帶有覆蓋率機制的文本摘要模型研究*
2019-02-13 06:58:58鞏軼凡劉紅巖岳永姣杜小勇
計算機與生活 2019年2期
鞏軼凡,劉紅巖,何 軍+,岳永姣,杜小勇
1.數據工程與知識工程教育部重點實驗室(中國人民大學 信息學院),北京 100872
2.清華大學 經濟管理學院,北京 100084
1 引言
隨著互聯網技術的快速發展,文本信息出現了爆炸式增長,各種網絡媒體如微信公眾號、新聞網站、微博等每天都會產生海量的信息。對于這些海量的信息,人們沒有足夠的精力去閱讀每一篇文本,信息過載成為一個嚴重的問題。因此,從文本信息中提取出關鍵的內容成為一個迫切的需求,而文本摘要技術則可以很好地解決這個問題。
目前的文本摘要主要是利用帶有注意力機制的序列到序列模型(sequence to sequence,Seq2Seq[1])對文本生成摘要,但是注意力機制在每個時刻的計算是獨立的,沒有考慮到之前時刻生成的文本信息,導致模型在生成文本時忽略了之前生成的內容,導致重復生成部分信息,最終生成的文本只包含了原始文本的部分信息。本文在注意力機制的基礎上,提出一種新的覆蓋率機制,記錄歷史的注意力權重信息,借此改變當前時刻注意力的權重分布,使模型盡可能地關注尚未利用到的信息,生成的摘要文本包含的信息更準確。
本文的主要貢獻如下:
(1)在文本摘要的經典模型中引入一種新的覆蓋率機制,使用覆蓋向量記錄歷史的注意力權重分布信息,解決注意力機制不考慮歷史時刻生成信息的問題。
(2)提出了兩種不同的衰減方法,降低輸入文本中部分位置的注意力權重,使模型盡可能地關注尚未利用到的信息。
(3)所提方法在新浪微博數據集進行了實驗,實驗結果表明,基于本文提出的覆蓋率機制的文本摘要模型性能評價得分高于普通的Seq2Seq模型。
本文后續內容安排如下:第2章是相關工作部分,介紹了抽取式摘要和生成式摘要的相關工作。第3章是文本摘要模型部分,介紹本文所用的Seq2Seq模型和注意力機制。第4章介紹覆蓋率機制,介紹了注意力機制存在的問題和本文引入的覆蓋率機制。第5章是實驗部分,介紹了本文的實驗設計,并對實驗結果進行了分析。第6章是總結和對未來工作的展望。
2 相關工作
文本摘要任務按照所使用的方法,可分為抽取式(extractive)摘要和生成式(abstractive)摘要[2-4]。抽取式摘要是從原文中抽取出關鍵的詞或句子再組合起來;生成式摘要則要求對文本進行分析,理解文本所描述的內容,然后生成新的摘要句子。
抽取式摘要主要是利用機器學習的方法為原文中的每個句子做出評價,賦予一定的權重,從而選出比較重要的句子,把這些句子組合起來,由于句子之間可能存在信息冗余,因此在組合句子的同時還要消除這些冗余信息[5]。相比于生成式摘要,抽取式摘要的方法通常都比較簡單,缺點是比較依賴于特征工程,句子組合起來可能出現不連貫的問題。
隨著深度學習技術的發展和計算能力的提升,越來越多的研究人員開始將深度學習技術用在文本摘要任務的研究上。通過帶有注意力機制的Seq2Seq模型實現對文本生成摘要。Seq2Seq模型由一個Encoder和一個Decoder組成,Encoder把輸入序列編碼成語義向量c,Decoder從語義向量中c解碼出對應的序列。將原始文本輸入到Encoder中并編碼成語義向量c,Decoder從語義向量c中解碼出對應的摘要文本。
在Seq2Seq模型中,Encoder和Decoder一般由循環神經網絡(recurrent neural network,RNN)構成,語義向量c一般為Encoder最后一個時刻的隱藏層狀態向量。由于語義向量c的維度是固定的,當輸入文本過長時會出現信息損失的情況,文獻[6]在Seq2Seq模型的基礎上提出了注意力機制,通過在不同的時刻輸入不同的語義向量來解決這個問題,在機器翻譯任務上取得了很好的效果。文獻[7]提出了全局注意力(global attention)和局部注意力(local attention)機制,在全局注意力機制中給出了三種計算注意力權重的方法,對于過長的輸入文本提出局部注意力機制,大大減少了模型的計算量。
文獻[8]基于新浪微博構建了一個大規模的中文短文本摘要數據集,提出基于漢字的摘要模型和基于詞的摘要模型,搭配兩種網絡架構實現自動文本摘要,結果表明基于漢字的模型要優于基于詞的模型。文獻[9]在文本摘要任務上提出了拷貝機制,拷貝輸入序列的片段到輸出序列中,解決了文本摘要任務中OOV(out of vocabulary)的問題。文獻[10]在機器翻譯模型中引入了覆蓋率機制,記錄了翻譯過程中歷史注意力權重信息,使模型更多地關注沒有被翻譯到的詞,解決了機器翻譯任務上“過度翻譯”和“漏翻譯”的問題。文獻[11]在Seq2Seq模型的基礎上提出了推敲(deliberation)網絡,包括兩個解碼器,第一個解碼器生成原始的輸出,第二個解碼器根據輸入文本和第一個解碼器生成的原始輸出,推敲打磨生成更好的輸出文本。文獻[12]在文本摘要任務上引入了LVT(large vocabulary trick)技術解決Decoder生成文本時詞表過大的問題,在模型訓練時加入了一些其他的語言學特征來提升模型的性能,通過pointer[13]指針選擇輸入文本中的詞作為輸出解決OOV的問題。
由于注意力機制在不同時刻的計算是獨立的,沒有考慮歷史的注意力權重分布信息,因此在文本摘要任務上,Seq2Seq模型也會出現文獻[10]提到的問題,會重復生成部分信息,漏掉部分信息,導致生成的摘要只包含了輸入文本的部分信息。本文借鑒機器翻譯任務上的覆蓋率機制,提出一種新的覆蓋率機制,通過衰減方法降低輸入文本中部分位置的注意力權重,使模型盡可能地關注沒有利用到的信息。
3 Seq2Seq文本摘要模型
Seq2Seq文本摘要模型選擇使用長短時記憶網絡(long short term memory network,LSTM)作為Encoder和Decoder,其結構示意圖如圖1所示。
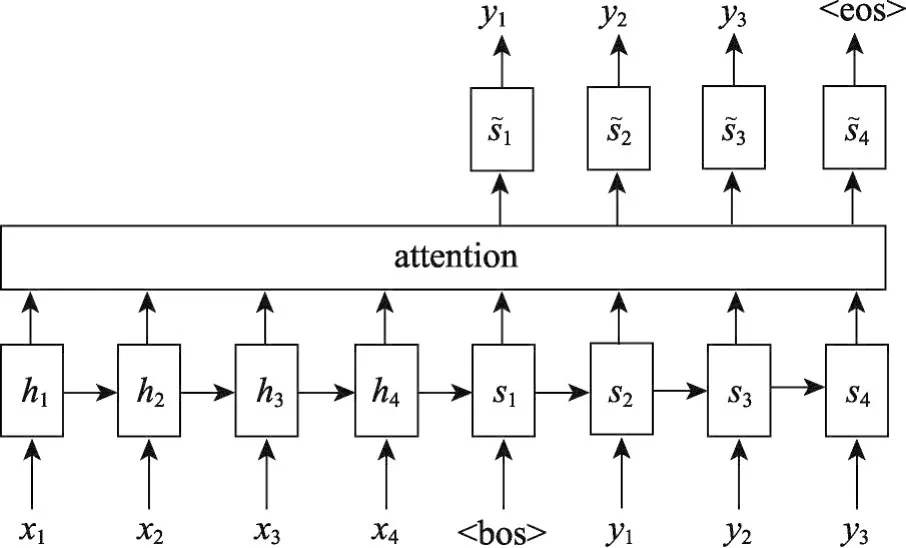
Fig.1 Text summarization model圖1 文本摘要模型示意圖
其中X={x1,x2,…,xn}表示輸入文本,xj代表輸入文本中的第j個字符,如一個詞或一個漢字,n為輸入文本的長度,Y={y1,y2,…,ym}表示對應的輸出文本,yi代表輸出文本中的第i個字符,如一個詞或一個漢字,m為輸出文本的長度。“<bos>”和“<eos>”分別代表Decoder開始解碼的字符和停止解碼的字符。Encoder對應的各個隱藏層狀態向量的集合為H={h1,h2,…,hn},Decoder對應的各個隱藏層狀態向量的集合為S={s1,s2,…,sm}:

f表示LSTM網絡,本文使用文獻[7]提出的注意力機制的計算方式,在不同時刻生成不同的語義向量ci,避免由固定的語義向量帶來的信息損失的問題。Decoder部分在時刻i對應的語義向量ci為:

其中,αij為歸一化后不同位置Encoder隱藏層狀態向量的注意力權重:

eij用來衡量Decoder隱藏層狀態向量和不同位置Encoder隱藏層狀態向量的相關性:

We為參數矩陣,將語義向量ci和Decoder的隱藏層狀態向量si拼接起來經過線性變換和激活函數后形成:

Wcs為參數矩陣。
模型生成字符的過程是一個多分類的問題,類別的個數為詞表中所有字符的個數,從詞表中選擇概率最大的字符作為時刻i的輸出。模型生成詞表中字符的概率分布yvocab的計算方式為:

Ws為參數矩陣,選擇yvocab中概率最大的字符yi-pre作為時刻i的輸出。采用交叉熵損失作為模型的損失函數進行學習:

模型通過梯度下降等方法對參數進行更新求解。模型在訓練階段,已經知道真正的輸出序列Y={y1,y2,…,ym},因此Decoder在時刻i的輸入為上一時刻真正的字符yi-1(teacher forcing)。模型在預測階段,不知道真正的輸出序列,因此Decoder在時刻i的輸入為上一時刻模型的輸出yi-pre。
4 覆蓋率機制
注意力機制把Encoder所有位置的隱藏層狀態向量加權和作為時刻i的語義向量ci,注意力權重αij越大,該位置j的隱藏層狀態向量在語義向量ci中所占的比重就越大,輸入xj為模型生成字符yi-pre貢獻的信息就越大。也就是說,模型在時刻i的注意力集中在該位置。
在注意力機制的計算中,不同時刻的注意力機制的計算是獨立的,注意力權重αij只與當前時刻Decoder隱藏層狀態向量si,Encoder隱藏層狀態向量hj有關,不會考慮歷史的注意力權重分布情況。因此模型在不同時刻可能會將注意力重復集中在某一位置,這就導致在生成的摘要文本中,出現重復生成部分信息和漏掉部分信息的情況。
表1是帶有注意力機制的Seq2Seq模型生成的摘要文本包含重復信息的樣例,可以看出,在生成的摘要文本中,重復生成了“預期”和“國際金價”的信息。分析模型在不同時刻注意力集中的位置可以發現,模型在生成第一個“國際金價”信息時,注意力集中在原文第42~45個字符“國際金價”的位置;在生成第二個“國際金價”信息時,注意力同樣集中在原文第42~45個字符“國際金價”的位置。也就是說,模型在這兩個時刻的注意力集中在相同的位置。
一個好的文本摘要模型,應該綜合考慮輸入文本中所有的信息,生成的摘要是對全部文本的一個總結。如果摘要模型把大部分注意力集中在部分位置,則生成的摘要不能包含所有的信息,還會出現信息重復的現象。因此在決定模型下一步注意力位置的時候,需要引入歷史生成的信息,從而避免再一次將模型的注意力集中到該位置。
因此,本文引入覆蓋率機制,通過coverage向量coveri={coveri1,coveri2,…,coverin}記錄i時刻之前的注意力權重信息,該向量維度與注意力向量維度相同,其中每個元素稱為覆蓋度,計算方法為:

Table 1 Summary containing duplicate information表1 包含重復信息的生成摘要
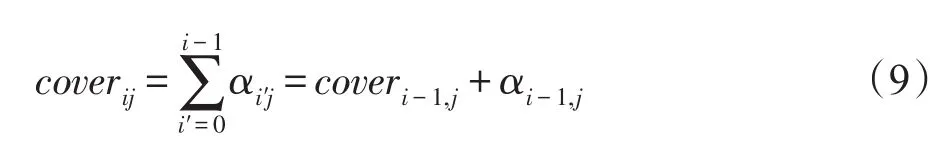
αi-1,j為i-1時刻位置j的注意力權重(計算見式(4));coverij記錄了歷史時刻位置j的注意力權重信息,表示i時刻之前模型位置j信息的使用情況。在初始時刻,cover0為零向量。
在模型生成摘要文本的過程中,注意力權重越大的地方貢獻的信息量越大,如果輸入文本的某個位置在當前時刻字符的生成時注意力權重很大,則在接下來的文本生成中注意力權重應該相對較小。基于以上思想,模型在時刻i計算注意力權重的時候,會對i時刻之前已經利用過信息的位置進行信息衰減,使模型更多地關注輸入文本中沒有用過的信息。
具體的,Decoder在生成時刻i的輸出時,需要對Encoder所有位置的隱藏層狀態向量H={h1,h2,…,hn}進行加權處理:

hj′為加權后新的Encoder隱藏層狀態向量;β為衰減因子,取值范圍為[1,10]。這步處理的目的在于,如果Encoder位置j的注意力權重在時刻i之前比較大,coverij的值就會比較大,通過exp(-βcoverij)乘上一個比較小的權重,這樣對其隱藏層狀態向量的作用就是衰減。衰減的程度與β有關,衰減因子β越大,對hj的衰減就越大。
若在時刻i,第j個輸入文本對應的覆蓋度的值coverij為0.3,當β=1時,該位置對應的hj′為原來的0.74;當β=5時,該位置對應的hj′為原來的0.22;當β=10時,該位置對應的hj′為原來的0.05。
除了對Encoder所有位置的隱藏層狀態向量H={h1,h2,…,hn}乘一個固定權重的方法外,本文還提出了另一種動態調整權重的方式:

其中,Wc為參數向量,由模型根據訓練數據自動學習得到,對Encoder隱藏層狀態向量的衰減方式由Wc決定。
圖2是帶有覆蓋率機制的文本摘要模型示意圖,模型采用雙向LSTM作為Encoder,在任何位置都可以同時利用上下文的信息。在計算注意力權重之前,通過coveri對Encoder隱藏層狀態向量進行衰減,然后在此基礎上計算eij′:
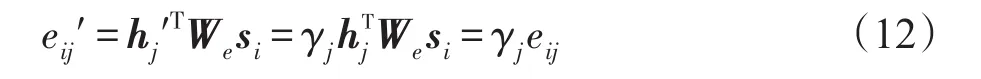
γj為Encoder隱藏層狀態向量的衰減權重,把eij′帶入式(4)中的eij,即可得到調整后的注意力權重αij,從而使coverij較大的位置對應的注意力權重降低,降低該位置的信息在語義向量ci中的比重,使模型更多地關注輸入文本中沒有用過的信息。
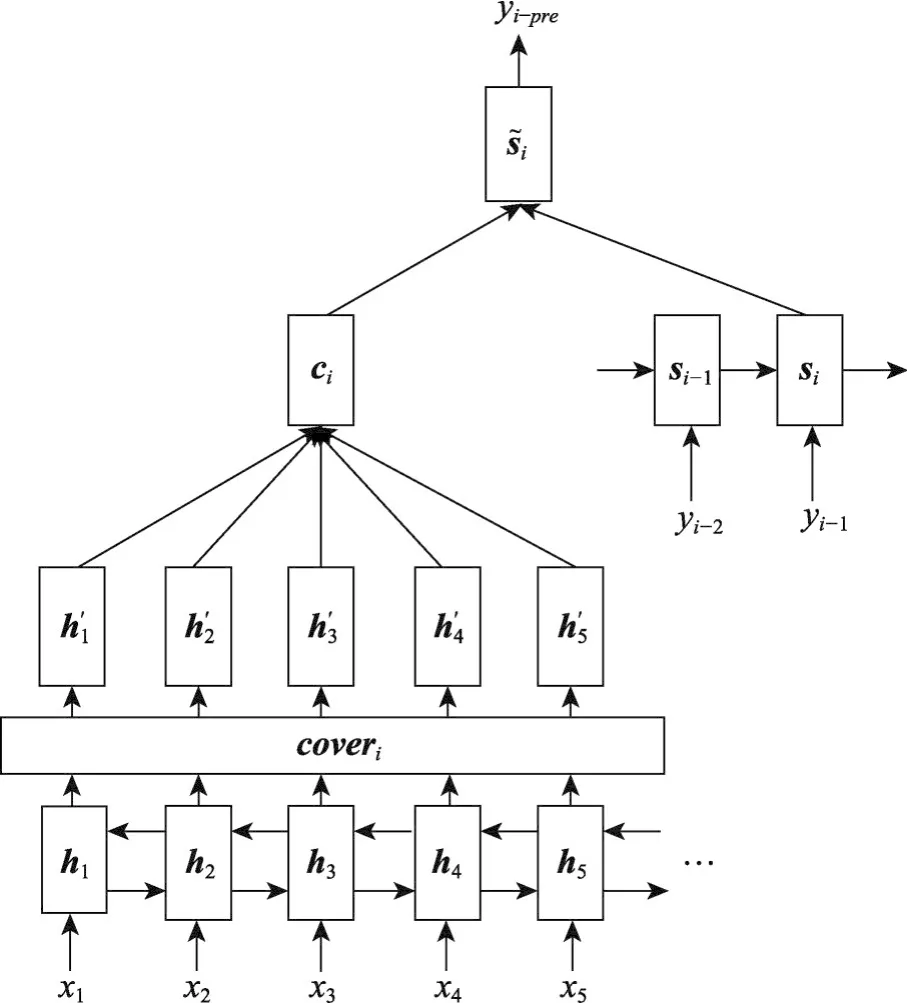
Fig.2 Text summarization model based on coverage圖2 帶覆蓋率機制的文本摘要模型示意圖
本文提出的帶有覆蓋率機制的文本摘要模型學習算法如算法1所示。其中,D={X1,X2,…,Xp}和S={Y1,Y2,…,Yp}分別代表訓練數據的輸入文本集合和摘要文本集合;p為訓練數據的條數;H′為經過coverage向量衰減后的Encoder隱藏層狀態向量集合;αi={αi1,αi2,…,αin}為時刻i所有位置Encoder隱藏層狀態向量的注意力權重的集合。
算法1模型學習算法
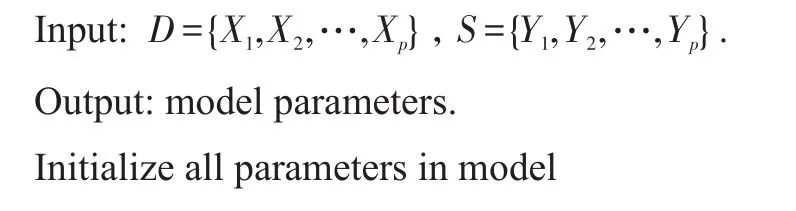

5 實驗
5.1 實驗數據
本文實驗所用的數據集來自于文獻[8]所提供的LCSTS(large-scale Chinese short text summarization dataset)數據集,數據集為微博文本和對應的摘要數據,分為PART I、PART II和 PART III三部分,其中PART I部分為主要的數據集,PART II部分的數據經過一人的人工評分,PART III部分的數據經過了三人的人工評分。人工評分的范圍為1~5,1表示非常不相關,5表示非常相關。數據分布如表2所示。

Table 2 LCSTS dataset表2 LCSTS數據集
在本文實驗中,選擇PART I中的部分數據共60萬條微博數據作為訓練數據,選擇PART III中人工評分大于3分的數據共725條微博數據作為測試數據。
5.2 數據預處理
對于LCSTS數據集,本文采用基于中文漢字字符的模型,將訓練數據按照漢字級別輸入到模型中,采用基于漢字的模型原因為:中文漢字的數量遠小于中文詞語的數量,可以減少模型的計算量,同時減少了生成文本中OOV的情況;而且基于中文詞語的模型的準確率還依賴于分詞工具的準確率,不恰當的分詞方式還會引入語義上的歧義。
同時,在詞表中加入四個新的字符:“<bos>”、“<eos>”、“<unk>”、“<pad>”。“<bos>”表示Decoder從語義向量c中解碼信息的開始字符,“<eos>”表示解碼的終止字符,“<unk>”表示未出現在詞表中的字符,“<pad>”表示將文本填充到統一長度的字符。
對訓練數據中Decoder端對應的摘要文本前加“<bos>”字符作為Decoder的啟動標志,在摘要文本末尾加“<eos>”作為解碼結束的標志,對于不在詞表中的字符,用“<unk>”字符代替。模型訓練時采用批梯度下降法(mini-batches learning)的方式學習參數,將一個batch內的文本通過“<pad>”填充到統一長度便于處理。隨機初始化中文字符的embedding表示,隨著模型的訓練對embedding向量進行學習。
5.3 實驗參數
在本次實驗中,覆蓋率機制的衰減因子β分別選擇1、5、10。中文字符詞典的大小選擇3 500,中文字符的embedding size為400,Encoder和Decoder共享中文字符詞典和embedding矩陣,LSTM隱藏層向量維度為500,batch的大小為64,梯度裁減的閾值為2,Decoder生成文本的最大長度為30,模型一共訓練30個epochs,使用梯度下降的方法對模型參數進行學習。選擇Pytorch深度學習框架搭建文本摘要模型[14],使用NVIDIATesla M60 GPU加速模型的訓練。
5.4 實驗結果
文獻[15]提出的ROUGE(recall-oriented understudy for gisting evaluation),是最常用的自動文本摘要的評估方法,本文采用這一評價方法,它采用召回率作為指標,通過將自動生成的摘要與一組參考摘要(通常是人工生成的)進行比較計算,得出相應的分值,以衡量自動生成的摘要與參考摘要之間的“相似度”,主要包括ROUGH-N(N=1,2,…)、ROUGH-L等。
表3是各種文本摘要模型的實驗結果,其中RNN(w)和RNN(c)為文獻[8]在LCSTS數據集上基于中文詞語模型和中文漢字模型的ROUGE評價得分,Cover-Tu是文獻[10]在機器翻譯任務上提出的覆蓋率機制的方法,本文采用其中的Linguistic Coverage Model在LCSTS數據集上進行了實驗。Cover-w為式(11)對應的模型,Cover-1、Cover-5、Cover-10為式(10)對應的模型,其中衰減因子β分別為1、5、10。

Table 3 Model experiment results表3 模型實驗結果
由實驗結果可知,帶有覆蓋率機制的Seq2Seq模型的ROUGE評價得分高于普通的Seq2Seq模型,當β為5時,ROUGE評價得分最高,高于Cover-Tu的覆蓋率機制的方法。與Cover-Tu的覆蓋率機制相比,本文方法直接對coverage值較大的位置對應的Encoder的隱藏層狀態向量進行衰減,降低注意力權重,減小在語義向量ci中的比重,可以更直接地使模型關注輸入文本中沒有被利用的信息。
5.5 結果分析
對于表1中的微博文本,本文提出的帶有覆蓋率機制的文本摘要模型最終生成的摘要文本為“高盛:黃金價格預期或跌至1 200美元”,與不帶覆蓋率機制的模型相比,避免了重復生成“國際金價”的信息。
表4是不同模型的實驗結果樣例。標準摘要表示LCSTS數據集中對應的摘要,Baseline表示不帶覆蓋率機制的文本摘要模型生成的摘要,Coverage表示本文提出的帶有覆蓋率機制的文本摘要模型。可以看出,文本摘要模型引入覆蓋率機制以后,生成文本的時候同時考慮了歷史的信息,從而避免模型重復生成已生成的信息,最終生成的摘要文本包含了輸入文本中更多的信息。如Baseline生成的文本為“央視曝光3.15被央視曝光”,在帶有覆蓋率機制的模型中,根據歷史生成的“央視曝光”的信息,模型調整注意力集中的位置,接下來生成了“互聯網公司”相關的信息。Baseline生成的文本為“山寨盒子的山寨公司”,在帶有覆蓋率機制的模型中,根據歷史生成的“山寨盒子”的信息,模型接下來生成了“隱秘生態圈”相關的信息。Baseline生成的文本為“廣州飛行員飛行訓練時飛行員跳傘成功”,覆蓋率機制引入了歷史的信息后生成的文本為“廣州空軍飛機突發機械故障飛行員跳傘成功”。

Table 4 Model results sample表4 模型結果樣例
6 結束語
帶有注意力機制的Seq2Seq模型在計算時不考慮歷史生成的文本信息,可能會將注意力重復集中在輸入文本的某些位置,導致生成的摘要文本出現重復,不能很好地概括輸入文本的所有信息。針對這一問題,本文引入了覆蓋率機制,記錄生成文本時歷史時刻的注意力權重分布,并對輸入信息進行衰減,降低部分位置的注意力權重,使模型更多地考慮輸入文本中沒有用到的信息。本文在新浪微博數據集上進行了實驗,實驗結果表明,帶有覆蓋率機制的文本摘要模型的ROUGE評價得分高于普通的Seq2Seq模型。
帶有覆蓋率機制的文本摘要模型可以在一定程度上解決重復生成部分信息的問題,但仍然不能完全避免這一問題,生成的摘要文本中仍然會出現生成重復信息的情況。與機器翻譯任務不同的是,文本摘要任務的輸出文本是對輸入文本的概括總結,長度遠小于輸入文本,在輸入文本中本來就包含很多的重復信息,而機器翻譯任務的輸入文本和輸出文本存在一一對應的關系,未來可以從這個角度出發,對文本摘要任務進行進一步的研究。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
語文知識(2014年1期)2014-02-28 21:59:13
