人工神經網絡在數據挖掘中的應用研究
2019-02-07 05:37:29梁春華
無線互聯科技 2019年22期
梁春華
摘? ?要:文章從數據挖掘基本概念和相關功能特點入手,闡述了人工神經網絡技術的相關概念和應用優勢。同時,重點以BP網絡模型為例,從工作原理、實現算法、工作流程等方面,深入分析人工神經網絡在數據挖掘中的應用要點。
關鍵詞:人工神經網絡;數據挖掘;應用
近年來,全球信息化技術發展進入到了新階段,數據挖掘技術開始進入到廣大普通企業當中,幫助企業執行數據庫分析和數據應用工作。數據挖掘旨在從大量數據中提取有價值的信息,對“互聯網+”時代各企業分析市場、制定策略有關鍵指導意義。近年業界提出的人工神經網絡理論吸引了大量從業者關注,充分結合了數據庫技術和人工智能,具備很好的應用前景。
1? ? 數據挖掘的基本概念與功能
1.1? 概念
目前,各行業、各企業單位會根據經營情況建立數據資源庫。隨著市場發展和經營方式多元化,數據庫中收集和儲存的數據信息越來越多,企業面臨著在龐大數據庫中難以快速、精準找到有應用價值信息的難題。隨著時代的發展,人們對相關數據的種類和呈現形式有更多要求,例如,企業市場部人員不再是僅關注銷售數據,還會對客戶購買頻率、時間、評價反饋等細節性信息有很高需求。顯然,如今傳統結構化、查詢語言已經不能滿足日漸增長且多樣化的信息數據需求,急需更先進的數據挖掘技術提供支持。數據挖掘的關鍵在于從龐大且復雜的數據庫中找到有隱性價值的數據信息,經過提取處理后給用戶帶來更多實用價值[1]。
1.2? 功能
簡單來講,數據庫挖掘主要功能有兩種:描述現在和預測未來。只有從現有數據中發現規律和價值,才能成功提取、分析出為未來發展工作提供依據、制定策略的信息。數據挖掘重點在于從數據庫找到相關數據,形成描述數據集合、預測發展趨勢的數據模型,其中,用到的分類法重點在于對數據離散類別進行描述,預測法則是基于數據規律對其連續進行預測,可見預測是數據挖掘技術中的關鍵功能。
2? ? 人工神經網絡的基本理論
顧名思義,人工神經網絡的參照物是生物神經系統,相關技術專家依照生物神經網絡架構、工作方式和支配管理機制,在信息數據領域進行人工模擬。人工神經網絡即通過建立大量處理單元,組成非線性自適應動態系統,該系統可以對大量數據進行統一或精細化管理,同時具有抽象分析、聯想記憶、自適應能力。與生物神經網絡中的神經元相似的是,人工神經網絡也擁有自學能力,加上該技術人工介入和干預很少,是信息技術領域中智能化的代表。在人工神經網絡體系中,各系統會對數據進行分析,發掘其中規律,神經網絡在發掘和學習過程中,基于相關邏輯規則自動調節神經元輸入、輸出機制,呈現某種數據信息規律。
3? ? 基于人工神經網絡數據的數據挖掘算法
3.1? 數據挖掘中典型的神經網絡模型
目前,在全球范圍內數據挖掘領域中比較常見的人工神經網絡模型包括反向傳播(Back Propagation,BP)網絡、循環BP網絡、自組織映射(Self-Organizing Maps,SOM)網絡、徑向基函數(Radical Basis Function,RBF)網絡等,這些模型是組成人工神經網絡的框架和基礎,是實現數據挖掘與智能分析應用的關鍵。
3.1.1? BP網絡模型
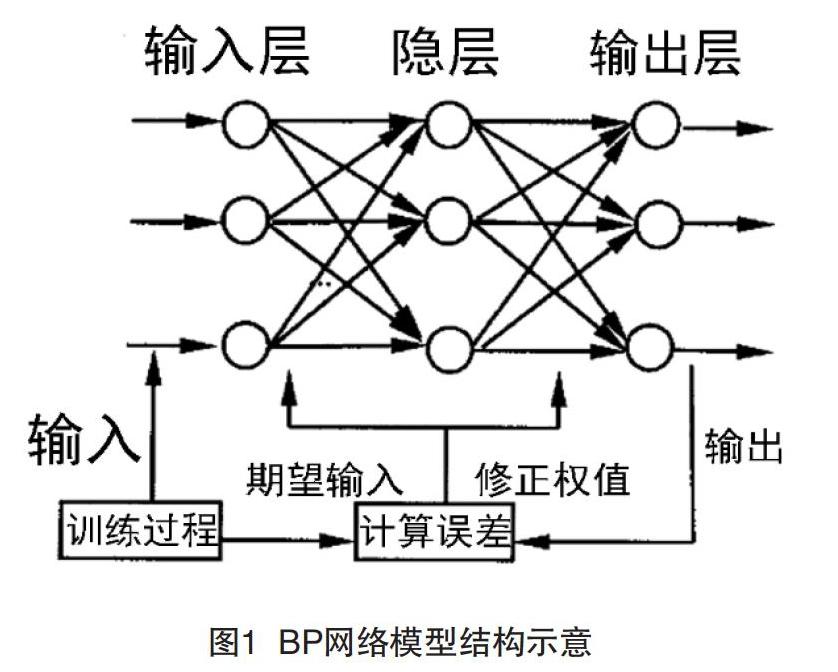
BP網絡模型主要構成要素包括輸入層、輸出層及中間層,整體構架屬于多層向前的拓撲形狀,可以應對大量輸入參數形成的復雜局面,并通過一定機制實現簡化。這種模型在知識發現(Knowledge Discovery in Database,KDD)任務中有大量應用,在非線性映射問題研究等方面也有較高的應用價值。例如,基于BP網絡模型可以實現多類型數據壓縮、圖像處理、手寫文字識別分析等。
3.1.2? RBF網絡模型
在RBF人工神經網絡模型中,主要是將非線性傳輸函數應用于隱單元中,如果隱層單元的矢量處于確定狀態,網絡則僅需修正引出線能至輸出層的單層權值。顯然,這種結構模型在收斂速度效率方面具備更高水平。作為前饋網絡的典型,RBF網絡在很多領域都有極高的應用價值[2]。
3.1.3? Hopfield網絡模型
Hopfield網絡模型理論架構于1984年被提出,主要架構基礎是S型神經元,架構機制為單層全互聯反饋動力學系統,具備連續性和精確定位特點,可以對系統狀態空間的平衡點進行快速收斂。這種人工神經網絡模型主要適用于數據庫優化計算,廣泛應用于系統優化領域。
在這些網絡模型當中,如果KDD目標在于預測時間序列,那么循環BP網絡本身的完善性和運行機制具備更高的應用價值;如果對人工神經網絡模型自我學習能力有更高要求,RBF在訓練數據模擬和執行方面的優勢則比較突出。
3.2? 人工神經網絡的實現算法
目前,BP神經網絡模型在我國多個地區和產業、領域中有大量應用,雖然具備穩定性強、覆蓋面廣等優勢,但同時也存在動態信息處理能力缺失、泛化能力差等缺點,下面本文就分析BP神經網絡模型在數據挖掘中的應用要點。
3.2.1? 工作原理
如圖1所示,BP神經網絡模型主要以誤差反向傳播算法為基礎,該算法在多層向前神經網絡當中應用非常廣泛。該算法多個層次神經元互為連接關系,層次內部神經元則相互獨立。在該算法當中,網絡計算起始點為輸出層,再由此向前逐漸傳遞,整個過程中信息沒有反饋操作,需要以專業方法對網絡進行訓練,一般是基于一套由輸入數據及理想數據構成的訓練樣本來實現網絡訓練。在訓練過程中,如果輸入樣本與理想樣本保持一致,則證明數據算法運行良好;反之,則需要對權值進行調整優化,直到其保持一致。
3.2.2? 工作流程
在BP神經網絡模型中,正常工作開展一般由工作階段和學習階段組成。工作階段中各個網絡節點連接權值是保持不變的,網絡計算依然自輸入層向每一個節點輸出值開展計算,確保每一個節點都計算完畢。學習階段則是在模型中各節點輸出保持固定的情況下,由輸出層反向推算各節點連接權值的修改量,逐步優化各個連接權值。在該人工神經網絡模型中,兩個階段相輔相成,前者旨在計算分析網絡輸出量和相關數值是否達到期望值,如果沒有,則由后者對其進行修正,盡量減小誤差。BP神經網絡就是通過反復計算和修正,確保網絡架構趨于穩定、輸出層的輸出值達到期望標準[3]。
BP神經網絡模型中,輸入層的各個節點主要工作是規格化處理相關樣本數據,而一般在第二層至最后一層之間才是進行網絡計算和處理分析的重要領域。一般情況下,大多數數據庫中都會將各個處理節點中的閾值作為單個連接權值,目的主要是簡化計算,便于人工查詢和分析模型運行狀態。一般人們會通過連接處理節點和虛節點,來達到簡化計算的目的。在BP人工神經網絡模型的計算階段,計算過程和處理過程描述基本上能夠保持一致,而在網絡學習過程中,重點在于精確發現輸出層實際輸出和期望標準值存在的誤差,再基于輸出層來調整節點連接權值。顯然,該模型的運行機制可以對數據計算和網絡計算狀態進行多次反復驗證和審查,對輸出數據準確性以及是否達標進行實時自我評估,讓整個網絡數據模型具備自我評估、自我調整、優化輸出的能力,進而全面提升數據信息輸出效率和質量。
4? ? 結語
綜上所述,當前以及未來的社會是一個基于互聯網和信息化的大數據時代,數據的分析處理成為各個行業關注的重點。數據挖掘在數據爆炸的時代當中,是人們從紛繁復雜的龐大數據庫中找到潛在規律、發掘有價值的信息、預估市場未來動向的重要手段。在傳統數據挖掘手段已經不適用于當代及未來社會的情況下,具備更高自主性、全面性、精細化和智能化優勢的人工神經網絡模型被提出。從我國當前相關領域技術發展現狀來看,需要進一步對BP,RBF,Hopfield,SOM等多種全球知名人工神經網絡模型及技術進行分析研究,通過實踐確定更適合我國各產業實際情況和應用前景的技術類型,全面提升我國各產業數據分析和價值挖掘能力,進而推動相關產業全方位、可持續發展。
[參考文獻]
[1]溫沁雪,李奕芯,楊碩,等.基于數據挖掘和人工神經網絡的厭氧產氣模型構建[J].中國給水排水,2019(1):77-81.
[2]邱明月,王新猛,唐松澤.基于人工神經網絡模型的搶劫犯罪微觀研究[J].信息技術與信息化,2018(10):140-143.
[3]張斌.數據挖掘在廈門第二西通道雙連拱隧道圍巖變形中的應用研究[J].施工技術,2019(13):90-93.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
考試周刊(2016年76期)2016-10-09 08:45:44
科技視界(2016年20期)2016-09-29 14:22:00
科技視界(2016年20期)2016-09-29 12:03:12
科技視界(2016年20期)2016-09-29 11:47:01
科技視界(2016年20期)2016-09-29 11:02:20
大眾理財顧問(2016年8期)2016-09-28 13:45:18
信息通信技術(2015年6期)2015-12-26 01:16:46
