以壓縮感知為基礎的語音數字編碼技術
2019-01-06 03:36:42黎華
無線互聯科技 2019年21期
黎華


摘? ?要:語音通信是當前社會發展中基本通信方式之一,實現高質量語音通信的根本在于計算機、電子技術等相關科技領域的發展。文章指出語音數字編碼技術主要用于將原本模擬信號的語音轉化為數字信號形式,方便用戶對語音進行處理、傳輸以及存儲。文章基于壓縮感知,對語音編碼技術進行詳細分析。
關鍵詞:壓縮感知;基礎;語音數字;編碼技術
壓縮感知技術能夠實現對信號在采樣的同時進行壓縮,因此,受到信號處理行業的重視。對于數字語音處理來說,采樣之后的量化編碼是比較重要的一部分,在這樣的背景下,本文以壓縮感知作為基礎,研究語音數字編碼技術,希望以此能夠為相關人士提供參考。
1? ? 概述壓縮感知
壓縮感知,又名壓縮采樣、稀疏采樣,從本質上來講是查找欠定線性系統的一種稀疏技術,這項技術被廣泛應用于電子工程領域,尤其是在信號處理方面。工作原理是信號具有稀疏特性,與奈奎斯特理論相比較,可以從比較少的測量中還原出原本想要獲得的信號。核磁共振是一個比較典型的例子。
2? ? 基于壓縮感知技術下系數表示的語音壓縮感知編碼研究
2.1? 稀疏表示理論
隨著科學技術的發展,傳感器技術應運而生,多數領域在發展中存在數據不斷增長情況,例如音頻、視頻、地震等數據信息,如何對以上數據進行有效處理,使其表達方式更加簡潔以及自適應,已逐漸成為當前信號處理行業重要問題之一。小波理論背景下的分解思想主要表達的是自適應選取特征。假設信號為s∈RN,L個N維長度向量d為字典D,表達式為D={d,∈RN,‖dγ‖=1,1≤γ≤L},給定字典后,信號s的線性組合表達式為:
也可運用分解逼近形式來表示信號:
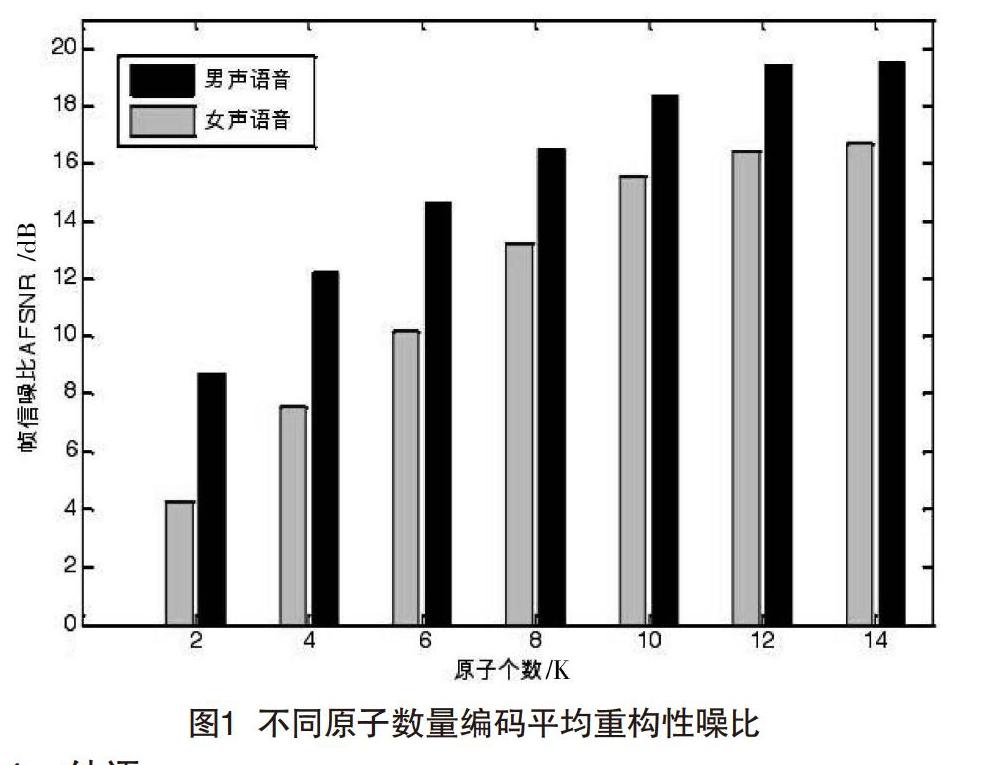
α為展開系數,R(k)為經過k項之后的殘差,若K< 上述表達式中α=[α1, α2, α3, …, αL],指系數展開后的向量組成,‖a‖0為a的L0范數,代表系數α非零元素個數。基于此,要想切實保證稀疏具備相應的稀疏度,就需要對維度k的大小進行合理固定,促使信號接近于模型min‖s-Da‖22 s.t.‖a‖0≤K,這種情況下,a處于絕對稀疏狀態,稀疏度為K< 2.2? 冗余字典 2.2.1? 基于調和分析的字典 通過展開某種類型的固定基,將其使用于信號中某種類型的結構特征,不適用于局部變化大的信號。一般來說,這種方式需要定義與該信號結構特征兩者相匹配的時頻原子,主要是通過固定窗函數w(t)平移、拉伸以及調制的方式獲取的,因此,要想確保時域局部性,就需要固定窗函數w(t)滿足以下幾點要求[1]: (1)固定窗函數w(t)必須為連續可為實函數。(2)‖w(t)‖=1。(3)w(t)=。(4)dt≠0 and w(0)≠0。 之后對時頻原子簇定義為: 在上述表達式中,γ=(s, u, ζ),尺度、平移、頻率3種參量分別為s>0, u, ζ。假設w(t)為偶函數,在坐標u集中已知能量,同時已知能量的集中程度與尺度s兩者成比例,這時候w(t)可轉變為: 因w(w)也屬于偶函數,這使得能量集中位置在對稱軸w=ζ附近。通過對以上兩個觀察式進行探究發現,時頻原子不管是在時域上,還是在頻域上,都具備相應的局部性。運用這種方法構成冗余字典,一方面能夠切實滿足信號的特征;另一方面對某類信號進行有效分解。從本質上來講,這種類型的字典生成方式主要是通過對參數進行調整,以此為基礎對原子時頻特性進行相應的調整,所產生的字典具有結構強、可選性大以及對各種異性結構進行有效稀疏表示等特征,在圖像消噪、壓縮等領域中已取得相應進展[2]。 2.2.2? 基于樣本訓練的字典 基于樣本訓練的字典、不需要提前對字典原子表達式進行定義,但在通常情況下,經常會存在各種復雜約束代價函數,正則理論也因此導入。 當前比較流行的算法為K-SVD算法,也是K-Means算法擴大化,當字典中一個原子的近似表示為K-SVD算法時,就會退化為K-Means算法。從性質上來講,這種算法主要是運用奇異值的方式進行分解,代替原有對逆矩陣進行求解的方式來獲取更新原子,在圖像消噪領域中獲得良好的應用。除以上集中算法之外,還有ODL算法、RLS-DLA字典學習算法、Analysis K-SVD算法等,以上得到的字典都屬于非結構性字典,而在大部分算法中,主要包括兩種,一種為稀疏分解,另一種為字典更新,其中,字典更新這種算法是由稀疏展開向量正則約束條件決定的。 2.3? 語音壓縮感知編碼中稀疏表示的應用 本文以K-SVD算法為例,目標函數公式如下: 其中,x∈RN指的是訓練樣本;α∈RL指訓練信號稀疏表示;D∈RN×L是冗余字典。其中X指訓練樣本集合,A指稀疏表示樣本集合,K指系數表示系數中的最大稀疏度。根據誤差逼近角度來分析,這種算法還可以表示為以下公式: 3? ? 仿真結果分析 通過仿真實驗驗證語音壓縮感知編碼算法是否具有可行性意義。本次實驗采用的語音來自CASLA98語音庫,其中采樣頻率是8 kHz,選取人數為50人,男女語音分別為100句,最終結果為平均數。為切實確保這項編碼具備可靠性,利用MOS分以及平均幀信噪比對解碼后重構語言質量進行評判。 本次仿真實驗冗余字典表示為D,其大小L=8 192;語音幀長大小為30 ms,圖1為不同原子數量編碼平均重構性噪比。根據圖1可知,隨著稀疏表示原子個數不斷增多(單位:K),相應的重構語音信噪比也因此不斷增大,但稀疏表示原子個數高于10以后,系統性能也隨之呈現緩和態勢發展。通過分析原子個數對重構語音MOS分產生的影響,可得出結論:重構語音MOS分會隨著原子個數不斷增加的過程逐漸趨于平緩發展。分析男聲可知,重構語音平均信噪比為16.478 dB,MOS分為3.083,人耳聽力感知趨于清楚,但還是存在雜音;分析女聲可知,重構性能與男生差別不多,但從整體上看重構效果比男聲語音要低,這主要是因為女聲高頻部分成分比較多,就使得DCT稀疏性差,出現重構誤差大的問題。基于此,要想解決男聲與女聲之間存在的壓縮感知性能差異,就需要選擇男聲女聲效果優質的稀疏域,從本質上來講就是將女聲的稀疏字典進行改進,進一步實現對女聲的真正稀疏表示[3]。 4? ? 結語 綜上所述,壓縮感知理論與語音數字編碼技術對社會的發展有積極性意義,本次探究希望能夠為相關科學研究人員提供參考意見。 [參考文獻] [1]賈曉立,江曉波,蔣三新,等.利用結構特征的語音壓縮感知重建算法[J].上海交通大學學報,2017(9):1111-1116. [2]隋昊,周萍,沈昊,等.基于混沌序列的壓縮感知語音增強算法[J].微電子學與計算機,2018(1):96-99. [3]宋維琪,張宇,吳彩端,等.多道聯合壓縮感知弱小反射地震信號提取處理方法[J].地球物理學報,2017(8):3238-3245. Speech digital coding technology based on compressed perception Li Hua (Yueyang Vocational Technical College, Yueyang 414000, China) Abstract:Speech communication is one of the basic communication methods in the current social development. The realization of high-quality voice communication lies in the development of computer, electronic technology and other related scientific and technological fields. The speech digital coding technology mentioned in this paper is one of them. Its main purpose is to convert the original analog signal speech into digital signal form, so as to facilitate users to process, transmit and store speech. In this paper, the speech coding technology is analyzed in detail based on the compression perception. Key words:compression perception; foundation; voice number; coding technology
