基于圖像分割與融合特征的黃瓜葉片含水量分析方法
2019-02-26 07:39:36何林飛錢婷婷
上海農業學報 2019年1期
何林飛,朱 煜*,錢婷婷,汪 妍
(1華東理工大學信息科學與工程學院,上海 200237;2上海市農業科學院,上海 201403)
植物葉片的含水量是指示植物生長狀態的重要生理指標。葉片含水量可以直接影響葉肉細胞的氣孔導度,氣孔導度是葉片光合性能的直接影響因素[1],因此,對葉片含水量的監測可間接評價植物葉片光合性能[2]。傳統的葉片含水量測量方法為稱重法,該方法需要對葉片進行破壞性取樣,因此無法滿足連續監測的研究要求。隨著信息技術的發展,數字圖像處理技術為植物生長發育監測提供了新的技術手段。從20世紀80年代開始,二維圖像在植物生長監測中得到了大量應用[3],包括結構分析[4]、氣孔運動和光合診斷[5]、病蟲害監測[6]和產量評估[7]等。蔡鴻昌等[8]利用圖像處理技術提取葉片的顏色特征,通過線性擬合和逐步回歸分析,建立了黃瓜葉片光合色素含量的顏色特征估算模型。孫瑞東等[9]采用非線性最小二乘擬合方法,建立Log-Modified回歸模型,提出黃瓜葉片含水量無損檢測方法。楊春合等[10]提取圖像的顏色和紋理特征,并運用主成分分析和回歸方法建立水分檢測模型。在圖像采集過程中,光源類型、拍攝角度、拍攝距離等條件因素受人為影響較大,很難建立相同的拍攝環境,因而前人的研究基礎難以直接應用。高通量表型平臺的出現,為圖像采集提供了統一的采集環境,解決了拍攝環境難以統一的難題,從而為圖像處理技術在植物生長監測中的應用和推廣提供重要的基礎條件支撐。因此,本研究選取黃瓜葉片含水量為研究對象,在高通量表型平臺中獲取黃瓜植株的二維圖像,通過圖像分割與多特征融合技術,研究黃瓜葉片含水量無損檢測方法,為圖像處理技術在黃瓜葉片生理狀況監測中的應用提供支持。
在本研究中,高通量表型平臺采集的黃瓜植株為整株,需要通過圖像分割獲得葉片目標區域,而目標葉片經常和其他葉片或者雜物黏連,傳統分割方法無法達到目標葉片分割效果。針對上述問題,本研究提出采用基于GrabCut算法[11-12]的精確目標區域提取方法進行目標葉片區域分割。針對含水量回歸模型的建立問題,本研究提出采用灰度統計特征與灰度共生矩陣(Gray-level co-occurrence matrix,GLCM)紋理特征[13]相結合的特征表達方法,建立圖像特征與葉片含水量的回歸模型,以期使回歸模型的準確度較高。
1 材料與方法
1.1 材料
本研究在上海孫橋現代農業園區的玻璃溫室中進行,選用的黃瓜品種為‘戴多星’。試驗采用盆栽土培法,用大小和質量基本相同的塑料盆(盆體上口直徑25cm),配制育苗基質,體積比泥炭土∶珍珠巖∶蛭石=3∶1∶1,多菌靈體積分數0.25%,按每盆0.5kg比例加入腐熟雞糞,裝土時適當進行鎮壓。管理期間保證黃瓜水肥充足,黃瓜長至4葉1心時插支撐竹竿、綁蔓。在黃瓜長至5葉1心時,選取100盆生長一致的黃瓜植株進行水分試驗處理。水分處理分為5個梯度,每個梯度20盆。水分處理方法:分別在試驗前的第5天、第4天、第3天、第2天、第1天,對不同處理植株進行澆水,澆水后用薄膜覆蓋盆面,防止水分過度蒸發。在第6天統一進行測量。試驗重復3次。
1.2 方法
試驗流程如圖1所示,獲得試驗材料后,通過圖像分割算法,分割出目標單葉片區域圖像,再通過特征提取方法,得到單葉片圖像的特征。最后通過最小二乘回歸計算所設計的特征和葉片真實含水量之間的關系模型,并檢驗該模型的可信度。本試驗使用相關系數R2和相對誤差率(預測誤差除以真實值)檢驗模型可信度。

圖1 試驗流程Fig.1 The flowchart of experiment
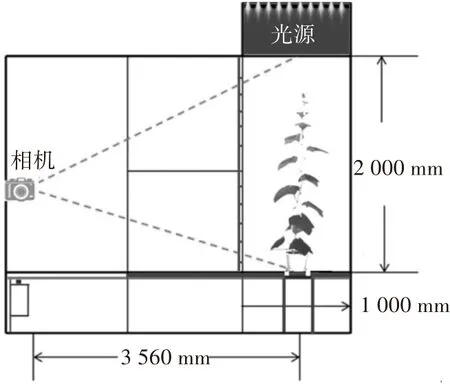
圖2 高通量表型平臺可見光成像系統示意圖Fig.2 High-throughput phenotyping platform visible imaging system
1.2.1 圖像獲取
每個處理選取生長一致的5株植株,放入高通量表型平臺的“可見光成像系統”拍攝植株側面照,并將葉齡為15d左右的葉片正面朝向鏡頭,該葉片為圖像提取對象。鏡頭距離植株3.56 m,可保證2m高度內的植株在鏡頭中全部成像。鏡頭分辨率2 448×2 050像素,像素大小3.45 μm×3.45 μm,光源強度22 kHz,圖像大小6.3 M。本試驗共獲取圖像75張。
1.2.2 含水量真值獲取
將拍照后的葉片進行破壞性取樣,在精度為0.0001g的電子天平(奧豪斯 AR224CN,美國奧豪斯公司)上稱量葉片鮮重,在80°C條件下烘干后,稱量葉片干重,葉片含水量由下式計算得到:
(1)
1.2.3 單葉片圖像分割
GrabCut算法[11]使用圖論的方法對圖像進行建模,把圖像分割問題轉化為圖的最小割問題。算法由GMM混合高斯模型對原始圖像RGB顏色空間進行前景和背景區域的建模,其中使用K個高斯分量,一般取K=5。圖像的Gibbs能量為:
E(α,k,θ,z)=U(α,k,θ,z)+V(α,z)
(2)
其中U是區域項,表示一個像素被歸類為目標或者背景的懲罰;V是邊界項,體現鄰域像素之間不連續的懲罰。下劃線表示該變量需要經過迭代優化。區域項U定義為:
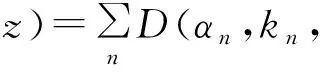
(3)
其中,D(αn,kn,θ,zn)表示第n個像素點為目標或背景的權重,D(αn,kn,θ,zn)=-log(zn|αn,kn,θ)-logπ(αn,kn),p(·)是高斯概率分布,π(·)是混合權重系數。αn表示第n個像素點處的標簽,0表示背景,1表示前景。kn表示第n個像素點屬于的高斯分量。θ={π(αn,kn),μ(αn,kn),∑(αn,kn)}表示GMM的3個參數。zn表示第n個像素點的RGB數值。
邊界項V定義為:

(4)
V(α,z)表示鄰域像素m和n之間的差異,兩鄰域像素差別越大,這兩個像素處于目標和背景邊緣的可能性越大,則其能量V越小。γ為平衡系數,平衡區域項和邊界項的比例,β為對比度系數,用于調整不同對比度圖像的邊界距離。基于GrabCut算法[11]的葉片分割步驟如下:
1)選擇一幅植株圖像中的葉片前景區域TF和背景區域TB。
2)初始化標簽參數αn=0,n∈TB;αn=1,n∈TF,并建立前景和背景的GMM模型。
3)對于可能的前景區域TF中的每一個像素點n,計算kn∶argminkn=D(αn,kn,θ,zn)。
4)已知圖像數據z,學習GMM的參數θ=argminθU(α,k,θ,z)。
5)通過最小費用最大流算法對圖進行分割估計min{αn:n∈TF}minkE(α,k,θ,z)。
6)重復步驟3—5,直到收斂,從而獲得分割的單個葉片圖像。
1.2.4 圖像特征提取與含水量回歸分析
分割后得到目標葉片,通過圖像特征提取,得到與葉片含水量相關的統計特征。針對彩色圖像提取了三維RGB顏色特征[14],針對灰度圖,提取了標準差、平滑度、歪斜度、一致性、熵[18]以及GLCM紋理特征[13]作為葉片的圖像特征。采用的GLCM紋理特征包括:
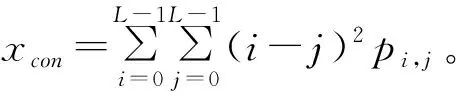


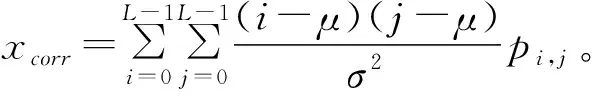

最后通過提取的圖像多維融合特征和葉片烘干含水量真值進行回歸分析,利用最小二乘回歸計算模型參數。回歸模型為:
y=a0+a1x1+a2x2+…+anxn
(5)
其中:x是圖像的特征,a為最小二乘擬合的系數,y為擬合的含水量,n為特征維度。

圖3 目標葉片區域分割Fig.3 Target leaf area segmentation
2 結果與分析
圖3為葉片分割結果對比試驗,每行為1棵植株,共展示3棵植株的結果。(a)圖為拍攝裝置獲取的黃瓜葉片原圖,其中紅框表示該植株用于含水量分析的葉片。(b)圖是基于經典水平集分割方法[15]的結果,可以看到由于目標葉片與其他葉片黏連,難以獲得理想的目標葉片區域。(c)圖為通過GrabCut算法分割后得到的目標葉片區域,可見GrabCut算法能完整分割出目標葉片區域,且有效去除了其他葉片區域的黏連影響。
通過GrabCut算法得到植株的目標葉片區域后,利用1.2.4節的方法進行特征提取,得到標準差、平滑度、歪斜度、一致性、熵、GLCM紋理特征等多維融合統計特征,再與葉片的含水量測量值進行回歸分析。
為了研究黃瓜葉片不同發育時期下的葉片含水量,試驗數據分三批獲取,前兩批各25株,第三批24株。為測試所選特征的合理性,將每批數據的80%(三批共計59株)用于擬合模型;剩余20%的樣本(三批共計15株)用于檢驗模型誤差,得到三批數據的平均相對誤差分別為9.10%、4.63%和4.61%。批次內的殘差分布(圖4)表明,三批數據均獲得較少的誤差率,所采用的圖像特征具有良好的表征能力。為進一步測試批次間的模型泛化能力,將第三批數據作為訓練集,前兩批數據作為測試集。使用最小二乘法擬合訓練集圖像特征與葉片含水量,得到R2為0.8358。圖5中訓練集數據的預測值和真實值分布接近于45°直線,說明模型選取的特征與含水量之間有較好的擬合關系。批次間的泛化性能測試得出,第一批的平均相對誤差為10.88%,第二批的平均相對誤差為7.98%。批次間的殘差分布(圖6)表明,誤差在可控范圍之內,表明該模型在批次間也有較好的泛化能力。
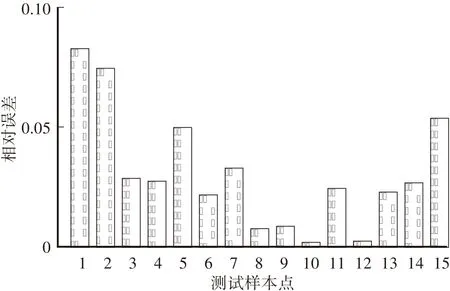
圖4 批次內殘差分布Fig.4 In-class residual distribution
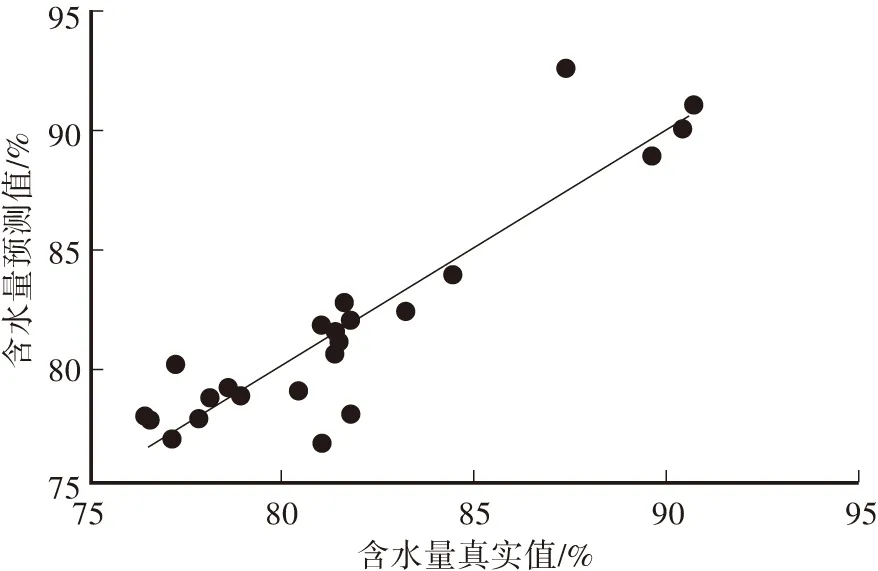
圖5 含水量真實值與預測值分布Fig.5 Water content of the true value and the predicted value distribution
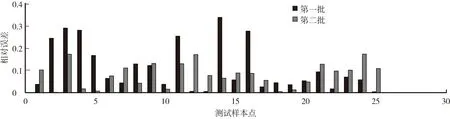
圖6 批次間殘差分布Fig.6 Residual distribution between classes
3 討論與結論
黃瓜葉片含水量不僅可以反映植株生長狀態和葉片光合能力,同時也是水分管理的敏感指標。本研究通過水分處理,使葉片中的含水量在67%—94%范圍內形成水分梯度,從而實現了不同含水量葉片的圖片獲取。與孫瑞東等[9]、王娟[16]的試驗方法不同,本研究沒有采用固定的土壤含水量處理,而是利用了澆水后土壤水分隨蒸散而減少的規律,與黃瓜生產中土壤水分變化規律更為接近,同時也避免了因長期水分脅迫對光合器官的破壞而引起的葉片顏色變化。
如何有效地從圖像中提取目標區域,剔除背景,一直以來都是研究人員關注的重點。目前圖像分割方法主要有基于閾值分割法、基于區域分割法、基于邊緣分割法以及基于特定理論分割法等[17-18]。針對植物葉片重疊嚴重的圖像,葉片與葉片之間顏色非常相近,單純用前三類算法提取往往達不到理想效果。因此本研究采用了GrabCut算法,利用簡單的交互就可獲得圖像中感興趣的目標圖像的準確區域。與基于傳統水平集算法的葉片分割結果進行對比,本研究的方法具有圖像分割準確性更高的特點。與此同時,該算法也存在著計算量大,需要人機交互的缺點,未來還應該考慮更加智能的分割方式,減少人機交互,優化算法性能。
本研究以黃瓜葉片為研究對象,在高通量表型平臺中獲取植株圖像,同時用烘干法測量植株目標葉片的含水量。使用GrabCut算法對植株圖像進行分割,得到目標葉片圖像區域。再提取圖像的標準差、平滑度、歪斜度、一致性、熵及GLCM紋理特征作為圖像綜合特征,與含水量進行回歸分計算。并對不同批次獲取的黃瓜葉片圖像與其含水量之間進行誤差分析。研究結果顯示,該模型有較高的可信度和較好的泛化能力,對于不同發育時期的黃瓜葉片都能較好的預測其含水量。下一步將考慮更有效的圖像融合特征表達,以提高預測的準確率以及模型的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
