步證實M>>F的主流觀點。盡管如此,支持M>>F的論述仍存在一些值得商榷之處。
根據(jù)Tesar和 Smolensky(2000)從可學性出發(fā)的論述,語法學習靠的是由顯性形式引起的M制約條件降級,我們可以做出如下假設:從M>>F排序轉變?yōu)镕>>M是可行的,但從F>>M轉變?yōu)镸>>F理論上行不通。可在Trapman和Kager(2009)對二語習得的研究中,母語語法為F>>M的學習者卻能成功習得排序為M>>F的目標語法。對Trapman和Kager的實驗結果有兩種可能的解讀:(1)子集語法的可學性問題根本就不成立,顯性形式同樣能帶來F制約條件的降級;(2)由于二語習得涉及到更多的顯性教學,學習者會接觸到更多的反面證據(jù),這些反面證據(jù)會帶動F制約條件的降級。究竟那一種解讀正確還有待進一步的研究來證明。若解讀(1)正確,兒童初始語法當然也有可能是介于M>>F和F>>M之間的某種中間狀態(tài),類似于成人的二語初始語法。
Smolensky(1996a)預測兒童非標記的語言產出及忠實的感知。但Pater(2004)指出,早期的語言感知并非完全如Smolensky所預測的那般準確無誤,如Jusczyk等(1999)曾記錄兒童無法正確感知語音的現(xiàn)象。Pater認為,語法中應存在兩組F制約條件,一組負責語言產出,另一組負責語言感知,兩組F制約條件與同一組M制約條件相互作用(Pater 2004:230)。根據(jù)Pater的觀點,初始排序應為{M >> F感知, F產出},而 Smolensky(1996a) 反映的其實是隨后的{F感知>> M >>F產出}。無論Smolensky與Pater哪一方正確,他們的觀點在本質上體現(xiàn)的都是M>>F的初始排序。
相比以上角度,對M>>F排序最無可爭議的證據(jù)來自兒童的非標記語言。從習得順序來看,兒童語言普遍遵循的是一條由非標記到標記的發(fā)展路徑;若兒童語言里出現(xiàn)非忠實的表層形式,表層形式的標記性往往低于其底層形式。在F>>M或無排序的初始語法下,我們很難解釋為何兒童語言中最早出現(xiàn)的是CV音節(jié),也無法解釋為何兒童首先掌握的音節(jié)首音是塞音。
7 從漢語聲調習得看OT初始語法
誠然,兒童的習得實證是對初始語法最有力的證明,但前人的研究集中于英語、荷蘭語等非聲調語言,考察的通常是音段或音節(jié)的習得,對聲調等超音段的習得卻很少考慮⑩。漢語作為聲調語言,兒童對漢語聲調的習得恰巧能填補這一理論空白,為初始語法提供進一步的依據(jù)。為此,本文將從OT語法的角度來重新審視前人的實證研究。
基于發(fā)音難度,Yip(2001:315)將不同聲調的標記性歸結如下:
(1)曲折調的標記性高于平調:?CONTOUR
(1)升調的標記性高于降調:?RISE>>?FALL
(3)高調的標記性高于低調:?H>>?L
以上的M制約條件可反映為一組固定排序,即?RISE>>?FALL>>?H >>?L.根據(jù)以上制約條件,漢語普通話的第三聲(降升調)涉及到兩組曲折調,標記性理應最高;第二聲(升調)和第四聲(降調)雖然同為曲折調,但第二聲的標記性高于第四聲;第一聲為高平調,標記性最低。根據(jù)M>>F的初始語法,排序越低的M制約條件應越早遭到降級,標記性越低的聲調也理應越早出現(xiàn)在兒童語言中,我們可以為普通話預期這樣的習得順序:高平調→降調→升調→降升調。
兒童語言習得是否也遵循同樣的發(fā)展路徑呢?本文將以Zhu(2002:78-105)的歷時研究為例討論這一問題。Zhu記錄4名北京兒童從一歲至兩歲期間對普通話聲調的習得,普通話四聲調分別于以下時間出現(xiàn)在這4名兒童的語言中:

表4 北京兒童對普通話聲調的習得順序?
高平調與降調在同一時間出現(xiàn),是出現(xiàn)最早的聲調;升調緊隨其后,其于一個月后出現(xiàn)在兩名兒童的語言中,另兩名兒童則在同一時期開始掌握一、二、四聲;對所有4名兒童而言,最晚出現(xiàn)的聲調均是降升調。因此,Zhu的聲調習得順序大致可總結為“高平調、降調→升調→降升調”。這一順序基本符合M>>F的預期,但仍有一處不同:高平調的出現(xiàn)并未早于降調。然而,Zhu(2002)提供的另一組數(shù)據(jù)顯示這一預測仍然適用,表5顯示這4名兒童第一聲和第四聲的發(fā)音正確率達到66.7%的時間。
高平調正確率達到66.7%(即Zhu指的穩(wěn)定期)的時間普遍早于降調,這也反映出降調確實對兒童構成更大的習得困難。另一個支持“高平調→降調”順序的證據(jù)來自Li和Thompson的普通話母語習得研究,他們(1977:191)著重描述習得初期的一個有趣現(xiàn)象:曲折調極少出現(xiàn),除少數(shù)例外,多數(shù)曲折調被發(fā)成平調,見表6?。
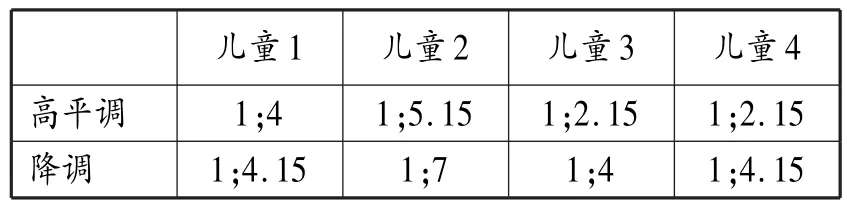
表5 兒童一、四聲發(fā)音正確率達到66.7%的時間
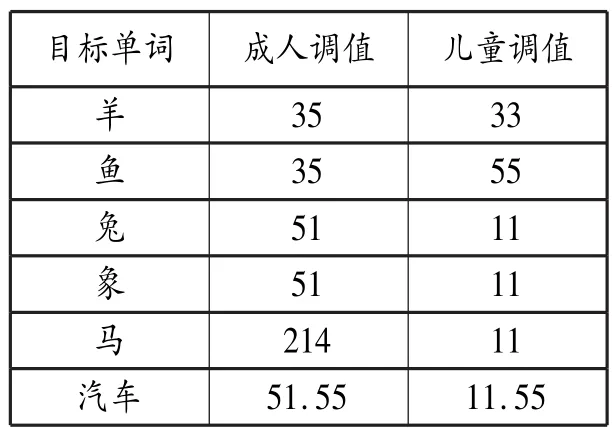
表6 兒童對曲折調的發(fā)音
表6中“羊”和“魚”的升調分別變成中平調33和高平調 55;“兔”、“象”和“汽車”的“汽”均由降調變?yōu)榈推秸{11,而“車”字原本的高平調維持不變。兒童對平調的偏愛表明平調的習得應早于曲折調,與M>>F的預期相符。值得注意的是,“兔”和“象”并非是直接變?yōu)槠胀ㄔ挊I(yè)已存在的高平調,而是變成低平調11。考慮到?H>>?L的標記性排序,低平調的出現(xiàn)應能等到解釋——降調變成標記性更低的低平調。低平調的意外出現(xiàn)也恰巧反映OT中的“非標記產生”現(xiàn)象(the emer?gence of the unmarked)(McCarthy, Prince 1994),進一步支持M>>F的初始排序。事實上,M>>F的初始排序在其他漢語方言的聲調習得中也有體現(xiàn),例如Tse(1978)記錄兒童對粵語聲調的習得,結果同樣顯示平調的出現(xiàn)早于曲折調,降調早于升調?。
8 M>>F排序的進一步問題
不管論證的出發(fā)點是什么,絕對的M>>F排序本身也有待進一步探討。OT語法中存在一類固定排序的M制約條件,Prince和Smolensky(1993/2004:141)給出以下例子:
(1) 音節(jié)首尾和諧度:?a >>?i >> ...>>?d>>?t
(2) 音節(jié)峰和諧度:?t >>?d >>...>>?i >>?a
上面的(1)表示在音節(jié)首尾(margin)位置,音段a的接受度最低,i次之,t最高;(2)表示在音節(jié)峰(peak)位置音段的接受度恰好相反。然而,(1)和(2)的制約條件會被任何表層音節(jié)違反:任何首音和尾音都違反(1),任何音節(jié)峰都違反(2)。在絕對的M>>F排序下,優(yōu)選項會將底層音段統(tǒng)統(tǒng)刪除,這是因為若表層無任何音段,對(1)和(2)的違反也就無從談起,付出的代價僅僅是違反低排序的F制約條件MAX.由于固定排序的M制約條件,M>>F初始排序將導致語法無法生成任何表層形式,其結果為兒童沒有語言產出。對于M>>F是否仍然正確,存在兩種可能。
第一,以兒童產出的首個有意義的單詞為界,若兒童之前發(fā)出的咿呀、咕咕等聲是受語法支配的語言,M>>F初始排序將無法自圓其說,因為M>>F預測的是兒童如啞巴一般什么都不說。但根據(jù)Stager和Werker(1997)的兒童感知研究,早期的兒童似乎很難將聽到的語音與其意義聯(lián)系起來,若兒童無法在聲音及意義之間建立聯(lián)系,我們當然不能把咿呀、咕咕等視為有意義的語言,因此該可能不成立。
第二,若兒童首詞之前的咿呀學語是無意義的語言,M>>F的初始排序仍能說得通,因為咿呀、咕咕根本不是語法的產物,與生成零表層形式的語法并不沖突。但照此理,當兒童說出首個有意義的單詞時,他們的語法已不是絕對意義上的M>>F,某些M制約條件已經受到降級。盡管M>>F排序下的語言系統(tǒng)是極其簡單的,但這一簡單的習得起點恰恰反映兒童語言從無到有,從簡單到復雜的蛻變過程。
以上的論述還回答Fikkert和de Hoop(2009:319)提出的初始語法的改變究竟是發(fā)生在首詞前還是首詞后的問題——當兒童開始說出首個單詞時,初始語法已經改變;在真正的初始語法下,兒童其實并不具備語言產出能力。既然真正的初始語法存在于首詞之前,我們就要在未來的研究中獲取盡可能早期的兒童語言證據(jù)。顯然,Da?vidson等(2004)采用的轉頭范式為將來的研究提供一個可借鑒的模板。
除兒童語言外,我們還可以從其他領域尋找初始語法的證據(jù),這里值得一提的是二語習得和借詞。一些在一語顯現(xiàn)不出作用的M制約條件在二語會變得至關重要,通過觀察這些M制約條件在學習者語言中的排序,我們可以獲知它們在初始語法的位置。例如Broselow,Chen和 Wang(1998)探究普通話母語者學習英語時的尾音清化現(xiàn)象,并將此分析為NOVOICEDOBSCODA位于F制約條件之上。但普通話中并沒有阻塞尾音,自然也不存在提升NO?VOICEDOBSCODA的語法過程,因此NOVOICEDOB?SCODA的高排序只能源自M>>F初始語法。類似的,Shinohara(2004)和 Davidson 等(2004)對借詞的研究也為M>>F初始排序提供支持。
9 結語
本文回顧和分析對OT語法初始狀態(tài)的各家觀點,鑒于F>>M初始排序在解釋力上的不足,本文進一步證實M>>F的主流觀點,同時認為對M>>F排序最具說服力的證據(jù)來自兒童早期的語言產出及感知。有鑒于此,本文從漢語聲調習得的角度進一步探究這一問題,結果顯示超音段習得同樣也遵循M>>F的初始排序。作為OT語法的重要一環(huán),M>>F的初始排序對我們把握語言習得及普遍語法的本質具有重要意義。由于漢語與西方語言分屬不同語系,有諸多不同,通過考察兒童對漢語的習得,我們能為初始語法研究提供更多新的信息,這也是我們中國學者能為理論界做出貢獻的一個方向。
注釋
①關于OT語法可學性的論述,參見馬秋武(2003)。
②C1,C2,C3等指代不同的制約條件。
③近年來,新的可學性算法相繼問世(如Boersma 2009,Tesar 2012),但這些算法并未過多提及初始排序問題,此處不做討論。
④M制約條件?STOP+NASAL阻止“塞音+鼻音”的輔音叢;F制約條件MAX要求輸出項保留輸入項的音段。
⑤圖1中的 C 表示輔音,V 表示元音。 (iv?a)和(iv?b)代表個體間習得順序的差異,一些兒童先掌握復雜尾音,另一些先掌握復雜首音。
⑥為便于表達,所有F制約條件被統(tǒng)一概述為FAITH.
⑦關于轉頭范式的具體介紹,見Jusczyk(1998)。
⑧根據(jù)基礎豐富性原則,可有數(shù)量上無限的候選輸入項。
⑨Fikkert和Levelt(2008)認為,輔音和元音的賦值差別源于語音感知,在感知中元音更凸顯。
⑩須要說明的是,習得包含音系、句法、語義等層面,由于篇幅有限,也由于OT研究集中于音系領域,本文討論的主要是音系的習得。
?表4中的1;2表示一歲兩個月;1;2.15表示一歲兩個半月。
?表6采用的是Chao(1930)的調值標注系統(tǒng),聲調高度被分為5個等級,1為最低,5為最高。
?兒童發(fā)出的平調有可能是無調狀態(tài),這一點有待進一步考證。但姑且不論平調是否是調,“降調 → 升調 →降升調”的習得順序足以說明M>>F的排序。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2022年11期)2022-02-14 07:14:12
文苑(2020年4期)2020-05-30 12:35:30
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
兒童繪本(2018年5期)2018-04-12 16:45:32
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
雜文選刊(2016年7期)2016-08-02 08:39:56
小天使·一年級語數(shù)英綜合(2016年6期)2016-05-14 12:21:05
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
