大數據環境下基于用戶畫像的學術文獻推薦系統研究
2019-02-06 03:56:07劉相金王夢菊
河南圖書館學刊 2019年12期
劉相金 王夢菊
關鍵詞:大數據環境;用戶畫像;學術文獻推薦系統
摘 要:文章在闡述用戶畫像概念的基礎上,從技術工具、數據模塊、學術文獻數據庫、學術文獻推薦模塊等角度總結了基于用戶畫像學術文獻推薦系統的構建方式,以期為用戶推送符合其需求的學術文獻。
中圖分類號:G250文獻標識碼:A文章編號:1003-1588(2019)12-0113-03
隨著社會發展進入大數據時代,信息數據越來越多,讀者的需求也越來越多元化。面對這種趨勢,圖書館應使用大數據技術針對用戶的多元需求進行分析、定位及精準預測,在精準判定用戶個性化學術文獻需求的基礎上,使用新型技術創新圖書館服務模式,使學術文獻服務與用戶需求精準契合。在用戶感知層面,大多數圖書館習慣以調研的方式獲取用戶需求,甚至根據經驗主觀判定用戶需求,造成對讀者需求定位不準,學術服務精準性較差。伴隨大數據技術的發展,圖書館應使用數據分析技術、數據挖掘技術根據用戶的網絡行為軌跡及有關數據記錄獲取用戶數據,精準定位用戶需求,以便為用戶提供更有效的個性化服務[1]。同時,圖書館館藏資源的增加尤其是多種數據資源的聚合,使用戶利用圖書館查找符合自身個性化需求的資源越來越困難。用戶畫像作為大數據時代實現用戶需求挖掘及行為偏好識別的新型技術體系,可以使圖書館根據用戶行為偏好及個性化需求提供學術文獻,使學術文獻推薦服務更加精準。因此,構建基于用戶畫像模型的學術文獻推薦系統,可以對用戶行為偏好及個性化需求進行深度挖掘,從而實現圖書館館藏資源與用戶需求的精準匹配。
1 用戶畫像概述
1.1 用戶畫像的含義
用戶畫像是指在大數據環境中對用戶行為偏好和個性化需求進行分析和預測的一種技術機制,主要借助爬蟲數據對用戶瀏覽網頁及進行互聯網交互行為時產生的運動軌跡、網站瀏覽日志記錄進行爬取搜集,以實現用戶行為偏好數據的深度挖掘、提取、分析。用戶畫像實現的基礎是對用戶需求、個性、習慣的精準識別,核心機制是為可識別的用戶偏好數據、行為數據貼“標簽”,使面向用戶的虛擬數據、個性化信息有據可依。綜合來看,用戶畫像關注的焦點是用戶的行為、個性,并將用戶的社會屬性、背景、經歷、行為與服務預期關聯起來[2]。
1.2 用戶畫像在圖書館的應用
用戶畫像應用的重要目的是精準刻畫用戶的行為偏好及個性化特點,分析用戶的個性化需求,為圖書館實現精準的學術文獻推薦以及對用戶身份進行精準識別提供技術支持。用戶畫像在圖書館學術文獻推薦領域的主要作用包括:①精準分析用戶群,挖掘潛在用戶,預測潛在用戶需求并進行學術文獻精準推薦。②根據用戶的資源獲取習慣、個性化資源需求、行為偏好分析用戶可能產生的學術資源需求,分析學術資源的重點內容、應用趨向,為定制學術資源提供參考數據。③根據用戶學術文獻獲取行為、興趣習慣、行為偏好面向用戶精準推薦學術文獻,使用大數據技術實現某一時間段內用戶需求的具體描述,考察資源利用效果,評價學術文獻推薦效果。
2 圖書館用戶畫像模型構建
2.1 圖書館用戶畫像數據源
圖書館構建用戶畫像模型是指根據用戶使用網絡系統、數字圖書館、智慧圖書館產生的行為數據、運動軌跡對用戶行為偏好高度還原,采集的數據都與用戶行為有關。在圖書館服務中,用戶畫像數據處于多重系統網絡中,各類數據相互獨立,缺乏關聯[3]。在構建用戶畫像模型前,先要根據用戶信息、行為數據對用戶行為偏好進行初步刻畫,建立簡易的用戶畫像,后期通過抓取用戶大量的行為軌跡及網絡日志數據進行畫像完善,并建立完善的標簽系統。用戶畫像使用的用戶數據可分為直接數據和關聯數據。直接數據包括用戶年齡、學歷、性別、家庭、專業等基礎信息;關聯數據包括用戶的行為動態、心理活動、情緒變化、閱讀方式、知識獲取程度、網絡數據、網站瀏覽軌跡等數據。
2.2 用戶畫像模型
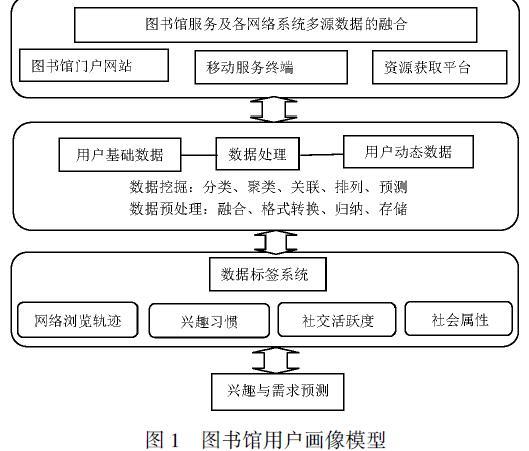
圖書館可以借助大數據系統進行數據分析與挖掘,并利用數據標簽進行標記,然后根據用戶特征建立標簽系統,再依托標簽系統精準定位個體用戶及用戶群,從而建立描述用戶個性化需求、個性特征及行為偏好的畫像(見圖1)。
首先,圖書館要對用戶使用圖書館過程中產生的各類數據進行融合和分析,如:使用爬蟲工具、文本挖掘技術等對圖書館信息門戶網站、圖書館線上信息服務系統、移動服務終端、線上知識庫系統、信息處理系統、用戶訪問模塊中的各類數據進行抓取,然后按照一定的數據獲取規則及篩選標準對用戶的基本信息及使用圖書館系統產生的各類行為數據進行整合歸類,形成結構化的數據信息,再對獲取的大數據進行清洗、轉換等預處理,并進行深度聚類、結構化處理、深度挖掘,最后建成完整的分析機制[4]。其次,要建立完善的用戶標簽體系。用戶畫像標簽是建立用戶畫像模型的核心步驟,是大數據環境下對用戶基礎數據、行為數據進行數字化抽象統計分析的信息,能有效反映出用戶的特征和行為偏好。建立多種標簽對關鍵數據進行標記,能更直觀地反映出用戶的行為偏好特征。再次,根據個體用戶及用戶群的需求偏好及特征向量,依靠用戶畫像建立反映個體用戶及用戶群的服務預測機制,即依靠清晰的畫像描述反映個體用戶與用戶群的需求變化,再根據用戶這種需求變化趨勢向用戶主動推送學術文獻。值得注意的是,在圖書館學術服務中,用戶的興趣、行為偏好并不是固定的,而是會伴隨用戶的教育背景、職業經歷發生變化,這就需要圖書館根據用戶的興趣、行為偏好及時優化與調整用戶畫像。
3 大數據環境下基于用戶畫像的學術文獻推薦系統構建
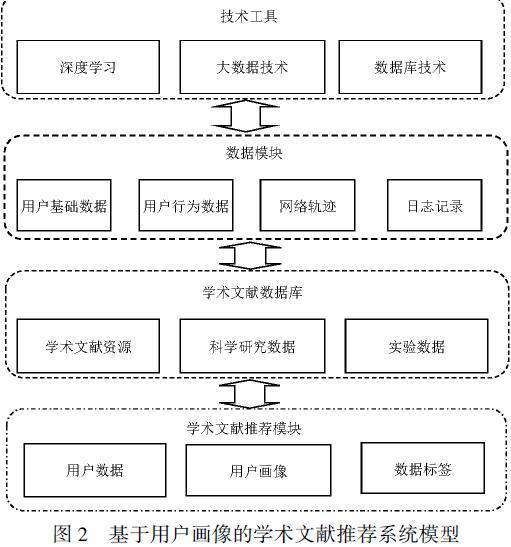
通過對用戶基本信息和行為數據的搜集、提取、分析、挖掘建立起反映用戶行為偏好、個性化特征的畫像模型,可以實現資源的精準匹配、個性化推薦及需求的科學預測。基于此,基于用戶畫像的學術文獻推薦系統可由技術工具、數據模塊、用戶畫像模型及學術文獻資源推薦模塊組成(見圖2)。
3.1 技術工具
圖書館構建基于用戶畫像的學術文獻推薦系統會應用到一系列的技術工具。圖書館先要對用戶使用圖書館系統產生的底層數據進行搜集分析,將數據轉變成可供系統識別與運用的特征向量,并增加相關的特征標簽,使基于用戶基礎信息與行為數據的畫像更加豐富。對于初次使用系統的新用戶,系統雖然無法準確判斷用戶的行為、興趣偏好,但可以根據用戶的注冊信息將反映用戶動態變化的數據組合成不同的數據集,使多種數據集中的元素盡可能地反映用戶的特征與行為偏好,然后使用大數據技術對用戶可能產生的需求進行精準預測,以實現用戶需求的智能識別及學術文獻的精準推薦。
3.2 數據模塊
基于用戶畫像的學術文獻推薦系統構建需要在底層建立數據搜集模塊,也就是針對用戶使用圖書館時產生的基礎數據、行為數據及使用各類終端、瀏覽網站產生的網絡軌跡進行搜集,并使用爬蟲工具精準獲取各類數據,然后依靠大數據分析系統將各類數據進行結構化處理,從中提取反映用戶行為偏好、個人特征的個體或用戶群的數據信息,實現用戶學術文獻需求的精準判斷。數據模塊要具備篩選過濾功能,在爬蟲工具爬取用戶各類信息的時候,能智能過濾各種無效信息,智能攔截惡意點擊與含有病毒的
數據流,并能構建智能防火墻抵擋病毒攻擊,保障用戶數據安全。同時,數據模塊要與數據庫關聯,將反映用戶特征、行為偏好的結構化數據存儲到數據庫中,并以有效的數據化標簽進行標記,同時,將反映用戶行為特征向量的數據存儲到單獨的數據庫中,以便于智能識別用戶身份。
3.3 學術文獻數據庫
在大數據環境下,圖書館基于用戶畫像為用戶推薦學術文獻,先要建立學術文獻數據庫對各類館藏學術文獻進行數字化分類存儲,為學術文獻推薦服務提供保障。充足的學術文獻資源是學術文獻推薦的基礎,圖書館應使用數字化技術對館藏實體學術文獻進行數字化處理,并依照圖書分類標準將其存儲到不同的館藏數據庫中。數字化的學術文獻資源不僅有利于共享傳遞,還能節約館藏成本,便于用戶高效獲取。
3.4 學術文獻推薦模塊
學術文獻推薦是在用戶行為數據搜集、用戶畫像勾勒完成后實現的,是指依靠圖書館構建的用戶畫像模型預測用戶的需求偏好及未來可能產生的學術文獻需求為用戶推薦學術文獻。為了提高推薦的精準性,圖書館要依靠標簽系統對用戶數據做標記,再根據標記的用戶數據分析個體用戶以及用戶群的行為偏好,將具有相似需求的群體用戶、個體用戶與學術資源進行匹配,并根據匹配程度反饋推送結果。由于不同個體用戶的需求不同,并且這種需求隨著時間的推移處在動態變化中,為了更高效地滿足用戶需求,學術文獻推薦模塊需設置個體用戶推薦窗口、用戶群推薦窗口兩個部分,針對用戶個體和用戶群分別推薦學術文獻。為應對用戶的興趣轉移和需求變化,學術文獻推薦模塊要設置用戶需求變化預測機制和興趣轉移預測機制,對用戶興趣需求變化進行精準預測,只有掌握用戶的動態變化才能實現學術文獻的精準推薦。
4 結語
大數據環境下基于用戶畫像的學術文獻推薦系統研究給圖書館學術服務、資源推薦帶來了新的突破。基于用戶畫像對用戶行為偏好、需求變化進行的定位與預測,能從多個維度實現用戶需求的動態掌握,最終實現學術文獻的精準推薦。
參考文獻:
[1] 袁軍.大數據環境下用戶畫像在高校圖書館的應用研究[J].圖書館研究與工作,2019(6):22-26.
[2] 梁榮賢.基于用戶畫像的圖書館精準信息服務研究[J].圖書館工作與研究,2019(4):65-69.
[3] 陳丹,羅燁,吳智勤.基于大數據挖掘和用戶畫像的高校圖書館個性化服務研究[J].圖書館研究與工作,2019(4):50-53,59.
[4] 李雅.基于讀者用戶畫像的高校圖書館精準化服務研究[J].農業圖書情報學刊,2018(12):108-111.
(編校:周雪芹)
收稿日期:2019-11-05
作者簡介:劉相金(1964— ),山東大學圖書館副教授;王夢菊(1964— ),山東大學圖書館副研究館員,系本文通訊作者。
