F-粗糙集視角的概念漂移與屬性約簡
2018-11-01 08:01:10鄧大勇李亞楠黃厚寬
自動化學報 2018年10期
鄧大勇 李亞楠 黃厚寬
現實中的數據往往隨著時間推移而變化,例如,證券交易數據、微博、微信、視頻、傳感器數據等,這種類型的數據稱為數據流[1].數據流具有按照時間順序排列、快速變化、海量甚至無限,并且可能出現概念漂移現象等特征[2?3].概念漂移目前尚無統一定義,是指數據流中概念(或目標變量的統計特性)的不穩定性、不確定性,以及隨著時間變化而變化的特征.數據流挖掘是當前數據挖掘研究的一個熱點,數據流分類和概念漂移探測是當前數據流挖掘的主要研究方向.
數據流的分類策略主要有:單一分類器[4?6]和集成分類器[3,7?11].概念漂移的探測準則主要有:分類準確率和聯合概率.無論是單一分類器還是集成分類器都常用分類準確率(或分類錯誤率)判斷概念漂移,將分類準確率低的分類器進行淘汰或改進,從而提高分類效率.除了分類準確率外,聯合概率也常用于探測概念漂移[12?14].分類準確率往往用于通過實驗分析探測概念漂移,聯合概率則往往用于從理論上對概念漂移進行分析或探測.
粗糙集理論[15?17]是一種處理不精確、不完全、含糊數據的有效數學工具,是數據挖掘和分類的重要方法.屬性約簡與不確定性分析是粗糙集理論的兩個重要應用.傳統的粗糙集理論不太適合研究海量的、動態變化的數據,也不太適合研究數據流;F-粗糙集[18?19]是第一個動態粗糙集模型,它將粗糙理論從單個信息表或決策表推廣到多個.與F-粗糙集相對應的屬性約簡方法是并行約簡.F-粗糙集和并行約簡比較適合研究動態變化的數據,能夠研究數據流和概念漂移.
利用粗糙集理論研究數據流和概念漂移比較少見.文獻[20?21]利用粗糙集上下近似的變化去度量概念漂移,這種從數據的結構角度度量概念漂移的方法,難以進行移植和擴展,也難以推廣應用;文獻[22]把每個滑動窗口看成是一個決策子表,利用F-粗糙集和并行約簡的方法整體刪除冗余屬性,通過比較不同子表之間的屬性重要性變化探測概念漂移,不受上下近似結構的限制,具有很好的移植性和擴展性.除了并行約簡之外,粗糙集理論中還有很多種類的約簡,例如,Pawlak約簡、互信息約簡[23]、條件熵約簡[24?25]等.粗糙集屬性約簡準則往往是不確定性分析的有力工具,例如,對應Pawlak約簡、互信息約簡、條件熵約簡等的屬性依賴度、互信息、條件熵等,都是粗糙集理論分析數據不確定性的有力工具.但是,能否直接用粗糙集屬性約簡準則探測概念漂移?屬性約簡與概念漂移有什么關系?受文獻[22]啟發,本文努力揭示粗糙集理論的屬性約簡和概念漂移之間的內在聯系.
本文首先從概念漂移的角度討論了粗糙集的屬性約簡與概念漂移之間的聯系和區別;其次,探討粗糙集屬性約簡觀點下的概念漂移準則與傳統的概念漂移準則(包括分類準確率和聯合概率)之間的區別與聯系.在此基礎上,提出了屬性依賴度和條件熵的概念漂移探測準則,分析了條件熵和聯合概率在探測概念漂移方面的聯系.理論分析和實驗結果顯示,與分類準確率一樣,屬性依賴度和條件熵能有效地探測概念漂移.屬性依賴度和條件熵具有聯合概率進行理論分析的優點,又具有分類準確率進行實驗分析比較的優點,并且可以增加可重用性、減少工作量.
1 基礎知識
本節簡單介紹粗糙集[15?17]、F-粗糙集和并行約簡[18?19]的基本知識.
1.1 粗糙集
IS=(U,A)是一個信息系統,其中U是論域,A是論域U上的條件屬性集.對于每個屬性a∈A都對應一個函數a:U→Va,Va稱為屬性a的值域,U中每個元素稱為個體、對象或行.
對于每一個屬性子集B?A和任何個體x∈U都對應一個如下的信息函數:
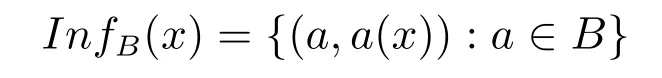
B-不分明關系(或稱為不可區分關系)定義為
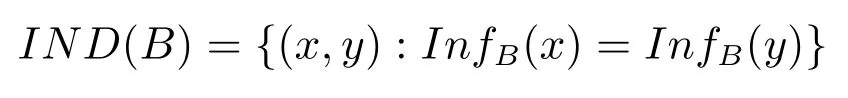
任何滿足關系IND(B)的兩個元素x,y都不能由屬性子集B區分,[x]B表示由x引導的IND(B)等價類.
對于信息系統IS=(U,A)、屬性子集B?A和概念X?U,有
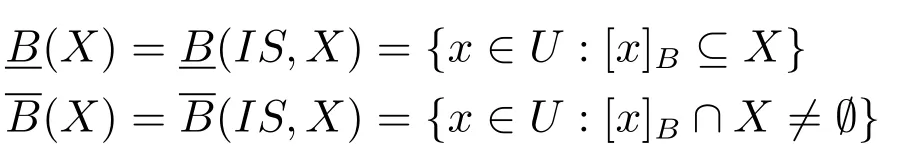
分別稱為B-下近似和B-上近似.B-下近似也稱為正區域,記為POSB(X).序偶稱為粗糙集.
在決策系統DS=(U,A,d)中,決策屬性d將論域U劃分為塊,U/g0gggggg={Y1,Y2,···,YM},其中Yi(i=1,2,···,M) 是等價類. 決策系統DS=(U,A,d)的正區域定義為POSA(d)
有時決策系統DS=(U,A,d)的正區域POSA(d)也記為POSA(DS,d)或POS(DS,A,d).
定義1[15?17].在決策系統DS=(U,A,d)中,稱決策屬性d以程度h(0≤h≤1)依賴條件屬性集A,其中,
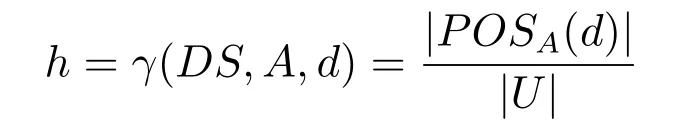
符號|·|表示集合的勢.
1.2 F-粗糙集
F-粗糙集[18?19]和其他任何粗糙集模型不同,它是關于信息系統簇或決策系統簇的粗糙集模型,這個粗糙集模型比較適合并行計算,也適合研究事物的動態變化.
下面用FIS={ISi}(i=1,2,···,n) 表示與決策系統簇F={DTi}相對應的信息系統簇,其中ISi=(Ui,A),DTi=(Ui,A,d).
定義2[18?19].假設X是一個在不同情形下可能發生變化的概念(即X是一個概念變量),N是一種情形,X|N表示在情形N下的概念X.在一個信息系統簇中,.如果不引起混淆,X|N可以縮寫為X.
假設X是信息系統簇FIS中的一個概念,那么X關于屬性子集B?A的上近似、下近似、邊界線區域和負區域的定義如下:
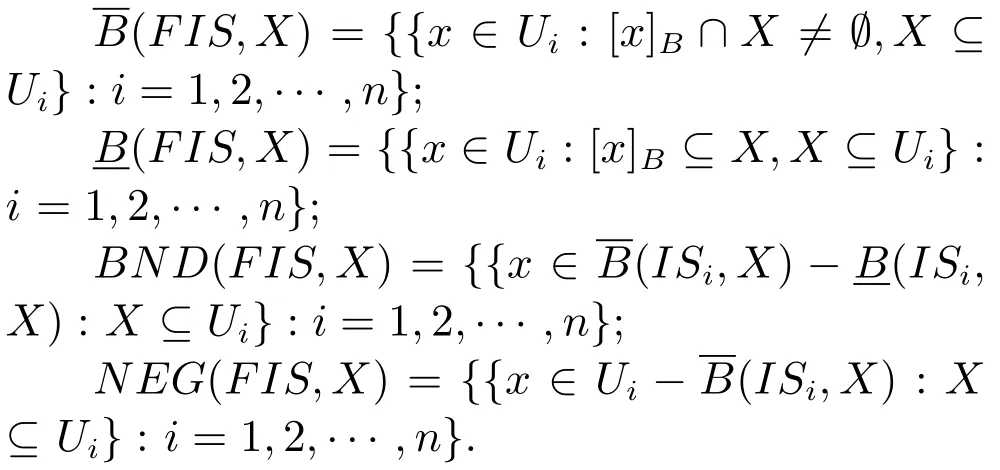
概念X關于信息系統簇FIS的上下近似、邊界線區域、負區域分別是FIS中的信息子系統關于概念X的上下近似、邊界線區域、負區域組成的集合.序偶稱為F-粗糙集.如果則稱序偶是精確的.
定義3[18?19].設F是一個決策系統簇,F的正區域定義如下:
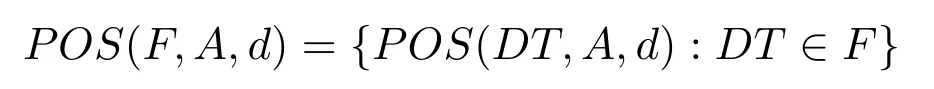
定義4[18?19].設F是一個決策系統簇,稱B?A為F的并行約簡當且僅當滿足下面條件:
1)POS(F,B,d)=POS(F,A,d);
2)對任意S?B,都有.
2 概念漂移準則分析與比較
概念漂移的評判準則主要分析比較以下三種:
1)分類準確率(或分類錯誤率).如果分類器對數據集的分類準確率有較大的變化,一般情況下是指分類準確率下降,而且超過了一定的閾值,則稱發生了概念漂移.分類準確率是最常用的一種概念漂移探測準則,常常用于實驗分析中.
使用分類準確率的變化判斷是否發生概念漂移,是一種使用概念漂移的結果進行判斷的方法,也是使用最廣泛的方法.這種方法依賴實驗或實際應用,能夠從總體上把握概念漂移,無論是在單一分類器還是集成分類器中都使用最廣泛.但是,對于同一訓練集得到的分類器,對于同一測試集,如果特征選擇不同,則實驗結果可能不同.
2)聯合概率.聯合概率p(X,Y)=p(X)p(Y|X)(其中,X表示由條件屬性誘導的概念,Y表示由決策屬性誘導的概念)發生變化,而且超過一定的閾值.用聯合概率作為概念漂移檢測準則又分為虛擬漂移和真實漂移.虛擬漂移[12,14]是指在聯合概率中p(Y|X)不發生變化,僅p(X)變化;真實漂移[13?14]是指在聯合概率中p(X)不發生變化,而p(Y|X)發生變化.
聯合概率的準則也較常用.這種準則因為有較強的數學理論基礎(統計理論與概率論),所以,從理論方面研討概念漂移,人們喜歡使用聯合概率的準則.但是,這個準則局限于某些概念,缺乏靈活性,對于整個數據集而言就不太實用.這是因為聯合概率p(X,Y)只能針對某些特定的研究其變化,而整個數據集可能是一系列的有序對,它們的概率分布并不相同,也很難用同一個表達式表示,如果用聯合概率p(X,Y)研究其變化,難以從總體上把握概念漂移.
3)屬性重要性.用屬性重要性變化探測概念漂移是文獻[22]新提出來的.屬性重要性是數據的內部屬性,是概念的內涵.用屬性重要性準則探測概念漂移,分析屬性重要性隨著數據的變化而變化,不直接依賴于概念的外延,而且用并行約簡進行特征選擇,統一了比較準則,避免了特征選擇不同對概念漂移探測產生的負面影響,所以,用屬性重要性準則探測概念漂移,既有確定性,又有靈活性;既能用于實驗檢測,又能用于理論分析,兼具有分類準確率準則和聯合概率準則的優點.
文獻[22]定義的基于屬性重要性的概念漂移準則,探測了并行約簡后各個屬性重要性的變化而引起的概念漂移,但是文獻[22]中單個屬性重要性的變化不能全面反映數據流中的概念漂移.為了更好地與分類準確率、聯合概率分布進行比較,本文定義和使用屬性依賴度和條件熵作為概念漂移探測準則.
3 屬性約簡與概念漂移的對比與分析
粗糙集中有很多種類的屬性約簡,其中最常用的是基于正區域的屬性約簡和基于互信息的屬性約簡.這些屬性約簡的準則,從概念漂移的角度看,就是在同一數據集中保持在屬性約簡準則下不發生概念漂移的最小屬性子集.但是各種準則并不一定兼容,有時一個準則可能違背另一個準則,也就是說,在一個準則下不發生概念漂移的約簡,在另一個準則下可能發生概念漂移.實際上,基于互信息的屬性約簡等價于基于條件熵的屬性約簡,但是因為條件熵比互信息更接近聯合概率,所以,本文以基于正區域的屬性約簡和基于條件熵的屬性約簡為例進行闡述.
定義5[15?17].給定一個決策系統DS=(U,A,d),B?A稱作決策系統DS的一個約簡當且僅當B滿足如下兩個條件:
1)POS(DS,B,d)=POS(DS,A,d);
2)對任意S?B,都有POS(DS,S,d)(DS,A,d).
定義6[15?17].給定一個決策系統DS=(U,A,d),B?A稱作決策系統DS的一個約簡,當且僅當B滿足如下兩個條件:
1)γ(DS,B,d)=γ(DS,A,d);
2)對任意的S?B,均有γ(DS,S,d)(DS,A,d).
定義5從正區域的結構出發定義了屬性約簡,定義6從屬性依賴度角度定義了屬性約簡;定義5適合理解,定義6適合計算.從概念漂移角度看,定義5的條件屬性約簡保證決策系統正區域不發生改變,保證正區域部分的條件概率p(Y|X)=1,即正區域部分不發生真實概念漂移;定義6的條件屬性約簡保證了決策系統的屬性依賴度不發生概念漂移;定義5只適合于單個決策表本身,不適合推廣.定義6可以從決策子表簇角度進行推廣,適合于探測決策子表簇中概念漂移.所以,在決策子表簇中可以將基于屬性依賴性的概念漂移準則定義如下:
定義7.在決策子表簇F中,DTi,DTj∈F相對于屬性依賴度的概念漂移定義為
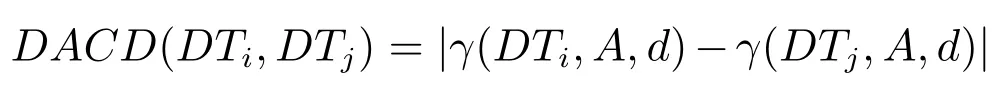
定義8[24?25].給定一個決策系統DS=(U A,d),設A和g0gggggg在論域U上導出的劃分分別為X和Y,其中,的信息熵分別定義為
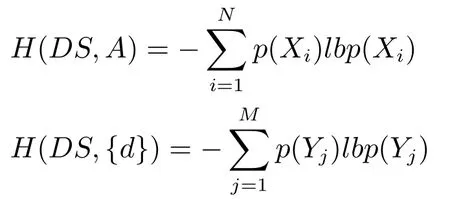
g0gggggg相對于A的條件熵定義為
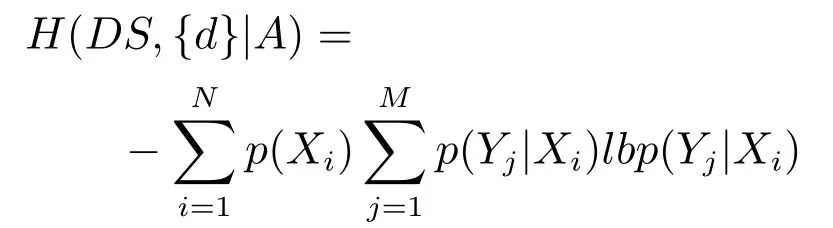
定義9[24?25].給定一個決策系統DS=(U,A,d),若B?A滿足下列兩個條件:
1)H(DS,g0gggggg|A)=H(DS,g0gggggg|B);
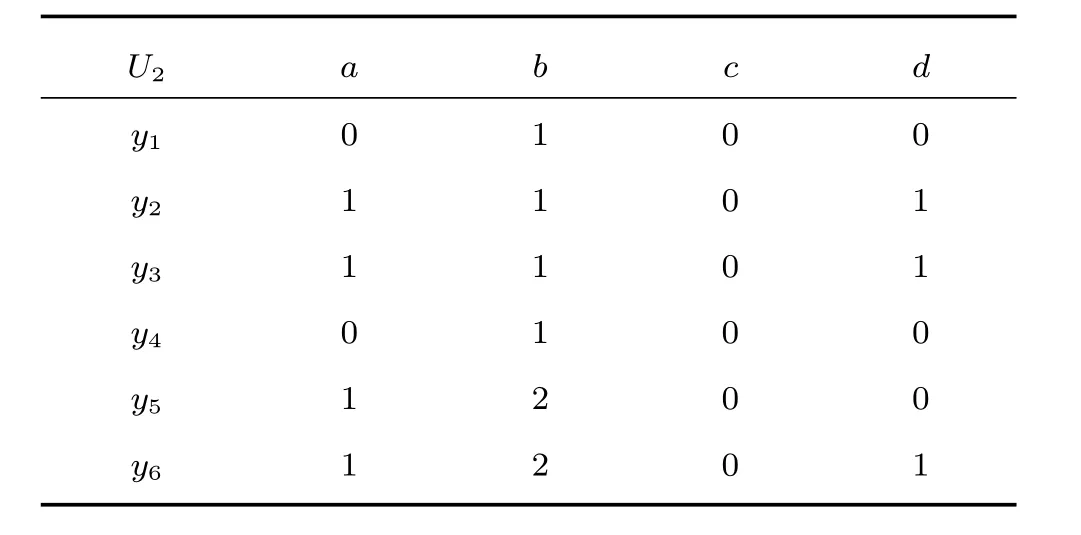
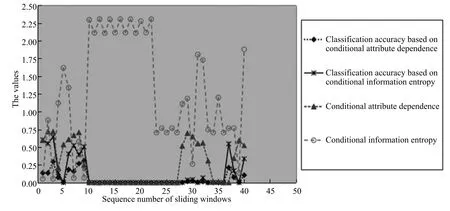
2)對任意b∈B,都有H(DS,g0gggggg|B) 則稱B是A的一個基于條件熵的相對約簡. 定理1.給定一個決策系統DS=(U,A,d),B1?B2?A,由B1,B2導出的劃分分別為U/B1={X1,X2,···,XN},U/B2={X1',X2',···,XM'},則聯合概率有如下關系:p(Xl',Yj)≤p(Xk,Yj),其中Xl'=[x]B2∈U/B2,Xk=[x]B1∈U/B1,Yj∈U/g0gggggg. 證明.對于中的每一塊,要么等于中的某一塊,要么是某幾塊的并.不失一般性,有,所以有,即 關于在一個系統中的條件熵隨條件屬性的變化,有下面引理: 引理1[25].給定一個決策系統DS=(U,A,d),B1?B2?A,則有 成立. 定理1和引理1說明,在一個決策系統中,聯合概率與條件熵都是隨著條件屬性的增加而單調不增.根據文獻[26]的屬性約簡準則,條件熵可以作為屬性約簡的準則,聯合概率也可以作為屬性約簡的準則;類似地,聯合概率可以作為概念漂移的準則,條件熵也可以作為概念漂移的準則. 定義10.在決策子表簇F中,DTi,DTj∈F相對于條件熵的概念漂移定義為 定理2.在決策子表簇F中,B?A是F相對于條件熵的并行約簡,DTi,DTj∈F,則約簡后相對于條件熵的概念漂移等于約簡前的概念漂移,即 定理3.在決策子表簇F中,B?A是F相對于屬性依賴度的并行約簡,DTi,DTj∈F,則約簡后相對于屬性依賴度的概念漂移等于約簡前的概念漂移,即 定理2和定理3根據相關定義可以非常容易證明.定理2和定理3說明,在條件熵和屬性依賴度等屬性約簡的條件下,并行約簡不會影響概念漂移的度量和探測,并且并行約簡可以將冗余屬性刪除,減少計算量,彰顯對概念漂移發生起作用的條件屬性. 通過以上分析和論述,粗糙集和F-粗糙集的屬性約簡準則可以推廣用于概念漂移的度量和探測.概念漂移和屬性約簡存在一定的內在聯系,屬性約簡是保證單個決策表或決策表簇內部不發生概念漂移的最小屬性子集,而一般情況下的概念漂移則是不同的數據集或變化的數據集之間某種度量發生變化而產生的. 定義11.在決策子表簇F中,,其中,并設內涵相同(即它們對應的屬性值相等),則的條件熵概念漂移定義為 下面討論聯合概率與條件熵在探測概念漂移方面的關系. 定理4.在決策子表簇F中,,其中,并設X與X'、Y與Y'內涵相同(對應的屬性值相等).用聯合概率準則探測發生虛擬概念漂移,則用條件熵準則也發生虛擬概念漂移;若用聯合概率準則發生真實概念漂移,則用條件熵準則也同樣發生真實概念漂移. 證明.反設用聯合概率準則沒有發生概念漂移,即, 1)在p(X)不變,即的情況下: 2)在p(Y|X)不變,即的情況下. 定理4說明,用聯合概率分布能探測到的虛擬概念漂移和真實概念漂移都能用條件熵探測.從上述推理過程可知,定理4的逆定理也成立. 例1.設F={DT1,DT2},如表1和表2所示.a,b,c是條件屬性,d是決策屬性. 表1 決策子系統DT1Table 1 A decision subsystemDT1 表2 決策子系統DT2Table 2 A decision subsystemDT2 顯然,F的并行約簡為 于是, 從例1可以看出,無論是從屬性依賴度還是從條件熵的角度,只要選取的參數δ<1/3,兩種標準都發生了概念漂移. 由此可見,概念漂移和屬性約簡具有內在的聯系.概念漂移探測的有些準則(例如聯合概率)能夠用于屬性約簡,反過來,屬性約簡的準則(例如屬性依賴度和條件熵)也能用于概念漂移探測.屬性約簡就是保證某種準則下不發生概念漂移的刪除冗余屬性過程.然而,作為不確定性度量指標的屬性依賴度僅考慮正區域部分的數據,不考慮非正區域部分的數據,無論是在屬性約簡方面還是在探測概念漂移方面都忽略了非正區域數據的變化;而條件熵則把所有的數據都考慮在內,在屬性約簡和概念漂移探測上全盤考慮了數據的變化.所以,我們推測,大部分條件屬性約簡準則能夠用于概念漂移探測,能夠用于數據流概念漂移探測的屬性約簡準則應該滿足不依賴于數據的結構,但不同的不確定性指標在屬性約簡和概念漂移探測方面各具特色.深入分析其他的屬性約簡準則是否能夠用于概念漂移探測,以及研究它們在概念漂移探測方面的區別與聯系,是我們下一步研究的內容. 下一節將通過實驗比較屬性依賴度、條件熵和兩種特征選擇(屬性約簡)后的分類準確率作為概念漂移探測準則.這兩種特征選擇分別是基于屬性依賴度的屬性約簡和基于條件熵的屬性約簡. 實驗數據為KDD-CUP991http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html網絡入侵檢測數據10%的子集.該數據包含494021條記錄,42個屬性.實驗中滑動窗口的大小分別為5000和10000,相鄰窗口之間有或無10%的重復率,實驗中將第一個數據集(滑動窗口)當成訓練集,其余的數據集都是測試集. 理論分析和實驗結果顯示,分類準確率和屬性依賴度都屬于[0,1],而條件熵的值可以大于1,實驗結果也證實了這一點. 圖1~4雖然只是顯示了這幾種準則相對于訓練集的值,沒有直接顯示概念漂移,但只要這些指標數值和訓練集相應的指標數值相減,然后取絕對值,并與閾值(可以根據需要自己設定)進行比較,就可以很容易判定是否發生概念漂移.而且圖1~4非常明顯地顯示,特征選擇不同,對同一個數據集的分類準確率不同. 圖1~4顯示基于屬性重要度/條件熵的分類準確率和屬性依賴度的整體變化趨勢不如條件熵明顯,所以條件熵能更加準確地探測概念漂移. 圖1顯示在第10~27個滑動窗口,基于屬性重要度/條件熵的分類準確率的值為0,屬性依賴度的值接近于0,變化趨勢不明顯,均不利于探測概念漂移;在第10~22個滑動窗口,條件熵的變化也不明顯,但在探測概念漂移過程中,條件熵優于分類準確率和屬性依賴度. 圖2顯示在第25~43個滑動窗口,基于屬性重要度/條件熵的分類準確率的值為0,屬性依賴度的值接近于0,變化趨勢很不明顯,不利于探測概念漂移;雖然在第32~38個滑動窗口,條件熵的變化趨勢很小,但是在探測概念漂移的過程中,條件熵優于上述三種方法. 圖3顯示在第30~50個滑動窗口,基于屬性重要度/條件熵的分類準確率的值為0;在第35~65個滑動窗口,屬性依賴度的值趨近于0,且變化趨勢不大;在第40~50個滑動窗口,條件熵的變化趨勢也不明顯.但是,條件熵變化不明顯的滑動窗口數目較少,因此,條件熵作為概念漂移的探測準則較優. 圖4顯示在第15~33個滑動窗口,基于屬性重要度/條件熵的分類準確率的值為0,屬性依賴度的變化較小,均不利于探測是否發生了概念漂移;條件熵的變化能有效的探測概念漂移. 圖1 滑動窗口的大小為10000,且相鄰窗口之間沒有重復Fig.1 The size of sliding windows is 10000 without repeat 圖2 滑動窗口的大小為5000,且相鄰窗口之間沒有重復Fig.2 The size of sliding windows is 5000 without repeat 圖3 滑動窗口的大小為5000,且相鄰窗口之間有10%的重復Fig.3 The size of sliding windows is 5000 with 10%repeat 圖4 滑動窗口的大小為10000,且相臨窗口之間有10%的重復Fig.4 The size of sliding windows is 10000 with 10%repeat 從圖1~4可以看出,使用這些指標都可以在一定的程度上判定是否發生概念漂移,但分類準確率只能與訓練集比較,相鄰兩個滑動窗口(數據集)之間相對于分類準確率是否發生概念漂移,只能以一個為訓練集,另一個為測試集,工作量相當大,而且沒有對稱性;如果將兩個相鄰滑動窗口相對于訓練集的分類準確率之差進行概念漂移探測,那么很多時候都不利于探測概念漂移.然而使用屬性依賴度和條件熵作為概念漂移的判定標準,在元素個數和屬性集不發生變化的情況下,每個決策表的屬性依賴度和條件熵都是不變的,屬性約簡也不影響它們的值,任何兩個數據集(滑動窗口)之間都可以進行比較,而且具有對稱性和可重用性,從而可以減少工作量. 本文從F-粗糙集和概念漂移的角度,揭示了概念漂移和粗糙集屬性約簡之間的區別與聯系.屬性約簡是在一個信息表內部保持不發生概念漂移的最小屬性子集.本文提出了基于屬性依賴度和條件熵的概念漂移探測準則,理論分析顯示粗糙集的屬性約簡準則大部分都可用于度量概念漂移,屬性依賴度和條件熵具有聯合概率分布可進行理論分析的優點,又具有分類準確率可進行實驗分析的優點,即將粗糙集的屬性約簡準則用于概念漂移的探測兼具兩種傳統的的概念漂移準則的優點.此外,屬性依賴度和條件熵作為概念漂移探測準則還具有對稱性和可重用性,從而可以減少工作量.所以,F-粗糙集是研究數據流分類和概念漂移,進行數據流分析的非常好的理論和實踐工具.將F-粗糙集和粗糙集屬性約簡準則用于數據流挖掘及概念漂移探測,豐富了數據流挖掘和概念漂移探測的工具,同時,對粗糙集及粒計算理論的發展與應用將起促進作用. 下一步研究重點是將F-粗糙集進一步運用于概念漂移探測和數據流分類,特別是集成分類器的分類研究,并深入研究這些概念漂移準則之間的關系.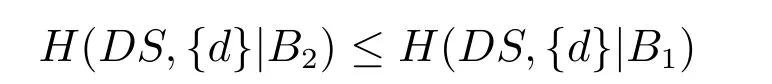
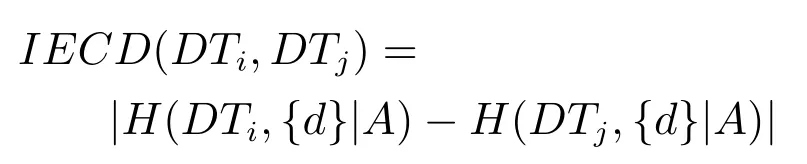
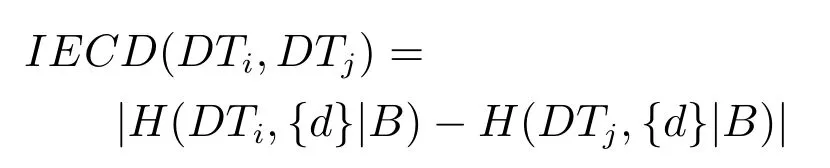
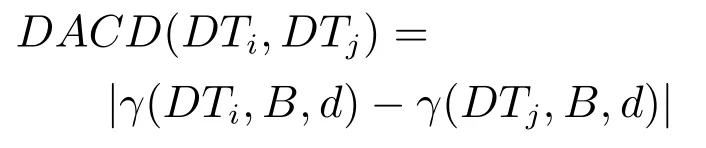
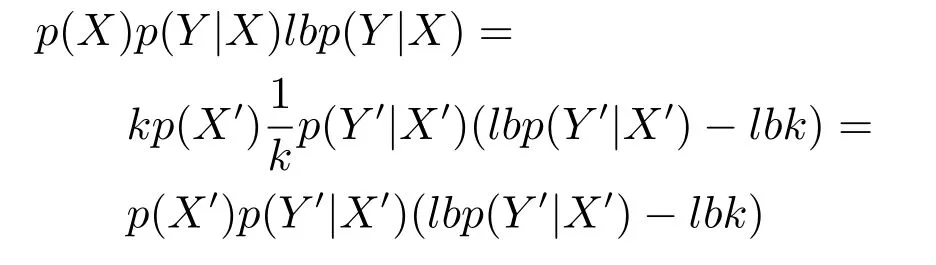
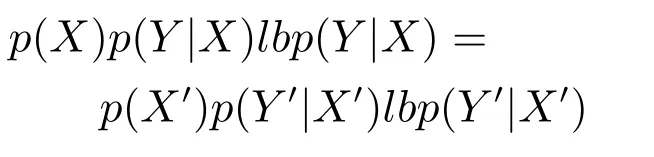
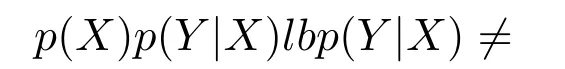
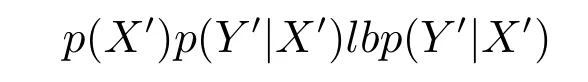
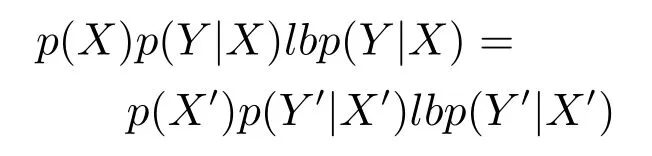
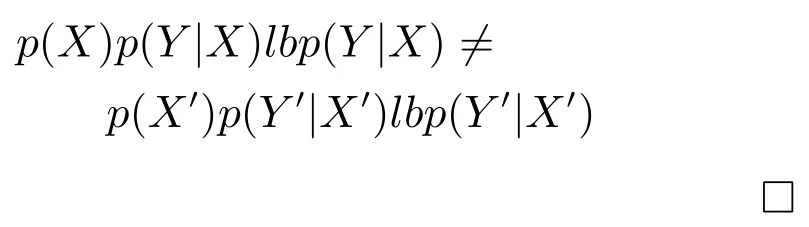
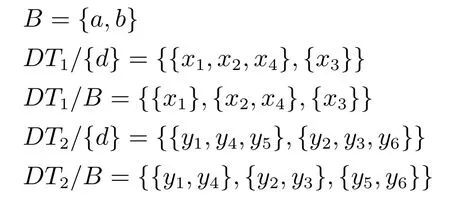
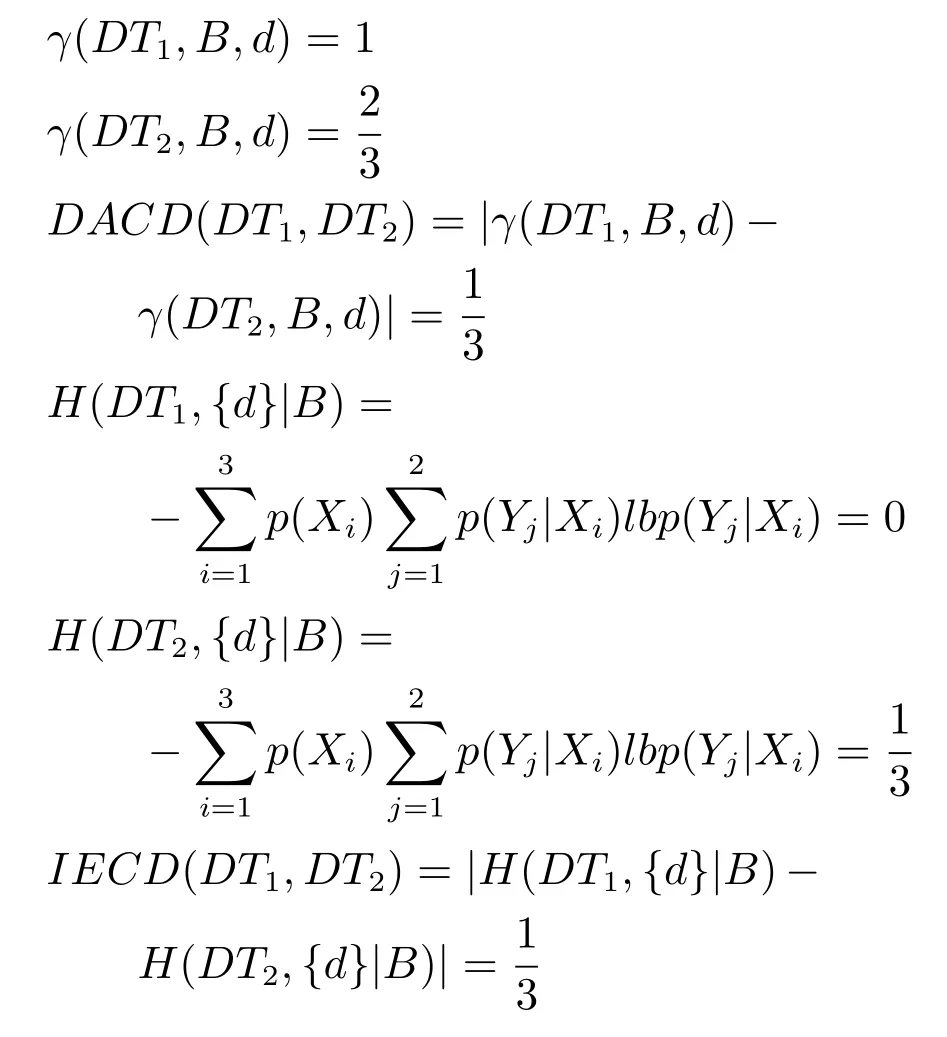
4 實驗結果與分析
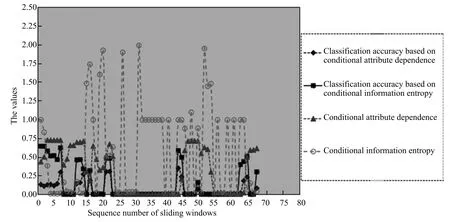
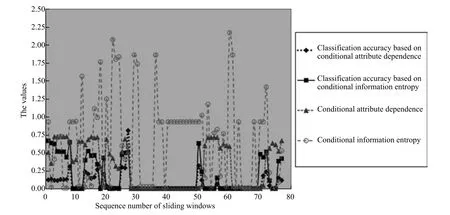
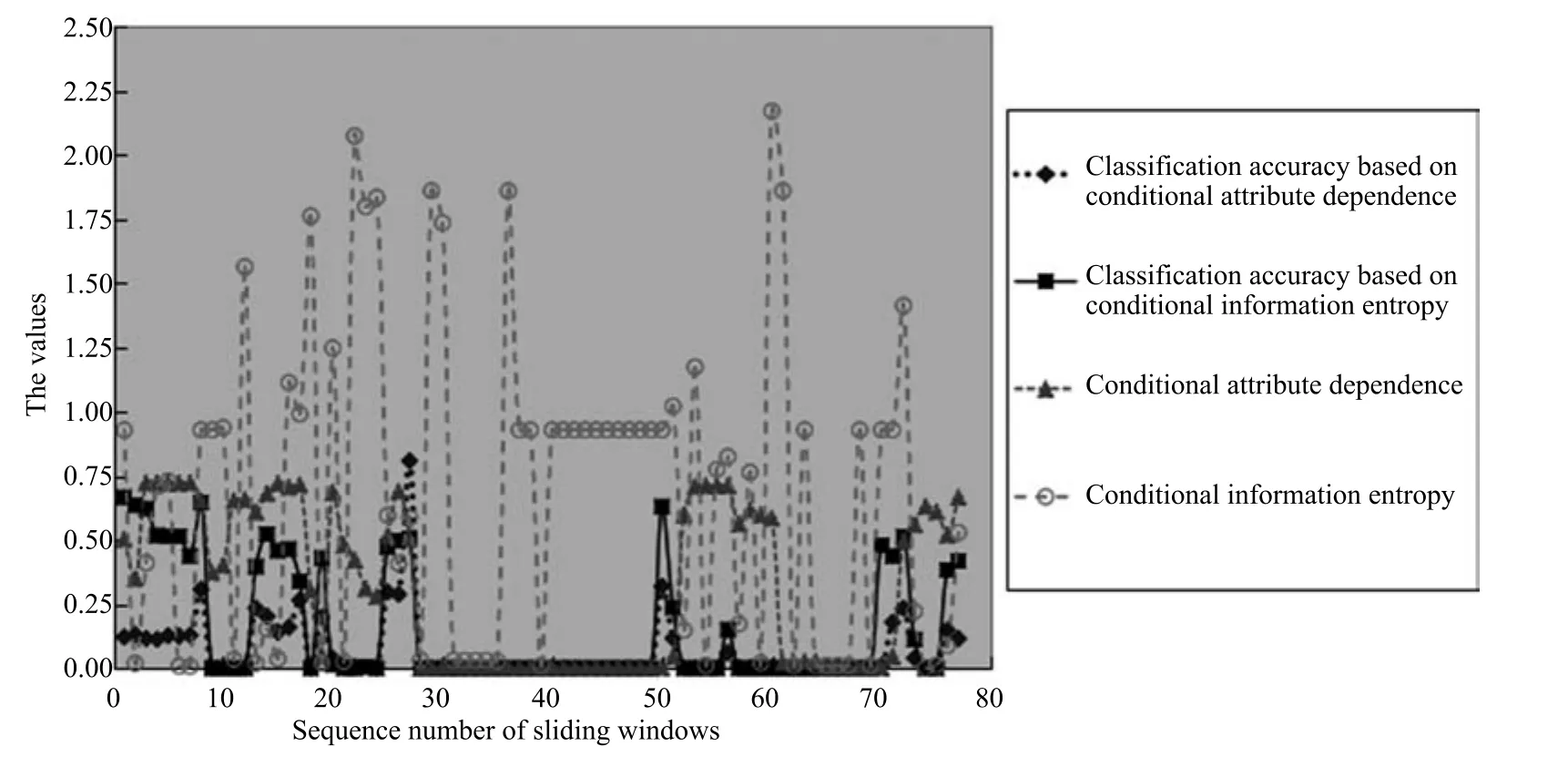
5 結論與展望
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
