兩種翻譯方向下語言隱喻對源語理解過程的影響
2018-10-12 03:45:58王一方
外語學刊 2018年2期
王一方
(英國杜倫大學,杜倫DH12JZ)
1 引言
在翻譯學領域,“無論從翻譯實踐的角度,還是從理論探討的角度”(Sch?ffner 2004:1253),隱喻翻譯的研究都“引發了許多至關重要的問題”(Do?brzynska 1995:595)。隨著科技發展和實證研究方法的應用,學者們逐漸開始關注隱喻認知過程(Jones et al.2006; Faust, Weisper 2000)。 雖然關于概念隱喻的認知過程研究很多,但對語言隱喻的關注度不高(項霞 鄭冰寒2011:423)。“隱喻式的思維是一種在感覺思維基礎上沉淀人類文化基因的思維方式,它已經成為人類思維的一種本源性的和本然性的思維能力,是人類的一種建設性和創造性的思維。”(徐盛桓 廖巧云2017:11)語言隱喻與概念隱喻相對立(Lakoff 1993:202, K?vecses 2002:33),指的是“將原用于指代某物的詞或詞組指代另一事物,因為兩個所指之間存在一些真實或隱含的相似性”(Anderson 1964:53,項霞 鄭冰寒 2011:422)。
在語言隱喻相關的認知過程研究中,專門針對語言隱喻翻譯過程的實證研究數量不多,與大量的翻譯實踐不成比例。大多數對語言隱喻認知的理論探討和實證研究結果都不能直接應用在語言隱喻翻譯過程研究中。因為學者們發現,認知目的會對認知資源分配模式造成顯著影響。如Jakobsen和Jensen通過眼動追蹤法證實,以理解為目的的閱讀和以翻譯為目的的閱讀相比,二者所耗費的認知負荷量存在顯著差異(Jakobsen,Jensen 2008)。Carl和Dragsted發現,翻譯過程經常會始于針對原文含義的“推測”,即對譯文的部分構思,然后原文的含義“會隨著翻譯過程而浮現與固化”(Carl,Dragsted 2012:143)。 此外,Balling等學者也通過眼動等實驗方法發現,譯者在源語理解的過程中已經開始目的語再形成的預處理(Balling et al.2014:251)。這些發現證實,就認知資源的分配模式而言,翻譯時的理解過程與閱讀時的理解過程存在顯著差異。這就意味著,此前大量關于隱喻認知和理解過程的實證研究(Diaz et al.2011;Wang,He 2013;Obert et al.2014),由于其實驗設計大多基于普通閱讀而非翻譯,所以直接用來描述隱喻翻譯的理解過程會缺乏客觀性和準確性。
鑒于上述情況,要想準確描述隱喻對譯者的源語理解產生的影響,理論模型和實驗設計必須基于隱喻翻譯來構建。本研究秉持這一原則,采用眼動法和鍵擊法等實證手段,描述38位譯者的隱喻筆譯過程;重點研究在英漢和漢英筆譯時,語言隱喻對源語理解所耗費的認知資源造成哪些影響;然后進一步探討:在英譯漢和漢譯英這兩個翻譯方向下,語言隱喻對源語理解過程的影響是否會隨著翻譯方向的改變而改變。
2 隱喻翻譯的理解過程與翻譯方向
作為翻譯學領域最古老的課題之一(Gile 2005:9),翻譯方向主要指譯者在從事翻譯活動時譯入還是譯出第一語言(Beeby 1998:63-64)。在很多國家,譯出母語數量占據整個翻譯行業的半壁江山(Shuttleworth, Cowie 1997:90),翻譯方向的研究越來越得到重視(Newmark 1988:52)。調查顯示,中國大陸的譯者“經常譯出母語”(Wang 2011:907);在香港翻譯界,從母語譯入英語的需求之大,“深刻影響專業譯者的工作模式”(Li 2001:89)。在這一現實背景下,實證研究和理論指導非常必要。作為最常見的修辭手法之一,隱喻翻譯的實踐無法擺脫行業現狀的影響,相關研究和理論指導對隱喻翻譯實踐的意義自不待言。
傳統的翻譯方向研究以理論探討為主,近年來,學者們也逐漸開始用實證手段研究這一課題,實證研究方法包括有聲思維法、眼動追蹤法、鍵擊法、事件相關電位等。許多學者對翻譯方向與譯者認知資源分配模式的關系尤為關注(Jensen,Pavlovi'c 2009;Chang 2011等)。譬如,Kroll和Stewart提出的修正層次模型(the Revised Hierar?chical Model)認為:比起從第二語言譯入第一語言,一個單詞從第一語言譯入第二語言時要耗費更多的時間和經由更復雜的認知路徑(Kroll,Stewart 1994)。簡單來講,第一語言的詞匯存儲與概念存儲之間的鏈接清晰而牢固;相比之下,第二語言的詞匯存儲與概念存儲之間的聯系則脆弱得多,二語詞匯與概念的連接常常要經過與其對應的第一語言詞匯。一語和二語存儲在同一個語義系統,但二語和一語的詞匯表征相互獨立;在很多情況下,二語單詞譯入一語的過程可以只通過詞匯層面而不牽涉語義,不啟動概念。因此,二語單詞譯入一語所耗費的翻譯時長顯著短于一語譯入二語。
這一模型被置入不同語言之間進行驗證和探討(Altarriba, Mathis 1997;Jiang 1999;Rinne et al.2000),如Chang通過眼動追蹤法、功能性磁共振成像等證實,修正層次模型不但在單詞層級成立,在英漢文本互譯過程中,也存在“翻譯的不對稱性”(translation asymmetry)(Chang 2011:156)。然而,在關于翻譯方向的實證研究中,源語和目的語文本往往被視為實驗載體,并沒有得到應有的重視。具體來說,本研究考察的重點是“以語言隱喻為核心的、不同種類源語的理解過程的差異”,這一點很少被列入翻譯方向過程研究中。
對隱喻翻譯過程來講,將翻譯方向納入研究范疇,在行業現狀的實際需求下,能解決許多重要問題,如隱喻認知翻譯過程理論和實驗結果的適用性等。Sj?rup在英語譯入丹麥語的研究中發現,相比于字面表達(literal expression)的理解過程,隱喻的理解過程所消耗的認知負荷并沒有顯著增多(Sj?rup 2013:204)。 這一發現是否僅僅局限于英語譯入丹麥語值得探究。同等文本難度下,丹麥語譯入英語時是否也會發生同樣的情況呢?考慮到不同翻譯方向對譯者認知資源分配模式的 影 響 (Tokowicza, Kroll 2007:778;Chang 2011:156),直接用該發現來描述丹麥語譯入英語的翻譯過程會不客觀,對兩個翻譯方向進行對比研究才能回答這一問題。以往的隱喻翻譯過程實證研究很少與翻譯方向相結合,語言隱喻翻譯過程實 證研 究 (Mandelblit 1996;Tirkkonen?Condit 2002;Jensen 2005;Martikainen 2007;Sj?rup 2013;項霞 鄭冰寒 2011;Zheng, Xiang 2014; Sch?ffner,Shuttleworth 2013;Schmaltz 2015;Koglin 2015)較常涉及到的問題包括:背景信息與隱喻視譯過程(項霞 鄭冰寒 2011; Zheng,Xiang 2014)、隱喻翻譯的過程和產出(Tirkkonen?Condit 2002,Sj?rup 2013)、隱喻翻譯過程與翻譯能力(Jensen 2005)、隱喻對譯者認知資源分配模式的影響(Sj?rup 2013, Schmaltz 2015)、隱喻與譯后修改過程(Ko?glin 2015),等等。本研究的核心問題之一是隱喻對源語理解過程的影響,而源語理解過程的描述一般只基于一個翻譯方向,因此隱喻翻譯的理解過程與翻譯方向的關系尚未得到足夠的探討。
基于上述情況,本研究將譯者的認知資源分配模式、語言隱喻的翻譯過程和翻譯方向這3個問題結合起來,進行系統考察;采用眼動追蹤法和鍵盤記錄法,通過觀察和描述38位被試漢英互譯的過程,探究以下問題:(1)相比于字面表達,譯者在理解語言隱喻的過程中,所耗費的認知資源是否有區別;(2)源語中特有的語言隱喻(特定隱喻)和源語與目的語中都有固定表達的語言隱喻(共有隱喻),二者理解過程中耗費的認知資源是否有區別。在本實驗中,語言隱喻對譯者認知資源的影響分為以下幾個方面:對翻譯過程中的認知資源總量的影響、對譯者認知資源調配的影響以及對譯者工作記憶認知負荷的影響(Hvelplund 2011:220),通過眼動等實證方法的數據描述每一個方面的影響。(3)對于第一語言為漢語,第二語言為英語的中國譯者來說,語言隱喻對源語理解過程的影響,是否會隨著翻譯方向的改變而發生變化。換句話說,譯入和譯出母語相比,語言隱喻對源語理解過程的影響有哪些異同?
3 研究設計
3.1 實驗設置
本實驗的主要研究方法為眼動追蹤法,輔助方法為鍵盤記錄法。被試在筆譯過程中的眼動追蹤數據由Tobii TX300(300Hz)眼動儀采集,鍵擊數據由Translog II鍵盤記錄軟件采集。在實驗過程中,被試在同一臺電腦上完成翻譯任務。被試距離電腦屏幕60-65厘米,電腦顯示屏尺寸為23英寸,分辨率為1280?1024。在屏幕上,源語與目的語以左、右分割方式呈現。源語字體大小和間距都按字數成比例調整,英文字體為Times New Roman,中文字體為宋體。字號為16,行間距為1.5 倍。
3.2 被試
本研究共招募到38位英國杜倫大學翻譯學女碩士生,她們自愿參與實驗。被試年齡為22-24歲,來自中國大陸,她們的第一語言為漢語,第二語言為英語。被試入學前英語雅思成績平均分為7分(SD=0.5)。所有被試的雙眼矯正視力為1.0以上,日常電腦筆譯時基本為盲打,并且能熟練使用實驗電腦上提供的中文輸入法(搜狗拼音輸入法)。被試參加實驗前先簽署實驗同意書,并獲得10英鎊的樂購購物券作為報酬。
實驗結束后,在38位被試中,共有34位被試的眼動數據通過質量評定標準。眼動數據質量評定標準包括以下幾個方面:屏幕注視總時間(gaze time on screen),注視樣本占比(gaze sample to fi?xation percentage),平均注視時長(mean fixation duration)(Rayner 1998,Hvelplund 2011)。
3.3 實驗文本
為提升內容效度,本實驗隨機設計兩組翻譯任務,譯者隨機選擇并完成其中一組任務。每組任務各包含一篇英文原文和中文原文。這兩組翻譯任務的漢英原文都是包含語言隱喻的簡單日常對話,通俗易懂,沒有使用特殊句型或專業術語,閱讀難度較低。兩組翻譯任務的區別是:在第一組的漢英原文中,每句話都包含一個語言隱喻,句子順序與隱喻類型(特定隱喻、共有隱喻)無關。第二組原文中的隱喻按照類型固定分配:全文有9句話,前3句話是字面表達,中間3句話各包含1個共有隱喻,最后3句話各包含1個特定隱喻。有16名被試抽簽抽到第一組任務,有22名被試抽到第二組任務。在數據分析時,原文中的隱喻被切割出來作為語言隱喻的關注區域(area of interest),與字面表達的數據做對比。
針對同一任務內的英文和中文原文,由于本實驗重點考察翻譯過程中語言隱喻對理解過程的影響,再將兩個翻譯方向的隱喻影響做宏觀對比,而不是直接對比兩個翻譯方向的源語理解過程。所以,實驗中同一任務內英語原文和漢語原文的對比度沒有嚴格的要求,文風、篇幅、句型、詞頻難度在同一范圍內即可。對比度主要集中在同一篇文章中的句子和句子之間。本文參考之前的眼動與鍵擊研究(Sj?rup 2013;Chang 2011;Jensen,Pavlovic 2009)中涉及的語言因素,從以下幾個方面著手,保障同一個翻譯任務文本內句子之間的對比度:全文風格、句型結構、句子長度以及每句話的平均詞頻數、難詞比例、平均詞長和單詞平均音節,這些都作為實驗文本設計客觀評定方面的主要內容。
兩個任務漢英原文的風格都是日常會話。句型結構為基本的主謂賓結構、主系表結構和簡單的祈使句。這4篇文章中的句子的平均詞頻數接近(中高頻詞大于85%),難詞比例接近(每句話最多包含一個低頻單詞)。第一組任務的英文篇幅為96個單詞,中文篇幅121個漢字;第二組任務的英文篇幅為125個單詞,中文篇幅151個漢字;第一組任務的英文句子長度為11-15個單詞,中文句子長度為15-19個漢字;第二組任務的英文句子長度為13-15個單詞,中文句子長度為15-17個漢字。在第一組任務和第二組任務的英文原文中,每句話的平均詞長接近,分別是:3.93 -4.92 和3.40 -4.77;每個句子的詞平均音節數也接近,分別是:0.91 -1.67 和0.86 -1.23。
3.4 實驗過程
實驗包括3個階段:前期培訓、熱身階段和第一個翻譯方向與第二個翻譯方向階段。實驗開始前,派發給被試一個實驗流程和注意事項表。被試在了解實驗過程后,將完成一個熱身任務,把一篇50個單詞的文本從英文翻譯成中文。熱身階段的環境與正式實驗的環境完全一致。
第一個翻譯方向和第二個翻譯方向的任務都遵循以下流程:校準瞳孔位置后,屏幕顯示提前設計好的原文。翻譯任務以及翻譯方向的順序均按編碼隨機分配給被試。被試在理解原文的同時,在電腦上產出并鍵入目的語。整個翻譯過程除被眼動儀和Translog II軟件記錄之外,被試的翻譯行為還被錄影裝置所攝錄。被試完成第一個翻譯任務后,有1分鐘的休息時間,然后開始進行另一個翻譯方向的實驗任務。
4 結果與討論
針對譯者在翻譯過程中如何調配“處理模塊”(processing building blocks),本實驗參考“并行模式”(the parallel view)(Balling et al.2014)和“混合模式”(the hybrid view)的觀點(Hvel?plund 2011, Ruiz et al.2008),沿用丹麥學者Hvelplund(2011)的實驗設計,將翻譯過程中的認知加工類型(cognitive processing type)分為3類:源語處理(source text processing)、目的語處理(target text processing)和平行處理(parallel pro?cessing)。其中,平行處理是指譯者的源語和目的語處理同時發生。比如,在翻譯過程中,源語迻譯(ST rendition)與目的語再形成(TT reformulation)常常發生在同一時刻(Ruiz et al.2008:491),這一疊加的認知現象被納入平行處理的范疇。
在本研究中,3個認知加工類型分別對應3種注意單位:源語文本注意單位、目的語文本注意單位和平行處理注意單位。每一個注意單位都是由原始眼動與鍵擊數據切分而成。這些注意單位一共組成4項指標,從不同的角度來描述譯者的認知資源分配情況,它們分別是:注意總時長、注意單位次數、注意單位時長和瞳擴。其中,注意總時長、注意單位時長和瞳擴3項指標分別對應翻譯過程中的認知資源總量、譯者認知資源的調配情況和譯者工作記憶的認知負荷(Hvelplund 2011:220)。
從上述介紹可知,在翻譯的理解過程中涉及到的加工類型有兩種:源語處理和平行處理。所以,數據分析將在源語注意單位和平行注意單位上開展。也就是說,在本研究中,描述翻譯時理解過程的主要數據來源為注視在源語的有效眼動數據,而鍵盤記錄法的主要用途是注意單位的切分和翻譯過程與產出的記錄。
本研究采用SPSS統計軟件中的廣義線性模型(generalised linear model)來分析客觀指標數據。廣義線性模型是基于正態線性模型發展出來的統計分析模型,被廣泛應用在醫學、經濟學、社會學等許多領域(陳希孺2002:54)。廣義線性模型不但適用于屬性數據、計數數據等離散數據,還允許偏離均值的隨機誤差服從多種分布,如伽馬分布、逆高斯分布、泊松分布等,非常適用于本研究探討的問題和數據類型。在本研究中,廣義線性模型的固定變量按屬性分為3組:組1:字面表達;組2:共有隱喻(在源語和目的語中都有固定表達的隱喻);組3:特定隱喻(只在源語中有固定表達的隱喻)。在所有指標的模型中,協變量包括關注區域面積和語言因素協變量。在英—漢翻譯方向的注意總時長和注意單位指標的模型中,關注區域位置(AOI position:關注區域距離屏幕中心直線距離)也列入協變量。
對于漢—英翻譯方向,語言因素協變量為詞頻,每個眼動—鍵擊指標導入一個模型中進行計算。對于英—漢翻譯方向,語言因素協變量包括單詞平均音節數、單詞平均字母數和詞頻;關注區域為每個模型的恒定協變量、不同的語言因素協變量與恒定協變量組合。即每個指標導入3個模型中進行計算,然后統一對比計算結果。模型計算結果按照具體的每一項眼動—鍵擊指標(如瞳擴)呈現,示例參見表1。
如表1所示,如果一個模型中的固定變量或協變量的顯著值低于0.05,則說明該變量對指示變量的影響顯著。在計算出所有模型的結果后,每項指標所描述的認知負荷量,按照字面表達、共有隱喻和特定隱喻的分組從大到小排序。英—漢翻譯方向和漢—英翻譯方向的計算結果對比見表2(表2只列出在每個模型的固定變量分組中,區別達到顯著性標準的對比項)。
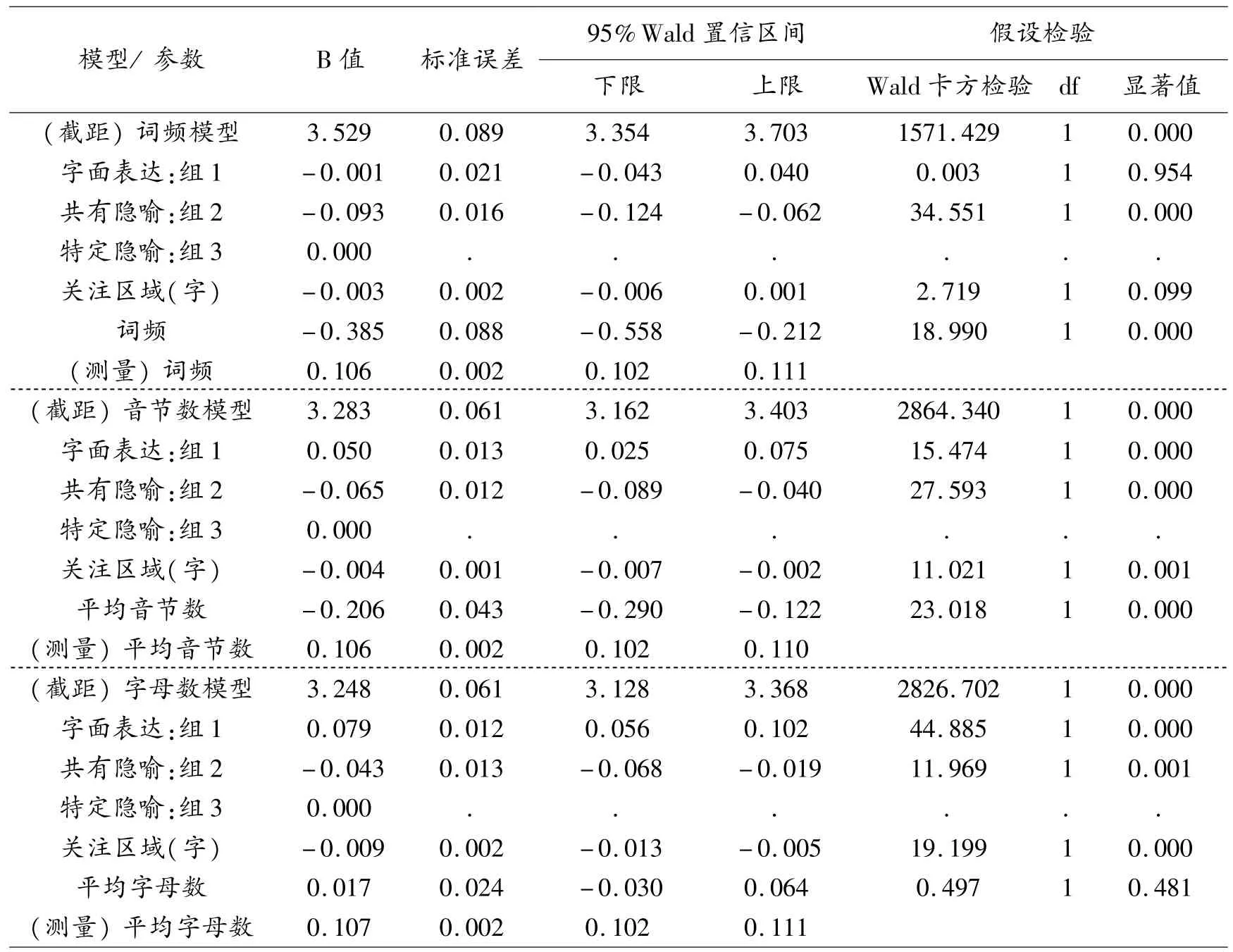
表1 廣義線性模型計算結果示例(英—漢瞳擴值)

表2 源語理解的認知資源分配:英—漢和漢—英翻譯方向對比
如表2所示,在漢—英和英—漢這兩個翻譯方向中,所有的眼動—鍵擊指標都顯示,譯者在理解字面表達、共有隱喻和特定隱喻時,耗費的認知資源存在顯著的差別。但在不同的翻譯方向中,這種差別的表現形式不同。
首先,針對翻譯過程中,字面表達和語言隱喻理解的差異(此處,共有隱喻和特定隱喻統一歸為語言隱喻,與字面表達相區分),兩個翻譯方向的結果不盡相同。(1)漢—英翻譯方向4個指標的結果非常一致。所有數據結果都顯示:與語言隱喻的理解過程相比,字面表達的理解過程更加耗費譯者的認知資源。(2)在英—漢翻譯方向,各項指標的結果則相差甚遠。注意總時長和瞳擴這兩個指標的結果顯示:字面表達的理解過程比語言隱喻更加耗費認知資源;但二者在注意單位時長上,結果完全相反;同時在注意單位次數上,二者的區別并不顯著。由于注意總時長、注意單位時長和瞳擴3項指標分別對應翻譯過程中的認知資源總量、譯者認知資源的調配情況和譯者工作記憶的認知負荷(Hvelplund 2011:220),所以可得出如下結論,在英—漢翻譯過程中,字面表達的理解所消耗的認知資源總量和譯者工作記憶的認知負荷超過語言隱喻,但其所占的單位認知資源小于語言隱喻。
其次,對于不同類型隱喻之間的區別,不同翻譯方向的表現形式也不同。(1)在漢—英翻譯方向,4項指標的結果大相迥異。數據顯示,特殊隱喻的理解比共有隱喻要耗費更多的注意總時長和注意單位次數,但特殊隱喻的理解的注意單位時長卻顯著小于共有隱喻。而在瞳擴方面,二者的區別不顯著。(2)在英—漢翻譯方向,4項指標的結果也略有出入。注意總時長、注意單位次數和瞳擴這3個指標,都顯示特殊隱喻的理解比共有隱喻更耗費認知資源。但二者在注意單位時長上的區別卻并不顯著。
本研究關于英漢翻譯的客觀數據結果與前人研究中基于其他語言的實證研究結果之間存在一些共性。Sj?rup發現,當譯者從第二語言(丹麥語)譯入第一語言(英語)時,源語中的語言隱喻讓語篇更連貫(facilitate textual coherence),它的出現能幫助譯者更加準確而迅速地理解原文信息(Sj?rup 2013:160)。 Sj?rup 認為這個發現印證Black(1981)、Koller(2004)和 Noveck 等(2000)的觀點:隱喻在翻譯中具備一定功能和“潛在的裨益”(the potential to yield benefits)(Noveck et al.2000:118)。本實驗的結果表明,在第二語言為英語,第一語言為漢語的二語譯入一語的過程中,如果譯文的難度被控制在較低的程度,從注意總時長和瞳擴這兩個指標來看,語言隱喻的出現使譯者在源語理解上消耗的認知負荷顯著減少。
參考并對照 Sj?rup(2013)的實驗,Schmaltz(2015)在其漢語(第一語言)譯入葡萄牙語(第二語言)的實證研究中發現,即使翻譯方向從譯入母語變成譯出母語,她的數據結果和 Sj?rup(2013)的結果也很一致:在翻譯過程中,理解不包含隱喻的原文所占用的認知資源并不小于理解隱喻時的認知資源。她們認為,這些數據結果與Mason(1982),Inhoff和 Carroll(1984),Gibbs等(1997)的觀點相符(Schmaltz 2015:188),即隱喻的出現不會增加翻譯任務的難度,或迫使譯者在原文上傾注更多的精力。與這些發現相一致的是,在本實證研究中,所有眼動—鍵擊指標都顯示:在翻譯的文本難度較低的情況下,母語中語言隱喻的出現,無論是“時間就是金錢”這樣的共有隱喻,還是“逃不出五指山”這樣的特定隱喻,都會促進譯者對原文的理解,顯著降低他們在理解中消耗的認知負荷量,讓翻譯過程變得更加迅速和順暢。
5 結論
本實驗的眼動—鍵擊數據結果表明,在漢英翻譯過程中,隱喻的出現會對源語理解的認知資源分配造成顯著影響。而這一影響在不同的翻譯方向上,具體表現也有所不同。
問題一:對翻譯過程中出現的語言隱喻,譯者是否要花費更多精力去理解。數據結果顯示:在漢—英翻譯過程中,所有指標都顯示,語言隱喻的理解并不需要花費更多的認知資源,甚至比字面表達更容易理解。但在英—漢翻譯過程中,不同指標的結果存在差異,4個指標中有2個指標的結果與漢—英翻譯方向的結果一致:語言隱喻理解的單位時長大于字面表達;而語言隱喻理解的注意總時長和瞳擴都顯著小于字面表達,并且二者在注意單位次數上的區別并不顯著。
問題二:特定隱喻和共有隱喻的理解所耗費的認知資源是否有區別。實驗結果顯示:在漢—英翻譯過程中,不同指標的結果存在差異。4個指標中,有2個指標顯示特殊隱喻的理解比共有隱喻更耗費認知資源:特殊隱喻的注意總時長和注意單位次數顯著高于共有隱喻,但其注意單位時長卻小于共有隱喻,此外,二者在瞳擴指標上的區別也并不顯著。而在英—漢翻譯過程中,除注意單位時長之外,所有的指標都顯示,特殊隱喻的理解更加耗費認知資源。
問題三:對于第一語言為漢語,第二語言為英語的中國譯者,語言隱喻對源語理解過程的影響,是否會隨著翻譯方向的改變而發生變化。數據結果顯示,在譯者理解第二語言的原文時,語言隱喻的出現會在某些方面促進理解,但在某些方面,會加重譯者的認知負荷。但在理解母語的簡單文本時,語言隱喻會幫助譯者更省力地理解原文。此外,原文中語言隱喻是否在目的語中具備對應的固定表達對第二語言理解的影響較大,但對母語譯出時的原文理解的影響,在各個指標上存在明顯的差異。
簡而言之,在中譯英和英譯中兩個翻譯方向之間,語言隱喻對翻譯理解過程的影響存在明顯差異。雖然現有的實證方法并不能百分之百地還原譯者大腦內部的認知過程,并確認其完全遵從修正認知層次模型,但本研究的結果可以證實:“翻譯不對稱性”不僅在單詞和文本層面上存在,而且在隱喻對源語理解過程的影響上也同樣存在。值得一提的是,這些發現的前提是翻譯原文的難度控制在較低標準,同時譯者具備一定程度的翻譯能力。在這個課題未來的研究中,譯者的翻譯能力和實驗的文本難度將是非常有意義的延伸方向。
猜你喜歡
汽車實用技術(2022年7期)2022-04-20 11:44:42
計算機應用(2022年2期)2022-03-01 12:33:42
載人航天(2021年5期)2021-11-20 06:04:32
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年1期)2021-01-21 03:22:38
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
外語學刊(2016年4期)2016-01-23 02:34:15
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
