Fisher準則下面向判別性特征的字典學習方法及其組織病理圖像分類研究
2018-11-01 08:01:50湯紅忠李驍張小剛張東波王翔毛麗珍
自動化學報 2018年10期
湯紅忠 李驍 張小剛 張東波 王翔 毛麗珍
組織病理圖像包含大量復雜的病理信息,具有豐富的空間幾何結構,細胞類型多樣且形態各異.目前,組織病理圖像的分析,主要依賴具有臨床經驗的病理學家尋找圖像中的病理特征.隨著遠程治療與精準治療的提出,組織病理圖像數量呈指數級增長,極大地增加了工作量.近幾年來,機器學習與計算機輔助診斷技術(Computer aided diagnosis,CAD)得到了迅速的發展,自動提取組織病理圖像中的判別性特征,輔助疾病診斷,已成為研究熱點,并迅速引起國內外學者的關注[1?3].
病理圖像的特征提取與分類是組織病理圖像CAD系統的關鍵環節,對疾病診斷有著極其重要的作用.為此諸多學者提出了很多解決辦法,主要分為兩大類.1)基于像素級特征的分類.如細胞的大小與形態特征[1,4]、圖像的灰度或彩色信息[5]、紋理特征[5?9]等.Tabesh等[5]提取了前列腺癌病理圖像的顏色、紋理和形態學特征,并基于監督學習框架進行特征組合,然后對比了K-NN、支持向量機(Support vector machine,SVM)等分類方法的性能.Doyle等[6]嘗試采用紋理和細胞核結構特征構造特征集,并采用SVM 實現了乳腺癌患病等級的鑒定.Li等[7]結合隨機投影、局部二值模式(Local binary patterns,LBP)與獨立子空間分析,提取了直腸息肉的三維紋理特征來鑒定疾病等級.Linder等[8]提取了腫瘤上皮與基質組織的LBP、LBP/C特征,并采用SVM 進行分類.2)基于空間結構與多尺度特征的分類.如尺度不變特征(Scale invariant feature,SIFT)[10]、小波特征[11]等;Irshad等[10]比較了紋理特征、SIFT特征、多級最大化模型(Hierarchical MAX,HMAX)特征對組織病理圖像分類性能的影響.Ergin等[11]提取了方向梯度直方圖(Histogram of oriented gradients,HOG)、稠密尺度不變特征(Dense scale invariant feature,DSIFT)與局部結構特征,并應用于乳腺癌組織病理圖像的分類.上述方法提取的均為手工特征,特征冗余度高,且較適合特定圖像集的分類問題,應用范圍受到一定的限制.
近年來,Wright等[12]提出了基于稀疏表示的分類方法,并在組織病理圖像[13?22]、語音信號[23]、SAR圖像[24]、人臉圖像[25?27]和圖像超分辨算法[28]等領域得到了廣泛應用.Srinivas等[13?14]提出一種同步稀疏模型,將組織病理圖像中訓練樣本RGB三通道值作為字典,并利用測試樣本的稀疏重構誤差進行分類.Nayak等[15]提出了一種帶稀疏約束的受限玻爾茲曼機(Restricted Boltzmann machine,RBM)模型,實現腫瘤組織病理圖像的特征提取及分類.Chang等[16?17]提出一種基于堆疊預測稀疏分解的字典學習方法,利用空間金字塔匹配(Spatial pyramid matching,SPM)方法對稀疏表示系數進行編碼,并采用SVM實現了腫瘤的病理狀態分類.Shi等[18]提出了一種基于聯合稀疏編碼的空間金字塔匹配方法,該方法利用RGB三個顏色通道信息,通過聯合稀疏編碼將灰度描述算子轉化為彩色描述算子,提高了組織病理圖像分類性能.Zhou等[19]提出一種面向組織病理圖像的多光譜特征學習模型,該模型基于卷積稀疏編碼自動學習一組卷積濾波算子,利用學習的濾波算子提取多通道的光譜特征,并采用SVM 進行分類.Shi等[20]基于多模式稀疏表示提出了一種肺部組織病理圖像的分類方法(Multimodal sparse representation-based classification,mSRC),該方法利用遺傳算法引導了顏色、形狀和紋理三個子字典的學習,然后結合稀疏重構誤差和多數投票算法對肺部組織病理圖像進行分類.Xu等[21]基于堆棧式稀疏自編碼器(Stacked sparse autoencoder,SSAE)進行乳腺癌組織病理圖像的特征提取,并利用Softmax實現了組織病理圖像中細胞核的檢測.Zhang等[22]基于圖方法實現了具有細胞核圖像的全局與局部特征的融合,然后結合排序與多數投票算法對乳腺癌組織病理圖像進行分類,并取得較好的效果.
上述方法引入圖像的稀疏性可以有效提取圖像特征,均屬于無監督方式,提取的特征具有較好的重構性,但并不一定具有較好的判別性.Zhang等[25]利用監督學習思想,提出了一種判別性KSVD(Discriminative K-SVD,DK-SVD)字典學習方法,該方法主要通過優化分類器參數來提升字典的判別性.Jiang等[26]提出了基于類標一致KSVD(Label consistent K-SVD,LC-KSVD)的字典學習方法,通過引入樣本類標信息,增加稀疏表示系數的判別性.Yang[27]提出一種Fisher判別字典學習(Fisher discrimination dictionary learning,FDDL)方法,該方法通過稀疏表示系數的Fisher準則約束來提高分類性能.上述文獻主要通過約束分類器參數或者稀疏表示系數來間接提升字典的判別性能.
最近,Vu等[29]提出了一種面向判別性特征的字典學習(Discriminative feature-oriented dictionary learning,DFDL)方法,并應用于組織病理圖像分類.DFDL方法引入了訓練樣本的類標信息,直接學習無病字典與有病的字典,并取得一定的分類性能.但是,組織病理圖像空間幾何結構豐富,細胞類型多樣,同類圖像中細胞形態與幾何結構變化可能較大,非同類圖像中細胞卻存在一定的相似性,導致類內圖像特征間的距離有可能大于類間圖像特征間的距離.因此,DFDL方法所學習的有病字典與無病字典相似程度較高,對無病樣本與有病樣本的判別性仍然較低,分類性能依然有待于提高.
本文基于Fisher準則,提出了一種新的面向判別性特征的字典學習方法(Discriminative featureoriented dictionary learning based on Fisher criterion,FCDFDL),并應用于組織病理圖像分類.
1 DFDL方法
Vu等[29]于2015年提出了一種面向判別性特征的字典學習方法(Discriminative featureoriented dictionary learning,DFDL),并應用于醫學組織病理圖像分類.其目標函數定義如下:
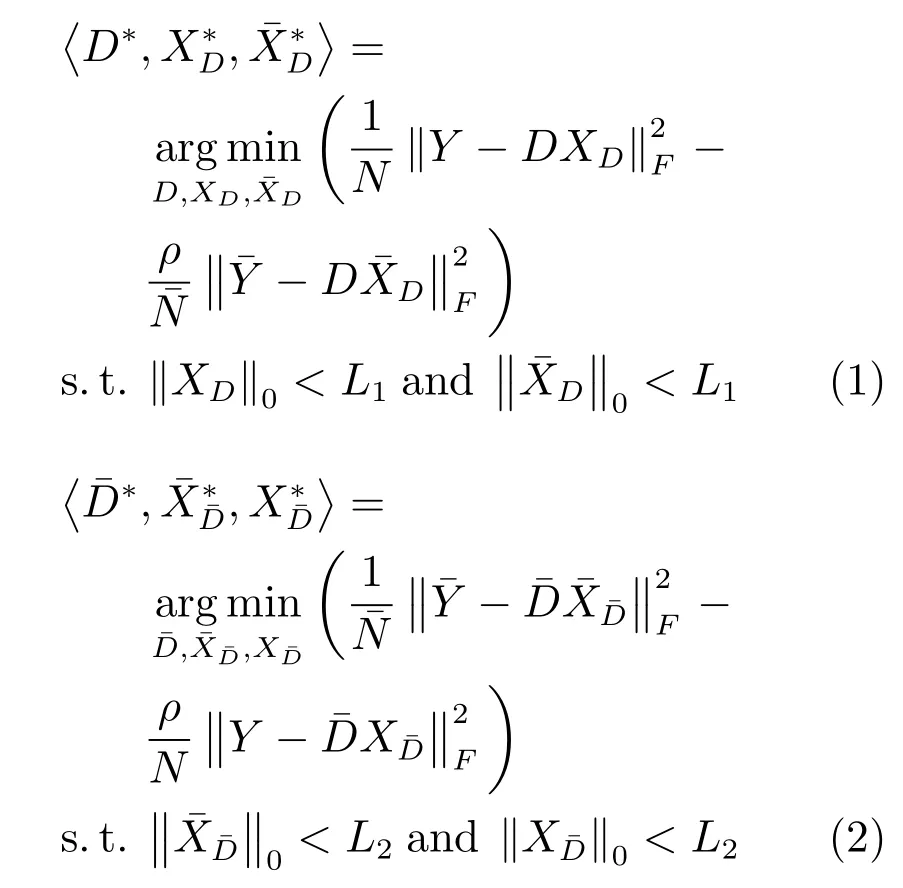
其中,Y和分別代表無病與有病的訓練樣本,D和分別代表無病與有病的字典,在本文中統稱字典.XD和分別代表無病與有病樣本在D下的稀疏表示系數,和分別代表無病與有病樣本在下的稀疏表示系數.N和分別代表Y和的樣本個數,L1,L2為稀疏度,ρ為正則化參數,且ρ>0.
式(1)和式(2)中,第1項都表示學習字典對同類樣本的稀疏重構誤差,第2項都表示學習字典對非同類樣本的稀疏重構誤差.通過最小化第1項并最大化第2項,可以直接學習無病字典與有病字典.DFDL方法在學習過程中沒有考慮無病字典D與有病字典之間的差異,導致所學習的D與之間相似程度高,對無病樣本與有病樣本的稀疏表示系數判別性仍然較低,影響了組織病理圖像的分類與疾病診斷性能.
2 FCDFDL方法
2.1 Fisher準則
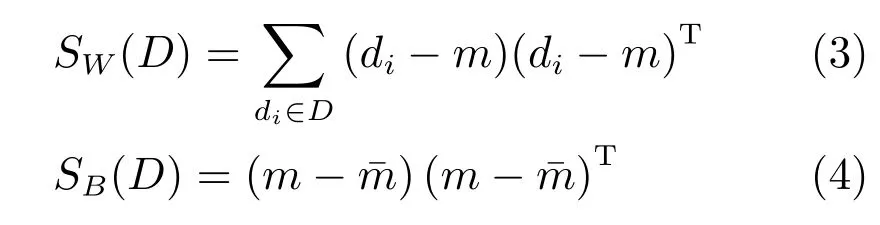
其中,di是無病字典D中第i個原子,m是無病字典D中所有原子的均值,是有病字典中所有原子的均值.在字典學習階段要保證無病字典D的類內距離更小,同時要保持與有病字典之間的距離更大,結合Fisher準則,本文構造的無病字典D懲罰項定義如下:
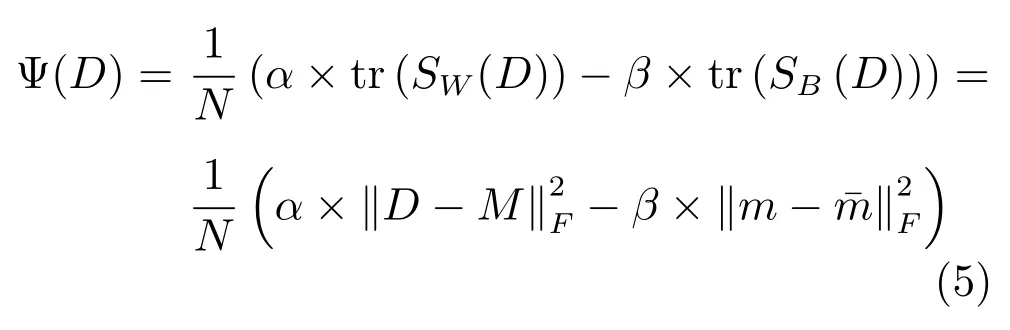
其中,矩陣M中列向量均為m,tr表示矩陣的跡.
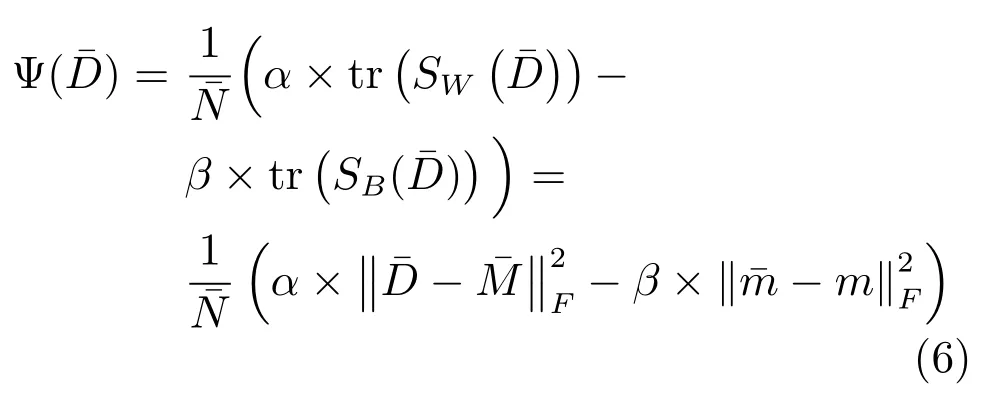
2.2 FCDFDL模型構建及其優化求解
針對DFDL方法的不足,本文結合Fisher準則,提出一種FCDFDL方法,該方法最小化學習字典的類內距離的同時最大化學習字典的類間距離,以提升無病字典與有病字典之間的差異.其模型定義如下:
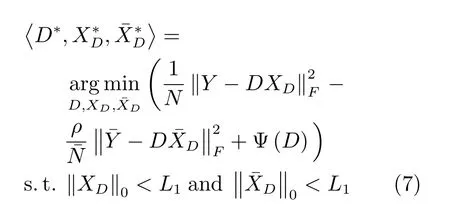
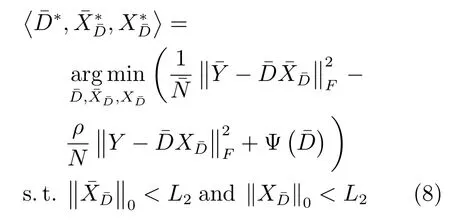
式(7)和式(8)目標函數中的第1項、第2項與DFDL方法保持一致.不同之處在于第3項,即基于Fisher準則構造了學習字典的懲罰項;與FDDL方法不同,本文利用Fisher準則直接約束了學習字典的類內距離與類間距離,而不是約束稀疏表示系數.通過交替優化式(7)和式(8),可以獲得以下性能:
1)無病字典中原子分布更加緊湊,對無病樣本具有更好的稀疏表示性能,同時抑制了對有病樣本的稀疏表示性能.
2)有病字典中原子分布更加緊湊,對有病樣本具有較好的稀疏表示性能,同時抑制了對無病樣本的稀疏表示性能.
3)最大化無病字典與有病字典之間的距離,大大降低了無病字典與有病字典間的相似性,增強了學習字典對同類樣本的重構性與對非同類樣本的判別性.
式(7)和式(8)都是非凸優化問題,其求解一般通過反復執行稀疏編碼與字典更新兩個步驟直至收斂.FCDFDL模型求解步驟如下:
步驟1.稀疏編碼
步驟1.1.固定無病字典D,計算訓練樣本在無病字典D下的稀疏表示系數,式(7)可重新定義為
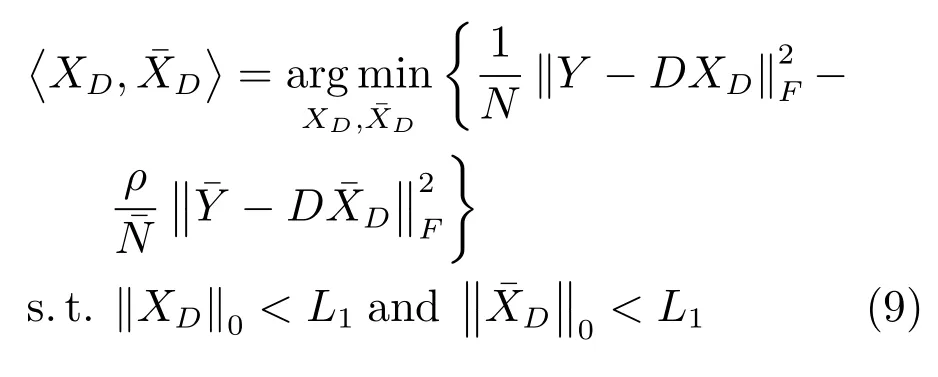
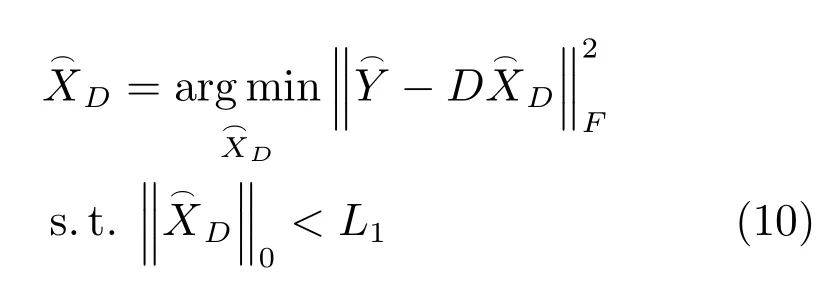
步驟1.2.固定有病字典,計算訓練樣本在有病字典下的稀疏表示系數,式(8)可重新定義為
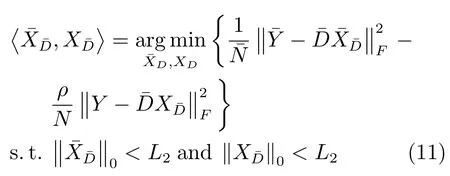
本文利用SPAMS工具箱1http://spams-devel.gforge.inria.fr/中的OMP[30]算法求解式(10).
步驟2.字典更新
步驟2.1.固定無病字典D下的稀疏編碼系數,更新無病字典D,式(7)重新定義為
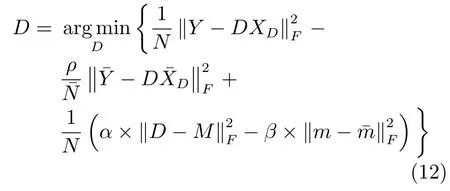
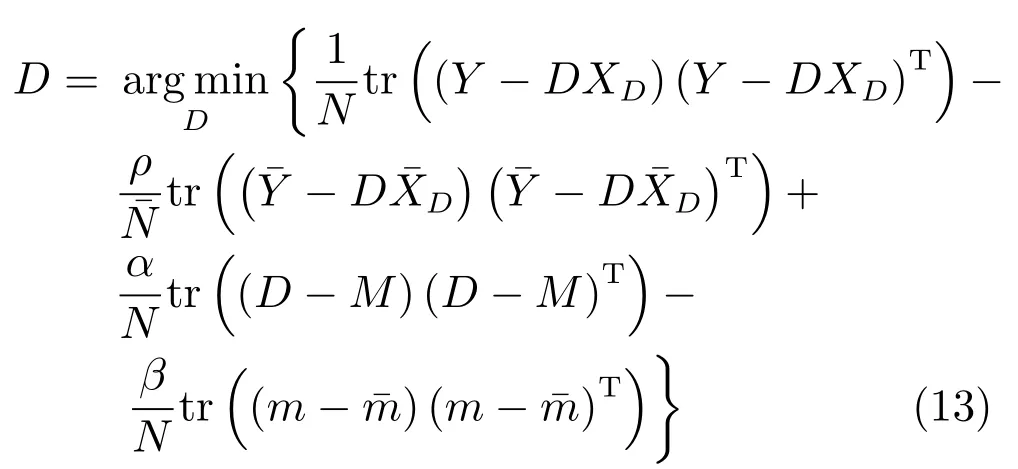
同時,忽略式(13)中的常數項,式(13)可化簡為
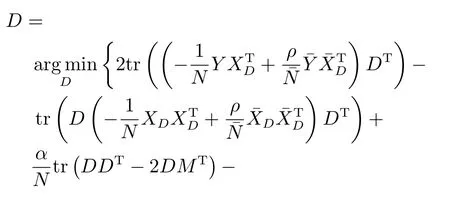
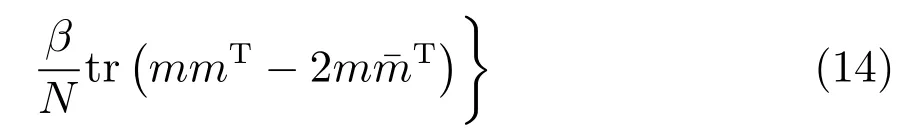
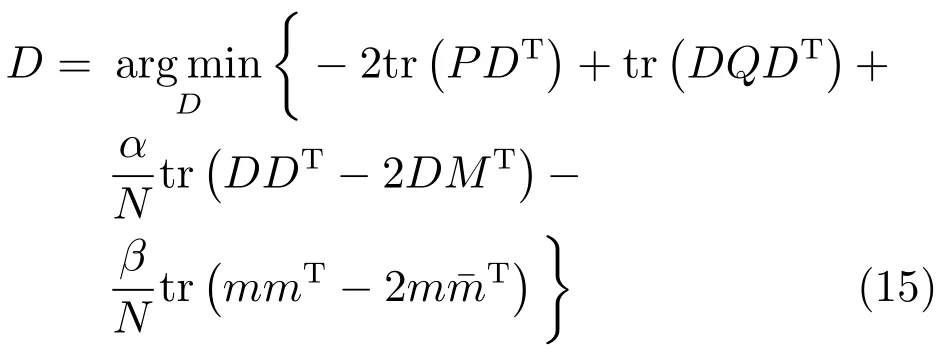
步驟2.2.固定有病字典下訓練樣本的稀疏編碼,更新有病字典,令,則式(8)可簡化為
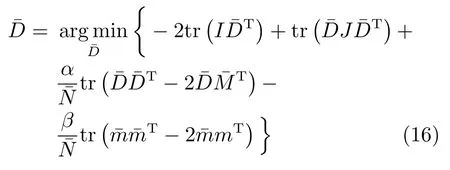
式(15)和式(16)均為凸函數,本文采用坐標梯度下降法可求出學習字典的最優解.
2.3 組織病理圖像的分類器構造
基于第2.2節,利用所學習的字典對測試樣本進行稀疏表示,可分別求出測試樣本在無病字典D?與有病字典下的稀疏重構誤差,構造分類統計量實現組織病理圖像的分類,具體分類步驟如下:
步驟1.將測試圖像分塊,將每個圖塊展開為一個列向量,隨機選取多個圖塊組成測試樣本H,利用
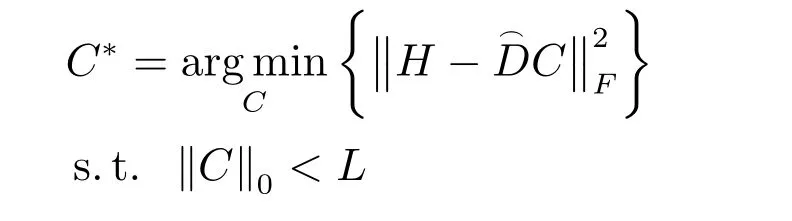
采用OMP方法求出H在下的稀疏編碼系數;
步驟2.計算測試樣本在D?與下的重構誤差向量,即
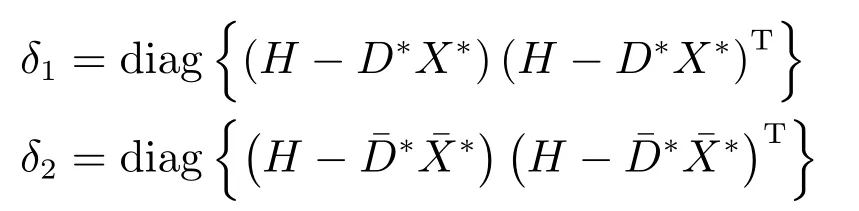
其中,diag{·}表示矩陣主對角線上的元素;
步驟3.定義分類向量
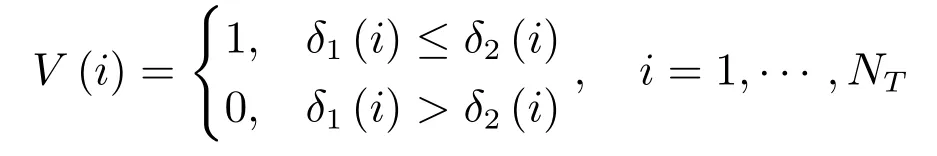
其中,NT為測試樣本的個數;
步驟4.基于分類向量V,計算分類統計量S=.
當分類統計量S大于閾值Th,測試樣本為無病樣本;反之,測試樣本則為有病樣本.
2.4 本文方法的具體操作步驟
步驟1.輸入無病訓練樣本Y與有病訓練樣本的,并分別從Y與中隨機提取K個列向量初始化D與,初始化無病與有病的樣本個數N與,稀疏度L1與L2,迭代次數,懲罰因子ρ,α,β;
步驟2.固定無病字典D,利用式(10)求在D下的稀疏編碼系數;
步驟3.固定有病字典,利用式(10)求在的稀疏編碼系數;
步驟4.固定無病字典D的稀疏編碼,求P,Q,優化式(15)更新無病字典D;
步驟5.固定有病字典的稀疏編碼,求I,J,優化式(16)更新有病字典;
步驟6.判斷迭代是否完成,若沒有完成迭代次數,加1轉至步驟2;反之,迭代完成,輸出學習的字典;
步驟7.基于學習字典,計算測試樣本在D?與下的稀疏重構誤差,結合第2.3節構造分類統計量S而進行分類.
3 實驗結果及分析
本文分別在ADL[31]與BreaKHis[32]數據集上驗證了FCDFDL方法的有效性,并與其他方法進行對比分析.
3.1 ADL數據集的實驗結果
1)ADL數據集及實驗設置
ADL數據集賓夕法尼亞州立大學提供,包括肺、脾臟、腎臟三類器官,共計900多張圖像.每類器官包括無病和有病兩類樣本,各150多張,尺寸為1360像素×1024像素.為了提高算法的計算效率,本文將所有圖像歸一化為600像素×600像素.如圖1所示,圖1(a)從左至右依次表示肺、脾臟、腎臟的無病圖像,圖1(b)從左至右依次表示肺、脾臟、腎臟的有病圖像.
針對肺、脾臟、腎臟的彩色圖像,在相應的無病與有病樣本中分別隨機選取40張圖像作為訓練集,剩余的110張圖像作為測試集.然后,從每張訓練圖像中隨機提取250個圖塊,則每類器官中無病與有病樣本分別有10000個圖塊,并將每個圖塊的RGB三個通道值串成列向量作為訓練樣本Y,.其中,肺與脾臟圖塊尺寸為20像素×20像素,腎臟圖塊尺寸為30像素×30像素.以肺部圖像為例,Y,∈R1200×10000,字典D,∈R1200×100,最大迭代次數為50.基于第2.4節的步驟,分別對肺、脾臟、腎臟圖像進行分類.其中,肺部相關實驗參數設置為ρ=0.001,α=1E?3,β=1E?3,脾臟相關實驗參數設置為ρ=0.001,α=1E?2,β=0.1,腎臟相關實驗參數設置為ρ=0.001,α=1E?2,β=1E?4(實驗參數分析見第3.4節).
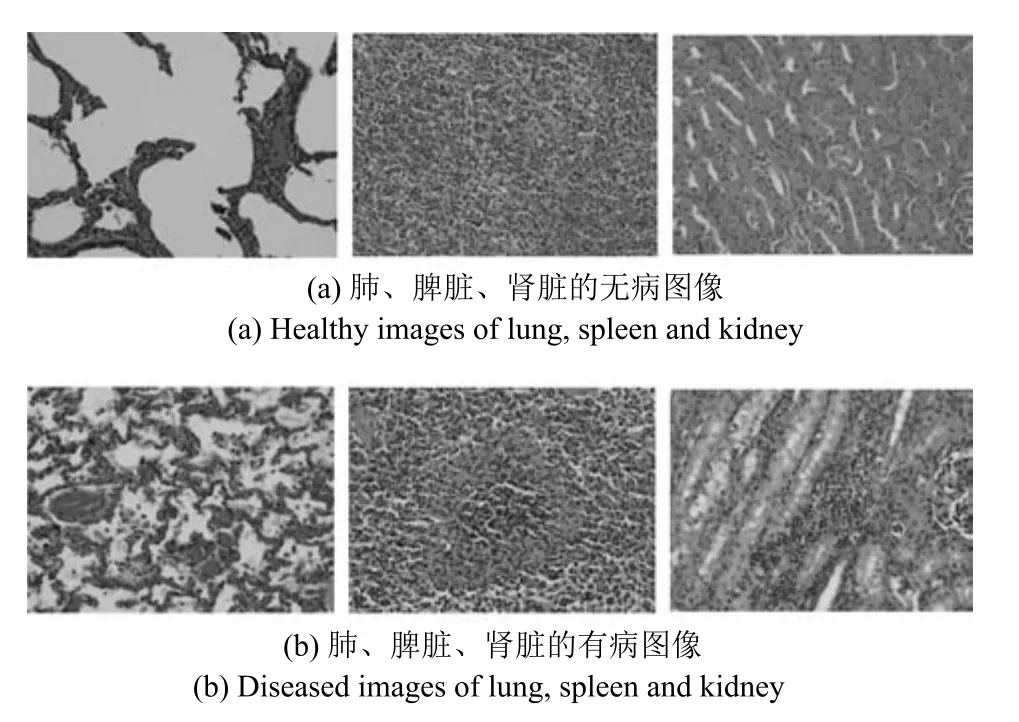
圖1 肺、脾臟、腎臟的組織病理圖像Fig.1 Lung,spleen and kidney images
2)FCDFDL與其他方法的實驗對比
應用本文FCDFDL方法,在不同組織圖像上,與WND-CHARM[33],SRC[12],SHIRC[13],LCKSVD[26],FDDL[27]和DFDL[29]進行分類性能對比.其中,WND-CHARM結合了對比度、像素及紋理等特征,并采用SVM分類;SRC和SHIRC方法中的字典并沒有經過學習,采用稀疏重構誤差進行分類.表1~3分別給出了肺、脾臟、腎臟的分類結果.表中結果是采用不同樣本分別進行10次實驗所取的平均值.
在表1~3中,第2行給出了不同方法下無病樣本的正分率與錯分率,第3行給出了不同方法下有病樣本的錯分率與正分率.可以看出,本文FCDFDL方法在肺、脾臟、腎臟的無病樣本與有病樣本中正分率都有所提高,錯分率有所下降,具有更好的疾病診斷性能.特別對肺部圖像的分類結果提升尤為明顯(表1),與DFDL相比,本文方法的分類精度提升了2%~3%.表明本文學習的字典對同類樣本具有更好的重構性,對非同類樣本具有更好的判別性.
3.2 BreaKHis數據集的實驗結果
1)BreaKHis數據集及相關實驗設置
為進一步驗證FCDFDL方法的有效性,本文將其應用于BreaKHis數據集中疾病類型的診斷.該數據集包括不同放大倍數(40×,100×,200×,400×)下82名患者的良性乳腺癌圖像,包括腺病、纖維腺癌、葉狀癌和管狀腺癌四個類別,共計2368張.40×放大倍數下的腺病與葉狀癌兩種組織病理圖像共計223張,其中,腺病圖像為114張,葉狀癌圖像為109張.圖2(a)表示腺病的組織病理圖像,圖2(b)表示葉狀癌的組織病理圖像.
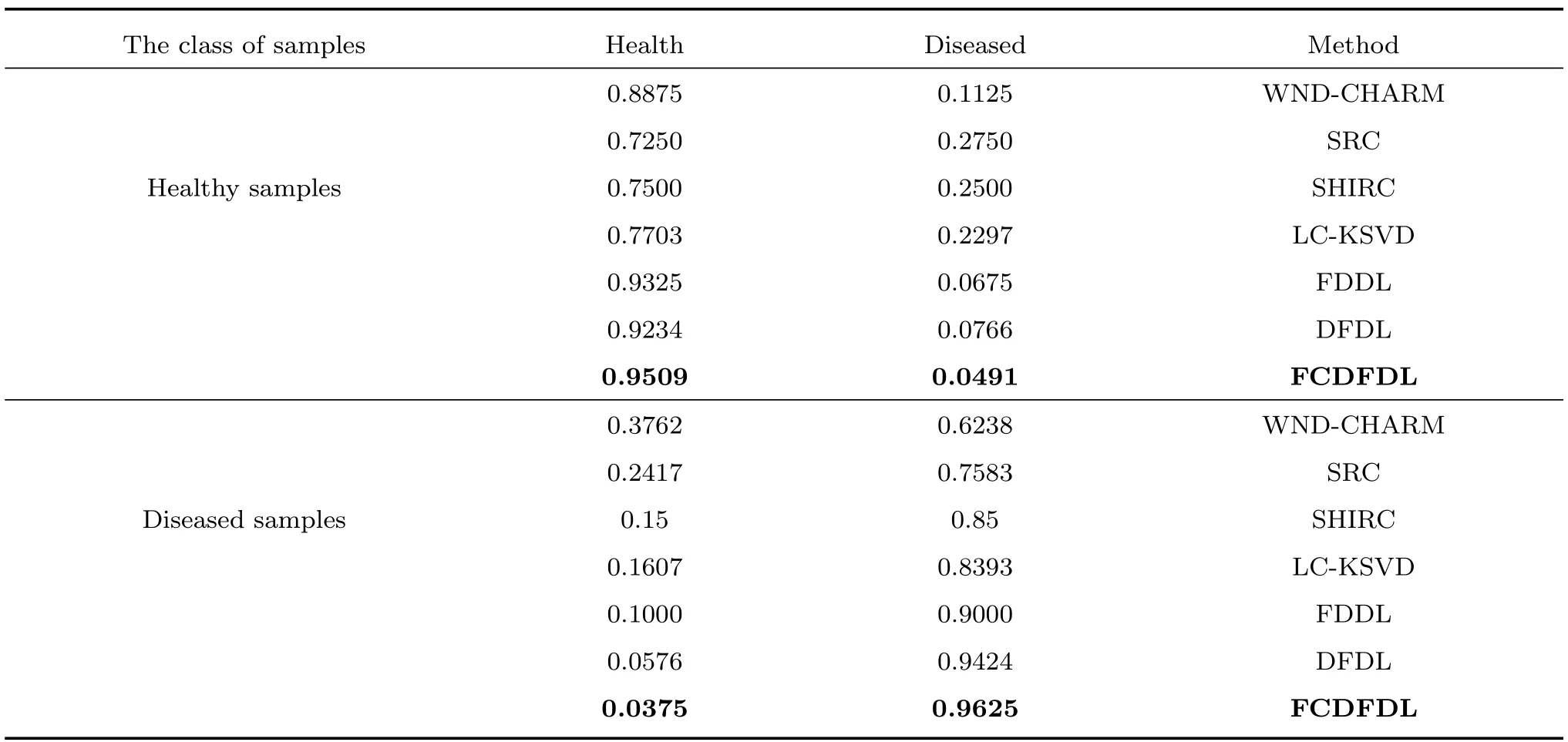
表1 不同方法在肺部圖像的分類結果對比Table 1 Classification results comparison of different methods on lung images
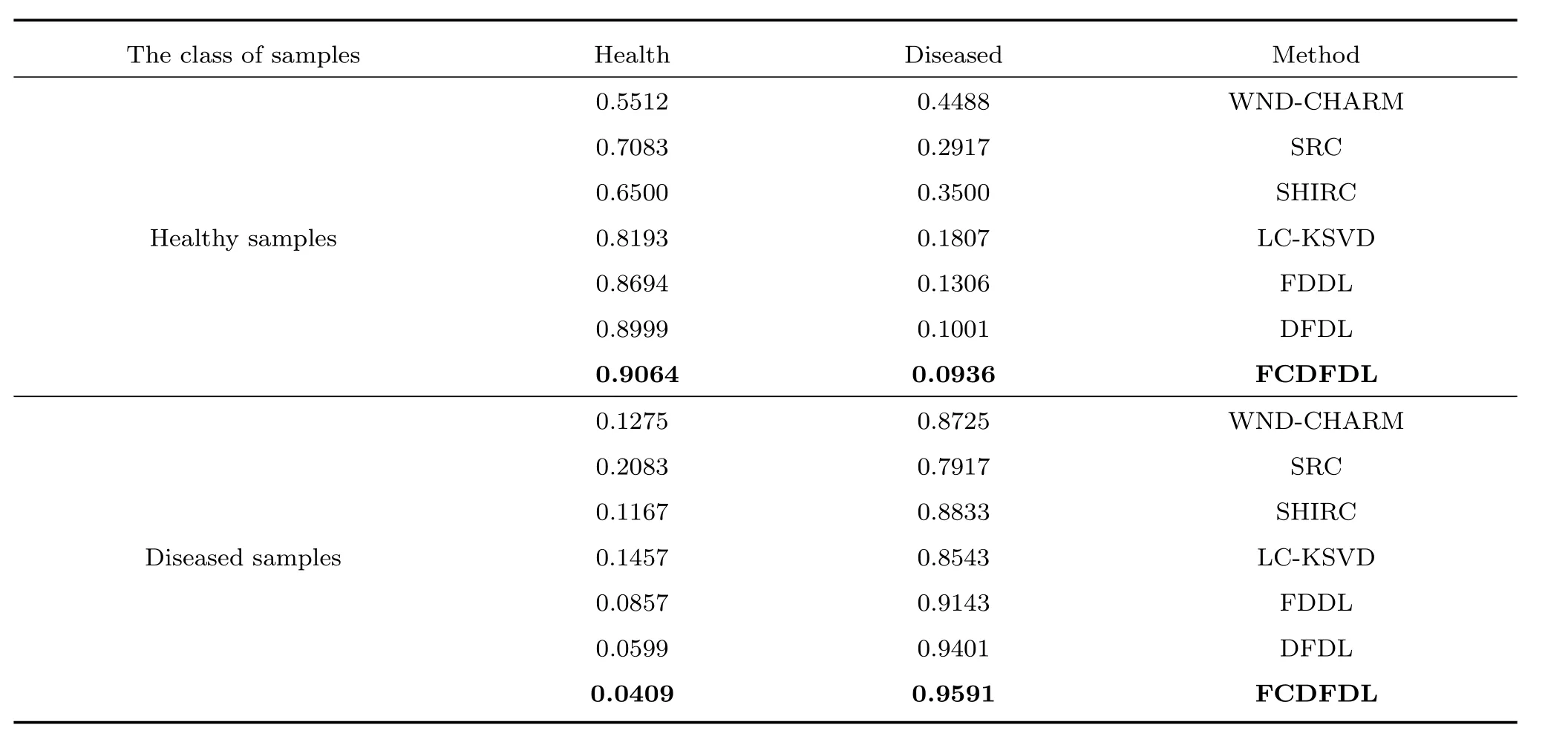
表2 不同方法在脾臟圖像的分類結果對比Table 2 Classification results comparison of different methods on spleen images
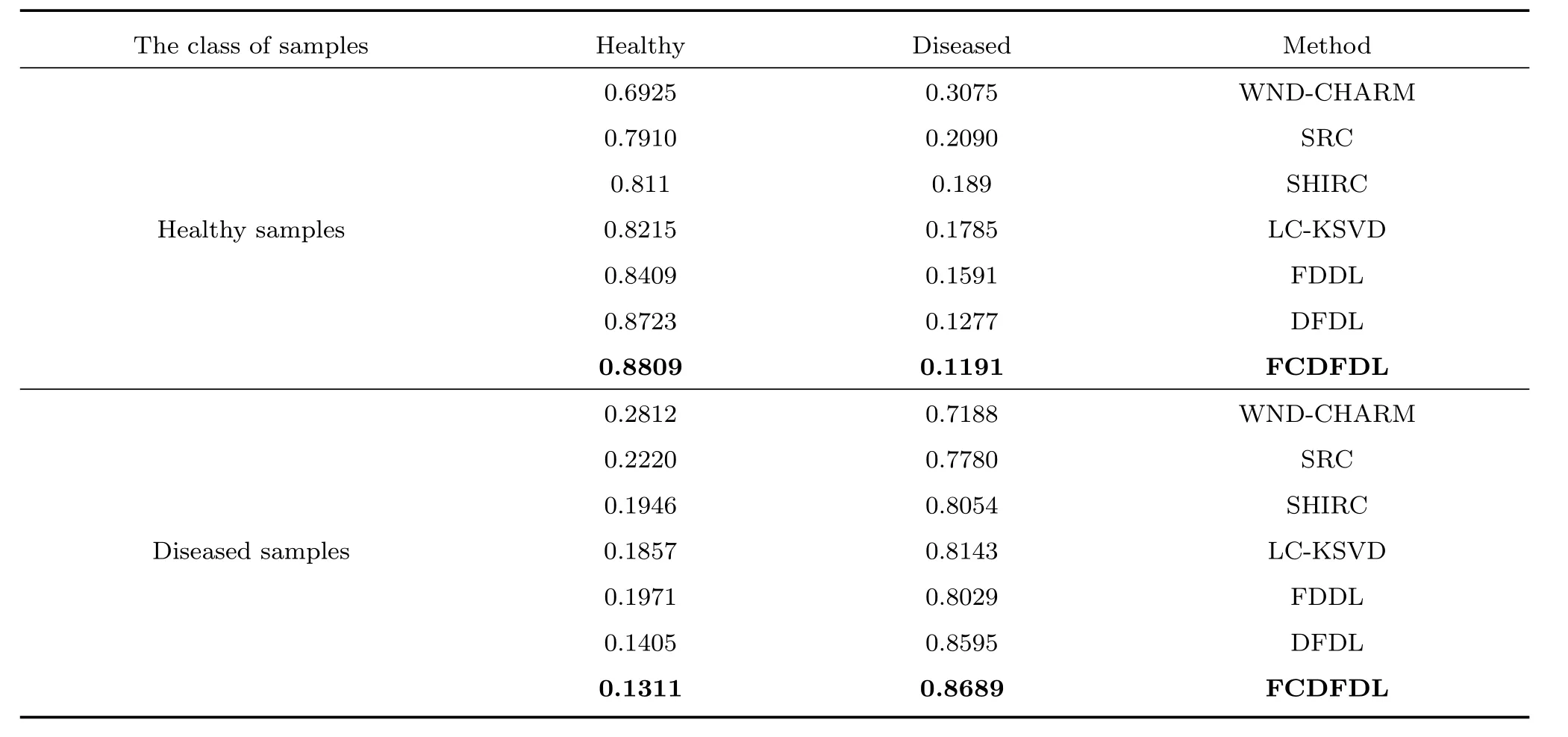
表3 不同方法在腎臟圖像的分類結果對比Table 3 Classification results comparison of different methods on kidney images
本文選取40×放大倍數下的腺病與葉狀癌兩種組織病理圖像作為訓練樣本(這兩種病理圖像相似度較高),并將所有圖像歸一化為600像素×600像素.在腺病和葉狀癌的彩色圖像中各隨機選取40張,每張圖像提取250個圖塊,塊的尺寸為20像素×20像素,則腺病與葉狀癌樣本分別為10000個圖塊.將每個圖塊的RGB三通道串成列向量作為訓練樣本,則Y,∈R1200×10000,字典D,∈R1200×100,最大迭代次數為50.采用本文第2.4節的步驟,分別學習了腺病字典與葉狀癌字典,并利用測試樣本在腺病字典與葉狀癌字典上的稀疏重構誤差進行分類.實驗參數設置為:ρ=0.001,α=1E?3,β=1E?3.
2)FCDFDL與其他方法的實驗對比
表4給出了FCDFDL與其他方法在BreaKHis數據集上的分類結果.
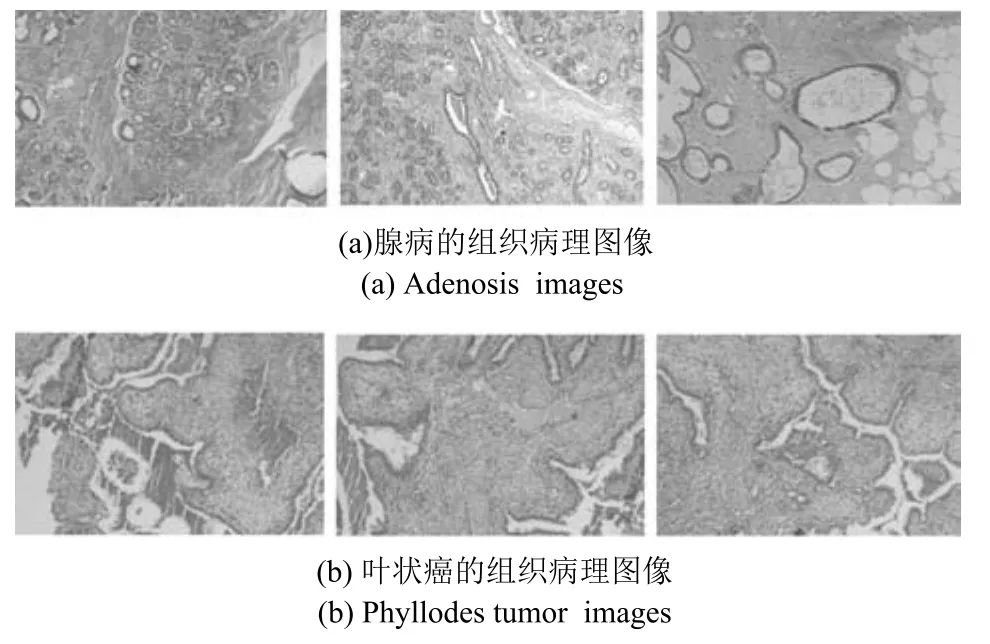
圖2 腺病與葉狀癌的組織病理圖像Fig.2 The images of adenosis and phyllodes tumor
可以看出,與 WND-CHARM[33],SRC[12],SHIRC[13],LC-KSVD[26],FDDL[27],DFDL[29]方法相比,由于本文FCDFDL方法學習了判別性強的腺病字典與葉狀癌字典,更能有效提取圖像的分類特征,取得較好的分類效果.
3.3 學習字典的類間差異
為了進一步探究不同字典學習方法下所獲得D與的類間差異,將FCDFDL方法與LC-KSVD,FDDL和DFDL進行主觀與客觀的比較.圖3為不同方法基于不同組織圖像的訓練樣本所學習的字典示意圖.圖3結果顯示,與其他三種方法相比,本文方法學習的兩類字典之間差異明顯,相似程度大大降低.表明結合Fisher準則直接約束學習字典的類內距離與類間距離,通過優化目標函數式(7)與式(8),可以最小化學習字典的類內距離與最大化學習字典的類間距離.LC-KSVD,FDDL與DFDL方法學習的D與較為相似,主要原因在于LCKSVD與FDDL方法僅僅約束稀疏表示系數的判別性,而DFDL方法在優化過程中并沒有考慮學習字典之間的差異.因此,這三種方法得到的學習字典之間相似度高,判別性弱.對比分析表明,本文FCDFDL方法學習的字典包含的細胞結構與紋理更豐富,顏色信息更全面,稀疏表示能力更強,具有更好判別性特征提取能力.
為客觀衡量本文方法與LC-KSVD、FDDL和DFDL所學習的字典的類間差異,采用學習后的字典D與的距離作為評價指標(即),實驗結果如圖4所示.圖4中橫坐標表示不同的組織病理圖像,縱坐標表示學習字典的類間距離,其值越大,說明兩個字典之間的差異越明顯.由此可知,與其他三種方法相比,本文方法學習字典的類間差異更為明顯.因此,基于Fisher準則構造學習字典的懲罰項,可以大大降低學習字典之間的相似性,提高學習字典對非同類樣本的判別能力.
3.4 實驗參數分析
1)參數ρ,α,β的設置
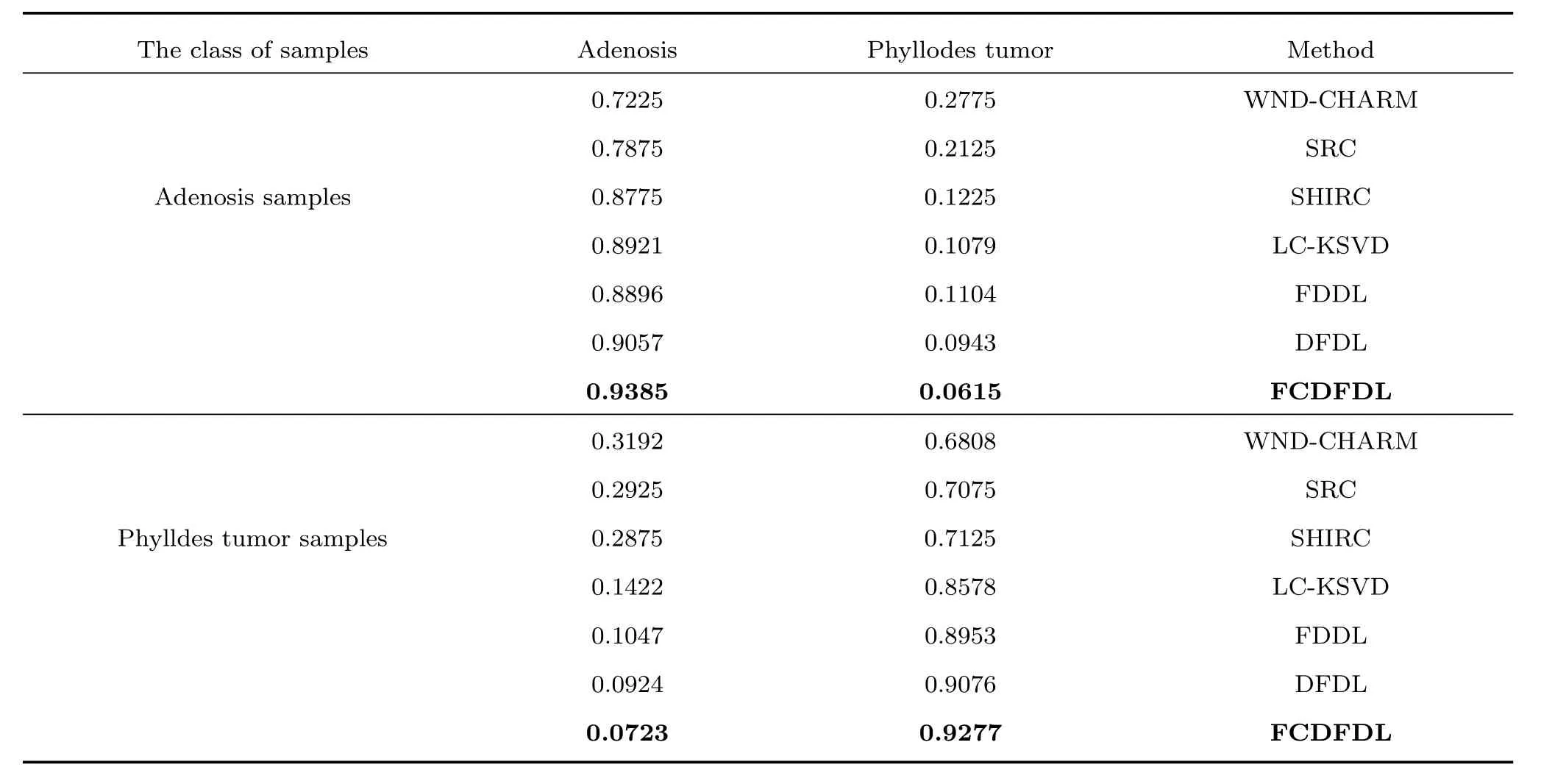
表4 不同方法在BreaKHis數據庫上的分類結果對比Table 4 Classification results comparison of different methods on BreaKHis dataset
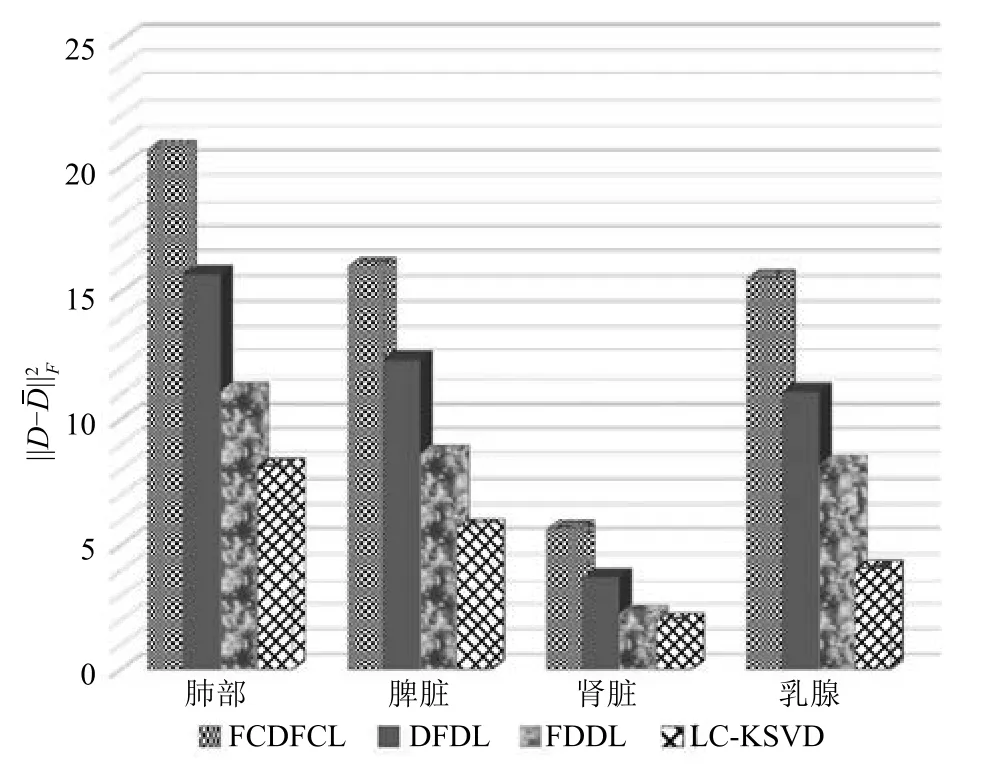
圖4 學習字典的類間差異Fig.4Inter-class differences between learnedDand
與DFDL方法相同,本文中參數ρ平衡了學習字典對類內樣本與類間樣本的重構誤差,因此參數ρ的設定參考了DFDL方法給出的經驗值ρ=0.001.不同之處在于FCDFDL方法增加了Fisher準則約束項懲罰因子α和β.圖5給出了隨參數α,β變化時,本文方法在不同組織病理圖像的分類精度.從圖5可以看出,肺部圖像在α=1E?3,β=1E?3時分類性能達到最優;脾臟圖像在α=1E?2,β=1E?4時分類性能達到最優;腎臟圖像在α=1E?3,β=1E?3時分類性能達到最優;乳腺圖像在α=1E?3,β=1E?3時分類性能達到最優.
2)圖塊尺寸的設置
隨著圖塊尺寸變化,圖6給出了本文方法在肺、脾臟、腎臟和乳腺的分類精度.由此可知,肺部、脾臟和乳腺圖塊尺寸取值為20像素×20像素時,腎臟圖塊尺寸取值為30像素×30像素時,本文方法的分類性能達到最優.因此,利用合適尺寸的圖塊作為訓練樣本,能更有效提取圖像特征,取得較佳的分類效果.
4 總結
針對面向組織病理圖像特征提取的字典學習方法存在學習的無病字典與有病字典相似程度高、判別性弱的問題,本文提出一種新的面向判別性特征的字典學習方法(FCDFDL).利用Fisher準則直接約束無病字典與有病字典的類內距離與類間距離,構建了字典學習函數的懲罰項,得到了判別性更強的無病字典與有病字典;同時,可最小化學習字典對同類樣本的重構誤差,并最大化學習字典對非同類樣本的重構誤差,獲得了較好稀疏表示性能.最后,基于學習字典對測試樣本的稀疏重構誤差構建了分類器,實現了組織病理圖像的二分類.在ADL數據集與BreaKHis數據集上的實驗結果表明,本文方法能有效提取組織病理圖像內在的分類特征,與同類其他算法相比,具有更好的分類性能.
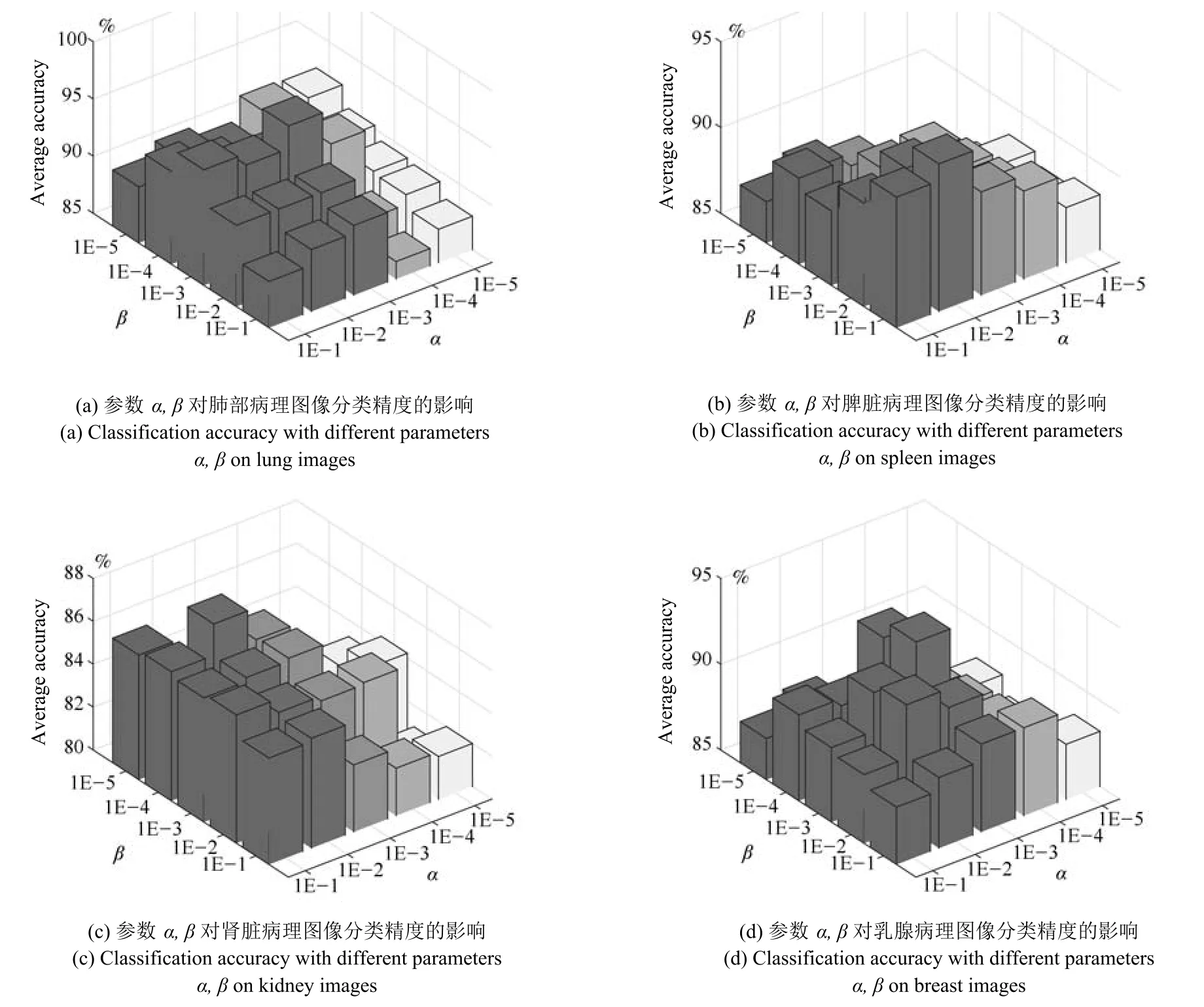
圖5 參數α,β的變化對不同病理圖像分類精度的影響Fig.5 Classification accuracy with different parametersα,β on different pathological images
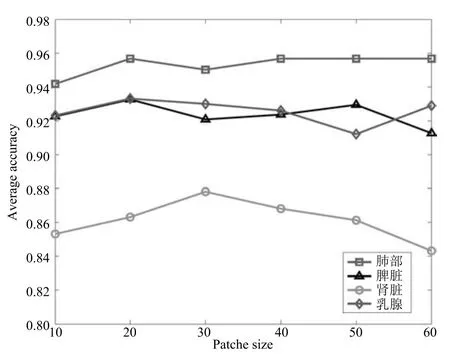
圖6 FCDFDL方法下圖塊尺寸的變化對不同病理圖像分類精度的影響Fig.6 Classification accuracy on different pathological images with different image block size,and with FCDFDL method
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
