大數據智能運維運營系統在運營商的設計與應用
2019-01-06 03:36:42王巍
無線互聯科技 2019年21期
王巍

摘? ?要:在運營商某融合通信系統中,傳統的Hadoop海量文件批處理速度慢,數據庫面對海量數據存儲及全文檢索能力弱,無法應對日常運維需要。處理海量業務日志且提升實時性,技術選型flume+Kafka+Spark+ElasticSearch,改造為流式計算大數據技術架構。文章結合業務訴求,基于領域模型全新設計,DashBoard分層遞進,漸進明細地實時發現故障—初步分析—根因分析—定界定位,大幅提升系統運維運營能力和時效性的同時,還降低了人力成本。
關鍵詞:大數據;智能運維;Kafka;Spark;ElasticSearch
運營商某融合通信運維系統原本選型Hadoop,該技術架構盡管能處理海量業務日志,但因為基于文件傳輸和MapReduce的批處理延遲較大,每批次處理最快也要20 min左右才能入庫查詢。運維講求時效性,業務故障后幾分鐘內就要及時發現并分析定位解決,Hadoop文件批處理技術架構往往在用戶投訴上來后,日志還在下一批次的處理入庫中,無法滿足日常運維需要。數據庫面對海量日志存儲和各種組合查詢力不從心,同時,系統業務設計單一,只有業務上報的告警和日志查詢,運維能力過于單薄。
1? ? 架構設計
針對上述運維訴求的痛點,急需設計一套能實時處理大容量日志、支持海量日志存儲且可組合檢索、貼近運維運營訴求、統計分析簡約易用的大數據運維運營系統。
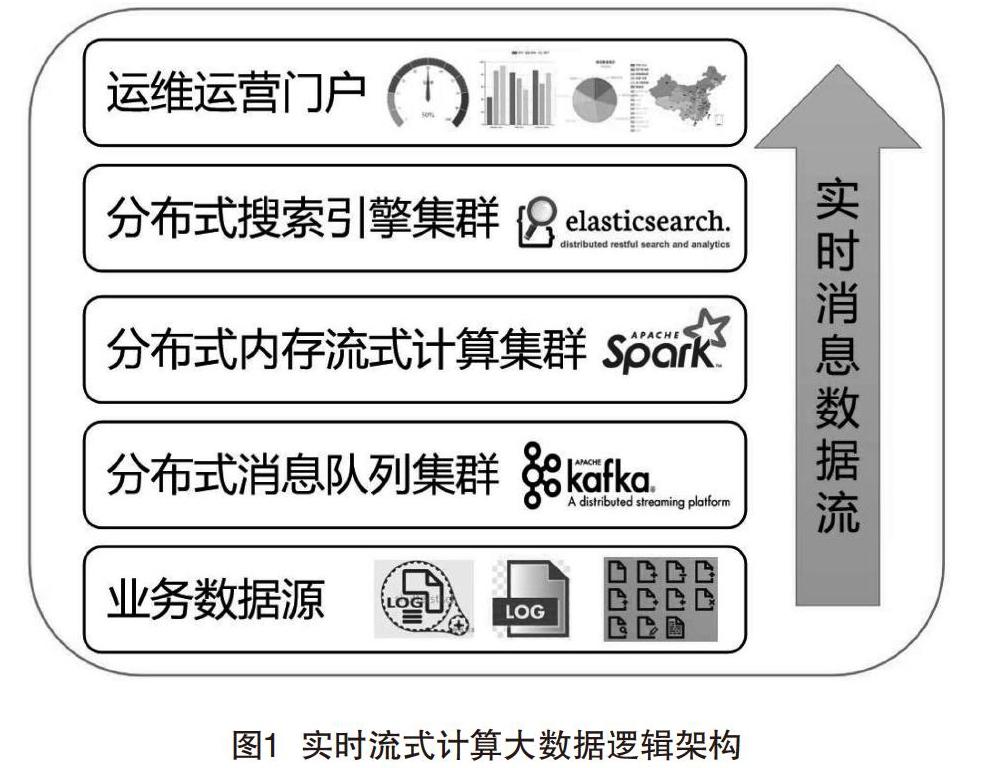
1.1? 邏輯架構
首先,從邏輯架構出發,結合業務痛點,逐層梳理設計并技術選型。實時流式計算大數據邏輯架構如圖1所示。
(1)業務數據源。原本由自身業務系統生成日志文件SFTP定時采集,改造為日志消息接口實時發送;原本第三方系統生成日志文件SFTP定時采集,改造為flume或logstash實時采集。
(2)分布式消息隊列集群。該層用于前臺業務和后臺運維運營系統消息異步處理,系統間隔離解耦,同時避免多套業務系統日志對后臺運維運營系統的流量沖擊,進行削峰。最終選型Kafka,因為Kafka是一個基于發布/訂閱模式的分布式消息隊列,完全滿足上述特性要求,且對記錄2 KB以內的日志,單模塊處理性能經測試就可達近10萬TPS,還支持持久化,是業界實時大數據日志處理MQ的事實標準組件。
(3)分布式內存流式計算集群。該層用于從Kafka實時消費各個topic的日志數據流,進行實時流式計算,如實時日志清單入庫、實時分組統計多維度的業務量、失敗量等可累加指標;同時也要具備海量數據的批處理能力,用于從持久化到HDFS的數據批量計算不可實時統計的日活用戶排重、top失敗等指標。最終選型Spark,因為Spark是一個同時支持流式計算(Spark Streaming)和批量計算(SparkSQL/RDD)的大數據處理系統,完全滿足上述特性要求,且可無縫對接Kafka和ElasticSearch集群。Spark Streaming相當于mini batch的RDD批處理,也就是說流式計算和批量計算的開發方法基本相同,且對各類分組、排序、排重等常用統計進行了函數封裝,大幅降低了研發學習和開發成本。業界也有很多成功應用案例。
(4)分布式搜索引擎集群。該層用于存儲海量日志清單,同時需要支持多維度組合條件查詢分析。最終選型ElasticSearch,因為ElasticSearch底層是基于lucence索引的分布式搜索引擎,完全滿足上述特性要求,相對solr可以支持更大數量級的日志存儲和檢索,提供了各類Rest接口的API,方便進行分組、聚合等輕量級快速、靈活查詢分析,還支持全文檢索。業界也有很多成功應用案例。
(5)運維運營門戶。該層需要結合業務設計,DashBoard多維度展現各類統計分析監控指標,支持鉆取、聯動分析等。業界有Grafana、Kibana可以使用。最終選型是自身的Web管理平臺,原因是自身的Web管理平臺還具備權限管理、操作日志、告警界面展現等,并支持菜單集成掛載鏈接到Grafana,Kibana等。
1.2? 技術架構
在邏輯架構和已選型的組件基礎上,進行了架構細化、業務功能設計與組件實現相對應,讓數據流在整套系統內流轉起來,并在實驗室部署調試驗證組件功能和性能,從無到有搭建,小步快跑逐步實現了整套系統。實時流式計算大數據技術架構如圖2所示。
2? ? 業務設計
2.1? 故障告警專題
告警是運維系統監控發現故障問題的重要手段,是整套運維系統的最先切入點。
傳統的告警功能是業務觸發告警一一對應。本專題設計了3層靈活組裝模型:基礎指標—組合指標—告警策略,只需要向業務獲取基礎指標。本運維系統基于基礎指標和算術表達式,可靈活定義配置出新的組合指標;基礎指標和組合指標又可以任意邏輯組合,靈活定義配置出新的告警策略。舉例如下:
基礎指標,每分鐘業務量、每分鐘成功數。
組合指標,在運維系統配置即可新增“業務成功率(%)組合指標”=每分鐘成功數/每分鐘業務量×100%。
告警策略,系統配置新增“平日夜間告警策略”。
時間范圍:周一至周五,22:00—5:30。
優先級:1。
告警策略:(每分鐘業務量>10)AND(業務成功率(%)組合指標<95(%)。
可以看出,該專題設計大幅減輕了業務系統的告警工作,轉由本運維系統靈活配置快速組裝承載,降低了研發人力的同時,還增強了運維能力。
2.2? 業務質量專題
故障告警專題鉆取聯動的下一級是業務質量專題:當運維人員發現系統業務告警后,點擊告警,系統自動鉆取聯動跳轉到對應的業務質量界面,在故障發生時間點粒度內,結合界面的時間趨勢圖等DashBoard,多維度分析,初步判斷故障發生的業務類型、地域、終端類型、終端版本、APP版本等。
2.3? 質量分析專題
業務質量專題鉆取聯動的下一級是質量分析專題:運維人員在業務質量對故障發生的業務類型、地域、終端類型、終端版本、APP版本等維度有了初步判斷,界面點擊,系統自動鉆取聯動跳轉到相同維度的質量分析界面,在故障發生時間點粒度內,對應維度的業務內部錯誤碼、外部失敗響應碼按出現次數TOP倒排分析,讓運維人員迅速得知故障根因。
2.4? 故障定位專題
質量分析專題鉆取聯動的下一級是故障定位專題:運維人員在質量分析界面點擊出現次數TOP的業務內部錯誤碼、外部失敗響應碼,系統自動鉆取聯動跳轉到相同維度條件的詳單查詢并自動查詢,展現出來受此影響的用戶和波及業務詳單記錄,讓客服提前做好準備解答客戶問題。
2.5? 資源占用專題
儀表盤、時間趨勢圖實時展現當前系統各類業務資源、緩存資源、CPU、內存、存儲資源的占用和訪問情況等。
2.6? 用戶分析專題
運維之外,系統還具備分地域、分終端,各APP等維度的已開戶用戶數,日活、周活、月活用戶數,當前在線用戶數等用戶運營分析指標、發展趨勢、占比分析等。
3? ? 結語
本大數據運維運營系統目前已在運營商某融合通信系統成功上線商用,運維人員從擔心用戶投訴,手工采集日志打包反饋研發耗時、耗力,到系統自動業務告警及時發現故障,運維人員鉆取聯動自行初步判斷、根因分析、故障定界定位、實時監測系統和業務資源占用等,運營人員自助報表分析用戶行為,大幅提升了運維運營能力的同時,從過去的幾十人運維團隊降低到10人以內,得到了客戶、運維、運營、研發的一致認可。
[參考文獻]
[1]李祥池.基于ELK和Spark Streaming的日志分析系統設計與實現[J].電子科學技術,2015(6):674-678.
[2]毛開梅.大數據智能運維系統設計及應用[J].網絡與信息工程,2018(14):62-63.
Design and application of big data intelligent operation and maintenance system in operators
Wang Wei
(Zhongxing Telecommunication Equipment Corporation Co., Ltd., Nanjing 210012, China)
Abstract:In a converged communication system of the operator, the traditional Hadoop mass file is slow in batch processing speed, and the database faces massive data storage and full-text retrieval capability, so that the daily operation and maintenance needs cannot be met. In order to deal with the massive business log and improve the real-time performance, the technology type-type flume+Kafka+Spark+ElasticSearch is transformed into a stream-type large-scale data technology architecture in this paper. Based on the new design of the domain model and the new design of the domain model, the real-time discovery of the DashBoard hierarchical progression and the progressive details is based on the analysis of the position of the analytic hierarchy, and the operation and maintenance of the system is greatly improved. While operating ability and timeliness, it also reduces the cost of manpower.
Key words:big data; intelligent operation and maintenance; Kafka; Spark; ElasticSearch
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
北京測繪(2020年12期)2020-12-29 01:33:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
山東工業技術(2016年15期)2016-12-01 05:31:22
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
