基于稻穗幾何形態模式識別的在穗籽粒數估測
2019-03-06 02:27:36馬志宏毛雨晗劉成良
上海交通大學學報 2019年2期
關鍵詞:特征
馬志宏, 貢 亮, 林 可, 毛雨晗, 吳 偉, 劉成良
(上海交通大學 機械與動力工程學院, 上海 200240)
隨著人口的增加,水稻產量的提高已成為農業研究的重點問題.稻穗是水稻的結實器官,與水稻產量直接相關,其表型特征是水稻育種[1-2]研究中重要的量化指標,主要包括每穗籽粒數、一次枝梗數量及長度、一次枝梗籽粒數、結實率、稻穗骨架結構[3]等.目前這些特征數據主要是通過傳統手工測量得到,這種方法不僅勞動強度大,而且效率低下,受人為主觀性限制,重復性較差.隨著技術的發展,自動化、高通量等技術運用于作物表型特征的提取,逐漸取代了傳統手工測量,可以節省大量時間和人力成本.圖像處理技術可以從高分辨率圖像自動測得各種表型參數[4-5].針對稻穗籽粒數的測量,國內外科研人員已經開發了一些基于圖像處理的自動化設備[6-7],這些設備均需要先對稻穗脫粒,再結合圖像處理方法對稻穗籽粒數和其他性狀參數進行測量,會破壞稻穗形態結構,不利于樣本保存.
基于圖像分割的方法是密集顆粒狀物體計數的常用方法,在細胞計數[8-9]上頗具效果.但是對于稻穗平面圖像,由于谷粒間互相遮擋和重疊較嚴重,谷粒之間邊緣不夠明顯,令計數難以進行,國內外相關研究也多采用稻穗面積等特征來預測谷粒個數.P-TRAP[10]是一款用于水稻表型測量的開源軟件,它采用總面積除以單個谷粒平均面積,并乘以一個修正系數加以修正的結果,作為籽粒數的測量結果,這種方法需要提前測量非重疊谷粒的平均面積,而且修正系數由人為設定,主觀因素干擾大.文獻[11]中采用X射線成像技術對水稻穗部籽粒數無損檢測, X射線具有良好的透射特性,可以較好地解決遮擋問題,但這種方法具有放射性污染.文獻[12]中采用稻穗投影面積和一次枝梗總長度進行回歸預測,籽粒數預測誤差為 7.9%,但只能預測整株稻穗籽粒數,不能預測每個一次枝梗所含籽粒數.
除了圖像處理技術,機器學習技術也越來越多地應用到植物表型提取和測量研究領域[13-14].但是,利用機器學習結合圖像形態學特征來預測稻穗谷粒數方面的相關研究尚處于空白階段.因此,本文提出采用圖像特征提取和機器學習方法,訓練模型進行稻穗谷粒數預測.具體做法是,利用圖像處理方法提取稻穗一次枝梗,基于支持向量機(Support Vector Machine,SVM)訓練一次枝梗谷粒數預測模型,預測結果求和作為整株稻穗的谷粒數.本文認為二次枝梗為一次枝梗的一部分,且二次枝梗通常較小,使用圖像處理算法提取二次枝梗難度較大,在預測籽粒數時不再區分一次枝梗和二次枝梗,這樣對總粒數測量并沒有影響.本文以3個品種的稻穗為研究對象,分別為粳稻日本晴、9522、秈稻9311,并通過實驗驗證了所提方法的有效性.
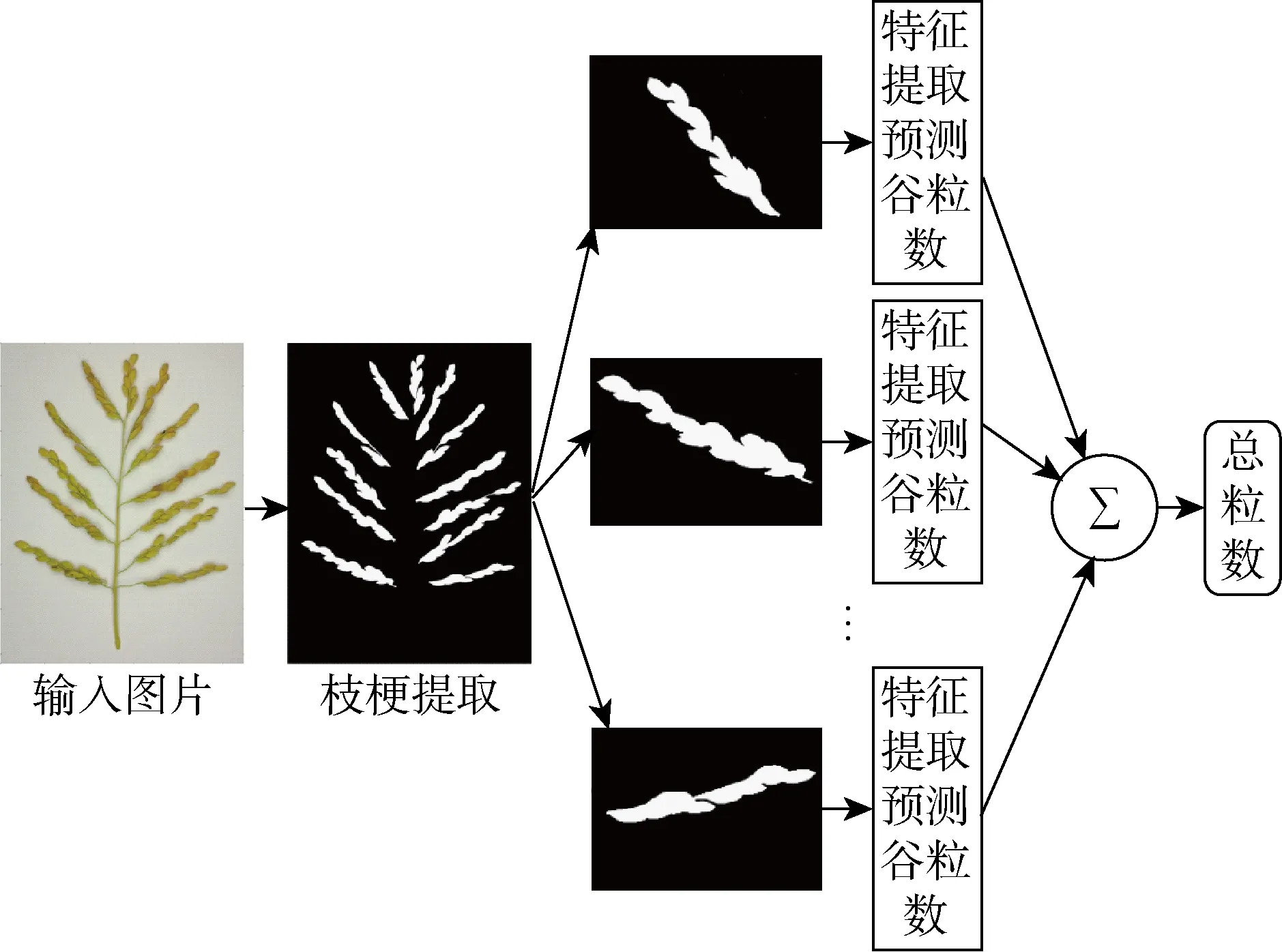
圖1 稻穗谷粒數預測方法流程圖Fig.1 Flow chart of rice grain number prediction method
1 研究方法
由于稻穗谷粒之間遮擋和粘連情況較嚴重,而且2個粘連谷粒之間沒有明顯的邊界特征,所以基于圖像分割方法的谷粒計數難以得到高精度的結果.如果采用機器學習的方法,直接使用圖像處理方法從稻穗圖像中提取特征,訓練粒數預測模型來計算稻穗谷粒個數,則可以避免圖像分割,且隨著訓練樣本的不斷擴充,理論上模型預測精度和泛化能力可以提高.文獻[13]中采用稻穗投影面積和一次枝梗總長度進行回歸預測,因此可以使用稻穗投影面積和一次枝梗長度作為訓練特征的一部分.選擇訓練對象時,如果將整株稻穗作為訓練對象,則存在以下問題:如果將個數預測看作分類問題,其類別會超過200個,當稻穗的樣本數量較少時,模型容易出現過擬合.實際中,采集并標注超過500個稻穗樣本需要耗費很大的勞動力.考慮到每株稻穗平均包含若干個一次枝梗,每個一次枝梗所包含的谷粒數大部分在40粒以內,如果將一次枝梗作為訓練對象,則可以增加訓練樣本數量,減少類別數目,有利于對抗過擬合.因此,本文提出如圖1所示的稻穗谷粒數預測方法,首先進行一次枝梗的提取,對每個一次枝梗分別提取特征并用SVM模型預測谷粒個數,隨后將所有預測值相加即可得到稻穗谷粒總數.
2 水稻稻穗形態圖像特征提取
特征提取是機器學習的前提,也是決定模型預測精度的關鍵,如果特征選擇不妥當,比如存在過多相關性差的冗余特征,訓練結果可能出現過擬合等問題.觀察稻穗樣本可以看出,顏色特征跟谷粒個數幾乎沒有相關性,而形態特征則有顯著相關性.另外,顏色特征容易受到光照環境影響,而形態特征與光照環境無關,不容易受到外界環境的干擾.因此,本文只采用形態學特征訓練模型.
2.1 圖像預處理
提取形態學特征前,需要將圖像轉換為二值圖,使一次枝梗的前景像素值為1,背景的像素值為0.由于光照情況下一次枝梗周圍會產生陰影,為了克服陰影帶來的影響,分割出完整的一次枝梗前景,這里采用在HSV(色度、飽和度和純度)顏色空間進行二值化操作.H、S分量可以消除亮度信息的影響,考慮本研究中由于光照不均勻,一次枝梗周圍會產生陰影,影響一次枝梗前景二值化,故可采用S通道抑制陰影.利用OSTU自適應閾值的方法對S通道圖像二值化,再通過開運算進行形態學濾波,去除二值圖中的噪點,同時消除一次支梗頭尾部多余的細枝,得到二值圖(見圖2(b)).隨后計算距離變換圖,距離變換是計算并標識空間點(對目標點)距離的過程,它最終把二值圖像變換為灰度圖像(其中每個像素的灰度值等于它到最近目標點的距離),使用歐式距離變換方式,對二值圖進行處理得到圖2(c),圖中顏色越接近黑色,表示離最近點距離越大,越接近白色,表示離最近點距離越小.它能反映圖像的某些形態學特征,如果配合骨架信息,能得到一次枝梗沿軸線上不同部位谷粒的分布密度.為此,先提取二值圖的骨架,使用細化算法進行骨架提取,得到骨架圖,骨架圖與距離變化圖相乘得到圖2(d),記為骨架距離圖,由圖2(d)可以看出一次枝梗沿軸線上不同部位谷粒的分布密度.

圖2 一次枝梗形態學特征圖Fig.2 Morphological features of primary branches
具體實現過程使用基于Python 3.5語言編寫的程序.使用OpenCV(版本2.4.9)工具進行HSV顏色空間轉換、二值化、開運算、輪廓提取、細化、距離變換等操作.其中,二值化閾值采用函數Threshold計算,方式參數為OSTU,形態學操作的結構元素設置半徑為3的圓盤結構,距離變換方式為歐氏距離,細化操作使用Hilditch算法[15]實現.
2.2 特征提取
對于一次枝梗形態學特征,最直觀的是投影面積和一次枝梗長度特征[12],在此基礎上,又提取了二值圖前景的輪廓和最小外接矩形,計算出周長,最小外接矩形長、寬、長寬比,矩形度(區域面積與最小外接矩形面積之比),骨架曲線長度這些特征.另外,根據一次枝梗的形狀特點,設計了骨架距離平均值和骨架距離方差,前者計算沿骨架上每一點的距離值平均值,容易發現,這個平均值一定程度上反映了一次枝梗的平均半徑.設二值圖為B(x,y),距離變換圖為D(x,y),骨架圖為T(x,y),骨架距離圖為H(x,y),則H(i,j)=D(i,j)T(i,j),i=1,2,…,w,j=1,2,…,h,其中w是圖像寬度,h是圖像高度.特征計算公式如下:
(1) 投影面積.投影面積可以直接從一次枝梗二值(圖2(b))反映,這里以一個像素點代表單位面積,投影面積則是對二值圖求和
(1)
(2) 周長.周長即輪廓長度,設一個閉合輪廓坐標點序列為{(x1,y1),(x2,y2),…,(xn,yn)},記xn+1=x1,yn+1=y1,其中n為序列長度,則周長為
(2)
(3) 最小外接矩形長寬比,主軸長度.提取最小外接矩形,得到其最小外接矩形2個邊長,記為l1,l2,則長寬比為
f3=max{l1/l2,l2/l1}
(3)
使用最小外接矩形長邊作為主軸長度
f4=max{l1,l2}
(4)
(4) 矩形度.矩形度表示區域面積與其最小外接矩形面積的比值
f5=f1/(l1l2)
(5)


(6)
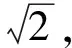
(6) 骨架距離均值.遍歷骨架上點,求骨架點所對應的距離值的均值,公式為
(7)
以上所有特征都具有旋轉不變性,平移不變性,但是某些特征不具有縮放不變性.因此需要保證訓練樣本的像素比和測試樣本的像素比相同,否則同一個一次枝梗在不同像素比的圖像中,提取的特征可能會有較大差異.本文實驗均為同一平臺,所得到圖像的像素比均為 0.118 mm/像素.而實際應用過程中,圖像可能來自其他成像平臺,對于這些圖像,提取特征前需要先將圖像等比例縮放到固定的像素比,使得像素比的值等于訓練集圖像的像素比 0.118 mm/像素,才能用本文算法得到正確的結果.
3 籽粒數預測SVM模型
籽粒數預測的目標是一個非負整數,在有限樣本下,這個非負整數有上界U,此時粒數預測可以看成一個分類問題,其類別數為U個.本文算法的模式識別部分選擇作為分類器, SVM是建立在統計學習理論VC維理論和結構風險最小化原理基礎上的機器學習方法.它在解決小樣本、高維和非線性模式識別問題中表現出許多獨特的優勢,而且具有堅實的理論基礎[16].
通常,一個SVM基本分類器只能完成二分類任務,對于對分類任務,一般采用多個SVM集成預測,通常采用的訓練策略有一對余型SVM、一對一型SVM等,如果類別數為n,一對余型SVM需要訓練n-1個SVM基本分類器,一對一型SVM需要訓練n(n-1)/2個SVM基本分類器.考慮到粒數預測值為連續整數的特點,本研究設計了一種集成SVM預測模型訓練策略.設訓練集中一次枝梗粒數的最大值為k粒,最小值為1粒,則設計這樣一個分類器,它由(k-1)個二分類SVM組成,第i個SVM的輸出表示粒數是否超過i,其中i=1,2,…,k-1.訓練第i個SVM分類器Fi時,正樣本對應大于i粒的一次枝梗,負樣本對應少于或等于i粒的一次枝梗,則一次枝梗谷粒數預測值為
(8)
相比于一對余型SVM的訓練策略,上述方法需要的SVM個數同樣為n-1.不同的是,只有對位于兩頭的SVM訓練時,訓練集樣本不平衡問題才會比較顯著,所以這種策略相對一對余型SVM可以更好地解決樣本集不平衡問題,相對于一對一型SVM有預測速度的優勢.
訓練對象是一次枝梗圖像(見圖2(a)),需要將每個一次枝梗摘下,分別拍照并手工計數標記.以9個一次枝梗為一組,將其按3×3的九宮格位置均勻擺放在背景板上,背景板尺寸為300 mm×240 mm,每個小方格可容納的一次枝梗長度為100 mm,可容納大多數長度的一次枝梗.使用500萬像素的工業相機,調整相機高度和焦距,使相機的視野剛好完整包含背景板,隨后進行一次拍照,采集圖像.然后,翻轉每個一次枝梗,再進行一次拍照,這樣,總共得到2張照片,故一組一次枝梗可以得到18個訓練樣本,在擺放枝梗的同時,手工數出籽粒個數,按圖像名記錄在表格,隨后經過圖像裁剪,得到所有一次枝梗圖像的訓練樣本,根據表格標記對應的籽粒數.實驗所用稻穗為3個不同的品種混合而成,分別為粳稻日本晴、9522、秈稻9311.實驗中總共采集了 2 688 幅稻穗一次枝梗圖像,裁剪后分辨率為800 pixel×600 pixel,每幅一次枝梗圖像僅包含1個一次枝梗.采集所用的相機為中國大恒公司生產的MER-500-7UM/UC-L型工業數字相機,實驗軟件基于Python 3.5,計算機的配置為處理器 Intel(R) Core(TM)i7-6700@3.40 GHz,內存8 GB.
訓練時,采用徑向基核函數,將 2 688 個樣本分為訓練集和測試集,大小分別為 2 190 幅,498幅,最大一次枝梗谷粒數為26粒,最小為1粒,故k=26.在訓練時,使用交叉驗證策略,將訓練集分為5份,其中 1 752 幅用來訓練,438幅用來驗證,以交叉驗證的平均預測誤差為優化目標,尋找最優懲罰參數C和核函數參數σ.

圖3 稻穗形態特征圖和一次枝梗提取效果Fig.3 Extraction effect of morphological features of panicle and primary branches
為保留有效特征,減少不重要特征數量,避免過擬合,本文使用ReliefF算法[17]先對特征進行重要性分析和排序,并根據特征權重,選擇若干組特征組合分別進行訓練,特征權重和不同特征組合的訓練結果如表1所示.由表1可知,誤差最小的2組特征分別為組合4(f1,f2,f4,f5,f6)和組合5(f1,f2,f3,f4,f5,f6),兩者誤差相等,但前者比后者少一個特征f3,可以減少一點計算量,故最終選擇前者作為訓練特征.
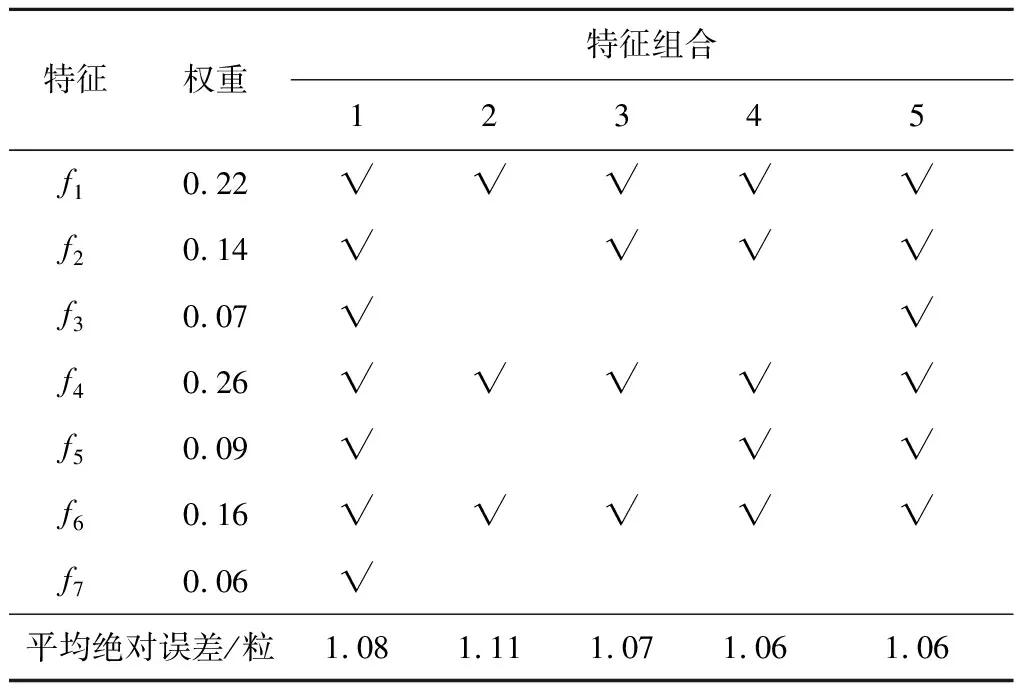
表1 不同特征組合的預測結果Tab.1 Prediction results of different feature combinations
4 一次枝梗提取和測量
本文的訓練對象是一次枝梗圖像,而實際中測量對象往往是整株稻穗.稻穗在自然狀態下具有收縮內斂的趨勢,直接成像往往會導致大量谷粒被遮擋,因此實際中,通常需要將稻穗平展鋪開再進行成像,如圖3(a)所示.為了提取稻穗上所有的一次枝梗,需要剔除莖稈和芒,文獻[10,12]中直接進行形態學開操作的方式去除直徑較細的莖稈和芒,開操作首先對二值圖進行腐蝕運算,再進行膨脹運算,而腐蝕運算會將所有半徑較小的區域剔除,半徑較大
的區域則保留,目的性較差.開操作結構元素半徑過小,不能剔除較粗的莖稈,半徑過大容易過度腐蝕,導致一次枝梗斷裂,如圖3(c)所示.所以采用這種方法通常需要二次判別篩選,將非目標區域剔除.本文根據稻穗形狀特點,提出基于局部距離方差的一次枝梗區域提取方法.這里,局部距離方差指以稻穗骨架上一點為中心,一定長寬的圓形領域內,所有骨架點在距離變換圖上的距離均方差,如圖4所示.
ω(i,j,r)=sgn(r2-i2-j2)
(9)

(10)
E(x,y,r)=
(11)
E(x,y,r)T(x,y)]2
(12)
式中:x,y為骨架點坐標;r為鄰域半徑;H(x,y)為骨架距離圖(見圖3(e));ω(i,j,r)表示圓形模板,當i,j在以(0,0)為中心,半徑為r的圓內時,輸出為1,其余為0;E(x,y,r)為骨架點半徑為r的領域內距離均值;S(x,y,r)為骨架點半徑為r的領域內距離方差.

圖4 局部距離方差示意圖Fig.4 Schematic of local distance variance
經過實驗,取閾值α,以r半徑的鄰域內距離方差小于α,并且當前點距離值小于β時,將這點周圍以1.5倍的距離值為鄰域的區域置為背景像素值,否則,不操作.如圖4所示,(x,y)表示當前需要處理的像素點坐標,點(x,y)的局部距離方差是指,在以此點為圓點,半徑為r的圓內,計算所有骨架上的像素點對應的距離值的方差,圖4中灰色區域為稻穗前景,細線條狀像素點表示骨架,其顏色代表像素點對應在距離變換圖中的距離值,越接近黑色,表示距離值越小,越接近白色,表示距離值越大.當遍歷完整個骨架像素點時,所有非目標物都被剔除,如圖3(f)所示,后面采用連通域查找算法即可提取所有一次枝梗的二值圖.經過實驗,α取6.5,β取10,r取40時效果最佳.
算法基于局部距離方差的一次枝梗分離算法

Input: image,α,β,r#輸入稻穗圖像和參數
1:B=binarization(image) #圖像預處理和二值化
2:D=distanceTransform(B) #距離變換
3:T=thining(B) #細化
4:H=DT#矩陣D和矩陣T對應元素相乘,得到矩陣H
5: Forxfrom 1 to width
6: Foryfrom 1 to height
7: IfH[x][y] > 0 andH[x][y]<βthen
8:s=S(x,y,r) #計算以(x,y)為中心的局部距離方差,見式(12)
9: Ifs<αthen
10: drawCircle(B,x,y,1.5×H[x][y])
#在圖B上以點(x,y)為中心,1.5×H[x][y]為半徑畫圓,填充灰度為0
11: End if
12: End if
13: End for
14: End for
Output:B
由于這一步已經進行了距離變換和細化操作,后面提取一次枝梗形態學特征時不必重復做這2個步驟,一定程度上節省了時間.所以,對于整株稻穗的谷粒計數算法偽代碼如上述算法所示,通過二值化,形態學預處理,基于局部距離方差的一次枝梗區域提取,對每個一次枝梗提取特征,并預測籽粒個數,最后對所有預測結果求和,得出整株稻穗的籽粒預測數.從圖3(f)可以看出,本文算法可以有效去除支稈,完整保留一次枝梗,并且不會造成一次枝梗斷裂(見圖3(c)),可以保證一次枝梗形態學特征提取的準確度,提高一次枝梗谷粒數的預測精度.
5 實驗結果與分析
實驗選取62株完整的稻穗來測試本文算法的預測效果,這些稻穗樣本品種來源與訓練樣本相同,不同之處為訓練樣本是將稻穗剪切成若干一次枝梗,而測試樣本則為完整稻穗.每株稻穗包含的一次枝梗數目為7~18個,總谷粒數在40~200粒.稻穗鋪開后在同一實驗平臺(即采集訓練樣本的平臺)下進行圖像采集,并手工數粒進行標記.
為了體現算法的預測穩定性,將測試樣本隨機分成3組,每組約20個稻穗,記為樣本1, 2, 3.實驗時,分別對3批樣本單獨測試1遍,然后對3批樣本合起來測試1遍.表2顯示了測試結果,可以看出最大平均誤差為 6.72%,優于文獻[12]的測量誤差.為了體現本文算法的優越性,同時使用一對余型SVM進行訓練和預測.由表2可見,一對余型SVM所得到的誤差略高于本文算法,說明本文提出的SVM訓練策略較好地解決了數據不平衡問題.
圖5所示為一組稻穗測試樣本的谷粒數預測結果和一次枝梗提取效果.結果顯示,大部分稻穗一次枝梗均能準確提取,但是當2個一次枝梗之間沒有充分分開,有粘連情況,則會將2個一次枝梗誤判為1個一次枝梗,因此稻穗擺放時需要保證每個一次枝梗互不粘連.

表2 稻穗谷粒數預測實驗結果Tab.2 Experimental results of panicle grain number prediction

圖5 稻穗測試樣本的谷粒數預測結果和一次枝梗提取效果Fig.5 The prediction results and primary branch extraction effects of rice grain numbers of test samples
6 結語
本文提出的使用形態學特征進行模型訓練來預測谷粒數的方法,在實驗中最大平均誤差為 6.72%,說明本文方法可以成功應用在稻穗谷粒數預測上;而形態學特征對顏色和光照環境不敏感,魯棒性較高,若稻穗發生霉變或其他原因造成稻穗顏色變化,只要形狀不發生變化,依然能得到相同測量結果;此外,基于局部距離方差的一次枝梗提取方法能夠較好地避免一次枝梗斷裂的問題,保證了一次枝梗特征提取的準確度和穩定性.不足之處是必須人工將稻穗充分鋪開,否則會出現較大誤差.同時,人工鋪開稻穗耗費時間和體力,因此本文方法只適合小批量樣本的測量.后續工作中,稻穗的鋪開方式還有進一步優化空間,采用自動化或半自動化方式鋪開稻穗,可以減少人力勞動成本,提高本文方法的實用性.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
