基于概率模型的非均勻數據聚類算法
2018-11-22 09:37:54楊天鵬陳黎飛
計算機應用 2018年10期
楊天鵬,陳黎飛,2
(1.福建師范大學 數學與信息學院,福州 350117; 2.福建師范大學 數字福建環境監測物聯網實驗室,福州 350117)(*通信作者電子郵箱clfei@fjnu.edu.cn)
0 引言
聚類分析作為數據挖掘的一種重要方法,目的是將給定數據劃分成多個子集(每個子集為一個簇),使得簇內對象彼此相似,與其他簇對象不相似[1]。傳統的聚類算法可分為層次聚類、基于劃分聚類、基于密度和網格聚類,以及其他聚類算法[2-3]。目前聚類分析已廣泛應用在Web搜索、圖像處理、模式識別、醫療數據分析等眾多領域。
作為數據挖掘十大算法之一,K-means算法[4]因其簡單高效的優點得到廣泛的研究和應用[5]。然而,受“均勻效應(uniform effect)”的影響[6],K-means型算法在聚類醫療診斷等復雜數據時性能受限。這類數據的一個特點是同一數據集同時包含了樣本數量和樣本密度有較大差異的簇,這種數據稱為非均勻數據(non-uniform data)。與不平衡數據(主要指簇樣本量即簇大小差異較大的數據)聚類[7]相比,非均勻數據聚類問題更具普遍性。例如,在含有“正常”和“患病”兩個簇的疾病診斷數據中,兩簇的大小差異明顯(通常,“正常”簇比“患病”簇的樣本數量大得多),更重要地,“患病”簇的樣本皆具特定的疾病模式,其密度比“正常”簇有顯著區別(表現為“正常”簇樣本分布的方差大得多)。
針對該問題研究者提出了多種方法[8-12],可大致分為三類:第一類方法基于樣本抽樣,在聚類之前首先對樣本集作欠采樣或過采樣的處理操作,文獻[8-9]即是在這樣預處理后的數據上進行K-means聚類的;第二類方法在聚類模型中考慮不同簇的樣本量差異,例如,文獻[10]引入簇的樣本數量,給出了經典模糊聚類算法目標優化函數的兩種改進方案;第三類方法則側重簇的密度差異,借助多代表點等方法[11]以區分數據集中的不同密度區域。這些方法是分別針對簇樣本數量不平衡特性或密度差異特性而提出的,未提供同時處置非均勻數據上述兩個特性的解決方案。
從原理上說,K-means型聚類是一種基于模型的方法,它所學習的概率模型是以相關參數為常數這一假設前提下的一種簡化的高斯混合模型[13],此簡化模型并不能很好地刻畫非均勻數據簇類的兩個特點。為此,本文提出一種基于概率模型的非均勻數據聚類新算法——MCN(Model-based Clustering on Non-uniform data),以應對傳統K-means型算法的“均勻效應”問題。本文的主要工作包括兩個方面:其一,以高斯混合模型為基礎,建立了非均勻數據簇的概率模型,新模型可以描述同一數據集中樣本量和密度都存在差異的簇;其二,基于提出的模型推導了聚類目標函數,并給出優化目標函數的算法步驟,實現了非均勻數據的軟子空間聚類。在合成數據和實際數據上的實驗結果表明,與現有的非均勻數據聚類算法相比,本文MCN算法有效提高了聚類精度。
1 相關工作
首先給出文中使用的符號及定義。令待聚類數據集為DB,含N個D維樣本,任一樣本用x=〈x1,x2,…,xj,…,xD〉表示,其第j(j=1,2,…,D)維屬性為xj。考慮硬聚類算法,它將DB劃分成K個不相交的子集的集合C={c1,c2,…,ck,…,cK}, 并稱子集ck為DB的第k(k=1,2,…,K)個簇,|ck|表示該簇包含的樣本數量。用vk=〈vk1,vk2,…,vkD〉表示ck的簇中心,V={v1,v2,…,vK}為全體簇中心的集合。
經典的K-means算法是一種劃分型聚類算法,其優化目標定義為:
(1)
K-means通過類期望最大化(Expectation Maximization, EM)算法[15]的學習過程求取式(1)的局部優解,過程如下:給定簇數目K,首先選擇K個初始簇中心,然后計算每個樣本與各簇中心點的距離,將樣本劃分至距離最小的簇,再為每個新劃分生成的簇計算最優的簇中心;算法迭代執行上述“劃分-簇中心優化”步驟,直到滿足停止條件算法終止,得到對應式(1)局部優解的數據集聚類劃分。

圖1 “均勻效應”的例子Tab. 1 An example of “uniform effect”
文獻[6]分析了K-means聚類的“均勻效應”現象。以聚類圖1(a)中的非均勻數據為例。圖1(a)隱含有3個簇Cluster1、Cluster2和Cluster3,它們不但在大小(樣本數)上有差異,簇密度也顯著不同,例如,Cluster1和Cluster2中樣本分布方差顯然有較大差別。該數據的K-means聚類結果如圖1(b)所示,其中樣本數較少的Cluster2會“吞掉”樣本較多的簇Cluster1的部分樣本,使得兩個簇的大小和密度趨向于相同,此即K-means型算法的“均勻效應”。
從統計學習[16]的角度,K-means可以看作是一種基于模型的統計聚類算法。這里,視簇ck的每個樣本x源自如下高斯分布:

(2)
那么,給定數據集DB,劃分聚類的目標就是搜索最小化下面負對數似然函數的模型參數(C,V):
(3)
注意到式(3)的推導結果與K-means算法的優化目標是相同的,見式(1)。
上面推導過程基于如下基本假設:每個簇的樣本方差σ是一個常數。如前所述,σ體現了簇的密度。這從模型的角度解釋了 “均勻效應”產生的一個原因:K-means型算法致力于求解密度相近的簇集合。此外,從式(3)還可以看出,K-means算法的優化目標也沒有體現不同簇中樣本數量的差異,這也是其所假設的概率模型所決定的:對應不同簇的高斯分布分量以一種“平等”的方式進行混合建模。因此,為提高K-means型算法在非均勻數據上的聚類性能,下面首先提出一種新的高斯混合模型,以區分簇類在樣本數量和密度上的差異;接著,以此為基礎,推導出一種新型的非均勻數據聚類算法。
2 非均勻數據聚類模型及算法
本章首先建立用于非均勻數據聚類的高斯混合模型,然后定義基于模型的聚類目標優化函數,最后給出聚類算法。
2.1 非均勻數據聚類模型
如前所述,在一個非均勻數據集中,簇的密度通常存在差異。為刻畫這種差異,引入兩組記號:用σk2(k=1,2,…,K)表示簇ck的方差,其值越大,表明ck的密度越小;進一步,引入向量wk=〈wk1,wk2,…,wkj,…,wkD〉,其各元素wkj>0,用于區分簇ck在不同屬性上的密度差異,值越大表明ck投影在相應屬性上時數據分布的密度越小。由此,ck屬性j上數據分布的方差可用σk2/wkj來表示。將這個方差表達式代入形如式(2)的高斯密度函數,得到任意樣本x∈ck投影在屬性j上的概率密度函數,如下:
(4)
在此基礎上,基于數據集的D個屬性是統計獨立的這一“樸素”假設[17]來建立簇的模型。雖然該假設在一些實際數據上并不現實,但它可以有效降低所構造模型的復雜性:簡單地通過一組變量邊緣分布的乘積來估計向量的概率密度。這樣,令P(x)表示ck中任一樣本的概率密度,有:
(5)
接下來,考慮非均勻數據的另一個特性:同一數據可能包含大小各異的簇。為此,引入代表簇大小的記號αk(k=1, 2,…,K),滿足約束條件:

(6)
其數值大小與簇所包含的樣本數量相關,可以看作是賦予每個簇的一種權重。根據這些定義,非均勻數據的加權似然函數表示為:
(7)
其中:Θ={(ck,σk,vk,wk)|k=1,2,…,K}為K組參數的集合。
基于上述模型,給定數據集DB和簇數K,聚類轉變成了從DB求取優化的參數Θ以最大化加權似然的問題:
上式在式(7)基礎上使用了對數變換,受條件式(6)約束。代入式(4)和(5),并略去其中的常數項,優化目標改寫為:
(8)
對比式(1)可知:
1)當所有的αk、σk和wkj都為常數,J2退化為K-means算法的優化目標函數J0。這意味著K-means假定了所有簇具有相同的大小和相同的方差,且各簇每個屬性上的數據分布密度也是相同的。而新的目標函數通過σk、vk和wk等參數可以區分簇類這些各異的特性;
2)在J2表達式中,wkj主要作用于xj與vkj間距離(實際上是二者間的平方誤差,數值上等于二者歐氏距離值的平方)的計算。從效果上看,衡量屬性密度差異的wkj(j=1,2,…,D)相當于賦予各屬性的特征權重,其數值大小反映了各屬性對距離度量的貢獻程度。因此,優化J2的過程可以看作是對非均勻數據集實施的軟子空間聚類[14]。
2.2 軟子空間聚類算法
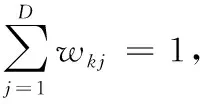
根據拉格朗日乘子法,將wkj、αk的約束條件引入到目標函數中,可得帶約束條件的聚類優化目標函數為:
(9)
其中:λk和η為拉格朗日乘子。
上述目標函數參數的求解是非線性函數的優化問題,難以求得全局最優解。本文MCN算法基于常用的EM算法結構求取其局部最優解。為敘述方便,引入符號W={wkj|k=1,2,…,K;j=1,2,…,D}和Λ={α1,α2,…,αK,σ1,σ2,…,σK}。參數的求解可分為以下幾個步驟:
1)固定W、V、Λ,求C。對任意一個樣本x根據以下公式進行簇劃分:
(10)
式(10)通過比較樣本x源自各高斯分量的概率將其劃分到概率最大的簇中。
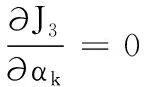
αk=|ck|/N
(11)
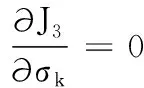
(12)
從式(12)可知,σk2即是第k個簇中樣本分布的加權散度,反映了非均勻數據中各簇有差異的密度信息。根據以上分析,算法的最優解αk和σk2能刻畫非均勻數據中不同簇之間樣本數量和密度都可能存在差異的特點。

(13)
式(13)為簇中心點求解公式,通過該式完成簇中心點的更新。
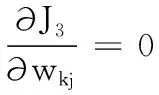
(14)

式(14)通過求解wkj為各特征賦予不同的權重,效果上相當于將第k個簇的樣本投影到相應的子空間中。
根據上述參數求解方法,可以得到基于概率模型的非均勻數據軟子空間聚類算法如下。
輸入 數據集DB,簇數目K。
輸出 簇劃分C。
初始化 隨機生成初始簇中心vk,并令wkj=1/D,σk=1/K,αk=1/K(k=1,2,…,K;j=1,2,…,D)。
Repeat:
更新C:利用式(10)更新簇劃分;
更新vkj:根據式(13),更新vkj;
更新αk、σk:根據式(11)、(12)更新αk、σk;
計算wkj:先計算λk,并將求得的λk代入到式(14)中求得wkj;
Until:滿足迭代停止條件
根據上述算法步驟可知本文MCN算法的時間復雜度為O(PKND),其中P為算法的迭代次數。
3 實驗
實驗平臺為:Core i5-3470 3.2 GHz CPU,4 GB內存,操作系統為Windows 7。算法采用Java編寫。
3.1 實驗設置
實驗選擇了GMM[16]、Verify2[19]、IFCM[10]三種算法進行對比。GMM作為基于概率模型的典型聚類算法,將其作為對比算法用來驗證經典的概率模型和結合子空間技術的概率模型在非均勻數據上的表現;Verify2為文獻[19]提出的一種將欠采樣和譜聚類結合對類不平衡數據進行聚類分析的方法,其中欠采樣是非均勻數據預處理方法中的一種代表性方法;IFCM為文獻[10]中提出的基于樣本數量加權的模糊聚類算法。

圖2 DS1投影到部分低維空間中的數據分布Tab. 2 Distribution of DS1 projected on some low-dimensional spaces
因為非均勻數據不同簇之間樣本存在較大差異,合成數據能夠從簇的數目、大小等控制數據集的簇結構,便于分析算法的性能及算法性能與簇結構之間的關系。首先在多個合成數據上進行測試,然后在4個真實數據上實驗。由于各數據集已知類標簽,選擇兩個外部評價指標Macro-F1[13]和標準化互信息(Normalized Mutual Information, NMI)[20]來評估各種算法的聚類性能,指標的值越大表明聚類效果越好。
其中:F1(classk)為第k個簇的F1值;P(classk,ci)和R(classk,ci)分別表示數據集中真實的類classk與聚類結果中簇ci相比的準確率和召回率;classk表示數據集中第k個真實的類;nk表示classk包含的樣本點數。
NMI的計算公式如下:
其中:nij表示真實數據集中類i與聚類結果中簇j相一致的樣本點數目;ni表示屬于類i的樣本點數目;nj表示屬于簇j的樣本點數目;R表示真實類別數,實驗中設定K=R。
3.2 合成數據實驗結果
實驗中利用numpy中的random.multivariate_norma()函數合成三個數據集。由于二類數據可以直觀表現簇結構,因此,在合成數據時,將簇數目固定為兩類;此外,使用方差σ衡量各簇中樣本的分布散度。合成數據的主要參數如表1所示。如表1所示,三個合成數據集的樣本數量逐個遞增,以此來驗證本文MCN算法在不同數據量下的性能表現;同時,注意到同個數據集不同簇之間樣本數量和樣本方差都有較大差異。三個合成數據集的數據維度也逐個遞增,以此測試不同數據維度下各算法的性能。
為直觀地展現合成數據中樣本的分布情況,將DS1投影到部分維度所確定的低維空間中,投影結果如圖2所示。從圖2可知,DS1中的多數類(樣本數量較多的簇)的數據分布較為分散,少數類的分布則較為集中,且兩個簇存在交疊現象。
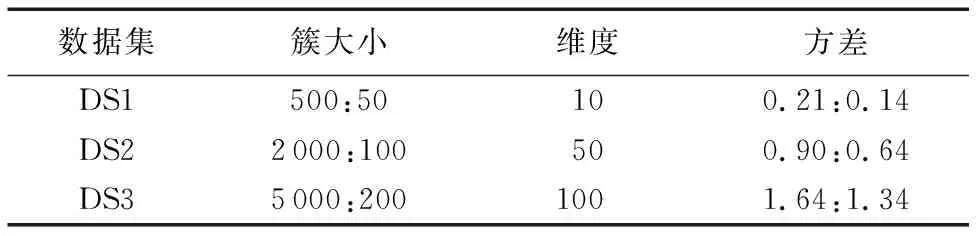
表1 合成數據集參數Tab. 1 Parameters of synthetic datasets
表2顯示不同算法在合成數據集上取得的聚類結果。如表所示,本文MCN算法的聚類精度和NMI值都優于對比算法,表明MCN能更好地聚類此型非均勻數據。GMM算法在三個合成數據集上的NMI值均為0,這是因為GMM算法將數據中的所有樣本都劃分到同一個簇中,側面反映了基于經典高斯模型的方法并不能有效處理非均勻數據。在兩個指標上,IFCM算法與GMM接近。Verify2的聚類精度最低,但與GMM和IFCM算法相比,其NMI值有一定的提升,表明基于樣本抽樣的方法對非均勻數據聚類效果的改善有限。

表2 合成數據集不同算法聚類結果Tab. 2 Clustering results of different algorithms on synthetic datasets
不同算法在合成數據上的運行時間如表3所示。表3中,本文MCN算法的運行時間低于對比算法GMM、Verify2和IFCM。Verify2的運行時間遠高于GMM和MCN算法,一個主要原因是Verify2采用了譜聚類方法,涉及到矩陣特征值計算等,當樣本數量和數據維度較大時,其算法運行時間較長。
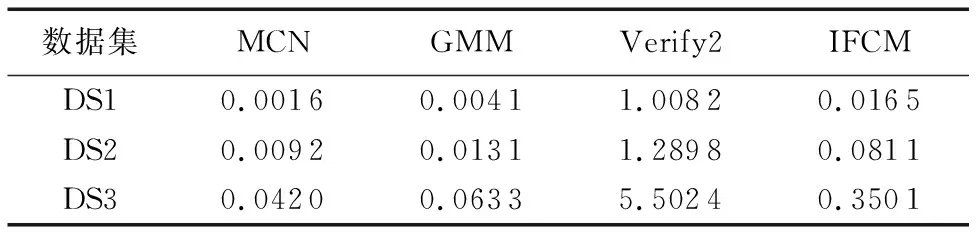
表3 不同算法在合成數據上的運行時間 sTab. 3 Running time of different algorithms on synthetic datasets s

表5 算法在實際數據集上的聚類結果Tab. 5 Clustering results of different algorithms on real-world datasets
3.3 實際數據實驗結果
實驗使用的實際數據來自聚類分析常用的UCI Machine Learning Repository(http://Archive.ics.uci.edu/ml/datasets.html)。選用了四個實際數據集:Breast Cancer Wisconsin(簡寫為BCW)、Wine、 ForestType和Ionosphere,數據集主要參數如表4所示。其中,BCW為乳腺癌診斷數據,包含241個惡性樣本和458個良性樣本;Wine是相關研究常用的不平衡數據集,其普通品質酒類的樣本數較多,而品質較好和品質較差的樣本數量則較少;ForestType是森林遙感數據,包含三種不同的森林類型和一類空地,其中Sugi forest類的樣本數量較多;Ionosphere為電離層雷達波數據,其中具有某種特定結構的樣本數量較多。這四個數據集中,不同簇類的樣本數有較大差異,且樣本分布(方差)也存在差異,是典型的非均勻數據。實驗將基于BCW、 Wine數據集驗證各種算法在低維數據上的性能,在ForestType、Ionosphere上對比算法在較高維度數據上的表現。本文MCN算法與對比算法在四個實際數據上的聚類結果如表5所示。表5顯示,MCN算法在Wine數據上的兩項指標稍低于IFCM算法,但在其他數據集上的聚類精度和NMI值都明顯優于對比算法,表明MCN算法可以有效聚類實際應用中的非均勻數據。

表4 實際數據集參數Tab. 4 Parameters of real-world datasets
如前所述,本文提出的MCN算法可以實現非均勻數據的子空間聚類,實現途徑是在聚類過程中自動地賦予每個特征以不同的權重。下面以Wine數據集為例,從MCN算法的一次聚類結果中提取特征權重信息,作進一步分析。圖3顯示該數據集中三個簇(分別記為Cluster1、Cluster2和Cluster3)各自的13個特征(分別命名為A1,A2,…,A13)的權重分布。

圖3 Wine數據中三個簇的特征權重分布Fig. 3 Distribution of feature weights of three clusters in dataset Wine
如圖3所示,不同簇的特征權重分布并不相同。例如,對于Cluster3,MCN算法賦予A11(指“酒的色調”)較大的權重,這表明“色調”對識別Cluster3有重要的作用;而特征A8(一種稱為“Nonflavanoid phenols”的酚類化學物質)對Cluster2中酒的品質有較大影響。以上結果表明,MCN算法可以有效識別特征對于不同簇類有差別的貢獻度,從而提高了實際應用中非均勻數據聚類的性能。
4 結語
針對K-means型算法的“均勻效應”問題,本文提出了MCN算法。首先分析了經典K-means算法隱含使用的概率模型,它是基于有關參數為常數這一假設的高斯混合模型,此簡化模型并不能很好地刻畫非均勻數據簇之間樣本數量和密度都有較大差異的特點。接著,從概率模型角度入手,結合軟子空間聚類技術定義了一種非均勻數據簇的概率模型,并推導出了相應的聚類優化目標函數。最后給出了MCN的算法過程。在合成數據和實際數據上的實驗結果表明,與GMM、Verify2、IFCM等算法相比,MCN算法在多數情況下都可以取得較大的聚類性能提升,從而驗證了本文所提算法的有效性。
在大數據時代如何結合大數據處理工具分析非均勻數據是一項有意義的工作,因此下一步將結合分布式Spark平臺進一步研究非均勻數據聚類新方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂探索(2022年2期)2022-05-30 21:01:37
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
中國特種設備安全(2018年11期)2019-01-08 02:08:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
