文本向量化表示方法的總結與分析
2018-12-06 06:17:28冀宇軒
電子世界 2018年22期
冀宇軒
隨著計算機技術的深入發展,由于計算能力的大幅提高,機器學習和深度學習取得了長足的發展,因此我們在自然語言處理領域的研究越來越多的應用了機器學習和深度學習的工具,在這樣的情況下,文本的向量表示就是一個非常重要的問題,因為良好的文本向量可以更好地在向量空間中給出一個文本空間內的映射,從而使得文本可計算。在近些年出現了許多的文本向量生成方法,本文主要介紹了文本向量化的發展過程,并對常見的文本向量生成方式進行了對比。
1.概述
1.1 研究背景
正如圖像領域天然有著高維度和局部相關性的特性,自然語言處理領域也有著其自身的特性,其主要體現在以下幾方面:
(1)由于計算機系統本身的硬件特點,任何計算的前提都是向量化,而自然語言處理領域的空間難以直接向量化,其不像圖像與語音領域,信息可以直接被向量化,在自然語言處理領域的文本難以直接被向量化。
(2)自然語言處理領域中存在著多種高級的語法規則及其他種類的特性,具體體現為語法上的規則、近義詞,反義詞等。乃至于自然語言本身就體現了人類社會的一種深層次的關系(例如諷刺等語義),這種關系給自然語言處理領域的各種工作帶來了挑戰。
而文本信息的向量表示作為自然語言處理中的基本問題,其應當盡可能地包含原本空間內的信息,因為一旦在空間映射時丟棄了信息,則在后續的計算中也無法再獲取到這些信息了。
1.2 研究意義
如上所示,在自然語言處理中,文本向量化是一個重要環節,其產出的向量質量直接影響到了后續模型的表現,例如,在一個文本相似度比較的任務中,我們可以取文本向量的余弦值作為文本相似度,也可以將文本向量再度作為輸入輸入到神經網絡中進行計算得到相似度,但是無論后續模型是怎樣的,前面的文本向量表示都會影響整個相似度比較的準確率,因此,對于自然語言處理的各個領域,文本向量化都有著舉足輕重的影響。
2.模型簡介及分析
2.1 詞袋模型
2.1.1 One-hot Representation
最早的一種比較直觀的詞向量生成方式稱為One-hot Representation,這種映射方式是通過先將語料庫中的所有詞匯匯總的得到N個詞匯,并將語料庫中的每個文檔個體生成一個N維的向量,在每個維度就體現了該文檔中存在多少個特定詞匯。這種方式是一種較為簡單的映射方式,其產生的向量表示體現了詞頻的信息。
2.1.2 TF-IDF模型
上述方式的模型僅考慮了詞頻,并且會造成長句子和短句子的向量長度不一致的情況,因此又有一種考慮了文檔詞匯中的逆文檔頻率的映射方式:TF-IDF(term frequency-inverse document frequency)模型,在這種方式中,首先對詞頻進行了歸一化,即使用詞出現的頻率而非次數代表詞頻,表示為公式如下:
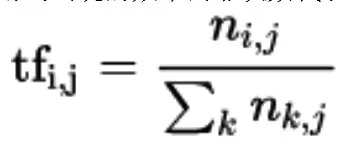
另一處改進為統計了每個詞的逆文檔頻率指標,并使用該指標作為詞罕見程度的度量值,以更好地刻畫文檔的生成向量。逆文檔頻率的模型如下:
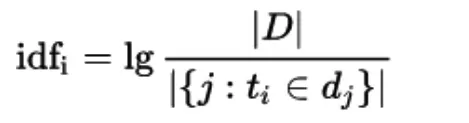
這兩種模型的共同的缺點在于其二者的向量長度都非常大,對于一個有著30W詞匯量的語料,每個文檔的映射向量長度將都是30W,這意味著產出的矩陣非常稀疏,并且在計算時也會非常復雜。
2.1.3 潛語義分析模型
因此,我們引入降維的方式來對高維度的文檔向量進行處理,其主要的模型為潛語義分析模型(Latent Semantic Analysis),這種模型通過數學方法,將文檔之間的關系、詞之間的關系和文檔與詞之間的關系都納入考慮中(Deerwester,S.,Dumais,S.T.,Furnas,G.W.,Landauer,T.K.,& Harshman,R.(1990).Indexing By Latent Semantic Analysis.Journal of the American Society For Information Science,41,391-407.10)。
具體來講,潛語義分析模型使用了主成分分析的方式來進行降維,即通過抽取向量空間內分布方差最大的若干個正交方向來作為最后的表示方向,并對其余的方向的內容進行丟棄即得到了每個樣本的低維表示,該表示是有損的,即丟失了在丟失維度上的分布細節。
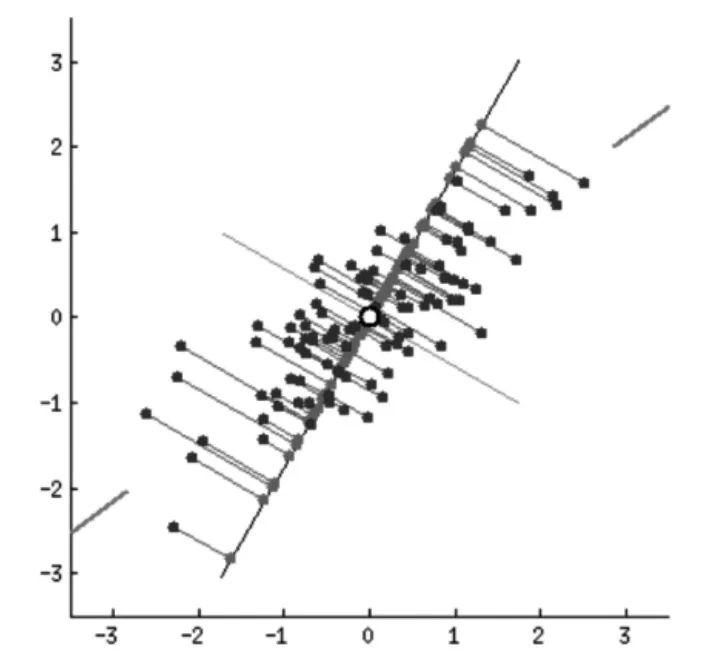
圖1 二維向量分布的主成分分析
潛語義分析模型將這種將高維的向量表示轉換為低維的向量表示的方法解釋為文檔的詞向量空間轉化為語義級別的向量空間,由此實現了一個有意義的文本降維的工作,即在更低維度上,一個維度并不再代表原來的一個詞的信息,而是代表原來的幾個詞的一個混合信息,這被稱為“語義維度”。被丟棄的維度上的分布也被認定為是一種“噪音”,對其丟棄可以更好地使用低維度的信息來表達原文本的語義信息。
值得被關注的是,上述的模型均為詞袋模型,其基本的特點即為忽略了文本信息中的語序信息,即不考慮段落中的詞匯順序,僅將其反映為若干維度的獨立概念,這種情況有著因為模型本身原因而無法解決的問題,比如主語和賓語的順序問題,詞袋模型天然無法理解諸如“我為你鼓掌”和“你為我鼓掌”兩個語句之間的區別。因此基于上述模型的文本模型無法獲取到原文本中語序所帶來的信息。
2.2 基于神經網絡的文本向量化模型
深度學習出現以后,逐漸被應用于自然語言處理領域,在文本向量化上也有著許多的進展,其中很多的成果已經成為了自然語言處理領域的基礎部分。
2.2.1 Nerual Network Language Model
2001年,來自蒙特利爾大學計算機教授Yoshua Bengio給出了一種生成詞向量的方式,即通過一個三層的神經網絡、softmax分類及反向傳播算法實現了詞向量的映射(Bengio,Yoshua,et al.”A neural probabilistic language model.”Journal of machine learning research 3.Feb(2003):1137-1155),在這種映射中,詞向量本身包含了語義的信息,即通過向量的分布信息可以得知其對應詞的相互聯系,其基本結構如下:
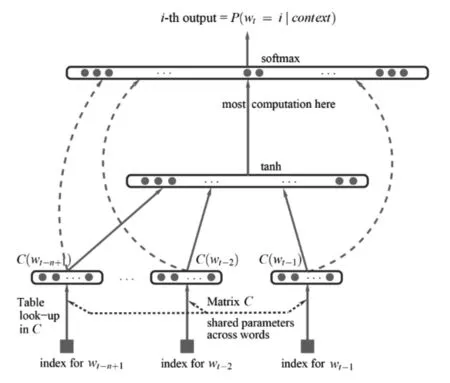
圖2
其輸入層為中心詞附近的多個詞的向量表示,并將這些向量進行拼接得到隱藏層,并通過softmax函數得到輸出層,即可以通過梯度下降的方式來訓練輸入向量與權重參數,在這里需要注意的是在這個模型中,我們所需要的是模型產出的詞向量而非權重參數。
2.2.2 word2vec與doc2vec
2013年,來自Google的Mikolov.Tomas等人發表了《Efficient Estimation of Word Representations in Vector Space》,提出了兩種詞向量映射模型(Mikolov,Tomas,et al.”Distributed representations of words and phrases and their compositionality.”Advances in neural information processing systems.2013),不僅簡化了NNLM模型,也提升了訓練的準確度,在訓練得到的詞向量中。同年,Google公司開源了可以在百萬詞典和千億級別語料數據上進行計算的word2vec工具,并分享了基于分布式計算框架在千億級大規模新聞語料中訓練得到了詞向量結果,極大推動了自然語言處理的發展。
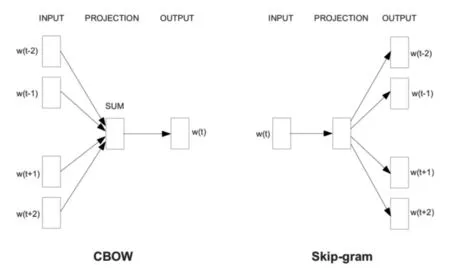
圖3
其使用兩種模型結構,分別是CBOW模型和Skip-gram模型,CBOW模型的主要思想是使用中心詞附近的詞去預測中心詞,而Skipgram模型主要是使用中心詞去預測中心詞附近的詞。其二者的區別主要在于CBOW模型某種意義上屬于一種詞袋模型,一定程度上忽略了文本的語序順序,并且由于模型結構的不同,其二者反向傳播進行參數調整的方式不同:CBOW模型的中心詞會共享一次反向傳播的梯度下降,而Skip-gram則不存在這種共享關系。除此之外,word2vec的方法還提出了兩種方法來加速詞向量的訓練速度。
在word2vec詞向量方式出現以后,很多學者開始了基于word-2vec的文檔向量化方法的研究。其中主要有以下兩種主要方法:第一種是簡單的向量加和取平均值,這種方法的特點是速度快,但是由于完全忽略語序信息,因此效果比較差,另一種方式是基于語法規則樹來建立文本向量,但是其局限性在于其性能較低且僅適用于句向量的生成,效果同樣不是很好。2014年,Mikolov.Tomas提出了一種新的基于神經網絡的段落文本生成方式,是一種良好的端對端的文檔向量化方式(Le,Quoc,and Tomas Mikolov.”Distributed representations of sentences and documents.”International Conference on Machine Learning.2014)。
其中,PV-DM算法主要沿用了word2vec 中cbow的方法,通過一個單層的簡單神經網絡來構建模型,在構建隱藏層時將段落向量也加入隱藏層,并且與其他的詞向量一起獲得反向傳播的梯度,這樣在多輪迭代后就可以:
Distributed Memory version of Paragraph Vector (PV-DM)
該算法大致上沿用了word2vec CBoW的方法,即通過一個單層的神經網絡結構來建立模型,在這個模型的訓練過程中得到副產物段落向量,其不同點在于在這里另外增加了一個向量作為段落的向量表示,與詞向量共同拼接或加和作為輸入進入網絡,網絡通過梯度下降的方式進行優化,當需要給出一個新的段落向量表示時,在預測階段,模型的參數(包括詞向量和模型中的softmax參數)都是固定的。
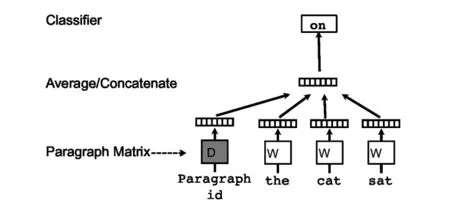
圖4
Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
這種算法大體上也是沿用了Word2vec中的Skip-gram的方法,即以文檔向量作為輸入,以最大化輸出為文檔中的詞作為目標進行訓練,這種方式也可以獲得文檔的向量表示。
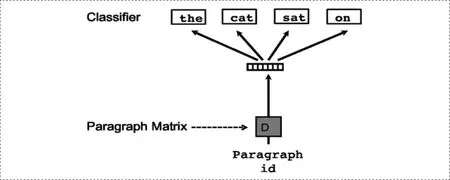
圖5
以上兩種方式均可以通過Hierarchical Softmax或者Negative Sampling簡化模型訓練,從而提升訓練效率,除此之外另有Glove等方式用于詞向量表示(Pennington,Jeffrey,Richard Socher,and Christopher Manning.”Glove:Global vectors for word representation.”Proceedings of the 2014 conference on empirical methods in natural language processing(EMNLP).2014)。
基于神經網絡的文本向量化方式的特點主要包括以下幾個:
(1)基于神經網絡的文本向量化方式可以更多地利用激活函數及softmax函數中的非線性特點,這種特點為模型帶來了更多的擬合能力,使得模型可以學習到更多的文本特性,生成的文本向量是更好地文本向量化表示。
(2)基于神經網絡的文本向量化方式很大程度上保留了語序信息,其利用了文本相鄰的特性,這種特點在詞袋模型中往往是直接忽略掉了的。
(3)基于神經網絡的模型在語料規模和訓練復雜度上也有著更高的要求,這意味著只有在計算能力和文本數據量達到一定程度的時候才可以開展,近些年的深度學習的發展也是源于信息爆炸和計算能力的飛速發展。
3.總結與展望
在過去的主要文本向量化方法中,早期的模型主要是基于統計的,其計算相對簡單,但是效果也相對較弱,隨著深度學習的發展,基于神經網絡的模型開始出現在自然語言處理領域,也極大地提升了文本向量化的質量,由于文本向量化本身的重要性,在未來一定會有更多優秀的模型可以用于這個領域,我們應該更加努力地學習相關知識,以期有所建樹。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學刊(2011年1期)2011-01-22 03:38:33
