Softmax分類器深度學習圖像分類方法應用綜述
2019-02-10 08:54:04盛明偉秦洪德唐松奇
導航與控制 2019年6期
萬 磊,佟 鑫,盛明偉,秦洪德,唐松奇
(哈爾濱工程大學水下機器人技術重點實驗室,哈爾濱150001)
0 引言
圖像分類是把圖像中不同目標區分出來的一種圖像處理方法,是計算機進行視覺判讀的重要手段。隨著互聯網技術的迅速發展及計算機能力的大幅提升,圖像數據的規模逐漸壯大,對圖像分類算法的性能要求不斷提高。近幾年,基于深度學習的圖像分類方法取得了突破性進展,并廣泛應用于人臉識別[1]、衛星遙感[2]、醫療診斷[3]、自主導航[4]及人機交互[5]等領域。基于深度學習的圖像分類方法實現了交通安全監控與管理、意外事故檢測及處理、犯罪跟蹤、安全解鎖以及自主導航等功能,其具體應用分類如表1所示。在深度學習圖像分類算法中,Softmax回歸(Softmax Re?gression,SR)起到了學習已知數據、預測未知數據的作用,是算法中必不可少的環節。
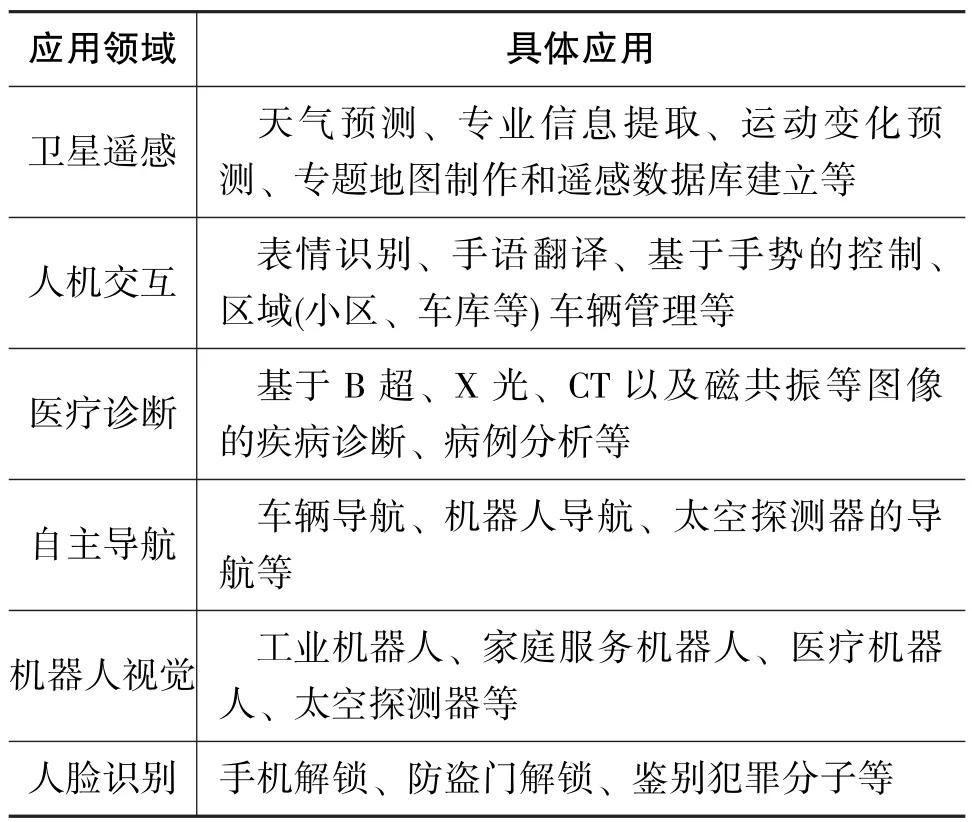
表1 基于深度學習的圖像分類應用領域Table 1 Applications of image classification based on deep learning
傳統的圖像分類技術包括基于色彩、紋理、形狀及空間關系等特征的分類技術,這些傳統技術對目標間具有明顯特征區別的圖像有作用,但無法滿足當前信息龐大的處理需求。2010年以后,深度學習逐漸成為圖像分類領域的熱門研究課題,國外的科研人員開展了大量研究工作。Ratle等[6]提出了基于神經網絡的半監督圖像分類框架,嵌入正則化產生一個操作分類器,用于解決遙感圖像分類問題。Vincent等[7]提出了一種堆疊去噪自動編碼器(Stacked Denoising Autoencoders,SDA)無監督分類算法,對輸入的損壞樣本去噪處理,采用無監督訓練提高了后續支持向量機(Support Vector Machine,SVM)分類器性能。Krizhevsky等[8]提出了大型深層卷積神經網絡模型 AlexNet,包括5個卷積層、3個全連接層和Softmax分類層,是近年來最受歡迎的圖像分類模型之一,該成果在2012年獲得了ImageNet ILSVRC競賽的冠軍。ImageNet ILSVRC 2014 年的冠軍由 Szegedy 等[9]獲得,他們提出了一個22層卷積神經網絡模型GoogleNet,增加網絡深度的同時降低維度,并采用平均池化層代替全連接層與Softmx分類器連接,實現了用極深網絡進行圖像分類。
國內在圖像分類領域的技術發展同樣迅速,Zhang等[10]提出了一種新的基于Softmax回歸的深度置信網絡(Deep Belief Network,DBN)半監督學習算法,用來解決標簽數據不足時的人臉識別問題。He等[11]提出了一個殘差學習框架來簡化大深度網絡訓練(ResNet),該技術不僅獲得了ImageNet ILS?VRC 2015年競賽的冠軍算法,也在同一年獲得了COCO競賽的冠軍。Zhong等[12]提出了一種新的條件隨機場(Conditional Random Field,CRF)模型,基于深度置信網絡聯合訓練進行高光譜圖像分類。除此之外,國內越來越多的團隊取得了優秀成果并獲得了國際圖像分類算法類比賽的冠軍,如商湯和港中文、海康威視等。
分類器作為圖像分類的一項關鍵技術,種類繁多,常見的有支持向量機(SVM)、K近鄰、隨機森林以及Softmax分類器,各分類器的優缺點如表2所示。SVM雖然在處理小樣本、非線性及高維模式識別問題時表現出特有優勢,但是對于較復雜分類問題其分類精度不高,且對當前大數據分類的處理代價太大[13];K近臨的算法過程簡單且易于理解,但K近臨屬于一種懶散學習法,當數據分布不均時,分類誤差率將會增加,識別準確率低,且其分類過程計算的復雜度大[14];隨機森林對于多維特征的數據集分類具有運算能力強、精度高、訓練速度快、丟失一些特征不影響結果等優勢,但隨機森林在某些噪音相對較大的分類問題上會產生過擬合,造成識別效果不佳,這限制了其在復雜圖像分類問題上的應用[15]。這些弊端導致上述3種分類器在應用上具有一定的局限性。
Softmax分類器具有分類種類多、應用簡單、準確率高、好訓練等優點[16],其結合深度模型進行圖像分類的算法逐漸占據了圖像分類算法的主流,使深度模型的分類準確率不斷提高。目前,簡單的圖像數據集如手寫數字庫(MNIST)的分類準確率已達到99%以上,大部分圖像分類的準確率也都在90%以上。取得如此高的分類準確率,一方面是由于深度模型的出現和應用,另一方面也是由于算法中包含的Softmax分類器效率較高。由此可見,Softmax在圖像分類領域占據重要位置,對其研究和改進對提高圖像的分類效果具有十分重要的意義。
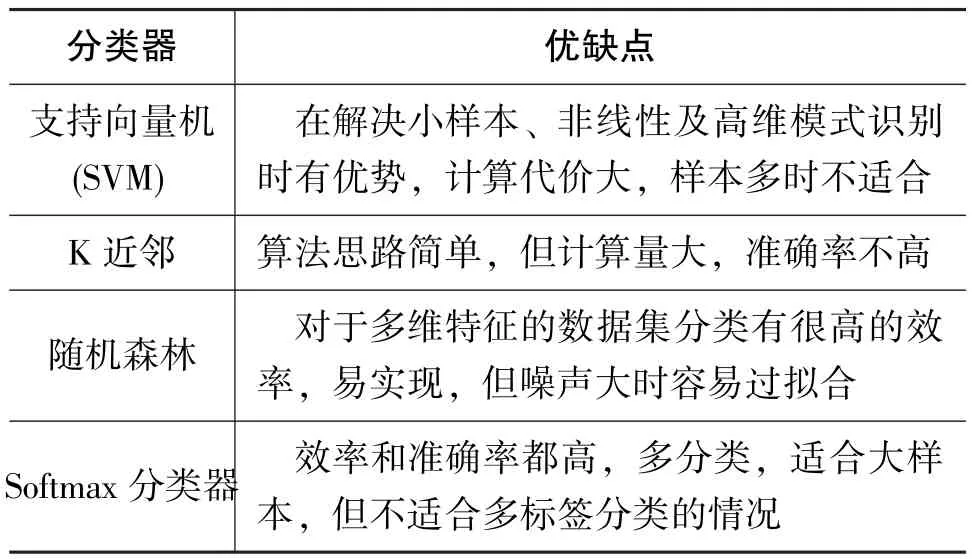
表2 多種分類器比較Table 2 Comparison of various classifiers
1 Softmax分類器原理
Softmax分類器原理較簡單,是一個概率計算過程。神經網絡對圖像進行分類時,輸入圖像經過神經網絡特征提取后傳入分類器,由Softmax分類器訓練后可獲得參數矩陣θ,θ與圖像特征列向量相乘,輸出該圖像分屬各類的概率值。其中,最大值對應類別即為該圖像的判定類別。
如圖1所示,所展示的是一個典型的簡單三分類結構,該神經網絡包含了輸入層、兩個特征提取層和分類輸出層。輸入特征經過兩個特征提取層獲得提取后的特征向量,傳入Softmax分類器經過矩陣相乘計算,輸出屬于三種類別的概率。這三個概率和為1準則不變,若輸出概率為[0,0.14,0.86],則輸入的所屬類別為2。
Softmax回歸是邏輯回歸(Logistic Regression,LR)的一個擴展,與類別標簽只能取兩個的邏輯回歸分類不同,SR為類別標簽提供了更多可能,適用于多分類問題。Softmax分類器將輸入矢量從N維空間映射到類別,結果以概率的形式給出,公式如下所示
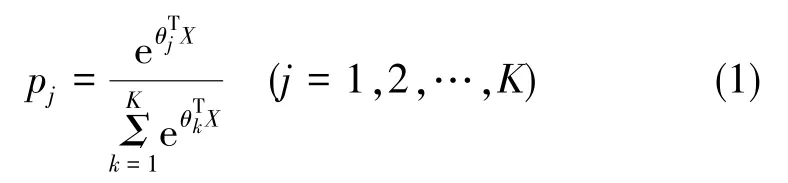
式(1)中,θk=[θk1θk2… θkK]T為權值,是類別所對應的分類器參數,總模型參數θ如下
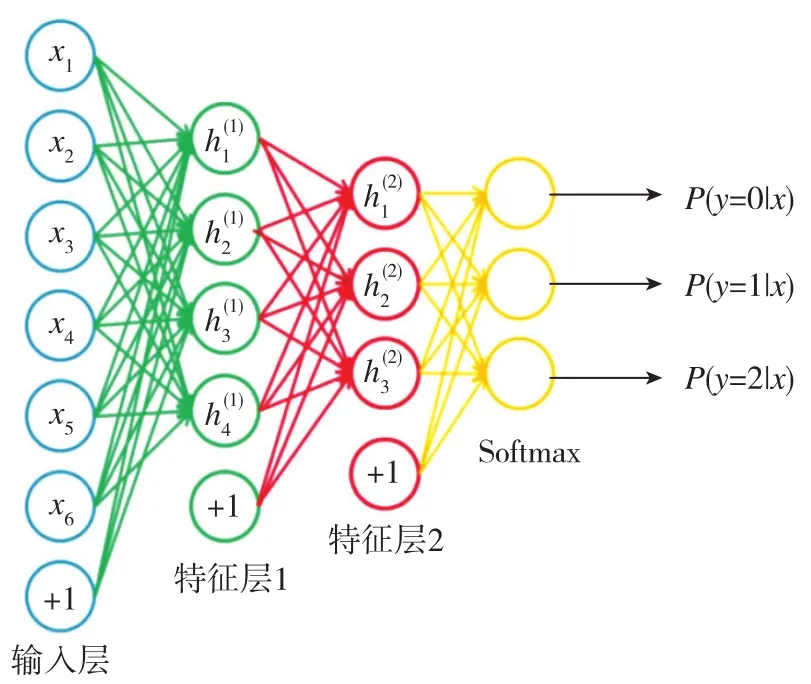
圖1 簡單三分類網絡結構Fig.1 Simple three classification network
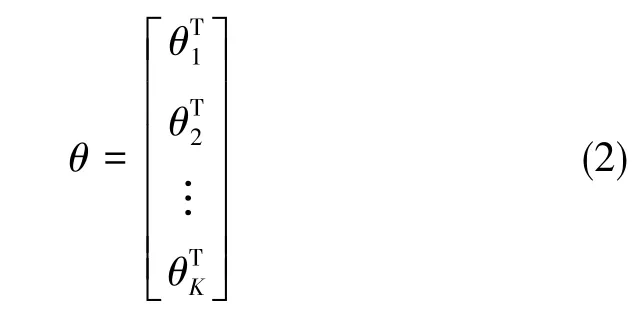
θ由Softmax分類器訓練獲得,作為參數可計算出待分類項的所有可能類別概率,進而確定其所屬類別。給定一個包括n個訓練樣本的數據集:{(x(1),y(1)),(x(2),y(2)),…,(x(n),y(n))},x代表輸入矢量,y為每個x的類別標簽。對于一個給定的測試樣本x(i),用 Softmax分類器估計其屬于每種類別的概率,函數公式如下
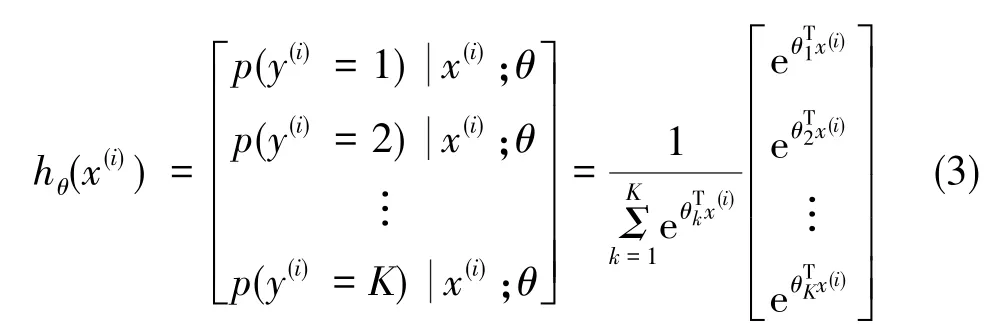
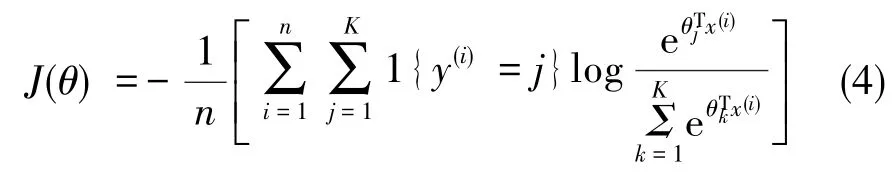
式(4)中,1{·}是一個指示性函數,值為真即等于1,值為假即等于0。令J(θ)最小化,即可得出分類器參數θ。
2 Softmax在深度學習圖像分類中的應用
自Softmax分類器問世以來,其在圖像分類領域的應用越來越廣泛,基于深度學習Softmax的圖像分類算法采用神經網絡模型與Softmax分類器級聯的形式實現圖像分類[17]。近年來,多種深度學習分類技術被專家、學者們提出用以解決各種圖像的分類問題,有些模型已投入到實際應用中,在某些類別的圖像分類領域,深度學習甚至令機器人的識別能力超過了肉眼。與Softmax分類器級聯的深度學習模型是對圖像進行特征表達的一種方式,保留圖像的有用信息,使圖像分類變得更簡單是模型的主要作用,下面詳細介紹幾種典型的深度學習分類技術。
2.1 Softmax在淺層神經網絡中的應用
淺層神經網絡即構造簡單的神經網絡模型,包含輸入層、隱含層和分類層三個部分。相鄰層的神經元間全連接,層內的神經元互相不連接,采用有監督或無監督的方法訓練以獲得分類結果。針對大數據圖像分類問題,淺層神經網絡分類識別技術的模型結構較簡單,易理解,但數據流大,學習速度慢,訓練容易陷入局部極小值。
BP神經網絡就是一種典型的淺層神經網絡模型,該網絡模型是一種多層前饋神經網絡,包括信息的前向傳遞和誤差的反向傳播兩個過程。信息的前向傳遞過程中,輸入信號經過輸入層、隱含層逐層傳遞到輸出層,計算誤差,與預測輸出進行比較。若輸出與預測不同,進入反饋狀態,通過反向傳播調整權值和閾值來減小輸出的預測誤差,使結果逐漸逼近預測輸出。基于BP神經網絡及Softmax回歸的分類方法的結構模型如圖2所示,ωij是輸入層和隱含層間的權值,θjk是隱含層和分類層間的參數,通過訓練分類器獲得。網絡模型隱含層的激勵函數一般取Sigmod函數,公式如下所示
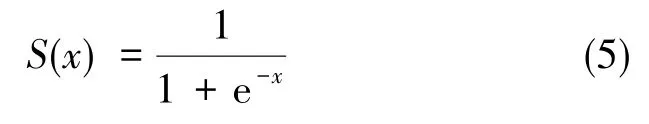
激勵函數是指隱含層的每個神經元的輸入和輸出間函數關系,由結點的輸入和權值、偏置參數計算,值在[0,1]之間,起到決定輸出的作用。
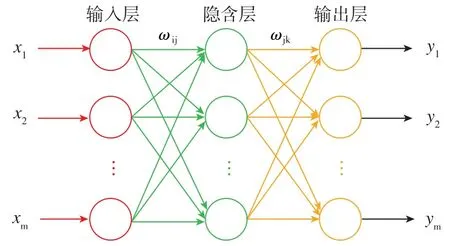
圖2 BP與Softmax級聯模型Fig.2 Cascade model of BP and Softmax
淺層神經網絡分類識別通常采用多層感知器進行特征提取,通過BP網絡算法進行訓練。汪海波等[18]就提出了一種基于主成份分析的人臉識別算法,其用到的模型通過 PCA層(感知器)與Softmax層連接,如圖3所示。在該結構中,PCA層得出的特征值和特征向量經過計算主要成分,得出保留特征向量后乘以權值W并加上截距b(W和b為PCA的訓練參數),再進行非線性變換作為SR層的輸入,采用反向傳播的訓練方法及先訓練Softmax分類器、再訓練整個網絡結構的方式進行分類訓練,得出訓練參數。除此之外,Lei等[19]提出了一種被稱為稀疏濾波的無監督兩層神經網絡模型,與Softmax分類器級聯用來解決機械故障診斷問題。這些算法充分說明了Softmax分類器與其他分類器相比,在圖像分類領域上具有優勢,這也是其成為當前主流分類器的原因。
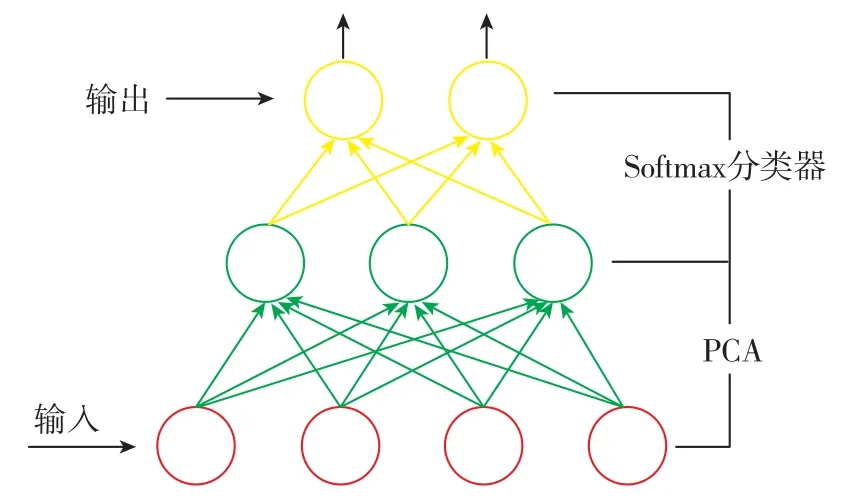
圖3 PCA與Softmax級聯模型Fig.3 Cascade model of PCA and Softmax
淺層神經網絡因網絡模型過于簡單的限制,特征提取效果較差。對于處理數據量小、類別數量少、環境單一、圖像特征明顯的圖像,速度和準確率可滿足實際需求。然而,其局限性在于在有限樣本和計算單元情況下對復雜函數的表示能力有限,針對復雜分類問題其泛化能力受到一定制約。
2.2 Softmax在深度置信網絡中的應用
深度置信網絡(DBN)是在2006年由Hinton提出的,開啟了深度學習的復興時代,其屬于一種生成模型,不僅可以用于特征識別、數據分類,還可以用來生成數據。該技術的訓練時間會顯著減少,只需要單個步驟就可以接近最大似然學習,但該結構也有可能會陷入局部最優。DBN是由受限玻爾茲曼機(Restricted Boltzmann Machine,RBM)堆疊組成的,RBM是一種二分類模型,只有一層可見層和一層隱藏層,是一種典型的基于能量的模型。所有可見層單元和隱藏層單元之間存在連接,而隱藏層內部和可見層內部不存在連接。經RBM堆疊的DBN是一種層次化的無向圖模型,其訓練過程主要是將第一個RBM的可見層作為輸入層,訓練一個RBM并將隱層單元的激活概率(權值)作為下一層RBM的輸入來訓練第二層RBM,第二層激活概率作為第三層RBM的可見層輸入,逐層訓練。通過這種逐層貪婪學習的無監督訓練,可得到比較好的特征。
深度置信網絡雖然在大量多分類問題上很少使用,但解決固定圖像分類問題上還是具有很高的應用價值。楊瑞等[20]在傳統深度置信網絡基礎上添加了一層Gabor特征融合層,對輸入圖像進行Gabor濾波,在進行卷積得到融合后特征再作為深度模型的輸入。深度模型結構如圖4所示,包含1個輸入層、3個隱藏層和1個基于Softmax分類器的輸出層。然后訓練第一層RBM,包括該層權值及類別標簽,對人臉圖像進行多尺度表達,第一層RBM的隱層向量由最大似然估計獲得。作為可見層的輸入,可通過調整參數使該層RBM趨于穩定,然后遞歸地逐層計算出每層RBM的隱層向量和權值以及各類別標簽,得到圖像的DBN特征描述。最后將DBN的輸出作為Softmax分類器的輸入,激活分類器,輸出設定類別標簽的概率。
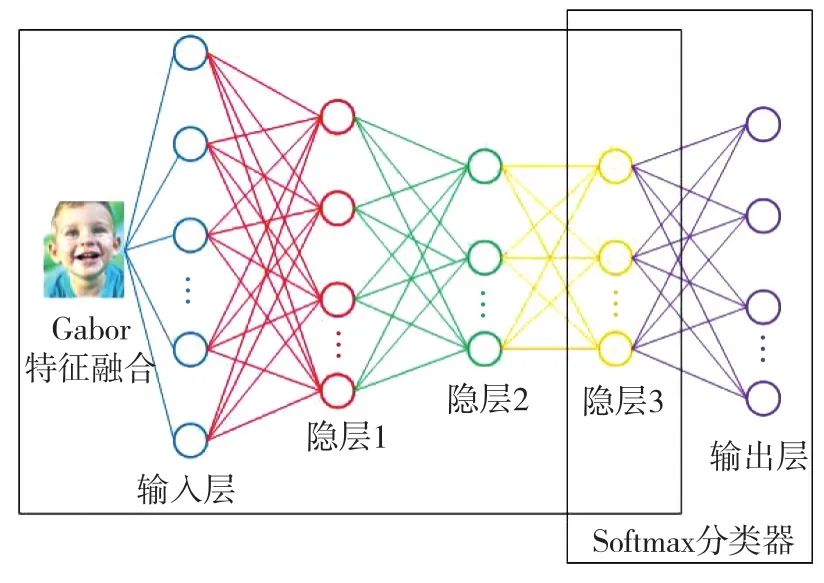
圖4 DBN與Softmax級聯模型Fig.4 Cascade model of DBN and Softmax
此外,Liao等[21]提出了一種基于 DBN 和Softmax分類器的圖像二值圖像檢索方法,采用BP算法進行權值調整,用Softmax分類器進行圖像分類,查詢圖像輸入返回為與其相似的圖像。Alam等[22]利用DBN生成權重初始化深度神經網絡(Deep Neural Network,DNN),建立DBM?DNN網絡模型,在頂部添加了Softmax分類層,解決了視聽生物特征識別問題。同時,該算法論證了Softmax分類器相較于SVM和線性回歸分類器(Linear Regression Classifier,LRC)的錯誤率更低,分類效果更好。而Ding等[23]針對DBN中普遍存在的過擬合問題,建立了基于最大似然估計的權重不確定性DBN模型,解決了過擬合問題的同時,又提高了DBN的圖像識別能力。Rasche等[24]又提出了巴氏涂片圖像深度置信網絡分類算法,該方法同樣應用Softmax分類器對巴氏涂片圖像分類,完成病灶判別。
DBN具有很高的靈活性,這使得它的拓展比較容易,在圖像分類的應用上較廣泛。然而,DBN在大數據訓練測試中的錯誤率較高,有待進一步研究。
2.3 Softmax在基于自編碼器網絡中的應用
自動編碼器于20世紀80年代被提出,是一種盡可能復現輸入信號的神經網絡。自動編碼器由編碼器和譯碼器組成,如圖5所示。將信息(input)輸入一個編碼器(encoder),就會得到一個代碼(code),若通過解碼器(decoder)輸出的信息和一開始的輸入信號信息很接近,這個代碼就屬于完全描述了圖像的。通過調整編碼器和解碼器的參數,使得重構誤差最小,誤差的來源就是直接重構后與原輸入相比得到的。自動編碼器屬于一種無監督特征學習單元,可以建立多層編碼器,更優化圖像信息特征,使圖像分類的特征更簡單清晰。之后,Softmax分類器在自動編碼器獲得圖像特征后,對這些信息進行不同方法的分類訓練以達到圖像分類的目的。例如,梯度下降法、最速下降法等。
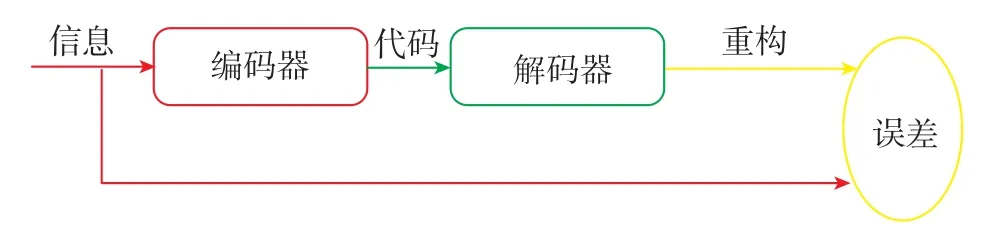
圖5 自編碼器Fig.5 Autoencoder
自編碼器在圖像分類領域的應用比2.1節和2.2節中的算法結構相對廣泛一些,Chen等[25]針對表情識別提出了一種深度稀疏自編碼器(DSAN)與Softmax級聯的模型,該模型結構如圖6所示。其中,hw,b(x)指Softmax分類器進行類別預測時對深度稀疏自編碼器的輸出數據通過權重相乘、偏置相加的計算獲得預測結果,wij、bj分別指網絡中的權重和偏置。深度稀疏自編碼器在自編碼器基礎上添加了稀疏性,抑制網絡結構隱層中的單元,可提高有用特征的提取能力。同時,該算法可通過優化稀疏參數來獲得隱藏層節點和隱藏層數以確定最佳網絡模型,通過GD方法訓練SR的最優模型參數,用BP算法對整個DSAN進行權重調整以增強面部情感識別性能。整個網絡自學習的特征在調整后看起來更加復雜,并且微調使總體成本函數收斂更快,克服了局部極值和梯度擴散的自編碼器常見問題。DSAN是一種HRI中完成面部情緒識別的有效方法,已實現了高興和生氣兩種情緒識別的人機交互。
此外,Hassan[26]等于 2017年針對醫學影像圖像提出了一種基于堆疊稀疏自動編碼器的分類結構模型。疊加學習的未標記圖像輸入像素的高級特征,區分包含各種局灶性肝臟疾病的圖像。所提出的系統由預處理階段以及使用水平集方法和模糊C均值聚類算法的肝臟病灶分割組成。最后,softmax層通過選擇每個類別的最高概率來區分不同的肝臟疾病。Badem等[27]又針對自動編碼器分類模型提出了新的訓練方法:基于混合人工蜂群的訓練策略(HABCbTS),用來調整結構參數。該策略將無導數的優化算法 “ABC”與基于導數的算法 “L?BFGS”結合起來進行訓練,性能優于L?BFGS、ABC和改進的ABC訓練的分類器。

圖6 DSAN與Softmax級聯模型Fig.6 Cascade model of DSAN and Softmax
自編碼器用于圖像分類一般采用堆疊形成深度模型,堆疊自動編碼器就是用自編碼器替換DBN里面的RBM,這就使得可以通過與DBN相同的規則來堆疊產生深度多層神經網絡架構,只是堆疊自編碼器缺少層的參數化的嚴格要求。與DBN不同的是,自動編碼器使用了判別模型,這就使得網絡較難捕捉圖像的特征。不過降噪自動編碼器卻能很好的避免這個問題,并且比傳統的DBN更優。自動編碼器同DBN一樣,同樣具有較好的開發空間。
2.4 Softmax在卷積神經網絡中的應用
卷積神經網絡(Convolutional Neural Network,CNN)[28]與其他神經網絡模型最大的區別是卷積神經網絡在神經網絡的輸入層前面連接了卷積層,這樣卷積層就變成了卷積神經網絡的數據輸入層。其學習過程是有監督的,濾波器權重可以根據數據與任務不斷進行調整,從而學習到更有意義的特征表達。卷積神經網絡可處理數據流大,分類效果極佳,近幾年廣泛應用于各個領域,甚至很多圖像分類競賽的冠軍算法均以卷積神經網絡為基礎。
卷積神經網絡的基本網絡結構可以分為四個部分:輸入層、卷積層、全連接層和輸出層。卷積層即為特征提取層,包括兩個部分:第一部分是真正的卷積層,主要作用是提取輸入數據特征;第二部分是pooling層,也叫下采樣層,主要目的是在保留有用信息的基礎上減少數據處理量,加快訓練網絡的速度。全連接層的神經節點都和前一層的每一個神經節點連接,層內神經元節點之間不連接。輸出層神經節點的數目是根據具體應用任務來設定的,如果是分類任務,卷積神經網絡輸出層通常是一個分類器。如采用Softmax分類器進行輸出分類,其神經元節點數即為所分類別數。
李宇等[29]用卷積神經網絡和Softmax級聯的模型進行了遙感圖像的檢索分類,如圖7所示,級聯模型包含了4個卷積層、3個池化層和1個全連接層。在此結構中的激活函數選用的是RELU函數,采用了最大池化方法,并在網絡中引入了Dropout層以防止過擬合問題,輸出層采用Softmax分類器對圖像進行分類,以識別出遙感圖像中的多個目標。
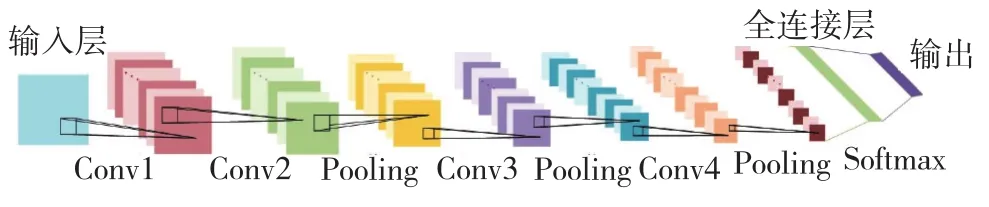
圖7 CNN與Softmax級聯模型Fig.7 Cascade model of CNN and Softmax
在此基礎上,Zhao等[30]于2017年提出了基于超像素的多重局部卷積神經網絡(SML?CNN)模型,提取有效的聯合特征表示,Softmax層將由多個CNN學習的特征分類成不同的類別。Choi[31]提出了一種卷積神經網絡(CNN)輸出優化方法來提高圖像分類中低精度類的精度。湯鵬杰等[32]設計了一種深度并行交叉CNN模型,該模型有兩條并行CNN提取深度特征,使用Softmax回歸對圖像進行分類識別。除以上對卷積神經網絡的優化,近幾年出現了很多新的卷積神經網絡模型,可實現大數據分類,且分類效果極佳,如VGG、LeNet、GoogleNet及ResNet等。這些網絡模型分別取得了圖像分類競賽近幾年的冠軍,也是目前深度學習檢測算法最常應用的網絡模型,且均采用Softmax作為分類器。
卷積神經網絡在圖像分類上表現驚人,能較好適應圖像結構,泛化能力強,在圖像特征表達及大數據上的分類表現普遍超過了上述所述的三種網絡模型,是目前學術界最常采用的神經網絡模型。該網絡模型深度及維度不易選擇定,圖像特征提取過程難以解讀,但這并不影響其在圖像分類上的優秀表現。
3 深度學習圖像分類器展望
圖像分類算法在工程應用上主要對目標進行特征識別,是目標檢測、跟蹤、定位等工作的基礎。在應用環境復雜多變、場景內類別數較多時,基于深度學習的圖像分類算法因其解決大數據多分類問題上的優勢獲得了廣泛認可。在場景固定、環境單一時,基于色彩、紋理、形狀及空間關系等圖像特征的傳統分類算法可以處理這類簡單圖像分類問題,但應用深度學習效果更優。在分類器方面,Softmax回歸分類器在圖像分類領域相比其他分類器表現出更好的性能:應用簡單、準確率高、適合大樣本、具有多分類功能。
然而,現有算法多局限于針對特定環境下的圖像多分類,對圖像中的目標特征要求高,較難實現對復雜環境下模糊、遠距離目標的識別。同時,基于深度學習的圖像分類算法在實時性上也很難保證。另外,Softmax回歸分類器因類別標簽每一維僅含有一個1的限制,導致其無法解決多標簽圖像分類問題。多標簽分類問題與多分類問題的主要區別在于:前者是每個實例對應多個標簽的分類問題,而后者指代每個實例對應單個標簽的分類問題。因此,復雜條件下的多分類、實時性保證及多標簽分類仍然是需要繼續努力的目標。據此,基于深度學習Softmax的圖像分類算法的主要發展趨勢如下:
(1)Softmax 回歸分類器
Softmax回歸分類器作為實現分類的關鍵步驟,起到了極其積極的作用,但仍需要繼續探索研究。在提高Softmax回歸分類器性能上,可從以下三方面著手:1)改進Softmax回歸分類器以提高性能:增加網絡層以聯合其他分類函數進行多層參數調整,提高精度;采用多個分類器搭建以解決多標簽圖像分類問題。2)提高訓練效果:調整Softmax函數,使其更易收斂;調整損失函數,增加訓練效率;尋找新的訓練算法以加快訓練速度,同時在保證分類性能的前提下減少參數。3)優化數據集:在對分類器進行訓練時,采用的數據庫多為公開的圖像數據集,但這些庫的數據采集過程具有人為選擇性,尤其是大部分測試庫和訓練庫都比較接近,用此類庫進行訓練和測試不具有代表性,其準確度會偏高。所以,對于圖像分類,未來的數據庫應盡量多元化、多清晰度、多來源、多數量,才能有效提高分類效果。
(2)深度學習網絡模型特征表達
深度學習應用于圖像分類上具有強大的學習能力,可深度挖掘隱含在圖像中的目標信息,卷積神經網絡表現尤其突出,應用廣泛。然而,深度學習網絡模型仍存在一些問題,如網絡模型的深度和維度如何確定、如何保證網絡模型的泛化能力、如何對模糊圖像進行特征提取、如何通過少量樣本準確抓取圖像特征等。因此,在模型上不僅要針對某指定問題找尋最佳網絡模型,還需提高模型的泛化能力及小樣本特征提取能力,使其不僅簡單的區分幾類物品。未來應像人眼一樣,對生活中遇到的所有類物品都具有學習識別以及跟蹤的能力,并不是像目前這樣針對某幾類圖像進行分類,應該達到真正意義上的人工智能。這方面的進一步研究將推進圖像處理領域的發展。
(3)高維數據分類
隨著圖像分類的領域發展,目前大數據多分類問題已不再是難題。隨著數據量的增加、多標簽的出現,高緯度數據的分類成為圖像分類領域又一個待攻克的課題,簡單深度網絡學習模型已經無法滿足要求。目前的普遍做法是考慮將多個分類器集成,以適應數據的維度變化,但集成分類器如何保證分類性能還未可知,亟待研究。此外,可選擇構建并行神經網絡或三維神經網絡以解決此類、甚至未來越發復雜的圖像處理問題。
4 結論
圖像分類技術在計算機視覺研究領域中具有十分重要的意義和應用價值,基于深度學習的網絡模型和最后一層的分類器直接影響著圖像分類的結果。本文面向Softmax分類器在深度學習智能識別算法中的應用,回顧了算法發展歷程,闡述了多種深度學習網絡模型及Softmax分類器在圖像分類上的具體表現。同時,對深度學習及Softmax分類器在圖像分類技術方面的未來應用與發展及其優化方式進行了展望。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
